Agentic Persona Generation with Critique-Refinement: An Industrial Evaluation
Pith reviewed 2026-06-27 15:19 UTC · model grok-4.3
The pith
PerGent generates personas via an iterative LLM critique-refinement loop that reaches 96.9% expert approval in an industrial test.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
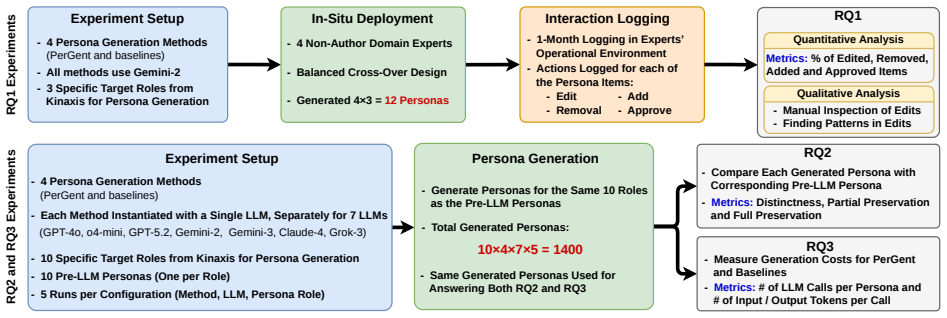
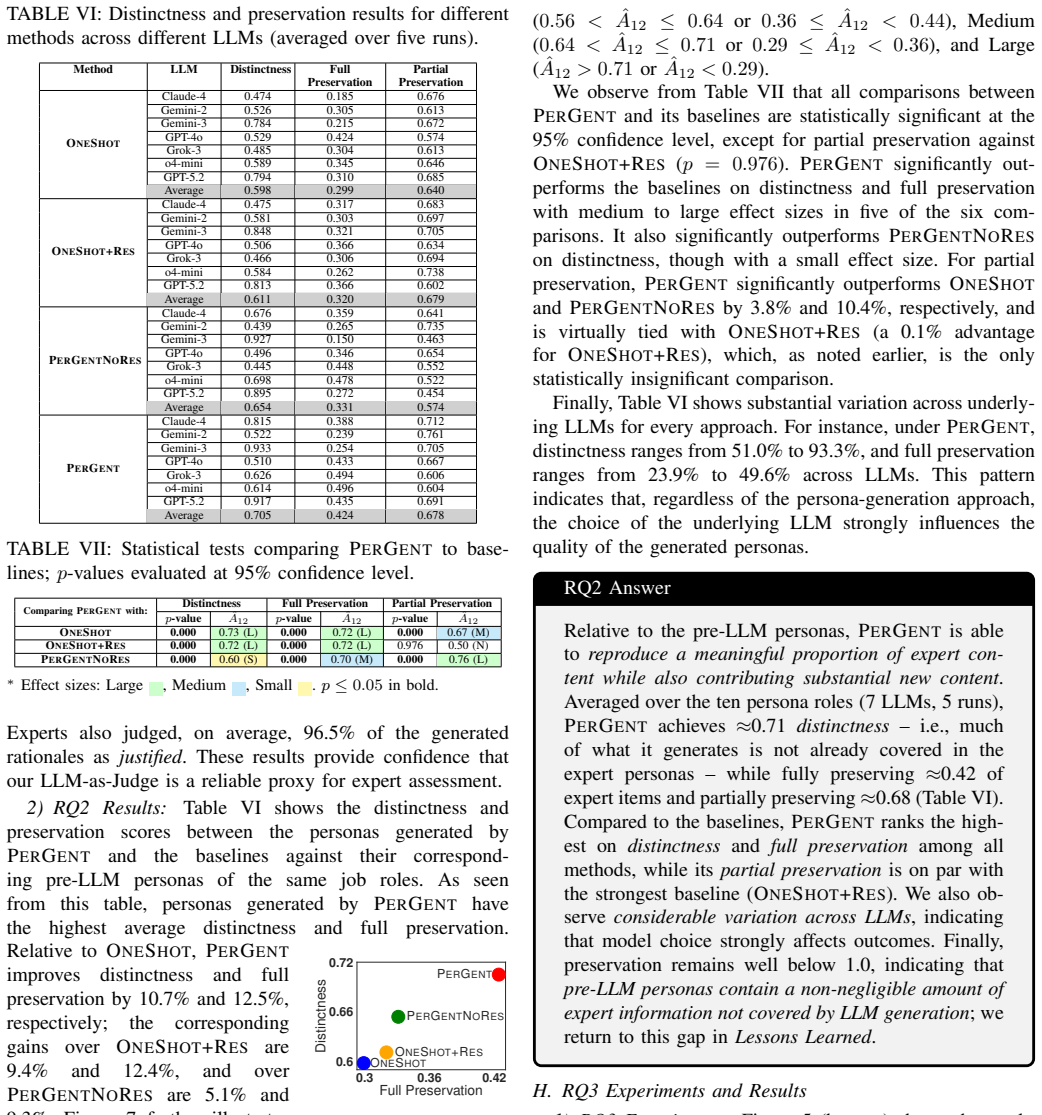
PerGent, an industry-grade method for persona generation built around an iterative critique-refinement loop, uses a generator and a critic LLM agent coordinated by an orchestrator to refine personas from external resources such as interviews, surveys, and job postings through a user-defined maximum number of rounds. In an expert in-situ evaluation at Kinaxis, PerGent achieved the highest expert approval rate of 96.9 percent, exceeding all baselines. Compared to baselines, PerGent reproduces a larger proportion of expert content while also contributing substantial new content beyond the pre-LLM personas.
What carries the argument
The critique-refinement loop in which a generator LLM produces personas and a critic LLM evaluates them against provided data sources, coordinated by an orchestrator for iterative passes up to a maximum round limit.
If this is right
- PerGent exceeds all one-shot baselines in expert approval rate during in-situ evaluation.
- PerGent reproduces a larger proportion of content from pre-existing expert personas than the baselines.
- PerGent contributes substantial new content not found in pre-LLM expert personas.
- The method supports deployment and evaluation inside an active industrial context such as Kinaxis.
Where Pith is reading between the lines
- If the iterative loop drives the gains, single-shot LLM methods may consistently miss nuanced details that multiple critique passes can capture.
- The same generator-critic structure could be tested on related artifacts such as user stories or acceptance criteria.
- Lessons from the Kinaxis deployment could inform how teams set round limits or select data sources when adapting the method elsewhere.
Load-bearing premise
Expert approval rates from a single-company in-situ setting provide an unbiased and generalizable measure of persona quality.
What would settle it
A replication study at a different company with independent experts that finds PerGent's approval rate falls below one or more one-shot baselines.
Figures




read the original abstract
Personas are widely used in software engineering to support requirements elicitation, design, and validation, but their manual creation is costly, time-consuming, and hard to scale. Recent LLM-based approaches automate persona generation from textual data; however, they typically rely on single-shot generation and subjective evaluations, limiting practical reliability. We present PerGent, an industry-grade method for persona generation built around an iterative critique-refinement loop. Specifically, PerGent uses a generator and a critic LLM agent, coordinated by an orchestrator, to iteratively refine personas using external resources such as interviews, surveys, and job postings through a critique-refinement loop with a user-defined maximum number of rounds. We deploy and evaluate PerGent in an industrial setting at Kinaxis, comparing it with three baselines, including one-shot methods. In an expert in-situ evaluation, PerGent achieved the highest expert approval rate (96.9%), exceeding all baselines. We further compare PerGent-generated personas with best-practice personas manually created by domain experts prior to the adoption of LLMs. Compared to baselines, PerGent reproduces a larger proportion of expert content while also contributing substantial new content beyond the pre-LLM personas. We conclude with lessons learned from deploying and evaluating PerGent at Kinaxis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PerGent, an agentic persona generation method that uses a generator-critic LLM pair coordinated by an orchestrator in an iterative critique-refinement loop (with user-defined max rounds and external resources such as interviews and job postings). In an industrial deployment at Kinaxis, PerGent is compared to three baselines (including one-shot LLM methods) and to pre-LLM manually created expert personas; the central empirical claim is that PerGent attains a 96.9% expert approval rate (highest among methods) while reproducing a larger share of expert content and adding substantial new content.
Significance. If the evaluation results hold under more rigorous controls, the work supplies a rare industrial case study showing that multi-agent iterative refinement can outperform single-shot LLM generation for a practically important SE artifact. The explicit comparison against pre-LLM expert personas provides independent grounding that is uncommon in LLM persona papers and strengthens the practical relevance of the findings.
major comments (1)
- [Abstract and Evaluation section] Abstract and Evaluation section: the central superiority claim rests on the reported 96.9% expert approval rate and the reproduction metric versus pre-LLM personas, yet the manuscript supplies no information on the number of experts, blinding procedures, inter-rater agreement, or how familiarity with the iterative Kinaxis context was controlled. These omissions are load-bearing because the evaluation is in-situ and the iterative loop is unique to PerGent.
minor comments (1)
- [Method section] The description of how external resources are ingested and how the orchestrator decides termination could be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation methodology. We agree that additional details are needed to support the reported results and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the central superiority claim rests on the reported 96.9% expert approval rate and the reproduction metric versus pre-LLM personas, yet the manuscript supplies no information on the number of experts, blinding procedures, inter-rater agreement, or how familiarity with the iterative Kinaxis context was controlled. These omissions are load-bearing because the evaluation is in-situ and the iterative loop is unique to PerGent.
Authors: We agree that the manuscript omits key details on the evaluation procedure. In the revised version we will expand the Evaluation section with a dedicated paragraph reporting the exact number of experts who performed the approval ratings, any blinding procedures employed, inter-rater agreement statistics, and how experts' familiarity with the Kinaxis context was handled. Because the study is an in-situ industrial deployment, complete blinding to the generation method was not feasible; we will explicitly note this limitation and describe the mitigation steps taken. These additions will allow readers to assess the strength of the 96.9% approval claim and the pre-LLM persona comparison. revision: yes
Circularity Check
No circularity; claims rest on external expert judgments and pre-LLM baselines
full rationale
The paper presents an industrial evaluation of PerGent using expert approval rates (96.9%) collected in-situ at Kinaxis and direct comparisons to independently created pre-LLM personas. These metrics are external to the generation process and not reduced to fitted parameters, self-definitions, or self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked; the central claims are grounded in independent human assessment rather than internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert in-situ approval rates constitute a reliable and unbiased proxy for persona quality and utility.
Reference graph
Works this paper leans on
-
[1]
Personacraft: Leveraging language models for data-driven persona development,
S. Jung, J. Salminen, K. K. Aldous, and B. J. Jansen, “Personacraft: Leveraging language models for data-driven persona development,” International Journal of Human-Computer Studies, vol. 197, p. 103445,
-
[2]
Available: https://doi.org/10.1016/j.ijhcs.2025.103445
[Online]. Available: https://doi.org/10.1016/j.ijhcs.2025.103445
-
[3]
J. Salminen, C. Liu, W. Pian, J. Chi, E. H ¨ayh¨anen, and B. J. Jansen, “Deus ex machina and personas from large language models: Investigating the composition of AI-generated persona descriptions,” inProceedings of the CHI Conference on Human Factors in Computing Systems, 2024. [Online]. Available: https: //doi.org/10.1145/3613904.3642036
-
[4]
Who uses personas in requirements engineering: The practitioners’ perspective,
Y . Wang, C. Arora, X. Liu, T. Hoang, V . Malhotra, B. Cheng, and J. C. Grundy, “Who uses personas in requirements engineering: The practitioners’ perspective,”Information and Software Technology, vol. 178, p. 107609, 2025. [Online]. Available: https://doi.org/10.1016/j. infsof.2024.107609
doi:10.1016/j 2025
-
[5]
Personagen: A tool for generating personas from user feedback,
X. Zhang, L. Liu, Y . Wang, X. Liu, H. Wang, A. Ren, and C. Arora, “Personagen: A tool for generating personas from user feedback,” inProceedings of 31st IEEE International Requirements Engineering Conference (RE’23), 2023, pp. 353–354. [Online]. Available: https://doi.org/10.1109/RE57278.2023.00048
-
[6]
Cooper,The Inmates Are Running the Asylum: Why High-Tech Products Drive Us Crazy and How to Restore the Sanity
A. Cooper,The Inmates Are Running the Asylum: Why High-Tech Products Drive Us Crazy and How to Restore the Sanity. Sams Publishing, 1999
1999
-
[7]
Understanding human-AI workflows for generating personas,
J. Shin, M. A. Hedderich, B. J. Rey, A. Lucero, and A. Oulasvirta, “Understanding human-AI workflows for generating personas,” in Proceedings of the 2024 ACM Designing Interactive Systems Conference, 2024, pp. 757–781. [Online]. Available: https://doi.org/10. 1145/3643834.3660729
arXiv 2024
-
[8]
Imaginary people representing real numbers: Generating personas from online social media data,
J. An, H. Kwak, S.-G. Jung, J. Salminen, M. Ahmad, and B. J. Jansen, “Imaginary people representing real numbers: Generating personas from online social media data,”ACM Transactions on the Web, vol. 12, no. 4, 2018. [Online]. Available: https://doi.org/10.1145/3265986
doi:10.1145/3265986 2018
-
[9]
From flat file to interface: Synthesis of personas and analytics for enhanced user understanding,
B. J. Jansen, S. Jung, and J. Salminen, “From flat file to interface: Synthesis of personas and analytics for enhanced user understanding,”Proceedings of the Association for Information Science and Technology, vol. 57, no. 1, 2020. [Online]. Available: https://doi.org/10.1002/pra2.215
doi:10.1002/pra2.215 2020
-
[10]
Automatic persona generation (apg): A rationale and demonstration,
S. Jung, J. Salminen, H. Kwak, J. An, and B. J. Jansen, “Automatic persona generation (apg): A rationale and demonstration,” inExtended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, 2018, p. 321–324. [Online]. Available: https://doi.org/10.1145/3176349.3176893
-
[11]
Generating personas using LLMs and assessing their viability,
A. Schuller, D. Janssen, J. Blumenr ¨other, T. M. Probst, M. Schmidt, and C. Kumar, “Generating personas using LLMs and assessing their viability,” inExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024. [Online]. Available: https://doi.org/10.1145/3613905.3650860
-
[12]
RepairAgent: An autonomous, LLM-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “RepairAgent: An autonomous, LLM-based agent for program repair,” in Proceedings of 47th IEEE/ACM International Conference on Software Engineering (ICSE’25), 2025, p. 2188–2200. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00157
-
[13]
An LLM-based agent-oriented approach for automated code design issue localization,
F. Batole, D. O’Brien, T. N. Nguyen, R. Dyer, and H. Rajan, “An LLM-based agent-oriented approach for automated code design issue localization,” inProceedings of 47th IEEE/ACM International Conference on Software Engineering (ICSE’25), 2025, pp. 1320–1332. [Online]. Available: https://doi.org/10.1109/ICSE55347.2025.00100
-
[14]
Advanced smart contract vulnerability detection via LLM-powered multi-agent systems,
S. Cheng, Y . Duan, Y . Li, L. Chen, Y . Xiao, Q. Li, L. Lin, Y . Jiang, and J. Zhao, “Advanced smart contract vulnerability detection via LLM-powered multi-agent systems,”IEEE Transactions on Software Engineering, vol. 51, no. 10, pp. 2830–2846, 2025. [Online]. Available: https://doi.org/10.1109/TSE.2025.3597319
-
[15]
Exploring LLM-based agents for root cause analysis,
D. Roy, X. Zhang, R. Bhave, C. Bansal, P. Las-Casas, R. Fonseca, and S. Rajmohan, “Exploring LLM-based agents for root cause analysis,” in Companion Proceedings of the ACM on Software Engineering, 2024, pp. 656–660. [Online]. Available: https://doi.org/10.1145/3663529.3663841
-
[16]
P. Khamsepour, M. Cole, I. Ashraf, S. Puri, M. Sabetzadeh, and S. Nejati, “The impact of critique on LLM-based model generation from natural language: The case of activity diagrams,” arXiv preprint, vol. abs/2509.03463, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.03463
-
[17]
N. Ayoughi, D. Dewar, S. Nejati, and M. Sabetzadeh, “DSL or Code? Evaluating the quality of LLM-generated algebraic specifications: A case study in optimization at Kinaxis,” inProceedings of 48th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP’26), 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.00469
-
[18]
AutoGen: Enabling next-gen LLM applications via multi- agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi- agent conversation,” 2023, arXiv:2308.08155 [cs]. [Online]. Available: https://doi.org/10.48550/arXiv.2308.08155
-
[19]
Use of personas in requirements engineering: A systematic mapping study,
D. Karolita, J. McIntosh, T. Kanij, J. Grundy, and H. O. Obie, “Use of personas in requirements engineering: A systematic mapping study,” Information and Software Technology, vol. 162, p. 107264, 2023. [Online]. Available: https://doi.org/10.1016/j.infsof.2023.107264
-
[20]
What’s in a persona? A preliminary taxonomy from persona use in requirements engineering,
D. Karolita, J. Grundy, T. Kanij, H. Obie, and J. McIntosh, “What’s in a persona? A preliminary taxonomy from persona use in requirements engineering,” inProceedings of the 18th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE’23), 2023, pp. 39–51. [Online]. Available: https://doi.org/10.5220/0011708500003464
-
[21]
Agentic software engineering: Foundational pillars and a research roadmap,
A. E. Hassan, H. Li, D. Lin, B. Adams, T.-H. Chen, Y . Kashiwa, and D. Qiu, “Agentic software engineering: Foundational pillars and a research roadmap,”arXiv preprint, vol. 2509.06216, 2025, preprint. [Online]. Available: https://doi.org/10.48550/arXiv.2509.06216
-
[22]
Online repository for PerGent,
M. H. Amini, S. Nejati, and M. Sabetzadeh, “Online repository for PerGent,” https://github.com/M-H-Amini/PerGent, 2026
2026
-
[23]
Dated data: Tracing knowledge cutoffs in large language models,
J. Cheng, M. Marone, O. Weller, D. Lawrie, D. Khashabi, and B. Van Durme, “Dated data: Tracing knowledge cutoffs in large language models,”arXiv preprint arXiv:2403.12958, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2403.12958
-
[24]
Judging LLM-as-a-judge with MT-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” inAdvances in Neural Information Processing Systems 36 (NeurIPS’23), vol. 36, 2023, pp. 46 595–46 623. [Online]. Available: https://doi.org/10.48550/arXiv.2306.05685
-
[25]
iKnow: An intent-guided chatbot for cloud operations with retrieval-augmented generation,
J. Huang, Y . Zhong, G. Yu, Z. Jiang, M. Yan, W. Luan, T. Yang, R. Ren, and M. R. Lyu, “iKnow: An intent-guided chatbot for cloud operations with retrieval-augmented generation,” inProceedings of 40th IEEE/ACM International Conference on Automated Software Engineering (ASE’25), 2025, pp. 958–970. [Online]. Available: https://doi.org/10.1109/ASE63991.2025.00084
-
[26]
Krippendorff,Content Analysis: An Introduction to Its Methodology, 4th ed
K. Krippendorff,Content Analysis: An Introduction to Its Methodology, 4th ed. SAGE Publications, 2018
2018
-
[27]
Wilcoxon signed-rank test,
D. Rey and M. Neuh ¨auser, “Wilcoxon signed-rank test,” inInternational Encyclopedia of Statistical Science, M. Lovric, Ed., 2011, pp. 1658–
2011
-
[28]
Available: https://doi.org/10.1007/978-3-642-04898-2 616
[Online]. Available: https://doi.org/10.1007/978-3-642-04898-2 616
-
[29]
A critique and improvement of the CL common language effect size statistics of McGraw and Wong,
A. Vargha and H. D. Delaney, “A critique and improvement of the CL common language effect size statistics of McGraw and Wong,”Journal of Educational and Behavioral Statistics, vol. 25, no. 2, pp. 101–132,
-
[30]
Available: https://doi.org/10.3102/10769986025002101
[Online]. Available: https://doi.org/10.3102/10769986025002101
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.