DeFAb: A Verifiable Benchmark for Defeasible Abduction in Foundation Models
Pith reviewed 2026-06-26 21:25 UTC · model grok-4.3
The pith
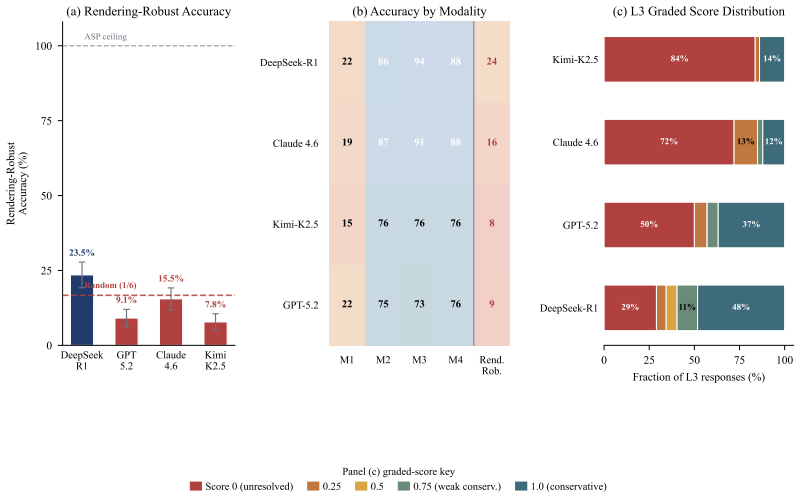
Frontier models reach at most 23.5% on a verifiable benchmark for defeasible abduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DeFAb converts four decades of publicly funded knowledge bases into 372,648+ instances across three difficulty levels, each backed by a gold-standard hypothesis that satisfies formal derivation, conservativity, and minimality checks. Four frontier models fail to internalize defeasible reasoning reliably: rendering-robust Level 2 accuracy sits between 7.8% and 23.5%, chain-of-thought prompting produces larger swings than inter-model differences, and a matched contamination control isolates a 19.4-point performance gap at Level 3. The same verification machinery also supports exact rewards for preference optimization and supplies harder variants including DeFAb-Hard and a Lean 4 kernel-verifie
What carries the argument
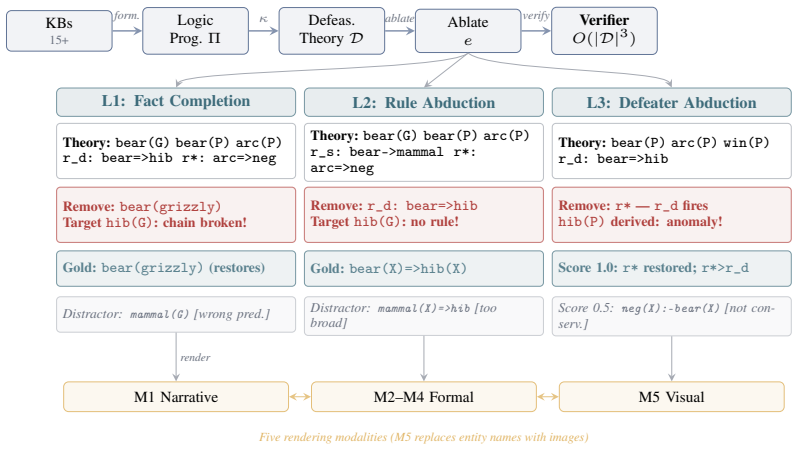
The DeFAb generation pipeline that pairs taxonomic hierarchies with behavioral property graphs to produce instances whose gold-standard answers are verified by polynomial-time checks for valid derivation, conservativity, and minimality.
If this is right
- Frontier models do not reliably internalize defeasible reasoning.
- Chain-of-thought prompting creates performance variance larger than differences among the tested models.
- Data contamination produces measurable score inflation on higher-difficulty levels.
- Symbolic solvers outperform all tested models by a wide margin on every instance.
- The released variants supply controlled tests for harder abduction cases and novel concept invention.
Where Pith is reading between the lines
- The benchmark supplies an exact, judge-free reward signal that can be used directly in preference optimization loops.
- Low performance points to a possible limit in how current training regimes capture non-monotonic theory revision.
- The pipeline could be extended to other non-monotonic reasoning tasks by swapping in additional knowledge bases.
- Public release of the full set of materialized rules enables community auditing for hidden artifacts.
Load-bearing premise
The pipeline that converts taxonomic hierarchies and behavioral property graphs into instances produces test cases whose gold-standard answers correctly measure the ability to perform defeasible abduction rather than testing surface-form sensitivity or dataset artifacts.
What would settle it
A frontier model achieving consistent rendering-robust accuracy above 50% on Level 2 instances with no detectable contamination would directly contradict the reported performance gap.
Figures



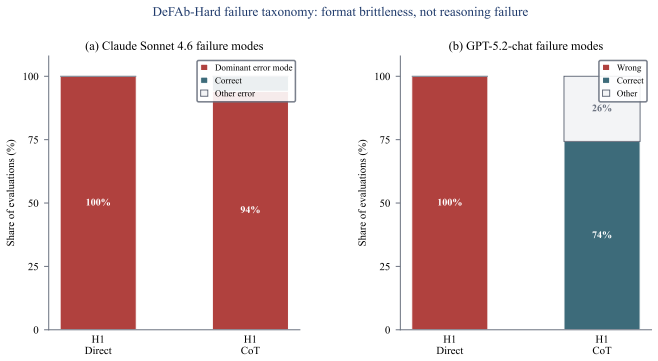


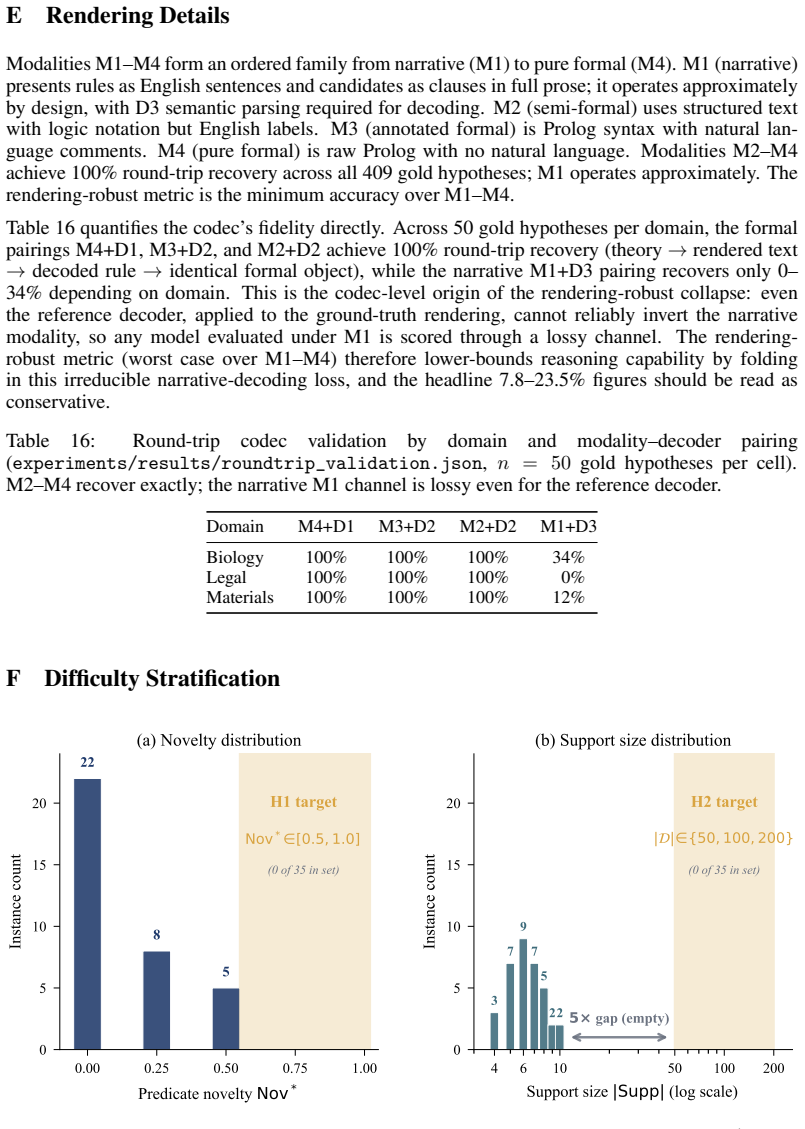




read the original abstract
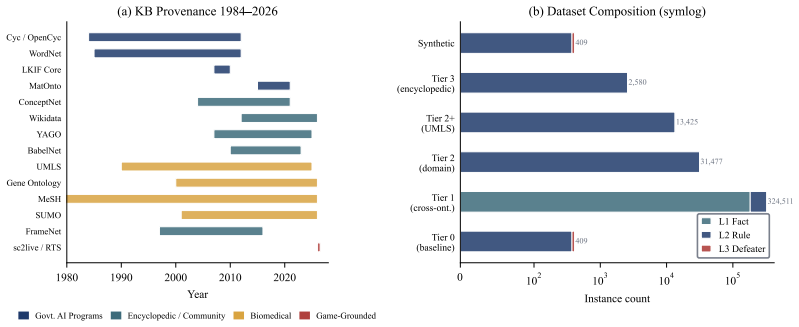
A rule-based logic solver resolves every instance in our benchmark in under 50 microseconds with 100% accuracy; the best frontier language model reaches 65% at best and drops to 23.5% under rendering-robust evaluation (worst case over four surface renderings). We introduce DeFAb (Defeasible Abduction Benchmark), a dataset and generation pipeline that converts four decades of publicly funded knowledge bases into formally grounded instances for defeasible abduction: constructing hypotheses that explain anomalies by overriding defaults while preserving unrelated expectations. Because every hypothesis must pass polynomial-time checks for valid derivation, conservativity, and minimality, DeFAb makes logical rigor the instrument for measuring creativity and theoretical reasoning, scoring the disciplined construction of theory revisions rather than fluent but theory-destroying prose. The pipeline pairs taxonomic hierarchies (OpenCyc, YAGO, Wikidata) with behavioral property graphs (ConceptNet, UMLS) to produce 372,648+ instances across 33.75M materialized rules from 18 sources, in three levels with polynomial-time verifiable gold standards. Four frontier models do not reliably internalize defeasible reasoning: rendering-robust Level 2 accuracy is 7.8-23.5%; chain-of-thought variance (~36 pp) exceeds any inter-model gap; and a matched contamination control isolates a +19.4 pp Level 3 gap. We further release DeFAb-Hard (a 235-instance Level 3 difficulty variant; best model 53.3% vs 100% symbolic) and CONJURE (a kernel-verified transformative-creativity variant of 560 Lean 4/Mathlib instances whose gold answers are definitions the proof kernel did not previously contain, judge-free verifier; a pilot finds zero novel concepts). The same verifier doubles as an exact reward for preference optimization (DPO, RLVR/GRPO). Released under MIT at https://huggingface.co/datasets/PatrickAllenCooper/DeFAb.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeFAb, a benchmark and generation pipeline that converts taxonomic hierarchies (OpenCyc/YAGO/Wikidata) and behavioral property graphs (ConceptNet/UMLS) into 372k+ instances of defeasible abduction problems. A rule-based symbolic solver achieves 100% accuracy on all instances via polynomial checks for valid derivation, conservativity, and minimality; four frontier models reach at most 65% (dropping to 7.8-23.5% under rendering-robust evaluation), with CoT variance of ~36 pp exceeding inter-model gaps and a matched contamination control isolating a +19.4 pp Level 3 gap. Additional releases include DeFAb-Hard (235 instances) and CONJURE (560 Lean 4/Mathlib instances with kernel-verified novel definitions).
Significance. If the pipeline produces instances that genuinely isolate defeasible abduction, the work supplies a large-scale, formally verifiable benchmark with an exact symbolic baseline and reusable verifier, enabling reproducible measurement of conservative hypothesis construction in LLMs and supporting downstream uses such as DPO/RLVR rewards. The explicit release of datasets, contamination controls, and a judge-free verifier constitute concrete strengths.
major comments (2)
- [Abstract] Abstract: The central claim that 'polynomial-time checks for valid derivation, conservativity, and minimality' make the benchmark a measure of defeasible abduction (rather than surface patterns or conversion artifacts) is load-bearing for all reported model gaps; the manuscript provides no external validation or human judgment that the generated gold standards correspond to the intended reasoning construct beyond internal consistency with the chosen logic.
- [Abstract] Abstract, Level 2/3 results: The rendering-robust accuracies (7.8-23.5%) and contamination-isolated gap (+19.4 pp) presuppose that the four surface renderings and matched control preserve the logical structure of the original instances; without explicit description of how the conversion rules from the source KBs interact with these transformations, it is unclear whether the performance drops reflect reasoning deficits or sensitivity to the pipeline's surface-form choices.
minor comments (2)
- [Abstract] The abstract states '372,648+ instances across 33.75M materialized rules from 18 sources' but does not clarify whether the instance count refers to unique logical problems or includes all renderings; this affects interpretation of scale.
- [Abstract] The description of CONJURE as 'judge-free verifier' is promising but lacks a brief statement of how the Lean kernel check is applied to confirm novelty of the generated definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the benchmark's verifiability, symbolic baseline, and release practices. We address the two major comments point by point below, proposing targeted clarifications where they strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'polynomial-time checks for valid derivation, conservativity, and minimality' make the benchmark a measure of defeasible abduction (rather than surface patterns or conversion artifacts) is load-bearing for all reported model gaps; the manuscript provides no external validation or human judgment that the generated gold standards correspond to the intended reasoning construct beyond internal consistency with the chosen logic.
Authors: The benchmark is defined by a precise formalization of defeasible abduction drawn from the source knowledge bases; the polynomial-time checks establish correctness by construction within that logic rather than by post-hoc human agreement. This design deliberately prioritizes judge-free verifiability over subjective external validation, which would introduce its own inconsistencies. The reported gaps therefore measure deviation from the formal criteria, not surface artifacts. We will add a short clarifying paragraph in Section 2 to restate this rationale explicitly. revision: partial
-
Referee: [Abstract] Abstract, Level 2/3 results: The rendering-robust accuracies (7.8-23.5%) and contamination-isolated gap (+19.4 pp) presuppose that the four surface renderings and matched control preserve the logical structure of the original instances; without explicit description of how the conversion rules from the source KBs interact with these transformations, it is unclear whether the performance drops reflect reasoning deficits or sensitivity to the pipeline's surface-form choices.
Authors: Section 3 details the KB conversion pipeline and states that each rendering applies uniform syntactic transformations while preserving the underlying set of facts, rules, and anomalies. The matched contamination control uses the identical logical instances. To remove any ambiguity, we will expand the rendering subsection with an explicit mapping showing how each of the four surface forms interacts with the KB-derived predicates and defaults. revision: yes
Circularity Check
No significant circularity; evaluation grounded in external solver and public KBs
full rationale
The paper's derivation chain consists of generating instances from external knowledge bases (OpenCyc/YAGO/Wikidata/ConceptNet/UMLS), applying polynomial checks for derivation/conservativity/minimality, and comparing model outputs to gold standards produced by an independent rule-based logic solver that achieves 100% accuracy. Reported metrics (rendering-robust accuracies 7.8-23.5%, CoT variance, contamination gap) are direct comparisons to this external verifier and released dataset; no metric is defined via fitted parameters from the same data, no self-definitional loop exists between hypothesis construction and scoring, and no load-bearing premise reduces to a self-citation. The pipeline validity assumption is external to the derivation of the numerical claims and does not create equivalence by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Defeasible abduction consists of constructing hypotheses that explain anomalies by overriding defaults while preserving unrelated expectations, subject to polynomial-time checks for valid derivation, conservativity, and minimality.
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence , volume =
Raymond Reiter , title =. Artificial Intelligence , volume =. 1980 , doi =
1980
-
[2]
Artificial Intelligence , volume =
John McCarthy , title =. Artificial Intelligence , volume =. 1980 , doi =
1980
-
[3]
Proceedings of the 20th Hawaii International Conference on Systems Science , pages =
Donald Nute , title =. Proceedings of the 20th Hawaii International Conference on Systems Science , pages =
-
[4]
Handbook of Logic in Artificial Intelligence and Logic Programming, Volume 3: Nonmonotonic Reasoning and Uncertain Reasoning , editor =
Donald Nute , title =. Handbook of Logic in Artificial Intelligence and Logic Programming, Volume 3: Nonmonotonic Reasoning and Uncertain Reasoning , editor =
-
[5]
Defeasible Deontic Logic , editor =
Donald Nute , title =. Defeasible Deontic Logic , editor =
-
[6]
Artificial Intelligence , volume =
Sarit Kraus and Daniel Lehmann and Menachem Magidor , title =. Artificial Intelligence , volume =. 1990 , doi =
1990
-
[7]
van Emden and Robert A
Maarten H. van Emden and Robert A. Kowalski , title =. Journal of the ACM , volume =. 1976 , doi =
1976
-
[8]
Lloyd , title =
John W. Lloyd , title =
-
[9]
Kakas and Robert A
Antonis C. Kakas and Robert A. Kowalski and Francesca Toni , title =. Journal of Logic and Computation , volume =. 1992 , doi =
1992
-
[10]
Maher , title =
Grigoris Antoniou and David Billington and Guido Governatori and Michael J. Maher , title =. ACM Transactions on Computational Logic , volume =. 2001 , doi =
2001
-
[11]
Maher , title =
Michael J. Maher , title =. Theory and Practice of Logic Programming , volume =. 2001 , doi =
2001
-
[12]
Maher , title =
David Billington and Grigoris Antoniou and Guido Governatori and Michael J. Maher , title =. ACM Transactions on Computational Logic , volume =. 2010 , doi =
2010
-
[13]
Artificial Intelligence , volume =
Phan Minh Dung , title =. Artificial Intelligence , volume =. 1995 , doi =
1995
-
[14]
Maher and Grigoris Antoniou and David Billington , title =
Guido Governatori and Michael J. Maher and Grigoris Antoniou and David Billington , title =. Journal of Logic and Computation , volume =. 2004 , doi =
2004
-
[15]
Journal of the ACM , volume =
Thomas Eiter and Georg Gottlob , title =. Journal of the ACM , volume =. 1995 , doi =
1995
-
[16]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages =
Oyvind Tafjord and Bhavana Dalvi and Peter Clark , title =. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages =. 2021 , doi =
2021
-
[17]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Jidong Tian and Yitian Li and Wenqing Chen and Liqiang Xiao and Hao He and Yaohui Jin , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , doi =
2021
-
[18]
arXiv preprint arXiv:2509.03345 , year =
Yunxin Sun and others , title =. arXiv preprint arXiv:2509.03345 , year =
-
[19]
arXiv preprint arXiv:2510.01530 , year =
Nuttapong Nananukul and others , title =. arXiv preprint arXiv:2510.01530 , year =
-
[20]
arXiv preprint arXiv:2510.11462 , year =
Yisen Gao and others , title =. arXiv preprint arXiv:2510.11462 , year =
-
[21]
arXiv preprint arXiv:2601.03840 , year =
Racquel Dennison and Jesse Heyninck and Thomas Meyer , title =. arXiv preprint arXiv:2601.03840 , year =
-
[22]
Agatha Christie , title =
-
[23]
Prusiner , title =
Stanley B. Prusiner , title =. Science , volume =. 1982 , doi =
1982
-
[24]
Ford Doolittle , title =
W. Ford Doolittle , title =. Science , volume =. 1999 , doi =
1999
-
[25]
The Quarterly Review of Biology , volume =
Eva Jablonka and Gal Raz , title =. The Quarterly Review of Biology , volume =. 2009 , doi =
2009
-
[26]
Keith Dunker and J
A. Keith Dunker and J. David Lawson and Celeste J. Brown and Ryan M. Williams and Pedro Romero and Jeong S. Oh and Christopher J. Oldfield and Andrew M. Campen and Catherine M. Ratliff and Kerry W. Hipps and Juan Ausio and Mark S. Nissen and Raymond Reeves and ChulHee Kang and Charles R. Kissinger and Robert W. Bailey and Michael D. Griswold and Wah Chiu ...
2001
-
[27]
International Conference on Fifth Generation Computer Systems , year =
Kazuhiro Fuchi , title =. International Conference on Fifth Generation Computer Systems , year =
-
[28]
Shrobe , title =
Edward Feigenbaum and H. Shrobe , title =. Future Generation Computer Systems , volume =
-
[29]
R&D Management , volume =
Peter Thomas , title =. R&D Management , volume =
-
[30]
Lenat and R
Douglas B. Lenat and R. V. Guha and Karen Pittman and Dexter Pratt and Mary Shepherd , title =. Communications of the ACM , volume =
-
[31]
Lenat , title =
Douglas B. Lenat , title =. Communications of the ACM , volume =
-
[32]
Miller , title =
George A. Miller , title =. Communications of the ACM , volume =
-
[33]
Proceedings of the 31st AAAI Conference on Artificial Intelligence , pages =
Robyn Speer and Joshua Chin and Catherine Havasi , title =. Proceedings of the 31st AAAI Conference on Artificial Intelligence , pages =
-
[34]
Wikidata: A Free Collaborative Knowledgebase , journal =
Denny Vrande. Wikidata: A Free Collaborative Knowledgebase , journal =. 2014 , doi =
2014
-
[35]
Mendes and Sebastian Hellmann and Mohamed Morsey and Patrick van Kleef and S
Jens Lehmann and Robert Isele and Max Jakob and Anja Jentzsch and Dimitris Kontokostas and Pablo N. Mendes and Sebastian Hellmann and Mohamed Morsey and Patrick van Kleef and S. Semantic Web , volume =. 2015 , doi =
2015
-
[36]
Suchanek and Mehwish Alam and Thomas Bonald and Lihu Chen and Pierre-Henri Paris and Jules Soria , title =
Fabian M. Suchanek and Mehwish Alam and Thomas Bonald and Lihu Chen and Pierre-Henri Paris and Jules Soria , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
-
[37]
Artificial Intelligence , volume =
Roberto Navigli and Simone Paolo Ponzetto , title =. Artificial Intelligence , volume =. 2012 , doi =
2012
-
[38]
Donald A. B. Lindberg and Betsy L. Humphreys and Alexa T. McCray , title =. Methods of Information in Medicine , volume =
-
[39]
Ball and Judith A
Michael Ashburner and Catherine A. Ball and Judith A. Blake and David Botstein and Heather Butler and J. Michael Cherry and Allan Peter Davis and Kara Dolinski and Selina S. Dwight and Janan T. Eppig and Midori A. Harris and David P. Hill and Laurie Issel-Tarver and Andrew Kasarskis and Suzanna Lewis and John C. Matese and Joel E. Richardson and Martin Ri...
2000
-
[40]
Rinke Hoekstra and Joost Breuker and Marcello Di Bello and Alexander Boer , title =
-
[41]
Wallace and John Sayers and Robert Raines and Peter Mater and Gregory S
Evan K. Wallace and John Sayers and Robert Raines and Peter Mater and Gregory S. Rohrer , title =. JOM , volume =
-
[42]
Proceedings of the 2nd International Conference on Formal Ontology in Information Systems (FOIS) , pages =
Ian Niles and Adam Pease , title =. Proceedings of the 2nd International Conference on Formal Ontology in Information Systems (FOIS) , pages =
-
[43]
Baker and Charles J
Collin F. Baker and Charles J. Fillmore and John B. Lowe , title =. Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and the 17th International Conference on Computational Linguistics , pages =. 1998 , doi =
1998
-
[44]
Hruschka Jr
Andrew Carlson and Justin Betteridge and Bryan Kisiel and Burr Settles and Estevam R. Hruschka Jr. and Tom M. Mitchell , title =. Proceedings of the 24th AAAI Conference on Artificial Intelligence , pages =
-
[45]
Alchourr
Carlos E. Alchourr. On the Logic of Theory Change: Partial Meet Contraction and Revision Functions , journal =. 1985 , doi =
1985
-
[46]
Knowledge in Flux: Modeling the Dynamics of Epistemic States , publisher =
Peter G. Knowledge in Flux: Modeling the Dynamics of Epistemic States , publisher =
-
[47]
Proceedings of the 7th National Conference on Artificial Intelligence , pages =
Mukesh Dalal , title =. Proceedings of the 7th National Conference on Artificial Intelligence , pages =
-
[48]
Mendelzon , title =
Hirofumi Katsuno and Alberto O. Mendelzon , title =. Artificial Intelligence , volume =. 1991 , doi =
1991
-
[49]
Advances in Neural Information Processing Systems , volume =
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , title =. Advances in Neural Information Processing Systems , volume =
-
[50]
International Conference on Learning Representations , year =
Kevin Meng and Arnab Sen Sharma and Alex Andonian and Yonatan Belinkov and David Bau , title =. International Conference on Learning Representations , year =
-
[51]
Transactions of the Association for Computational Linguistics , volume =
Roi Cohen and Eden Biran and Ori Yoran and Amir Globerson and Mor Geva , title =. Transactions of the Association for Computational Linguistics , volume =. 2024 , doi =
2024
-
[52]
2024 , howpublished =
The. 2024 , howpublished =
2024
-
[53]
2024 , note =
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context , institution =. 2024 , note =
2024
-
[54]
2024 , howpublished =
2024
-
[55]
2024 , note =
Abhimanyu Dubey and others , title =. 2024 , note =
2024
-
[56]
Gonzalez and Hao Zhang and Ion Stoica , title =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , title =. Proceedings of the 29th ACM Symposium on Operating Systems Principles , pages =. 2023 , doi =
2023
-
[57]
Technical Communications of the 30th International Conference on Logic Programming , year =
Martin Gebser and Roland Kaminski and Benjamin Kaufmann and Torsten Schaub , title =. Technical Communications of the 30th International Conference on Logic Programming , year =
-
[58]
Proceedings of the 28th European Conference on Artificial Intelligence , series =
Xiaotong Fang and Zhaoqun Li and Chen Chen and Beishui Liao , title =. Proceedings of the 28th European Conference on Artificial Intelligence , series =. 2025 , publisher =
2025
-
[59]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Tianshi Zheng and others , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[60]
2024 , howpublished =
Xingyu Chen and Jiahao Xu and Tian Liang and Zhiwei He and Jianhui Pang and Dian Yu and Linfeng Song and Qiuzhi Liu and Mengfei Zhou and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , title =. 2024 , howpublished =
2024
-
[61]
2025 , howpublished =
2025
-
[62]
Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and others , title =
Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and others , title =. Advances in Neural Information Processing Systems , volume =
-
[63]
Manning and Chelsea Finn , title =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn , title =. Advances in Neural Information Processing Systems , volume =
-
[64]
arXiv preprint arXiv:1707.06347 , year =
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. arXiv preprint arXiv:1707.06347 , year =
-
[65]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. International Conference on Learning Representations , year =
-
[66]
Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
Emily Allaway and Kathleen McKeown , title =. Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
2025
-
[67]
International Conference on Learning Representations , year =
Anonymous , title =. International Conference on Learning Representations , year =
-
[68]
Popper , title =
Karl R. Popper , title =. 1959 , address =
1959
-
[69]
Kuhn , title =
Thomas S. Kuhn , title =. 1962 , doi =
1962
-
[70]
1976 , doi =
Imre Lakatos , title =. 1976 , doi =
1976
-
[71]
Defeasible Reasoning as a Framework for Foundation Model Grounding, Novelty, and Belief Revision , note =
-
[72]
Datasheets for Datasets , journal =
Timnit Gebru and Jamie Morgenstern and Briana Vecchione and Jennifer Wortman Vaughan and Hanna Wallach and Hal Daum. Datasheets for Datasets , journal =. 2021 , doi =
2021
-
[73]
arXiv preprint arXiv:2110.14168 , year =
Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Mark Chen and Heewoo Jun and Lukasz Kaiser and Matthias Plappert and Jerry Tworek and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman , title =. arXiv preprint arXiv:2110.14168 , year =
-
[74]
Advances in Neural Information Processing Systems , volume =
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. Advances in Neural Information Processing Systems , volume =
-
[75]
International Conference on Learning Representations , year =
Kunhao Zheng and Jesse Michael Han and Stanislas Polu , title =. International Conference on Learning Representations , year =
-
[76]
Ayers and Dragomir Radev and Jeremy Avigad , title =
Zhangir Azerbayev and Bartosz Piotrowski and Hailey Schoelkopf and Edward W. Ayers and Dragomir Radev and Jeremy Avigad , title =. arXiv preprint arXiv:2302.12433 , year =
-
[77]
arXiv preprint arXiv:2502.10454 , year =
Countermath Authors , title =. arXiv preprint arXiv:2502.10454 , year =
-
[78]
arXiv preprint arXiv:2506.22005 , year =
LeanConjecturer Authors , title =. arXiv preprint arXiv:2506.22005 , year =
-
[79]
arXiv preprint arXiv:2511.02864 , year =
AlphaEvolve Team , title =. arXiv preprint arXiv:2511.02864 , year =
-
[80]
Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs , pages =
The mathlib Community , title =. Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs , pages =. 2020 , doi =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.