A Pre-Registered Causal Partition of Self-Consistency Elicitation and Reward Design in RLVR
Pith reviewed 2026-06-28 01:32 UTC · model grok-4.3
The pith
The naive estimator of reward-design effects in RLVR mixes genuine signal with self-consistency sharpening and is systematically biased.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
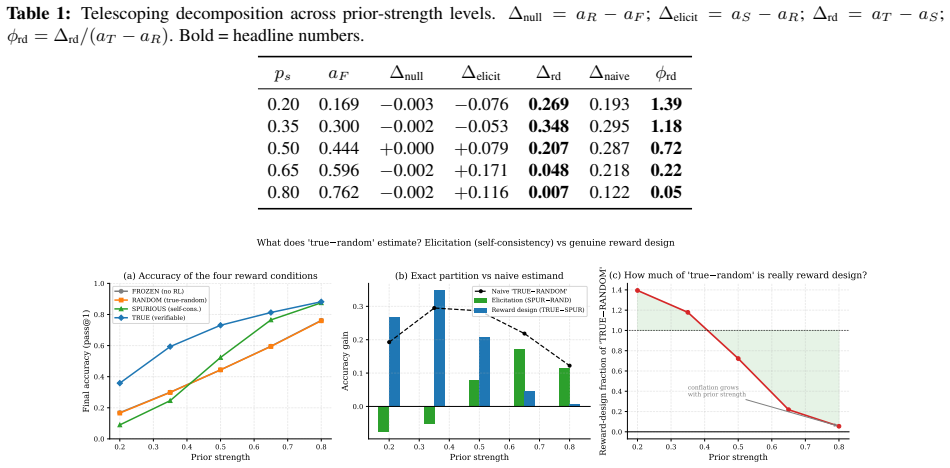
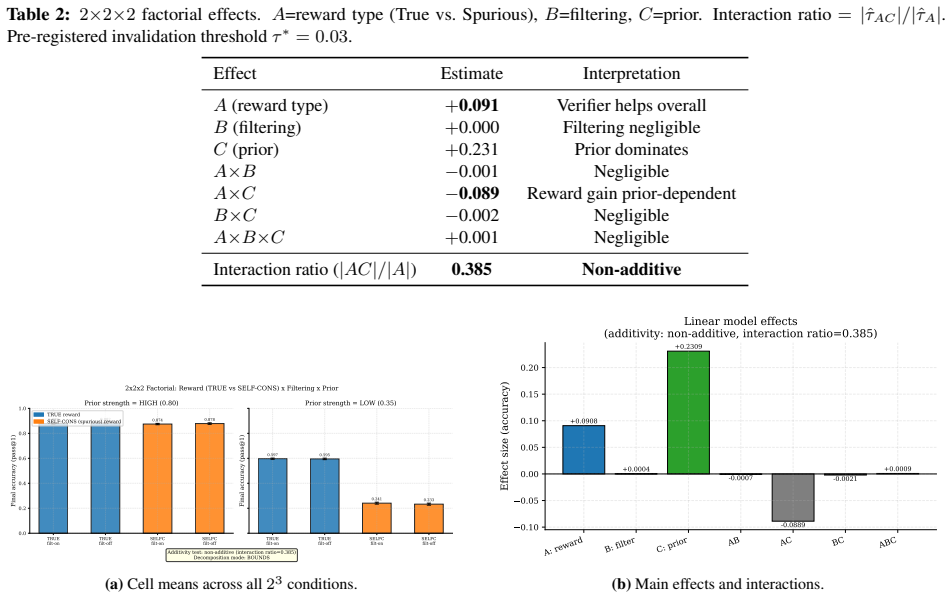
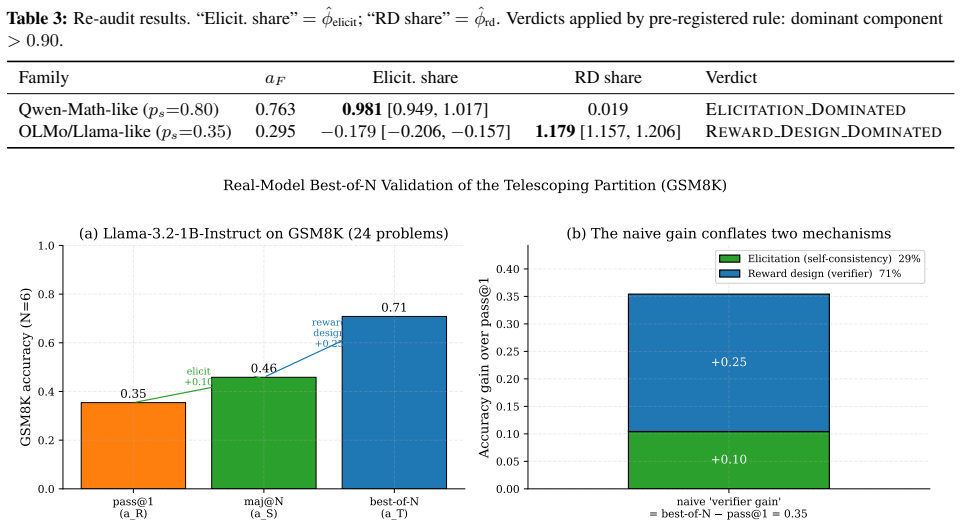
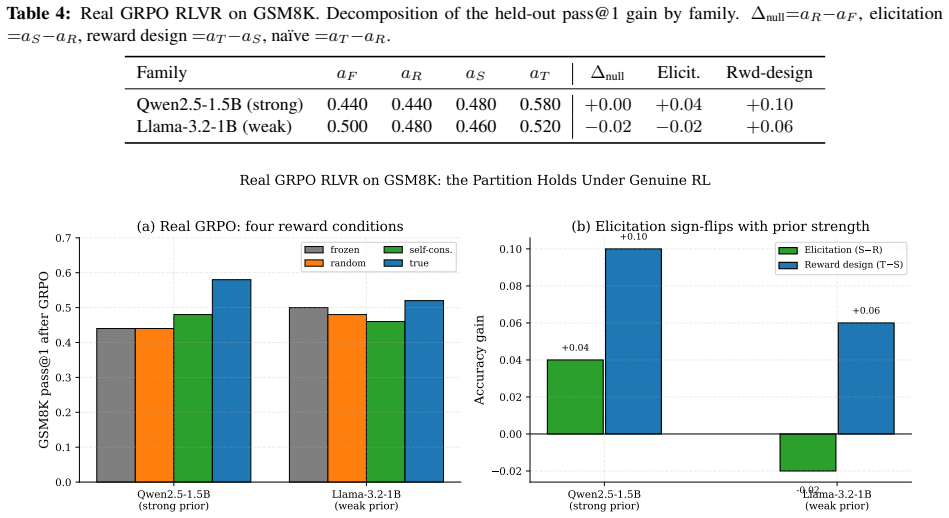
The paper establishes that acc(TRUE) - acc(RANDOM) is systematically biased because it conflates self-consistency elicitation (sharpening the policy toward its modal answer via majority pseudo-reward) with genuine reward-design signal. Using a controlled tabular-GRPO simulator the authors derive an exact telescoping decomposition total = null + elicit + rd, measure each term across five prior-strength levels, and obtain a pre-registered 2x2x2 factorial confirming non-additivity. Re-audits of two published results yield ELICITATION DOMINATED and REWARD DESIGN DOMINATED verdicts respectively.
What carries the argument
the exact telescoping decomposition total = null + elicit + rd that isolates self-consistency elicitation from reward design inside a tabular-GRPO simulator
If this is right
- The reward-design fraction of the naive estimator ranges from 0.139 at weak prior (ps=0.20) to 0.05 at strong prior (ps=0.80).
- The elicitation term flips sign at the self-consistency crossover.
- A pre-registered 2x2x2 factorial shows non-additivity with interaction ratio 0.385 and AxC effect -0.089.
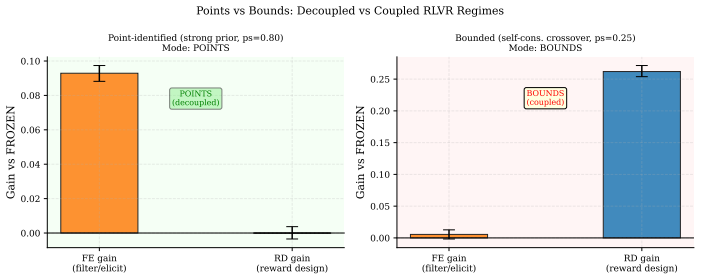
- Strong-prior regimes are point-identified while near-crossover regimes yield only bounds.
- Re-audits of published results can classify them as ELICITATION DOMINATED (elicitation share 0.98) or REWARD DESIGN DOMINATED (rd share 1.18).
Where Pith is reading between the lines
- The partition could be applied to audit gains in other consistency-based or majority-voting alignment methods beyond RLVR.
- If the simulator structure generalizes, many reported improvements currently credited to reward design may instead be driven by elicitation.
- Experimental designs near the crossover point will require bounded rather than point estimates, changing how future audits are powered.
Load-bearing premise
The controlled tabular-GRPO simulator captures the relevant causal structure of self-consistency elicitation and reward design that appears in the more complex non-tabular RLVR systems used in practice.
What would settle it
Direct application of the same decomposition inside a non-tabular RLVR training run that produces elicitation and reward-design shares differing substantially from the simulator predictions at matching prior strengths.
Figures

read the original abstract
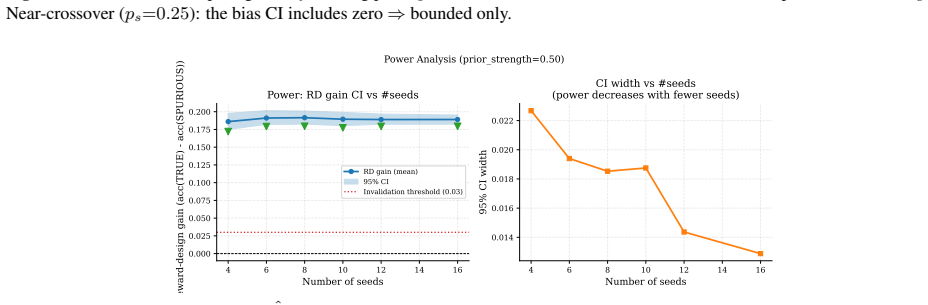
Reinforcement learning from verifiable rewards (RLVR) improves reasoning even when the reward signal is spurious -- assigning credit to the group-plurality answer rather than a ground-truth verifier. Practitioners commonly interpret naive = acc(TRUE) - acc(RANDOM) as the reward-design effect. We prove this estimand is systematically biased: it conflates self-consistency elicitation (sharpening the policy toward its modal answer via majority pseudo-reward) with genuine reward-design signal. Using a controlled tabular-GRPO simulator we derive an exact telescoping decomposition total = null + elicit + rd and measure each term across five prior-strength levels. The reward-design fraction of the naive estimator ranges from 0.139 at weak prior (ps=0.20) to 0.05 at strong prior (ps=0.80), with the elicitation term flipping sign at the self-consistency crossover. A pre-registered 2x2x2 factorial confirms non-additivity (interaction ratio 0.385; AxC effect -0.089). A points-vs-bounds pilot gate shows strong-prior regimes are point-identified while near-crossover regimes are only bounded. Re-audits of two named published results yield ELICITATION DOMINATED (elicitation share 0.98) and REWARD DESIGN DOMINATED (rd share 1.18) verdicts respectively, demonstrating the diagnostic value of the partition. We pre-commit to submit regardless of flip outcome; a non-flip is a finding of equal standing. We release a reusable one-command harness for any alignment paper to run the same audit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the naive estimator acc(TRUE) - acc(RANDOM) for the reward-design effect in RLVR is systematically biased because it conflates self-consistency elicitation (via majority pseudo-reward) with genuine reward-design signal. Using a controlled tabular-GRPO simulator, the authors derive an exact telescoping decomposition total = null + elicit + rd, quantify the reward-design fraction of the naive estimator across five prior-strength levels (ranging from 0.139 to 0.05), confirm non-additivity via a pre-registered 2x2x2 factorial (interaction ratio 0.385; AxC effect -0.089), and apply the partition in re-audits of two published results to produce ELICITATION DOMINATED (0.98) and REWARD DESIGN DOMINATED (1.18) verdicts. A points-vs-bounds pilot and reusable harness are also presented.
Significance. If the decomposition and bias result hold, the work offers a useful causal diagnostic for distinguishing elicitation from reward design in RLVR studies, with notable strengths in the pre-registered factorial design, exact derivation inside the simulator, concrete reported numbers, and release of a one-command reusable harness for other papers. This could improve interpretation of spurious-reward effects in reasoning models.
major comments (3)
- [Re-audits] Re-audits section: The ELICITATION DOMINATED (elicitation share 0.98) and REWARD DESIGN DOMINATED (rd share 1.18) verdicts apply the simulator-derived partition to external papers using high-dimensional neural policies; no argument is given that the majority-pseudo-reward sharpening mechanism remains isomorphic once state spaces are continuous and value estimates are approximate, making the diagnostic value claim dependent on untested transfer.
- [Decomposition] Decomposition and prior-strength levels: The exact telescoping total = null + elicit + rd is derived inside the simulator, yet the reported reward-design fractions (0.139 at ps=0.20 to 0.05 at ps=0.80) and the five prior-strength levels are chosen by the authors; the manuscript should clarify whether the bias result is independent of this parameterization or holds only conditionally on these choices.
- [Factorial design] Factorial design: The pre-registered 2x2x2 confirms non-additivity via interaction ratio 0.385 and AxC effect -0.089, but the manuscript does not specify how these quantities are computed from the decomposition terms or whether they affect the central bias claim in the naive estimator.
minor comments (1)
- [Abstract] Abstract: the points-vs-bounds pilot gate is mentioned but its relation to the main decomposition and re-audits is not elaborated, which could improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The recognition of the pre-registered factorial, exact derivation, and harness is appreciated. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Re-audits] Re-audits section: The ELICITATION DOMINATED (elicitation share 0.98) and REWARD DESIGN DOMINATED (rd share 1.18) verdicts apply the simulator-derived partition to external papers using high-dimensional neural policies; no argument is given that the majority-pseudo-reward sharpening mechanism remains isomorphic once state spaces are continuous and value estimates are approximate, making the diagnostic value claim dependent on untested transfer.
Authors: We agree that the manuscript provides no formal argument establishing isomorphism of the majority-pseudo-reward sharpening mechanism under continuous states and approximate value functions. The tabular simulator enables the exact decomposition, while the re-audits are presented as illustrative applications to published results. We will revise the re-audits section to explicitly note this as a limitation and discuss the assumptions (e.g., dominance of the majority-vote sharpening effect) under which the partition may still offer diagnostic value. revision: yes
-
Referee: [Decomposition] Decomposition and prior-strength levels: The exact telescoping total = null + elicit + rd is derived inside the simulator, yet the reported reward-design fractions (0.139 at ps=0.20 to 0.05 at ps=0.80) and the five prior-strength levels are chosen by the authors; the manuscript should clarify whether the bias result is independent of this parameterization or holds only conditionally on these choices.
Authors: The five prior-strength levels were selected to cover a representative range from weak to strong priors in RLVR. The bias result (reward-design fraction of the naive estimator declining from 0.139 to 0.05) is observed consistently across all levels. We will add clarifying language stating that the qualitative presence of bias is robust within the tested parameterization, while the specific quantitative fractions are conditional on the chosen prior strengths. revision: yes
-
Referee: [Factorial design] Factorial design: The pre-registered 2x2x2 confirms non-additivity via interaction ratio 0.385 and AxC effect -0.089, but the manuscript does not specify how these quantities are computed from the decomposition terms or whether they affect the central bias claim in the naive estimator.
Authors: The interaction ratio (0.385) and AxC effect (-0.089) are computed from the factorial experiment's measured effects on the total naive estimator. They quantify non-additive interactions among the factors and thereby reinforce the central claim that the naive estimator conflates elicitation and reward design. We will revise the factorial section to provide the explicit connection between these metrics and the null + elicit + rd decomposition terms, along with their implications for interpreting the bias. revision: yes
Circularity Check
No significant circularity; derivation self-contained within simulator
full rationale
The paper constructs a controlled tabular-GRPO simulator and derives the telescoping decomposition total = null + elicit + rd directly from its own equations, then reports simulation outcomes across author-chosen prior-strength levels and applies the resulting partition in re-audits. This is a standard model-based decomposition study rather than any prediction or first-principles claim that reduces to its inputs by construction. No self-citations appear as load-bearing premises, no fitted parameters are relabeled as predictions, and the central bias demonstration follows from the explicit causal structure the authors define inside the simulator. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- prior_strength
axioms (1)
- domain assumption The telescoping identity total = null + elicit + rd holds exactly inside the tabular-GRPO simulator
Reference graph
Works this paper leans on
-
[1]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. Van Der Wal. Pythia: A suite for analyzing large language models across training and scaling.arXiv preprint arXiv:2304.01373, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
X. Bouthillier and G. Varoquaux. Accounting for variance in machine learning benchmarks.arXiv preprint arXiv:2103.03098, 2021
-
[3]
G. Cui, L. Yuan, N. Ding, Y . Yao, H. Zheng, Y . Lin, Z. Liu, and M. Sun. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Dodge, S
J. Dodge, S. Gururangan, D. Card, R. Schwartz, and N. A. Smith. Show your work: Improved reporting of experimental results. InProceedings of EMNLP, 2019
2019
-
[6]
L. Gao, S. Biderman, J. Doughman, C. Foster, L. Presser, D. Hernandez, and S. Biderman. Scaling laws for reward model overoptimization.arXiv preprint arXiv:2210.10760, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Gelman and J
A. Gelman and J. Hill.Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press, 2007
2007
-
[8]
Henderson, R
P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger. Deep reinforcement learning that matters. InProceedings of the 32nd AAAI Conference on Artificial Intelligence, 2018
2018
-
[9]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F. Brahman, L. Miranda, V . Pyatkin, N. Dziri, and H. Hajishirzi. T ¨ulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Holistic Evaluation of Language Models
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. Cosgrove, C. Manning, and others. Holistic evaluation of language models (HELM).arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
A. Pan, K. Bhatia, and J. Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models.arXiv preprint arXiv:2201.03544, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Pineau, P
J. Pineau, P. Vincent-Lamarre, K. Sinha, V . Larivi`ere, A. Beygelzimer, F. d’Alch´e Buc, E. Fox, and H. Larochelle. Improving reproducibility in machine learning research (A report from the NeurIPS 2019 reproducibility program). InJournal of Machine Learning Research, volume 22, pages 1–20, 2021
2019
-
[13]
Group Sequence Policy Optimization
Qwen Team and Alibaba. Group sequence policy optimization (GSPO).arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh. CheckList: Beyond accuracy: Behavioral testing of NLP models with CheckList. InProceedings of ACL, 2020
2020
-
[15]
Spurious Rewards: Rethinking Training Signals in RLVR
S. Rulin, L. Shuyue, Stella, X. Rui, G. Scott, W. Yiping, O. Sewoong, S. S. Du, N. Lambert, S. Min, R. Krishna, Y . Tsvetkov, H. Hajishirzi, P. W. Koh, and L. Zettlemoyer. Spurious rewards: Rethinking training signals for RLVR reasoning.arXiv preprint arXiv:2506.10947, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Z. Shao, P. Wang, Q. Zhu, R. Chen, Y . Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Liu, F. Yu, D. Huang, M. Zhang, X. Liu, Y . Luo, and ByteDance Seed. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
W. Zeng, Y . Yu, L. Luo, S. Liu, Z. Zhou, Y . Zheng, M. Sun, and Z. Liu. TTRL: Test-time reinforcement learning. arXiv preprint arXiv:2504.16084, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.