Multimodal Sexism Identification and Characterization using Large Language Models and Gradient Boosting
Pith reviewed 2026-06-28 02:40 UTC · model grok-4.3
The pith
LLM-derived semantic features improve sexism detection in memes while video results hinge on feature dimensionality and generalize differently on test data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Focused LLM-derived semantic cues improve meme sexism identification, while video performance is highly sensitive to feature dimensionality and cross-modal noise; development results favor compact feature selection for videos, but this does not fully transfer to unseen test data where the unfiltered representation generalizes better.
What carries the argument
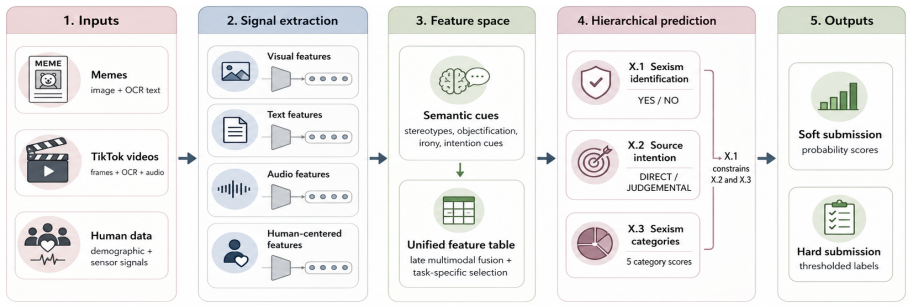
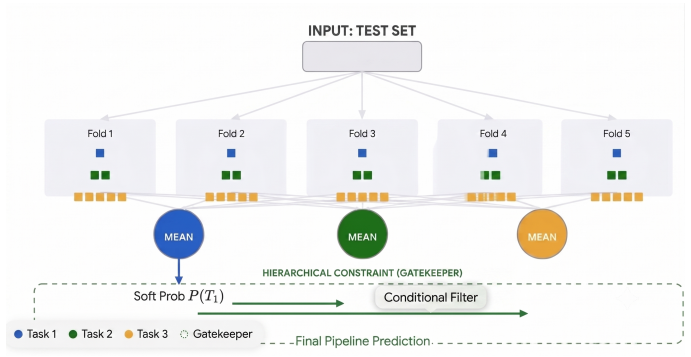
A feature-engineered late-fusion pipeline using gradient-boosted regression models and hierarchical post-processing that incorporates LLM-derived semantic indicators alongside visual, textual, demographic and biometric inputs.
If this is right
- LLM semantic indicators can be combined with traditional visual and textual descriptors to target high-level social cues in static meme content.
- Video sexism detection requires explicit management of feature count to limit cross-modal noise on development sets.
- Unfiltered multimodal representations may prove more robust than dimensionality-reduced ones when moving from development to unseen short-form video test data.
- Hierarchical post-processing after gradient boosting can refine initial regression outputs for both tasks.
Where Pith is reading between the lines
- The dev-test gap for videos points to a need for explicit temporal modeling that the current frame-based and acoustic features do not supply.
- Similar late-fusion pipelines with LLM cues could be applied to other multimodal classification problems involving social bias in images or short clips.
- The sensitivity to feature selection suggests that automated dimensionality reduction or noise-robust fusion layers might stabilize video performance across domains.
Load-bearing premise
The chosen visual, textual, demographic, biometric and LLM-derived features actually capture the intended high-level cues such as stereotyping, objectification, irony and misogyny without substantial bias or noise from the competition data.
What would settle it
Removing the LLM-derived semantic features and observing no drop in meme test performance, or finding that compact video features outperform unfiltered ones on additional held-out video data, would falsify the reported improvements and sensitivity claims.
Figures
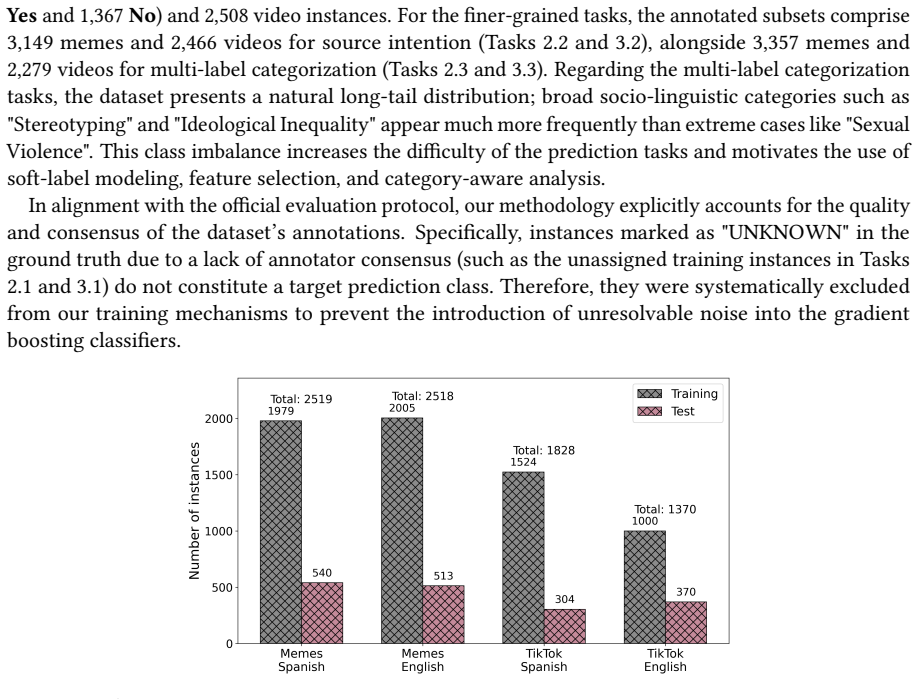
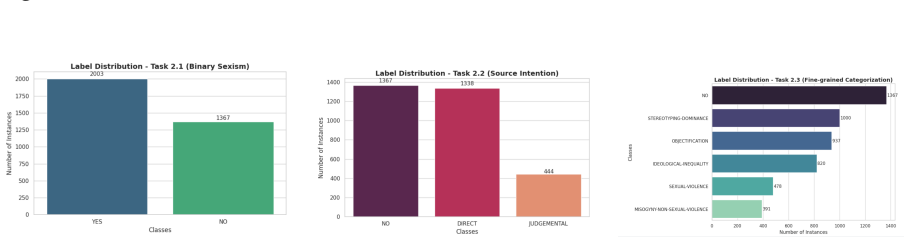
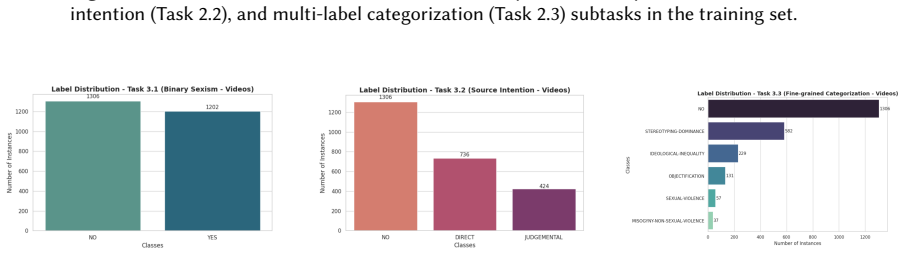
read the original abstract
We present the AILS-NTUA submission to the EXIST 2026 Lab at CLEF, addressing multimodal sexism identification and characterization in memes (Task 2) and short-form videos (Task 3). Our system follows a feature-engineered late-fusion pipeline built around gradient-boosted regression models and hierarchical post-processing. For memes, we combine visual, textual, demographic, biometric, and LLM-derived semantic indicators designed to capture high-level cues such as stereotyping, objectification, irony, and misogyny. For videos, we investigate the effect of feature selection, frame-based visual representations, OCR-based textual features, acoustic descriptors, and sensor-derived metadata. Development results show that focused LLM-derived semantic cues improve meme sexism identification, while video performance is highly sensitive to feature dimensionality and cross-modal noise. For videos, development results favor compact feature selection, but official test results show that this conclusion does not fully transfer to unseen data, where the unfiltered representation generalizes better. Overall, our findings highlight the usefulness of targeted semantic feature engineering for static memes and the need for more robust temporal modeling in noisy short-form video settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the AILS-NTUA submission to the EXIST 2026 Lab at CLEF for multimodal sexism identification and characterization in memes (Task 2) and short-form videos (Task 3). It describes a feature-engineered late-fusion pipeline using gradient-boosted regression models and hierarchical post-processing. For memes, visual, textual, demographic, biometric, and LLM-derived semantic features are combined to capture cues such as stereotyping and misogyny. For videos, the effects of feature selection, frame-based visuals, OCR text, acoustics, and metadata are investigated. The central empirical claims are that focused LLM-derived cues improve meme performance while video results are highly sensitive to feature dimensionality and cross-modal noise, with development favoring compact selection but official test results showing better generalization from the unfiltered representation.
Significance. If the reported patterns hold, the work offers modest empirical value by illustrating the utility of targeted semantic feature engineering for static memes and the practical challenges of feature selection transfer in noisy video settings. The explicit acknowledgment that development conclusions fail to generalize to test data is a strength, as is the use of diverse feature types including LLM indicators. No machine-checked proofs or parameter-free derivations are present, but the competition-system framing and honest limitation reporting aid reproducibility of observed patterns.
major comments (1)
- [Abstract] Abstract: the claims that 'development results show that focused LLM-derived semantic cues improve meme sexism identification' and that 'video performance is highly sensitive to feature dimensionality' with a specific transfer failure are presented without any quantitative metrics, ablation tables, error bars, or validation details, which are load-bearing for substantiating the central performance-pattern observations.
minor comments (2)
- The methods description would benefit from explicit listing of the exact feature dimensions used in the compact vs. unfiltered video representations and the precise form of the late-fusion step.
- Consider adding a dedicated results section with per-task scores on both development and official test sets to allow direct comparison of the reported sensitivity effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that 'development results show that focused LLM-derived semantic cues improve meme sexism identification' and that 'video performance is highly sensitive to feature dimensionality' with a specific transfer failure are presented without any quantitative metrics, ablation tables, error bars, or validation details, which are load-bearing for substantiating the central performance-pattern observations.
Authors: We acknowledge that the abstract presents these findings at a summary level without embedding specific numbers. The manuscript body provides the supporting quantitative evidence: ablation results demonstrating LLM feature gains on meme development data, tables comparing feature-selection variants for videos, and explicit development-versus-test performance gaps illustrating the transfer failure. Error bars from repeated runs are included where relevant. To better substantiate the abstract claims, we will revise the abstract to incorporate representative metrics and a brief reference to the key tables. revision: yes
Circularity Check
No significant circularity; empirical competition results only
full rationale
The paper is a system description for the EXIST 2026 Lab, reporting empirical performance of a late-fusion gradient-boosting pipeline on meme and video sexism tasks. No mathematical derivations, first-principles predictions, or equations are claimed. Feature selection and LLM-derived cues are presented as engineering choices evaluated on development vs. test splits, with explicit note that video conclusions fail to transfer. No self-citations, fitted-input predictions, or ansatzes appear in the provided text; all claims reduce to observed metrics rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Glick, S. T. Fiske, The ambivalent sexism inventory: Differentiating hostile and benevolent sexism, Journal of Personality and Social Psychology 70 (1996) 491–512. doi:10.1037/0022-3514. 70.3.491
-
[2]
B. L. Fredrickson, T.-A. Roberts, Objectification theory: Toward understanding women’s lived experiences and mental health risks, Psychology of Women Quarterly 21 (1997) 173–206. doi:10. 1111/j.1471-6402.1997.tb00108.x
arXiv 1997
-
[3]
Jane, Misogyny Online: A Short (and Brutish) History, SAGE Publishing, 2016
E. Jane, Misogyny Online: A Short (and Brutish) History, SAGE Publishing, 2016. doi:10.4135/ 9781473916029
2016
-
[4]
F. Santoniccolo, T. Trombetta, M. N. Paradiso, L. Rollè, Gender and media representations: A review of the literature on gender stereotypes, objectification and sexualization, International Journal of Environmental Research and Public Health 20 (2023). URL: https://www.mdpi.com/ 1660-4601/20/10/5770. doi:10.3390/ijerph20105770
-
[5]
just a joke
T. E. Ford, C. F. Boxer, J. Armstrong, J. R. Edel, More than “just a joke”: The prejudice-releasing function of sexist humor, Personality and Social Psychology Bulletin 34 (2008) 159–170. doi:10. 1177/0146167207310022
2008
-
[6]
Drakett, B
J. Drakett, B. Rickett, K. Day, K. Milnes, Old jokes, new media: Online sexism and construc- tions of gender in internet memes, Feminism & Psychology 28 (2018) 109–127. doi: 10.1177/ 0959353517727560
2018
-
[7]
Shifman, Memes in Digital Culture: Library Edition, Blackstone Audiobooks, 2016
L. Shifman, Memes in Digital Culture: Library Edition, Blackstone Audiobooks, 2016
2016
-
[8]
R. M. Milner, The World Made Meme: Public Conversations and Participatory Media, The MIT Press,
-
[9]
Spear.Building Ontologies with Basic Formal Ontology
URL: https://doi.org/10.7551/mitpress/9780262034999.001.0001. doi:10.7551/mitpress/ 9780262034999.001.0001
-
[10]
Posetti, N
J. Posetti, N. Shabbir, D. Maynard, K. Bontcheva, N. Aboulez, The Chilling: Global Trends in Online Violence against Women Journalists, Research Discussion Paper CI-2021/FEJ/PI/1, UNESCO, Paris, 2021. URL: https://unesdoc.unesco.org/ark:/48223/pf0000377223, international Center for Journalists and UNESCO
2021
-
[11]
Kiela, H
D. Kiela, H. Firooz, A. Mohan, V. Goswami, A. Singh, P. Ringshia, D. Testuggine, The hateful memes challenge: detecting hate speech in multimodal memes, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Curran Associates Inc., Red Hook, NY, USA, 2020
2020
-
[12]
Fersini, F
E. Fersini, F. Gasparini, G. Rizzi, A. Saibene, B. Chulvi, P. Rosso, A. Lees, J. Sorensen, SemEval-2022 task 5: Multimedia automatic misogyny identification, in: G. Emerson, N. Schluter, G. Stanovsky, R. Kumar, A. Palmer, N. Schneider, S. Singh, S. Ratan (Eds.), Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), Associat...
2022
-
[13]
Hakimov, G
S. Hakimov, G. S. Cheema, R. Ewerth, TIB-VA at SemEval-2022 task 5: A multimodal architecture for the detection and classification of misogynous memes, in: G. Emerson, N. Schluter, G. Stanovsky, R. Kumar, A. Palmer, N. Schneider, S. Singh, S. Ratan (Eds.), Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), Association fo...
2022
-
[14]
A. Arango, J. Perez-Martin, A. Labrada, HateU at SemEval-2022 task 5: Multimedia automatic misogyny identification, in: G. Emerson, N. Schluter, G. Stanovsky, R. Kumar, A. Palmer, N. Schnei- der, S. Singh, S. Ratan (Eds.), Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), Association for Computational Linguistics, Seatt...
-
[15]
F. J. Rodríguez-Sanchez, J. C. de Albornoz, L. Plaza, J. Gonzalo, P. Rosso, M. Comet, T. Donoso, Overview of exist 2021: sexism identification in social networks, Proces. del Leng. Natural 67 (2021) 195–207. URL: https://api.semanticscholar.org/CorpusID:250527210
2021
-
[16]
L. Plaza, J. Carrillo-de Albornoz, R. Morante, E. Amigó, J. Gonzalo, D. Spina, P. Rosso, Overview of exist 2023: sexism identification in social networks, in: Advances in Information Retrieval: 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April 2–6, 2023, Proceedings, Part III, Springer-Verlag, Berlin, Heidelberg, 2023, p...
-
[17]
L. Plaza, J. Carrillo-de Albornoz, R. Morante, E. Amigó, J. Gonzalo, D. Spina, P. Rosso, Overview of exist 2023 – learning with disagreement for sexism identification and characterization, in: Experimental IR Meets Multilinguality, Multimodality, and Interaction: 14th International Con- ference of the CLEF Association, CLEF 2023, Thessaloniki, Greece, Sep...
-
[18]
Plaza, J
L. Plaza, J. Carrillo-de Albornoz, V. Ruiz, A. Maeso, B. Chulvi, P. Rosso, E. Amigó, J. Gonzalo, R. Morante, D. Spina, Overview of exist 2024 — learning with disagreement for sexism identification and characterization in tweets and memes, in: L. Goeuriot, P. Mulhem, G. Quénot, D. Schwab, G. M. Di Nunzio, L. Soulier, P. Galuščáková, A. García Seco de Herre...
2024
-
[19]
L. Plaza, J. Carrillo-de Albornoz, I. Arcos, P. Rosso, D. Spina, E. Amigó, J. Gonzalo, R. Morante, Overview of exist 2025: Learning with disagreement for sexism identification and characterization in tweets, memes, and tiktok videos, in: Experimental IR Meets Multilinguality, Multimodality, and Interaction: 16th International Conference of the CLEF Associ...
-
[20]
Plaza, J
L. Plaza, J. Carrillo-de Albornoz, I. Arcos, M. Aloy-Mayo, E. Gomis-Vicent, P. Rosso, E. García-Arias, D. Spina, Overview of exist 2026: Physiological data for multimodal sexism characterization in social media. experimental ir meets multilinguality, multimodality, and interaction, in: Proceedings of the Seventeenth International Conference of the CLEF As...
2026
-
[21]
Fersini, D
E. Fersini, D. Nozza, P. Rosso, Overview of the evalita 2018 task on automatic misogyny identifica- tion (ami), in: EVALITA@CLiC-it, 2018. URL: https://api.semanticscholar.org/CorpusID:56483156
2018
-
[22]
V. Basile, C. Bosco, E. Fersini, D. Nozza, V. Patti, F. M. Rangel Pardo, P. Rosso, M. Sanguinetti, SemEval-2019 task 5: Multilingual detection of hate speech against immigrants and women in Twit- ter, in: J. May, E. Shutova, A. Herbelot, X. Zhu, M. Apidianaki, S. M. Mohammad (Eds.), Proceedings of the 13th International Workshop on Semantic Evaluation, As...
-
[23]
Plaza, J
L. Plaza, J. Carrillo-de Albornoz, I. Arcos, M. Aloy-Mayo, E. Gomis-Vicent, P. Rosso, E. García-Arias, D. Spina, Overview of exist 2026: Physiological data for multimodal sexism characterization in social media (extended overview), in: E. Sánchez Salido, A. Barrón-Cedeño, A. G. Seco de Herrera, S. MacAvaney, J. M. Struß (Eds.), CLEF 2026 Working Notes, 2026
2026
-
[24]
Suryawanshi, B
S. Suryawanshi, B. R. Chakravarthi, M. Arcan, P. Buitelaar, Multimodal meme dataset (MultiOFF) for identifying offensive content in image and text, in: R. Kumar, A. K. Ojha, B. Lahiri, M. Zampieri, S. Malmasi, V. Murdock, D. Kadar (Eds.), Proceedings of the Second Workshop on Trolling, Ag- gression and Cyberbullying, European Language Resources Associatio...
2020
-
[26]
Huang, J., Cui, L., Wang, A., Yang, C., Liao, X., Song, L., Yao, J., and Su, J
S. Pramanick, S. Sharma, D. Dimitrov, M. S. Akhtar, P. Nakov, T. Chakraborty, MOMENTA: A multimodal framework for detecting harmful memes and their targets, in: M.-F. Moens, X. Huang, L. Specia, S. W.-t. Yih (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2021, Association for Computational Linguistics, Punta Cana, Dominican Repub...
-
[27]
Arcos, P
I. Arcos, P. Rosso, Sexism identification on tiktok: A multimodal ai approach with text, audio, and video, in: L. Goeuriot, P. Mulhem, G. Quénot, D. Schwab, G. M. Di Nunzio, L. Soulier, P. Galuščáková, A. García Seco de Herrera, G. Faggioli, N. Ferro (Eds.), Experimental IR Meets Multilinguality, Multimodality, and Interaction, Springer Nature Switzerland...
2024
-
[28]
L. D. Grazia, P. Pastells, M. V. Chas, D. Elliott, D. S. Villegas, M. Farrús, M. T. Delor, Mused: A multimodal spanish dataset for sexism detection in social media videos, in: Second Conference on Language Modeling, 2025. URL: https://openreview.net/forum?id=eSAv7GKVFt
2025
-
[29]
P. Italiani, D. Gimeno-Gómez, L. Ragazzi, G. Moro, P. Rosso, MemeWeaver: Inter-meme graph reasoning for sexism and misogyny detection, in: V. Demberg, K. Inui, L. Marquez (Eds.), Findings of the Association for Computational Linguistics: EACL 2026, Association for Computational Linguistics, Rabat, Morocco, 2026, pp. 2120–2134. URL: https://aclanthology.or...
-
[30]
A. N. Uma, T. Fornaciari, D. Hovy, S. Paun, B. Plank, M. Poesio, Learning from disagreement: A survey, J. Artif. Int. Res. 72 (2022) 1385–1470. URL: https://doi.org/10.1613/jair.1.12752. doi: 10. 1613/jair.1.12752
-
[31]
A. Mostafazadeh Davani, M. Díaz, V. Prabhakaran, Dealing with disagreements: Looking beyond the majority vote in subjective annotations, Transactions of the Association for Computational Linguistics 10 (2022) 92–110. URL: https://aclanthology.org/2022.tacl-1.6/. doi:10.1162/tacl_a_ 00449
-
[32]
S. Frenda, G. Abercrombie, V. Basile, A. Pedrani, R. Panizzon, A. T. Cignarella, C. Marco, D. Bernardi, Perspectivist approaches to natural language processing: a survey, Lang. Re- sour. Eval. 59 (2024) 1719–1746. URL: https://doi.org/10.1007/s10579-024-09766-4. doi: 10.1007/ s10579-024-09766-4
-
[33]
E. Leonardelli, S. Casola, S. Peng, G. Rizzi, V. Basile, E. Fersini, D. Frassinelli, H. Jang, M. Pavlovic, B. Plank, M. Poesio, LeWiDi-2025 at NLPerspectives: Third edition of the learning with disagree- ments shared task, in: G. Abercrombie, V. Basile, S. Frenda, S. Tonelli, S. Dudy (Eds.), Proceedings of the The 4th Workshop on Perspectivist Approaches ...
-
[34]
Amigo, A
E. Amigo, A. Delgado, Evaluating extreme hierarchical multi-label classification, in: S. Muresan, P. Nakov, A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 5809–5819. URL: https://aclanthology.org/...
2022
-
[35]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever, Learning transferable visual models from natural language supervision, 2021. URL: https://arxiv.org/abs/2103.00020.arXiv:2103.00020
Pith/arXiv arXiv 2021
-
[36]
J. Li, D. Li, C. Xiong, S. Hoi, BLIP: Bootstrapping language-image pre-training for unified vision- language understanding and generation, in: K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, S. Sabato (Eds.), Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, PMLR, 2022, p...
2022
-
[37]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, V. Stoyanov, Unsupervised cross-lingual representation learning at scale, in: D. Jurafsky, J. Chai, N. Schluter, J. Tetreault (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computation...
-
[38]
Team, Qwen2.5: A party of foundation models, 2024
Q. Team, Qwen2.5: A party of foundation models, 2024. URL: https://qwenlm.github.io/blog/qwen2. 5/
2024
-
[39]
N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, 2019. URL: http://arxiv.org/abs/1908.10084
Pith/arXiv arXiv 2019
-
[40]
McFee, C
B. McFee, C. Raffel, D. Liang, D. P. W. Ellis, M. McVicar, E. Battenberg, O. Nieto, librosa: Audio and music signal analysis in python, in: SciPy, 2015. URL: https://api.semanticscholar.org/CorpusID: 33504
2015
-
[41]
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, I. Sutskever, Robust speech recognition via large-scale weak supervision, 2022. URL: https://arxiv.org/abs/2212.04356. doi: 10.48550/ ARXIV.2212.04356
Pith/arXiv arXiv 2022
-
[42]
Akiba, S
T. Akiba, S. Sano, T. Yanase, T. Ohta, M. Koyama, Optuna: A next-generation hyperparameter optimization framework, in: The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019, pp. 2623–2631. A. LLM Prompting Templates In this appendix, we provide the exact prompts used to query the Large Language Models for extracting struc...
2019
-
[43]
Considering both the image and the text, is there irony, sarcasm, or a joke? (1 for Yes, 0 for No)
-
[44]
Is there an insult, curse word, or derogatory language directed specifically at a man/boy? (1 for Yes, 0 for No)
-
[45]
No other words
Does the meme contain traditional stereotypes about women (e.g., kitchen, driving, emotional)? (1 for Yes, 0 for No) Output ONLY the three digits separated by commas. No other words. A.2. Comprehensive 10-Feature Taxonomy Prompt This prompt was utilized in the advanced experiments (e.g., E7) to force the LLM to evaluate the input across all fine-grained t...
-
[46]
IRONY: Is there irony, sarcasm, or a joke? (1 for Yes, 0 for No)
-
[47]
MALE INSULT: Is there an insult or derogatory language directed specifically at a man/boy? (1 for Yes, 0 for No)
-
[48]
CONTRADICTION: Is there a contrast or contradiction between the neutral text and the visual that creates a sexist joke? (1/Yes, 0/No)
-
[49]
DIRECT: Is the intention to write a message that is sexist by itself or incites to be sexist? (1 for Yes, 0 for No)
-
[50]
JUDGEMENTAL: Is the intention to judge, describing sexist situations or behaviours with the aim of condemning them? (1 for Yes, 0 for No)
-
[51]
IDEOLOGICAL AND INEQUALITY: Does the meme discredit the feminist movement, reject inequality between men and women, or present men as victims of gender-based oppression? (1 for Yes, 0 for No)
-
[54]
SEXUAL VIOLENCE: Are there sexual suggestions, requests for sexual favors, or harassment of a sexual nature? (1 for Yes, 0 for No)
-
[55]
The Holy Trinity
MISOGYNY AND NON-SEXUAL VIOLENCE: Does the meme express hatred and non-sexual violence towards women? (1 for Yes, 0 for No) Output ONLY the ten digits separated by commas. No other words. A.3. Targeted Fine-Grained Prompt ("The Holy Trinity") This streamlined prompt focuses exclusively on the most critical and frequently overlapping fine-grained categorie...
-
[56]
STEREOTYPING AND DOMINANCE: Does the meme express false ideas suggesting women are more suitable for certain roles (mother, submissive, etc.), inappropriate for certain tasks (driving, etc.), or claim men are superior? (1 for Yes, 0 for No)
-
[57]
OBJECTIFICATION: Does the meme present women as objects, focus on compliance with beauty standards, hypersexualize female attributes, or put women’s bodies at the disposal of men? (1 for Yes, 0 for No)
-
[58]
No other words
MISOGYNY AND NON-SEXUAL VIOLENCE: Does the meme express hatred and non-sexual violence towards women? (1 for Yes, 0 for No) Output ONLY the three digits separated by commas. No other words. B. Use of AI tools declaration AI tools were used for manuscript polishing, clarity enhancement and typo/grammar/syntax fixing
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.