Multistage Defer Trees for Hybrid Interpretability: If at First You Can't Succeed, Tree Again
Pith reviewed 2026-07-01 01:06 UTC · model grok-4.3
The pith
A sequence of sparse decision trees can match the accuracy of full tree ensembles by classifying most samples with one or two trees and deferring the rest to a black box.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multistage Defer Trees consist of a sequence of sparse decision trees where each tree makes predictions for most samples and defers a small proportion to the next tree in the sequence or ultimately to a black box. The authors demonstrate that this model class can be trained to match the performance of complex tree-based ensembles while routing most samples through only one or a small number of sparse decision trees, expanding the accuracy-interpretability frontier in settings where single-tree methods remain insufficient.
What carries the argument
Multistage Defer Trees: a sequence of sparse decision trees that each predict for most samples and defer a small share to later stages or a black box.
If this is right
- Most samples receive predictions from one or two sparse trees, preserving interpretability for the bulk of the data.
- Overall accuracy reaches levels comparable to complex tree ensembles without full opacity.
- The method applies in domains where single trees are insufficient but full black-box use is undesirable.
- Training techniques exist that maintain model simplicity while achieving the required deferral behavior.
Where Pith is reading between the lines
- This structure could support compliance needs in regulated settings by exposing tree-based explanations for the majority of cases.
- The deferral points might identify data regions that inherently require more complex modeling, informing future data collection.
- Similar staged deferral could be tested with other interpretable base learners beyond decision trees.
Load-bearing premise
Sequences of sparse trees can be trained so that deferral decisions keep overall accuracy high without needing many stages or deferring large fractions of the data on typical datasets.
What would settle it
On standard benchmark datasets, training multistage defer trees either drops accuracy below that of tree ensembles or requires more than a few stages with high deferral rates to reach comparable performance.
Figures

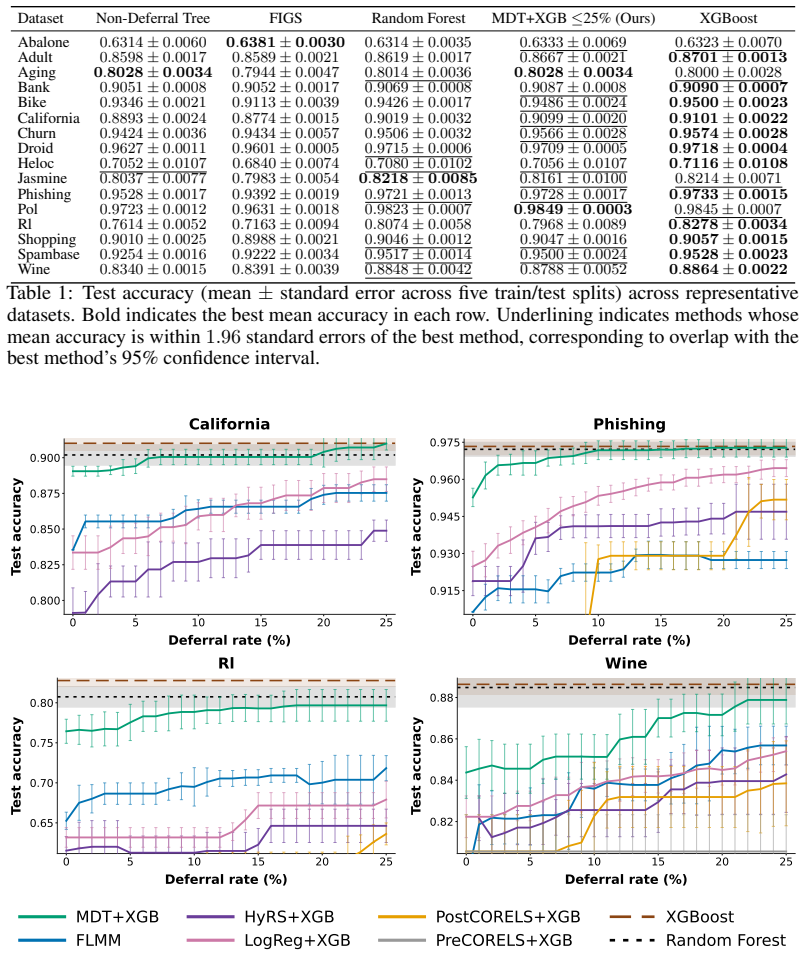
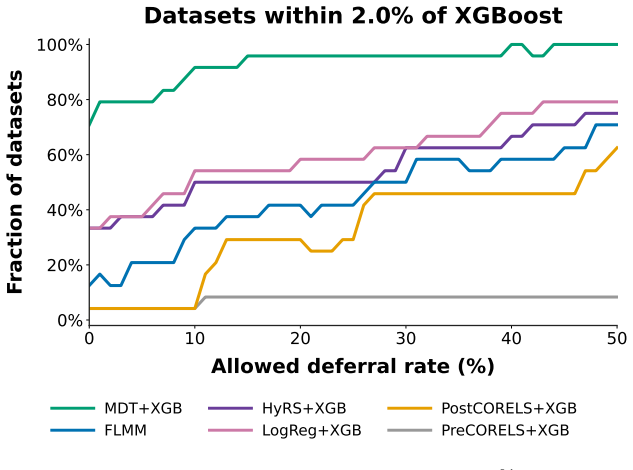






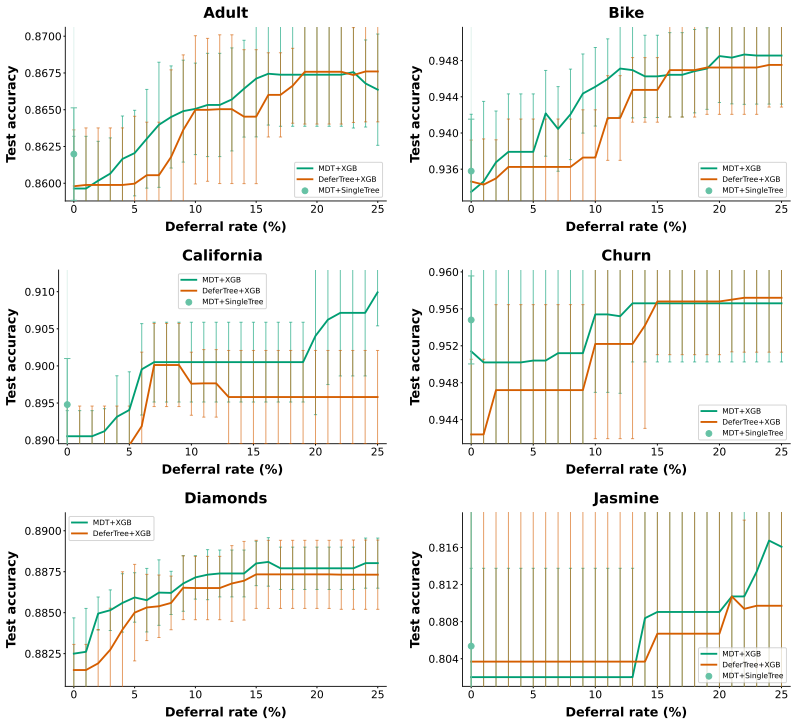


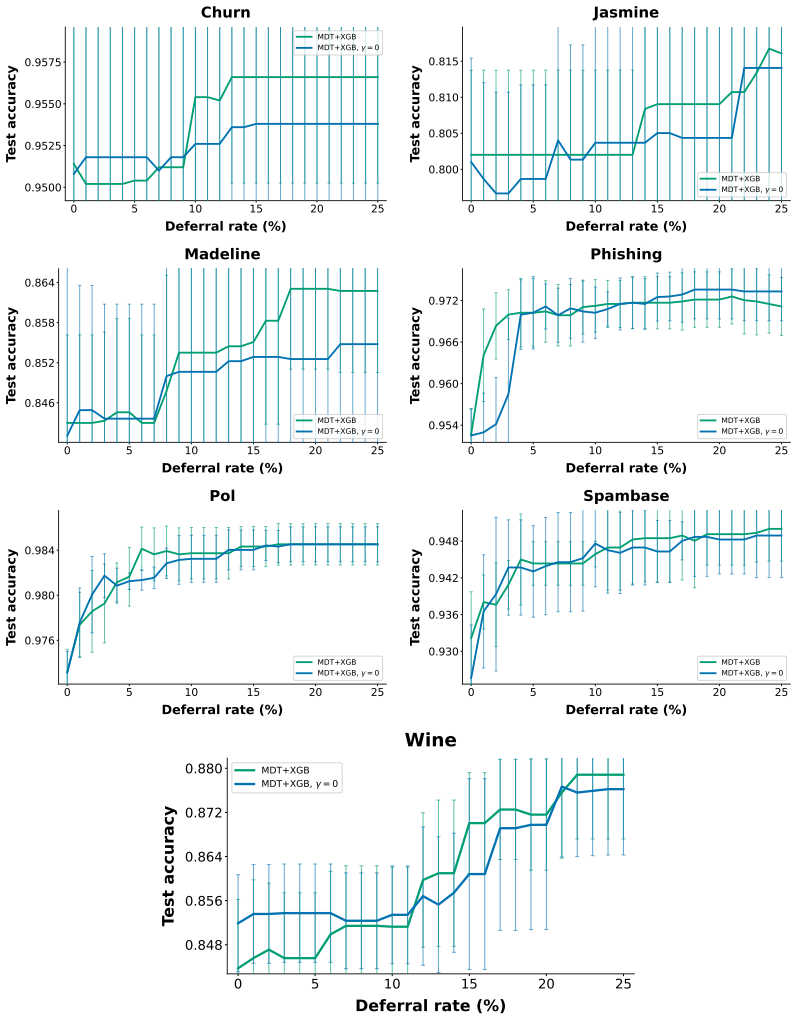





read the original abstract
Recent work has shown that well-optimized individual decision trees can match complex black box models in some settings, primarily in noisy domains. For the remaining settings, however, complex ensembled compositions of trees often achieve higher accuracy at the cost of interpretability, leaving practitioners with difficult modeling decisions along an accuracy-interpretability tradeoff. Ideally, we would like to classify as much of the data as possible with one or a small number of trees, achieving interpretability for most samples while maintaining state-of-the-art accuracy. We introduce Multistage Defer Trees: a sequence of sparse decision trees that each make predictions for most samples, while deferring a small proportion to the next tree in the sequence or, ultimately, to a black box. We demonstrate that we can train this model class to match the performance of complex tree-based ensembles while routing most samples through only one or a small number of sparse decision trees. We discuss a range of techniques for training these models while maintaining simplicity. Our method expands the accuracy--interpretability frontier in settings where single-tree methods remain insufficient, demonstrating that even when complex models are necessary, they need not be fully opaque.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multistage Defer Trees as a sequence of sparse decision trees, each classifying most samples while deferring a small fraction to the next stage or ultimately a black-box model. It claims that techniques exist to train this class such that it matches the accuracy of complex tree ensembles while routing the bulk of data through only one or a small number of the sparse trees, thereby expanding the accuracy-interpretability frontier.
Significance. If the claimed training procedure and routing behavior were empirically validated, the approach would meaningfully extend hybrid interpretability methods beyond single sparse trees by allowing most predictions to remain interpretable even when ensembles are needed for accuracy.
major comments (2)
- [Abstract] Abstract: The assertion that 'we can train this model class to match the performance of complex tree-based ensembles while routing most samples through only one or a small number of sparse decision trees' is presented with no experimental details, datasets, metrics, training procedures, or results, leaving the central empirical claim without any visible support.
- [Abstract] Abstract: The load-bearing assumption that deferral decisions can be trained to preserve overall accuracy without requiring many stages or large deferral fractions on typical datasets receives no analysis, ablation, or evidence, directly undermining the hybrid-interpretability benefit.
Simulated Author's Rebuttal
We thank the referee for their comments. We respond point-by-point to the major comments below and indicate where revisions are appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'we can train this model class to match the performance of complex tree-based ensembles while routing most samples through only one or a small number of sparse decision trees' is presented with no experimental details, datasets, metrics, training procedures, or results, leaving the central empirical claim without any visible support.
Authors: The abstract is a concise summary; the full manuscript contains dedicated experimental sections reporting results across multiple datasets, accuracy metrics, deferral fractions, and the training procedures used (including optimization of tree sparsity and deferral thresholds). We will revise the abstract to include a brief reference to the empirical validation and key datasets to make the support more visible at the summary level. revision: yes
-
Referee: [Abstract] Abstract: The load-bearing assumption that deferral decisions can be trained to preserve overall accuracy without requiring many stages or large deferral fractions on typical datasets receives no analysis, ablation, or evidence, directly undermining the hybrid-interpretability benefit.
Authors: The manuscript describes a range of training techniques intended to keep deferral fractions small and stage counts low while preserving accuracy. We acknowledge that dedicated ablations quantifying the sensitivity to stage count and deferral rate would provide stronger direct evidence for the assumption. We will add such analysis (or expanded discussion of existing results) in revision. revision: yes
Circularity Check
No circularity in multistage defer trees derivation or claims
full rationale
The paper introduces a new model class (sequences of sparse decision trees with deferral to later stages or a black box) and states an empirical claim that it can be trained to match ensemble accuracy while routing most samples through one or few trees. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The load-bearing step is a training procedure whose success is presented as a demonstration rather than a definitional identity or reduction to prior self-cited results. The derivation chain is therefore self-contained and does not reduce any claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of stages
- deferral threshold per stage
axioms (1)
- domain assumption Sparse decision trees can achieve competitive accuracy on appropriately chosen subsets of data.
Reference graph
Works this paper leans on
-
[1]
UCI Machine Learning Repository, 2017
In-Vehicle Coupon Recommendation. UCI Machine Learning Repository, 2017. DOI: https://doi.org/10.24432/C5GS4P
-
[3]
Learning optimal decision trees using caching branch-and-bound search
Gaël Aglin, Siegfried Nijssen, and Pierre Schaus. Learning optimal decision trees using caching branch-and-bound search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 3146–3153, 2020
2020
-
[4]
David Aha. Tic-Tac-Toe Endgame. UCI Machine Learning Repository, 1991. DOI: https://doi.org/10.24432/C5688J
-
[5]
Near-optimal decision trees in a SPLIT second
Varun Babbar, Hayden McTavish, Cynthia Rudin, and Margo Seltzer. Near-optimal decision trees in a SPLIT second. In International Conference on Machine Learning, 2025
2025
-
[6]
Michelle Bao, Angela Zhou, A. S. Zottola, Brian Brubach, Sarah Desmarais, Seth A. Horowitz, Kristian Lum, and Suresh Venkatasubramanian. It’s compaslicated: The messy relationship between rai datasets and algorithmic fairness benchmarks. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS), 2021. Datasets and Be...
2021
-
[7]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[8]
Optimal classification trees
Dimitris Bertsimas and Jack Dunn. Optimal classification trees. Machine Learning, 106: 1039–1082, 2017
2017
-
[9]
Harnessing the power of choices in decision tree learning
Guy Blanc, Jane Lange, Chirag Pabbaraju, Colin Sullivan, Li-Yang Tan, and Mo Tiwari. Harnessing the power of choices in decision tree learning. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[10]
R. Bock. MAGIC Gamma Telescope. UCI Machine Learning Repository, 2004. DOI: https://doi.org/10.24432/C52C8B
-
[11]
Using noise to infer aspects of simplicity without learning
Zachery Boner, Harry Chen, Lesia Semenova, Ronald Parr, and Cynthia Rudin. Using noise to infer aspects of simplicity without learning. In Advances In Neural Information Processing Systems, 2024
2024
-
[12]
Random forests
Leo Breiman. Random forests. Machine Learning, 45:5–32, 2001
2001
-
[13]
Classification and regression trees
Leo Breiman, Jerome H Friedman, Richard A Olshen, and Charles J Stone. Classification and regression trees. wadsworth & brooks, 1984
1984
-
[14]
Optimal classification trees for continuous feature data using dynamic programming with branch-and-bound
C˘at˘alin E Brit,a, Jacobus GM van der Linden, and Emir Demirovi´c. Optimal classification trees for continuous feature data using dynamic programming with branch-and-bound. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11131–11139, 2025. 10
2025
-
[15]
Xgboost: A Scalable Tree Boosting System
Tianqi Chen and Carlos Guestrin. Xgboost: A Scalable Tree Boosting System. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794, 2016
2016
-
[16]
On optimum recognition error and reject tradeoff
C Chow. On optimum recognition error and reject tradeoff. IEEE Transactions on information theory, 16(1):41–46, 2003
2003
-
[17]
Cortez and A
P. Cortez and A. M. Gonçalves Silva. Using data mining to predict secondary school student performance. 2008. URLhttps://api.semanticscholar.org/CorpusID:16621299
2008
-
[18]
Paulo Cortez. Student Performance. UCI Machine Learning Repository, 2008. DOI: https://doi.org/10.24432/C5TG7T
-
[19]
Murtree: Optimal decision trees via dynamic programming and search
Emir Demirovi´c, Anna Lukina, Emmanuel Hebrard, Jeffrey Chan, James Bailey, Christopher Leckie, Kotagiri Ramamohanarao, and Peter J Stuckey. Murtree: Optimal decision trees via dynamic programming and search. Journal of Machine Learning Research, 23(26):1–47, 2022
2022
-
[20]
Blossom: an anytime algorithm for computing optimal decision trees
Emir Demirovi´c, Emmanuel Hebrard, and Louis Jean. Blossom: an anytime algorithm for computing optimal decision trees. In International Conference on Machine Learning, pages 7533–7562. PMLR, 2023
2023
-
[21]
Compressing tree ensembles through level-wise optimization and pruning
Laurens Devos, Timo Martens, Deniz Can Oruc, Wannes Meert, Hendrik Blockeel, and Jesse Davis. Compressing tree ensembles through level-wise optimization and pruning. In Forty-second International Conference on Machine Learning, 2025
2025
-
[22]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
Ran El-Yaniv et al. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
2010
-
[23]
TabArena: A Living Benchmark for Machine Learning on Tabular Data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data, 2025. URLhttps://arxiv.org/abs/2506.16791
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Hadi Fanaee-T. Bike Sharing. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5W894
-
[25]
Event labeling combining ensemble detectors and back- ground knowledge
Hadi Fanaee-T and João Gama. Event labeling combining ensemble detectors and back- ground knowledge. Progress in Artificial Intelligence, 2:113 – 127, 2013. URL https: //api.semanticscholar.org/CorpusID:256282956
2013
-
[26]
Learning hybrid interpretable models: Theory, taxonomy, and methods
Julien Ferry, Gabriel Laberge, and Ulrich Aïvodji. Learning hybrid interpretable models: Theory, taxonomy, and methods. arXiv preprint arXiv:2303.04437, 2023
-
[27]
Home equity line of credit (heloc) dataset, 2018
FICO. Home equity line of credit (heloc) dataset, 2018. URL https://community.fico. com/s/explainable-machine-learning-challenge . FICO Explainable Machine Learn- ing Challenge
2018
-
[28]
Using and combining predictors that specialize
Yoav Freund, Robert E Schapire, Yoram Singer, and Manfred K Warmuth. Using and combining predictors that specialize. In Proceedings of the twenty-ninth annual ACM symposium on Theory of computing, pages 334–343, 1997
1997
-
[29]
Partially interpretable models with guarantees on coverage and accuracy
Nave Frost, Zachary Lipton, Yishay Mansour, and Michal Moshkovitz. Partially interpretable models with guarantees on coverage and accuracy. In International conference on algorithmic learning theory, pages 590–613. PMLR, 2024
2024
-
[30]
Analysis of the automl challenge series 2015-
Isabelle Guyon, Lisheng Sun-Hosoya, Marc Boullé, Hugo Jair Escalante, Sergio Escalera, Zhengying Liu, Damir Jajetic, Bisakha Ray, Mehreen Saeed, Michéle Sebag, Alexander Statnikov, WeiWei Tu, and Evelyne Viegas. Analysis of the automl challenge series 2015-
2015
-
[31]
URL https: //www.automl.org/wp-content/uploads/2018/09/chapter10-challenge.pdf
In AutoML, Springer series on Challenges in Machine Learning, 2019. URL https: //www.automl.org/wp-content/uploads/2018/09/chapter10-challenge.pdf
2019
-
[32]
From rashomon theory to PRAXIS: Efficient decision tree rashomon sets
Zakk Heile, Hayden McTavish, Varun Babbar, Margo Seltzer, and Cynthia Rudin. From rashomon theory to PRAXIS: Efficient decision tree rashomon sets. In Forty-third International Conference on Machine Learning, 2026. URL https://openreview.net/forum?id= Sgwd0l1u2V. 11
2026
-
[33]
Mark Hopkins, Erik Reeber, George Forman, and Jaap Suermondt. Spambase. UCI Machine Learning Repository, 1999. DOI: https://doi.org/10.24432/C53G6X
-
[34]
Optimal sparse decision trees
Xiyang Hu, Cynthia Rudin, and Margo Seltzer. Optimal sparse decision trees. In Advances in Neural Information Processing Systems, volume 32, pages 7265–7273, 2019
2019
-
[35]
Time constrained dl8.5 using limited discrepancy search
Harold Kiossou, Pierre Schaus, Siegfried Nijssen, and Vinasetan Ratheil Houndji. Time constrained dl8.5 using limited discrepancy search. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 443–459. Springer, 2022
2022
-
[36]
Efficient lookahead decision trees
Harold Kiossou, Pierre Schaus, Siegfried Nijssen, and Gaël Aglin. Efficient lookahead decision trees. In International Symposium on Intelligent Data Analysis, pages 133–144. Springer, 2024
2024
-
[37]
A generic complete anytime beam search for optimal decision tree
Harold Silvere Kiossou, Siegfried Nijssen, and Pierre Schaus. A generic complete anytime beam search for optimal decision tree. arXiv preprint arXiv:2508.06064, 2025
-
[38]
Interpret when possible: A tree-based hybrid framework for interpretable classification
Yifan Li, Shuhan Qi, Lei Cui, Chao Xing, Lei Zhang, and Xuan Wang. Interpret when possible: A tree-based hybrid framework for interpretable classification. Big Data Mining and Analytics, 9(1):263–283, 2026. doi: 10.26599/BDMA.2025.9020055. URL https: //www.sciopen.com/article/10.26599/BDMA.2025.9020055
-
[39]
Generalized and scalable optimal sparse decision trees
Jimmy Lin, Chudi Zhong, Diane Hu, Cynthia Rudin, and Margo Seltzer. Generalized and scalable optimal sparse decision trees. In International Conference on Machine Learning, pages 6150–6160. PMLR, 2020
2020
-
[40]
Accurate intelligible models with pairwise interactions
Yin Lou, Rich Caruana, Johannes Gehrke, and Giles Hooker. Accurate intelligible models with pairwise interactions. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, 2013. URL https://api.semanticscholar.org/ CorpusID:11246170
2013
-
[41]
Predict responsibly: improving fairness and accuracy by learning to defer
David Madras, Toni Pitassi, and Richard Zemel. Predict responsibly: improving fairness and accuracy by learning to defer. Advances in neural information processing systems, 31, 2018
2018
-
[42]
Malani, Jeffrey Kullgren, and Erica Solway
Preeti N. Malani, Jeffrey Kullgren, and Erica Solway. National poll on healthy aging (npha), united states, april 2017, 2019. URL https://doi.org/10.3886/ICPSR37305.v1. Distrib- utor
-
[43]
Marcoulides
George A. Marcoulides. Discovering Knowledge in Data: An Introduction to Data Mining. Wiley, 2005. Churn dataset
2005
-
[44]
NATICUSdroid (Android Permissions)
Akshay Mathur. NATICUSdroid (Android Permissions). UCI Machine Learning Repository,
-
[45]
DOI: https://doi.org/10.24432/C5FS64
-
[46]
Akshay Mathur, Mounika Podila, Keyur Kulkarni, Quamar Niyaz, and Ahmad Y . Javaid. Poster: Naticusdroid: A malware detection framework for android using native and custom. 2021. URL https://api.semanticscholar.org/CorpusID:232063483
2021
-
[47]
Quant-BnB: A scalable branch-and-bound method for optimal decision trees with continuous features
Rahul Mazumder, Xiang Meng, and Haoyue Wang. Quant-BnB: A scalable branch-and-bound method for optimal decision trees with continuous features. In International Conference on Machine Learning, volume 162, pages 15255–15277. PMLR, 17–23 Jul 2022
2022
-
[48]
Fast sparse decision tree optimization via reference ensembles
Hayden McTavish, Chudi Zhong, Reto Achermann, Ilias Karimalis, Jacques Chen, Cynthia Rudin, and Margo Seltzer. Fast sparse decision tree optimization via reference ensembles. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 9604–9613, 2022
2022
-
[49]
Phishing Websites
Rami Mohammad and Lee McCluskey. Phishing Websites. UCI Machine Learning Repository,
-
[50]
DOI: https://doi.org/10.24432/C51W2X
-
[51]
Mohammad, Fadi A
Rami Mustafa A. Mohammad, Fadi A. Thabtah, and Lee Mccluskey. An assessment of features related to phishing websites using an automated technique. 2012 International Conference for Internet Technology and Secured Transactions, pages 492–497, 2012. URL https://api. semanticscholar.org/CorpusID:5716727. 12
2012
-
[52]
Consistent estimators for learning to defer to an expert
Hussein Mozannar and David Sontag. Consistent estimators for learning to defer to an expert. In International conference on machine learning, pages 7076–7087. PMLR, 2020
2020
-
[53]
Jasmine dataset, 2018
OpenML. Jasmine dataset, 2018. URL https://www.openml.org/d/41143. OpenML Dataset ID 41143; dataset from the ChaLearn Automatic Machine Learning (AutoML) Chal- lenge
2018
-
[54]
Madeline dataset, 2018
OpenML. Madeline dataset, 2018. URL https://www.openml.org/d/41144. OpenML Dataset ID 41144; dataset from the ChaLearn Automatic Machine Learning (AutoML) Chal- lenge
2018
-
[55]
Diamonds dataset, 2019
OpenML. Diamonds dataset, 2019. URL https://www.openml.org/d/42225. OpenML Dataset ID 42225; dataset containing prices and attributes of nearly 54,000 diamonds
2019
-
[56]
Abalone dataset, 2022
OpenML. Abalone dataset, 2022. URL https://www.openml.org/d/44956. OpenML Dataset ID 44956; dataset for predicting abalone age from physical measurements
2022
-
[57]
California dataset, 2022
OpenML. California dataset, 2022. URL https://www.openml.org/d/44090. OpenML Dataset ID 44090; dataset used in the tabular data benchmark and derived from the California Housing dataset
2022
-
[58]
Pol dataset, 2022
OpenML. Pol dataset, 2022. URL https://www.openml.org/d/44082. OpenML Dataset ID 44082; dataset used in the tabular data benchmark and derived from a binarized version of the original regression dataset
2022
-
[59]
Rl dataset, 2022
OpenML. Rl dataset, 2022. URL https://www.openml.org/d/43949. OpenML Dataset ID 43949; dataset used in the tabular data benchmark and derived from the ChaLearn AutoML Challenge
2022
-
[60]
Wine dataset, 2025
OpenML. Wine dataset, 2025. URL https://www.openml.org/d/47041. OpenML Dataset ID 47041
2025
-
[61]
Interpretable companions for black-box models
Danqing Pan, Tong Wang, and Satoshi Hara. Interpretable companions for black-box models. In International conference on artificial intelligence and statistics, pages 2444–2454. PMLR, 2020
2020
-
[62]
Ross Quinlan
J. Ross Quinlan. Induction of decision trees. Machine learning, 1(1):81–106, 1986
1986
-
[63]
Approximating xgboost with an interpretable decision tree
Omer Sagi and Lior Rokach. Approximating xgboost with an interpretable decision tree. Information Sciences, 572:522–542, 2021
2021
-
[64]
C. Sakar and Yomi Kastro. Online Shoppers Purchasing Intention Dataset. UCI Machine Learning Repository, 2018. DOI: https://doi.org/10.24432/C5F88Q
-
[65]
Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and lstm recurrent neural networks
Cemal Okan Sakar, Suleyman Olcay Polat, Mete Katircioglu, and Yomi Kastro. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and lstm recurrent neural networks. Neural Computing and Applications, 31:6893 – 6908, 2018. URL https://api.semanticscholar.org/CorpusID:13682776
2018
-
[66]
Santos-Pereira and Ana M
Carla M. Santos-Pereira and Ana M. Pires. On optimal reject rules and roc curves. Pattern Recognition Letters, 26(7):943–952, 2005. ISSN 0167-8655. doi: https://doi.org/10.1016/ j.patrec.2004.09.042. URL https://www.sciencedirect.com/science/article/pii/ S0167865504002892
2005
-
[67]
Robert E. Schapire and Yoram Singer. Improved boosting algorithms using confidence-rated predictions. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, COLT’ 98, page 80–91, New York, NY , USA, 1998. Association for Computing Machinery. ISBN 1581130570. doi: 10.1145/279943.279960. URL https://doi.org/10. 1145/279943.279960
-
[68]
On the existence of simpler machine learning models
Lesia Semenova, Cynthia Rudin, and Ronald Parr. On the existence of simpler machine learning models. In 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1827–1858, 2022. 13
2022
-
[69]
A path to simpler models starts with noise
Lesia Semenova, Harry Chen, Ronald Parr, and Cynthia Rudin. A path to simpler models starts with noise. Advances in Neural Information Processing Systems, 36, 2023
2023
-
[70]
Fast interpretable greedy-tree sums
Yan Shuo Tan, Chandan Singh, Keyan Nasseri, Abhineet Agarwal, James Duncan, Omer Ronen, Matthew Epland, Aaron Kornblith, and Bin Yu. Fast interpretable greedy-tree sums. Proceedings of the National Academy of Sciences, 122(7):e2310151122, 2025. doi: 10.1073/ pnas.2310151122
2025
-
[71]
The monk”s problems-a performance comparison of different learning algo- rithms, cmu-cs-91-197, sch
Sebastian Thrun. The monk”s problems-a performance comparison of different learning algo- rithms, cmu-cs-91-197, sch. 1991. URL https://api.semanticscholar.org/CorpusID: 59699060
1991
-
[72]
Learning optimal classification trees using a binary lin- ear program formulation
Sicco Verwer and Yingqian Zhang. Learning optimal classification trees using a binary lin- ear program formulation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1625–1632, 2019
2019
-
[73]
Born-again tree ensembles
Thibaut Vidal and Maximilian Schiffer. Born-again tree ensembles. In International conference on machine learning, pages 9743–9753. PMLR, 2020
2020
-
[74]
Gaining no or low-cost transparency with interpretable partial substitute
Tong Wang. Gaining no or low-cost transparency with interpretable partial substitute. In International Conference on Machine Learning, 2019
2019
-
[75]
Hybrid predictive models: when an interpretable model collaborates with a black-box model
Tong Wang and Qihang Lin. Hybrid predictive models: when an interpretable model collaborates with a black-box model. J. Mach. Learn. Res., 22(1), January 2021. ISSN 1532-4435
2021
-
[76]
J. Wnek. MONK’s Problems. UCI Machine Learning Repository, 1993. DOI: https://doi.org/10.24432/C5R30R
-
[77]
Default of Credit Card Clients
I-Cheng Yeh. Default of Credit Card Clients. UCI Machine Learning Repository, 2009. DOI: https://doi.org/10.24432/C55S3H
-
[78]
The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients
I-Cheng Yeh and Che hui Lien. The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Syst. Appl., 36:2473–2480,
-
[79]
14 Appendix Contents A Proofs
URLhttps://api.semanticscholar.org/CorpusID:15696161. 14 Appendix Contents A Proofs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 Proposition 1: Top-down improvement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.