Unified MRI Brain Image Translation via Hierarchical Tumor Structure Comparison
Pith reviewed 2026-06-27 07:27 UTC · model grok-4.3
The pith
HTSCGAN translates multi-modal brain MRI by matching tumor structures across patch scales with contrast modules and pretrained losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
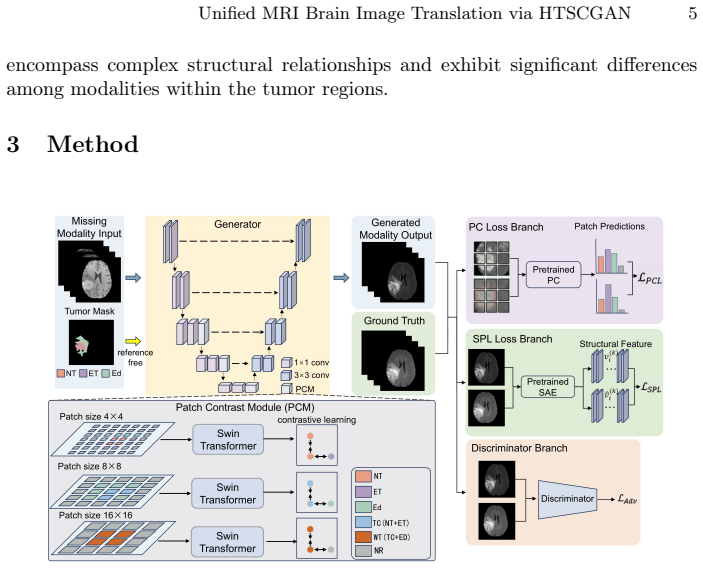
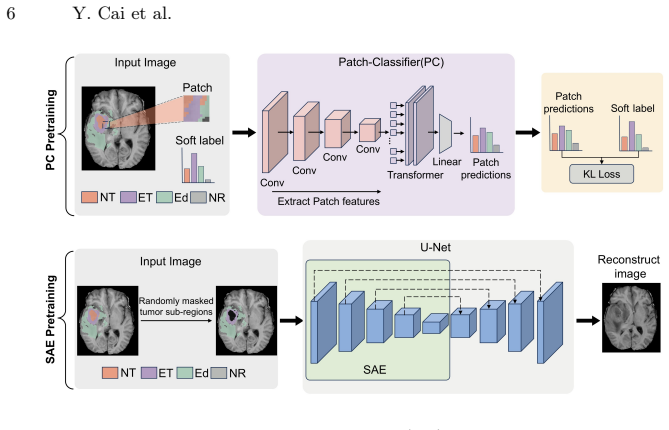
The generator in HTSCGAN employs three Patch Contrast Modules with different patch sizes to capture hierarchical tumor structure, while a pretrained Patch Classifier and a pretrained Structure-Aware Encoder supply patch classification loss and tumor perceptual loss that together enforce matching tumor region structure between generated and ground-truth images.
What carries the argument
Hierarchical tumor structure comparison realized through three Patch Contrast Modules of different sizes plus patch classification loss from a pretrained Patch Classifier and tumor perceptual loss from a pretrained Structure-Aware Encoder.
If this is right
- Translated images retain tumor region fidelity at multiple spatial scales.
- Downstream segmentation models achieve higher accuracy when trained or tested on the translated outputs.
- A single unified model handles multiple modality translation pairs without separate training for each pair.
- Clinical applicability improves because tumor boundaries remain consistent after translation.
Where Pith is reading between the lines
- The same patch-based structure losses could be applied to preserve other anatomical landmarks besides tumors.
- If the approach generalizes, it might reduce the number of physical MRI acquisitions needed for patients with limited scan time.
- The method supplies a concrete testbed for whether multi-scale contrastive signals can substitute for explicit segmentation supervision in image translation.
Load-bearing premise
The losses from the pretrained Patch Classifier and Structure-Aware Encoder will actually compel the generator to reproduce the ground-truth tumor structures at multiple scales.
What would settle it
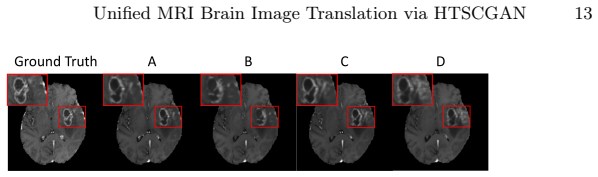
Run the same BraTS2020 and BraTS2021 translation and downstream segmentation experiments; if tumor segmentation Dice scores on HTSCGAN outputs are not higher than those from baseline translation models, the structural-matching claim fails.
Figures


read the original abstract
Multi-modal MRI brain image translation via available modalities holds significant practical importance in modern medicine, providing robust support for early diagnosis, treatment planning, and outcome assessment of diseases. For this purpose, it is important to ensure the fidelity of the tumor regions after translation. However, existing brain image translation methods ignore the structure information of different tumor regions, which could assist translation models in enhancing the quality and clinical applicability of the translated images. In this work, we propose a novel translation model called HTSCGAN, which is a unified multi-modal brain image translation generative adversarial model integrating the structural information within tumor regions with the aim of improving the quality of brain image translation. Specifically, the generator employs three Patch Contrast Module (PCM) with different patch sizes to capture the hierarchical structural information of the tumor regions. In addition, a pretrained Patch Classifier (PC) and a pretrained Structure-Aware Encoder (SAE) are employed to derive the generated image containing the same tumor region structure as the ground truth image via patch classification loss and tumor perceptual loss, respectively. The experiments on BraTS2020 and BraTS2021 demonstrate strong performance of our model in both translation tasks and down stream segmentation tasks, highlighting its effectiveness in enhancing the quality and clinical relevance of the translated brain images. Our code is available at https://anonymous.4open.science/r/HTSCGAN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HTSCGAN, a unified multi-modal brain image translation GAN that integrates hierarchical tumor structure information. The generator uses three Patch Contrast Modules (PCM) with different patch sizes to capture multi-scale tumor structure; a pretrained Patch Classifier (PC) applies patch classification loss and a pretrained Structure-Aware Encoder (SAE) applies tumor perceptual loss to enforce that generated images match ground-truth tumor region structure. Experiments on BraTS2020 and BraTS2021 are reported to show strong performance on both translation and downstream segmentation tasks.
Significance. If the PCMs combined with the pretrained PC/SAE losses demonstrably improve tumor-region fidelity over prior translation methods, the approach could enhance clinical utility of synthesized MRI images for diagnosis and treatment planning. Code availability is noted as a reproducibility strength.
major comments (2)
- [§3] §3 (Method description): The central premise that the patch classification loss from the pretrained PC and the tumor perceptual loss from the pretrained SAE will successfully constrain the generator (augmented by the three PCMs) to output images whose tumor regions match ground-truth structure at multiple scales is invoked without any analysis of pretraining domains, feature-space alignment, or sensitivity to subtle structural variations; this premise is load-bearing for the fidelity claim.
- [§4] §4 (Experiments): The manuscript asserts 'strong performance' on BraTS2020/2021 for translation and downstream segmentation but supplies no quantitative metrics, baseline comparisons, ablation results on the PCM/PC/SAE components, or implementation details, preventing verification of the claimed improvements.
minor comments (2)
- [Abstract and §3] The abstract and method sections use the term 'hierarchical structural information' without a precise definition or diagram clarifying how the three PCM patch sizes interact with the losses.
- The code link is given as anonymous; ensure the final version includes a permanent repository with full training details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will incorporate revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The central premise that the patch classification loss from the pretrained PC and the tumor perceptual loss from the pretrained SAE will successfully constrain the generator (augmented by the three PCMs) to output images whose tumor regions match ground-truth structure at multiple scales is invoked without any analysis of pretraining domains, feature-space alignment, or sensitivity to subtle structural variations; this premise is load-bearing for the fidelity claim.
Authors: We agree that the manuscript would benefit from explicit analysis of these aspects to support the load-bearing premise. In the revision we will add a dedicated paragraph (or subsection) detailing the pretraining datasets and domains for the PC and SAE, discussing feature-space alignment between the pretrained models and the generator, and reporting sensitivity experiments that vary tumor structural details (e.g., edema vs. enhancing tumor boundaries) to quantify robustness. revision: yes
-
Referee: [§4] §4 (Experiments): The manuscript asserts 'strong performance' on BraTS2020/2021 for translation and downstream segmentation but supplies no quantitative metrics, baseline comparisons, ablation results on the PCM/PC/SAE components, or implementation details, preventing verification of the claimed improvements.
Authors: We acknowledge that the current presentation of results is insufficient for verification. The full manuscript contains quantitative tables, baseline comparisons, and implementation details, but these will be expanded and reorganized in the revision: we will add explicit numerical results for translation metrics (e.g., PSNR, SSIM, FID) and downstream segmentation (Dice scores), include ablation tables isolating PCM, PC, and SAE contributions, provide all training hyperparameters and code references, and move any supplementary material into the main text or clearly labeled appendices. revision: yes
Circularity Check
No circularity detected; model is a new architectural construction
full rationale
The paper presents HTSCGAN as a novel GAN integrating PCM modules at multiple scales plus pretrained PC and SAE with patch classification and tumor perceptual losses. No equations, derivations, or predictions are shown that reduce claimed outputs to quantities defined by the authors' own fitted parameters or self-citations by construction. The central premise relies on empirical performance of the proposed components on BraTS datasets rather than any self-referential equivalence or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights on patch classification loss and tumor perceptual loss
axioms (2)
- domain assumption Standard conditional GAN training reaches a useful equilibrium for image translation
- domain assumption Pretrained patch classifier and structure-aware encoder remain reliable when applied to generated images from a different modality
invented entities (3)
-
Patch Contrast Module (PCM)
no independent evidence
-
Pretrained Patch Classifier (PC) used as loss
no independent evidence
-
Pretrained Structure-Aware Encoder (SAE) used as loss
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Elsevier Health Sciences (2020)
Adam, A., Dixon, A.K., Gillard, J.H., Schaefer-Prokop, C.: Grainger & Allison’s diagnostic radiology. Elsevier Health Sciences (2020)
2020
-
[2]
Computerized medical imaging and graphics79, 101684 (2020)
Armanious,K.,Jiang,C.,Fischer,M.,Küstner,T.,Hepp,T.,Nikolaou,K.,Gatidis, S., Yang, B.: Medgan: Medical image translation using gans. Computerized medical imaging and graphics79, 101684 (2020)
2020
-
[3]
Radiology: Artificial Intelligence 4(6), e220058 (2022) 14 Y
Calabrese, E., Villanueva-Meyer, J.E., Rudie, J.D., Rauschecker, A.M., Baid, U., Bakas, S., Cha, S., Mongan, J.T., Hess, C.P.: The university of california san francisco preoperative diffuse glioma mri dataset. Radiology: Artificial Intelligence 4(6), e220058 (2022) 14 Y. Cai et al
2022
-
[4]
Chartsias, A., Joyce, T., Giuffrida, M.V., Tsaftaris, S.A.: Multimodal mr synthesis viamodality-invariantlatentrepresentation.IEEEtransactionsonmedicalimaging 37(3), 803–814 (2017)
2017
-
[5]
IEEE Transactions on Medical Imaging41(10), 2598–2614 (2022)
Dalmaz, O., Yurt, M., Çukur, T.: Resvit: residual vision transformers for multi- modal medical image synthesis. IEEE Transactions on Medical Imaging41(10), 2598–2614 (2022)
2022
-
[6]
Urologic oncology31(3), 281 (2013)
Dickinson, L., Ahmed, H.U., Allen, C., Barentsz, J.O., Carey, B., Futterer, J.J., Heijmink, S.W., Hoskin, P., Kirkham, A.P., Padhani, A.R., et al.: Clinical ap- plications of multiparametric mri within the prostate cancer diagnostic pathway. Urologic oncology31(3), 281 (2013)
2013
-
[7]
arXiv preprint arXiv:2010.11929 (2020)
Dosovitskiy, A.: An image is worth 16x16 words: Transformers for image recogni- tion at scale. arXiv preprint arXiv:2010.11929 (2020)
Pith/arXiv arXiv 2010
-
[8]
arXiv preprint arXiv:2104.12753 (2021)
Gong, C., Wang, D., Li, M., Chandra, V., Liu, Q.: Vision transformers with patch diversification. arXiv preprint arXiv:2104.12753 (2021)
arXiv 2021
-
[9]
Communications of the ACM63(11), 139–144 (2020)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020)
2020
-
[10]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Han, L., Zhang, T., Huang, Y., Dou, H., Wang, X., Gao, Y., Lu, C., Tan, T., Mann, R.: An explainable deep framework: Towards task-specific fusion for multi- to-one mri synthesis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 45–55. Springer (2023)
2023
-
[11]
In: Medical Image Computing and Computer-Assisted Intervention– MICCAI 2016: 19th International Conference, Athens, Greece, October 17-21, 2016, Proceedings, Part II 19
Havaei, M., Guizard, N., Chapados, N., Bengio, Y.: Hemis: Hetero-modal image segmentation. In: Medical Image Computing and Computer-Assisted Intervention– MICCAI 2016: 19th International Conference, Athens, Greece, October 17-21, 2016, Proceedings, Part II 19. pp. 469–477. Springer (2016)
2016
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9729–9738 (2020)
2020
-
[14]
Medical image analysis35, 475–488 (2017)
Jog, A., Carass, A., Roy, S., Pham, D.L., Prince, J.L.: Random forest regression for magnetic resonance image synthesis. Medical image analysis35, 475–488 (2017)
2017
-
[15]
In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. pp. 694–711. Springer (2016)
2016
-
[16]
Pattern Recog- nition144, 109840 (2023)
Kang, M., Chikontwe, P., Won, D., Luna, M., Park, S.H.: Structure-preserving im- age translation for multi-source medical image domain adaptation. Pattern Recog- nition144, 109840 (2023)
2023
-
[17]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Kim, D., Al-masni, M.A., Lee, J., Kim, D.H., Ryu, K.: Improving pelvic mr-ct image alignment with self-supervised reference-augmented pseudo-ct generation framework. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 347–356. IEEE (2025)
2025
-
[18]
Sensors20(15), 4203 (2020)
Li, Q., Yu, Z., Wang, Y., Zheng, H.: Tumorgan: A multi-modal data augmentation framework for brain tumor segmentation. Sensors20(15), 4203 (2020)
2020
-
[19]
arXiv preprint arXiv:2603.12581 (2026) Unified MRI Brain Image Translation via HTSCGAN 15
Lin, J., Shen, Z., Cao, P., Yang, J., Zaiane, O.R., Liu, X.: Multiscale structure-guided latent diffusion for multimodal mri translation. arXiv preprint arXiv:2603.12581 (2026) Unified MRI Brain Image Translation via HTSCGAN 15
arXiv 2026
-
[20]
IEEE Transactions on Medical Imaging42(9), 2577–2591 (2023)
Liu, J., Pasumarthi, S., Duffy, B., Gong, E., Datta, K., Zaharchuk, G.: One model to synthesize them all: Multi-contrast multi-scale transformer for missing data imputation. IEEE Transactions on Medical Imaging42(9), 2577–2591 (2023)
2023
-
[21]
In: 2023 IEEE Symposium on Computers and Communications (ISCC)
Liu, Y., Zhong, S., Li, Z., Zhou, Y.: Contrastive learning with attention mechanism and multi-scale sample network for unpaired image-to-image translation. In: 2023 IEEE Symposium on Computers and Communications (ISCC). pp. 1335–1339. IEEE (2023)
2023
-
[22]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[23]
IEEE transactions on medical imaging 34(10), 1993–2024 (2014)
Menze, B.H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., Farahani, K., Kirby, J., Burren, Y., Porz, N., Slotboom, J., Wiest, R., et al.: The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging 34(10), 1993–2024 (2014)
1993
-
[24]
IEEE Transactions on Medical Imaging (2023)
Özbey, M., Dalmaz, O., Dar, S.U., Bedel, H.A., Özturk, Ş., Güngör, A., Çukur, T.: Unsupervised medical image translation with adversarial diffusion models. IEEE Transactions on Medical Imaging (2023)
2023
-
[25]
Neurocomputing538, 126211 (2023)
Ristea, N.C., Miron, A.I., Savencu, O., Georgescu, M.I., Verga, N., Khan, F.S., Ionescu, R.T.: Cytran: A cycle-consistent transformer with multi-level consistency for non-contrast to contrast ct translation. Neurocomputing538, 126211 (2023)
2023
-
[26]
In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, Oc- tober 5-9, 2015, proceedings, part III 18
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, Oc- tober 5-9, 2015, proceedings, part III 18. pp. 234–241. Springer (2015)
2015
-
[27]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 815–823 (2015)
2015
-
[28]
Sharma,A.,Hamarneh,G.:Missingmripulsesequencesynthesisusingmulti-modal generativeadversarialnetwork.IEEEtransactionsonmedicalimaging39(4),1170– 1183 (2019)
2019
-
[29]
Topics in Magnetic Resonance Imaging21(2), 129–138 (2010)
Wu, O., Dijkhuizen, R.M., Sorensen, A.G.: Multiparametric magnetic resonance imaging of brain disorders. Topics in Magnetic Resonance Imaging21(2), 129–138 (2010)
2010
-
[30]
Xie, Y., Zhang, J., Shen, C., Xia, Y.: Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation. In: Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part III 24. pp. 171–180. Springer (2021)
2021
-
[31]
IEEE transactions on medical imaging39(7), 2339–2350 (2020)
Yu, B., Zhou, L., Wang, L., Shi, Y., Fripp, J., Bourgeat, P.: Sample-adaptive gans: linking global and local mappings for cross-modality mr image synthesis. IEEE transactions on medical imaging39(7), 2339–2350 (2020)
2020
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhan, C., Lin, Y., Wang, G., Wang, H., Wu, J.: Medm2g: Unifying medical multi- modal generation via cross-guided diffusion with visual invariant. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11502–11512 (2024)
2024
-
[33]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.