Steering Beyond the Support: Adversarial Training on Unsupervised Jailbroken Activation Simulation
Pith reviewed 2026-06-30 13:18 UTC · model grok-4.3
The pith
A bi-level adversarial training method simulates jailbroken activations via unsupervised latent directions to defend LLMs against unseen jailbreaks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a bi-level adversarial training framework for zero-shot jailbreak defense. In the inner step, we simulate diverse jail-broken activations by extrapolating from refusal-state harmful-request activations via unsupervised latent direction discovery, which expands the coverage of real jailbreak activation subspaces. In the outer step, we train a potential-induced steering field to push these adversarial jailbroken states into refusal regions while keeping benign unchanged.
What carries the argument
Bi-level adversarial training framework whose inner loop performs unsupervised latent direction discovery to simulate jailbroken activations and whose outer loop optimizes a potential-induced steering field.
If this is right
- Attack success rates remain mostly below 5 percent across three LLMs and six classical jailbreak families.
- Subspace coverage of real jailbreak activations rises throughout training and correlates with improved generalization to unseen attacks.
- The steering field preserves benign utility while redirecting simulated adversarial states into refusal regions.
- The method operates without a static supervised training set of known jailbreaks.
Where Pith is reading between the lines
- If the overlap assumption holds for future jailbreaks, the framework could provide ongoing robustness as attack techniques evolve without retraining on each new variant.
- The emphasis on expanding activation subspace coverage suggests similar unsupervised simulation steps might strengthen other activation-based safety interventions.
- Testing the method on jailbreaks deliberately constructed to lie outside the discovered latent directions would directly probe the generalization boundary.
Load-bearing premise
The unsupervised latent directions discovered from refusal-state activations produce simulated jailbroken states whose distribution overlaps meaningfully with the subspaces of real unseen jailbreaks.
What would settle it
Measuring whether attack success rates stay below 5 percent on a fresh set of jailbreaks whose activation subspaces show no measurable overlap with the simulated directions generated during training.
Figures








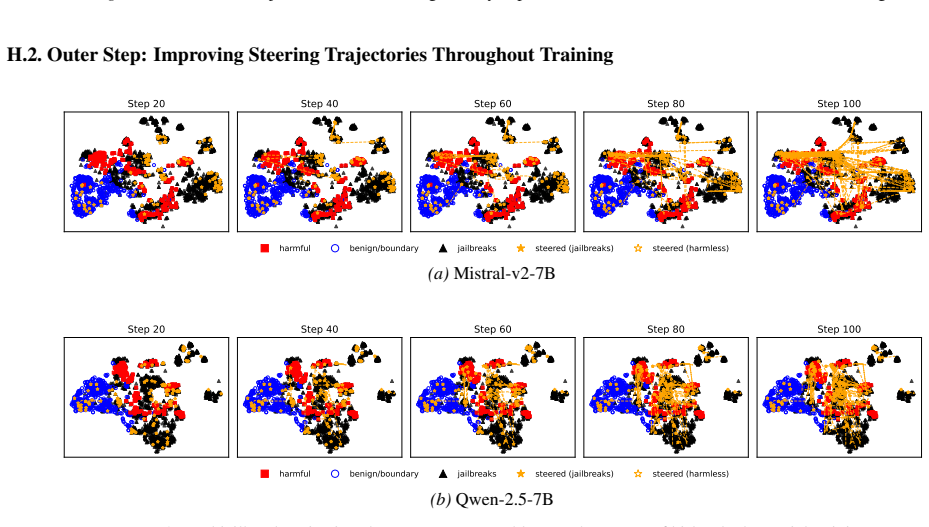

read the original abstract
Jailbreak prompts can trigger harmful completions on aligned LLMs, In accordance, safety steering has been proposed: test-time activation interventions that steer jailbreak activations to trigger refusal while preserving benign utility. However, existing steering methods are fundamentally supervised and tied to a static, limited training set, whereas real jailbreaks evolve and are often out-of-distributed from the training set, leading to failures on unseen attacks. In this paper, we tackle the failure on unseen jailbreaks problem, base on unsupervised latent direction discovery. We propose a bi-level adversarial training framework for zero-shot jailbreak defense. In the inner step, we simulate diverse jail-broken activations by extrapolating from refusal-state harmful-request activations via unsupervised latent direction discovery, which expands the coverage of real jailbreak activation subspaces. In the outer step, we train a potential-induced steering field to push these adversarial jailbroken states into refusal regions while keeping benign unchanged. Across three LLMs and six classical jailbreak families, our method achieves strong defense with attack success rates mostly below 5%, and rising subspace coverage throughout training helps explain the improved generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bi-level adversarial training framework for zero-shot jailbreak defense on aligned LLMs. The inner loop applies unsupervised latent direction discovery to refusal-state harmful-request activations in order to simulate diverse jailbroken activations that expand coverage of real jailbreak subspaces. The outer loop trains a potential-induced steering field that pushes these simulated states into refusal regions while preserving benign utility. The central empirical claim is that, across three LLMs and six classical jailbreak families, the resulting method yields attack success rates mostly below 5% and that the observed rise in subspace coverage during training accounts for the improved generalization to unseen attacks.
Significance. If the simulation step can be shown to produce activations whose distribution meaningfully intersects the subspaces of real out-of-distribution jailbreaks, the approach would constitute a meaningful step beyond supervised steering methods that remain tied to fixed training distributions. The bi-level structure and the explicit use of subspace-coverage monitoring as an explanatory diagnostic are potentially reusable ideas for activation-level robustness work.
major comments (2)
- [Abstract and §3] Abstract and §3 (inner-loop description): the central claim that the unsupervised extrapolation 'expands the coverage of real jailbreak activation subspaces' and thereby explains generalization requires direct evidence that the simulated points intersect the activation subspaces of held-out real jailbreaks from the six families. No subspace angles, projection norms, Wasserstein distances, or similar quantitative overlap metrics are reported between the simulated activations and real unseen jailbreak activations.
- [§4] §4 (Empirical Evaluation): the reported attack success rates 'mostly below 5%' are presented without quantitative baselines, ablation controls for the unsupervised discovery step, statistical significance tests, or error bars, making it impossible to assess whether the improvement is attributable to the proposed simulation rather than other factors.
minor comments (1)
- [Abstract] Abstract contains minor grammatical issues ('In accordance,' should be 'Accordingly,'; 'base on' should be 'based on').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our bi-level adversarial training framework for zero-shot jailbreak defense. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (inner-loop description): the central claim that the unsupervised extrapolation 'expands the coverage of real jailbreak activation subspaces' and thereby explains generalization requires direct evidence that the simulated points intersect the activation subspaces of held-out real jailbreaks from the six families. No subspace angles, projection norms, Wasserstein distances, or similar quantitative overlap metrics are reported between the simulated activations and real unseen jailbreak activations.
Authors: We agree that the manuscript's claim about expanded coverage would be strengthened by explicit quantitative overlap metrics between simulated activations and held-out real jailbreak activations. The current text reports rising subspace coverage as an internal diagnostic but does not include direct comparisons such as subspace angles, projection norms, or Wasserstein distances to unseen real jailbreaks. In revision we will add these metrics, computing for example average cosine similarities and projection norms between the unsupervised extrapolated directions and the leading principal components of held-out activations from each of the six families. revision: yes
-
Referee: [§4] §4 (Empirical Evaluation): the reported attack success rates 'mostly below 5%' are presented without quantitative baselines, ablation controls for the unsupervised discovery step, statistical significance tests, or error bars, making it impossible to assess whether the improvement is attributable to the proposed simulation rather than other factors.
Authors: The referee is correct that the empirical evaluation section lacks several standard elements needed to isolate the contribution of the unsupervised discovery step. The manuscript reports attack success rates without explicit baselines from prior methods, ablations of the inner loop, statistical significance tests, or error bars. We will revise §4 to include quantitative comparisons against supervised steering baselines, an ablation that disables the unsupervised extrapolation, results reported as means with standard deviations across multiple random seeds, and appropriate statistical tests. revision: yes
Circularity Check
Empirical bi-level framework with no definitional or self-citation circularity
full rationale
The paper describes an empirical adversarial training procedure: an inner unsupervised latent direction discovery step generates simulated jailbroken activations from refusal-state inputs, which are then used to train an outer potential-induced steering field. No equations, fitted parameters, or claims are shown to reduce the reported attack success rates or generalization to quantities defined by construction on the same data. Subspace coverage is presented as a post-hoc interpretive observation rather than a mathematical identity. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain remains self-contained against external benchmarks and does not collapse to input renaming or fitted-input-as-prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unsupervised latent direction discovery applied to refusal-state harmful-request activations yields simulated activations whose distribution overlaps with real unseen jailbreak activations.
invented entities (1)
-
potential-induced steering field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
OpenReview.net, 2025. URL https://openre view.net/forum?id=Oi47wc10sm. Li, X., Zhang, T., Dubois, Y ., Taori, R., Gulrajani, I., Guestrin, C., Liang, P., and Hashimoto, T. B. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_ eval, 5 2023. Lin, S., Hilton, J., and Evans, O. Truthfulqa: Measuring how mo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.0211 2025
-
[2]
URL https://doi.org/10.48550/arXiv.2 312.02119. OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., and Irving, G. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022. Qwen, :, Yang, A., Yang, B., Zhang, B., Hui,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2 2023
-
[3]
Gemma 2: Improving Open Language Models at a Practical Size
doi: 10.48550/ARXIV.2408.00118. URL https: //doi.org/10.48550/arXiv.2408.00118. Shairah, H. A., Hammoud, H. A. A. K., Turkiyyah, G., and Ghanem, B. Turning the spell around: Lightweight align- ment amplification via rank-one safety injection.arXiv preprint arXiv:2508.20766, 2025. Shen, G., Zhao, D., Dong, Y ., He, X., and Zeng, Y . Jailbreak antidote: Run...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00118 2025
-
[4]
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba
URL https://doi.org/10.48550/arXiv .2410.02298. Shen, G., Zhao, D., Dong, Y ., He, X., and Zeng, Y . Jailbreak antidote: Runtime safety-utility balance via sparse rep- resentation adjustment in large language models.arXiv preprint arXiv:2410.02298, 2024b. Sheng, L., Shen, C., Zhao, W., Fang, J., Liu, X., Liang, Z., Wang, X., Zhang, A., and Chua, T.-S. Alp...
work page internal anchor Pith review doi:10.48550/arxiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.