Not All Prediction Targets Keep Training-Free Diffusion Guidance on the Manifold
Pith reviewed 2026-07-02 14:30 UTC · model grok-4.3
The pith
X-prediction keeps training-free diffusion guidance samples on the data manifold most reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
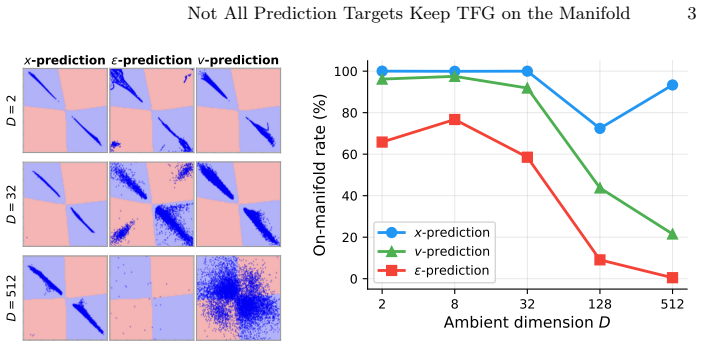
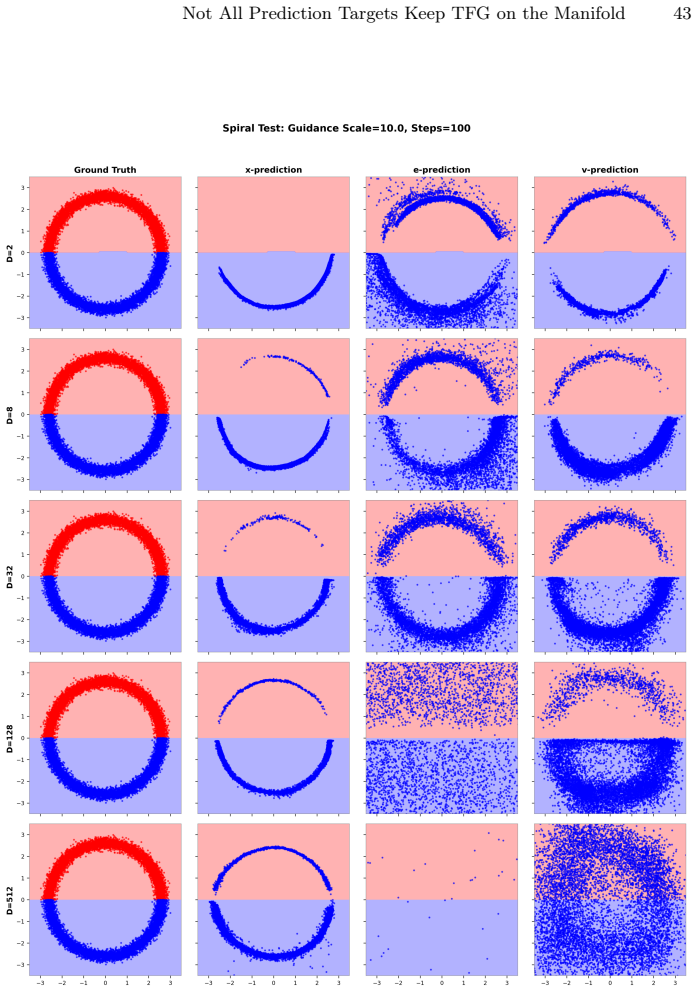
X-prediction outputs the clean image directly, removing the source of estimation error that causes ε- and v-prediction models to drift off the manifold when applying training-free guidance from high-noise steps. Theoretical analysis shows how each target shapes the accuracy of the clean-image estimate, and guided-class FID confirms the practical difference.
What carries the argument
X-prediction target, which directly predicts the clean image from the noisy state instead of requiring an intermediate estimate from noise or velocity.
If this is right
- X-prediction reduces manifold drift when guidance is applied from the earliest, highest-noise sampling steps.
- Child FID exposes manifold damage that standard FID scores miss in guided outputs.
- X-prediction supplies the most reliable base for any training-free guidance method that must start at high noise.
- The advantage appears on both fine-grained attribute guidance and style-transfer tasks.
Where Pith is reading between the lines
- Adopting x-prediction could improve the stability of guidance in other conditional tasks without retraining the underlying model.
- Manifold drift under ε- or v-prediction may silently degrade performance on downstream editing or interpolation that uses the guided samples.
- The same clean-image estimation error could affect any guidance signal that is only reliable on the data manifold.
Load-bearing premise
The guidance objective is defined only on clean images, so any error in estimating the clean image from the noisy state allows the trajectory to leave the manifold.
What would settle it
If x-prediction samples show equal or greater manifold deviation (or worse Child FID) than ε-prediction samples on the fine-grained bird benchmark, the central claim is falsified.
Figures








read the original abstract
Training-free guidance (TFG) steers a pretrained diffusion model toward a desired attribute at inference. To be effective, this guidance must be applied from the earliest, high-noise steps of sampling. Because its objective (a classifier or energy) is defined on clean images, $\epsilon$- and $v$-prediction models must first estimate the clean image $\hat{x}$ from the noisy state at each step, and the accuracy of that estimate determines how easily guidance drifts off the data manifold. $x$-prediction, a recent alternative, outputs the clean image directly, removing this source of error even at high noise. This is our motivation. We provide a theoretical analysis of how each prediction target shapes this accuracy, and introduce guided-class FID (Child FID), a metric that exposes the manifold damage standard evaluation misses. Experiments on a new fine-grained bird benchmark and on style transfer confirm that $x$-prediction keeps guided samples on the manifold most reliably, making it the strongest foundation for training-free guidance. Code is available at https://github.com/ManLuML/on-manifold-tfg
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
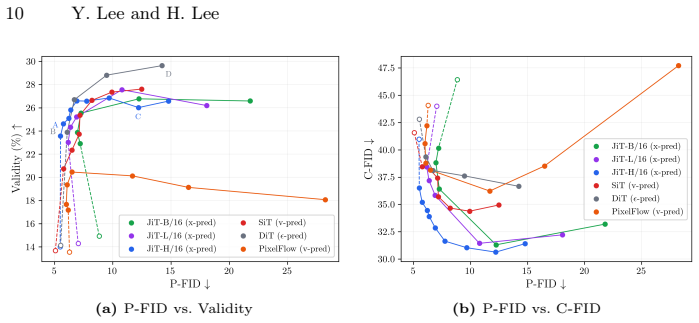
Summary. The paper claims that x-prediction is the strongest target for training-free guidance (TFG) in diffusion models because it directly outputs the clean image â, avoiding the noisy-to-clean estimation step required by ε- and v-prediction; this estimation error is analyzed theoretically as the source of manifold drift at high noise levels. The authors introduce guided-class FID (Child FID) to detect manifold damage missed by standard metrics and report confirmatory experiments on a new fine-grained bird benchmark plus style-transfer tasks showing x-prediction yields the most reliable on-manifold guided samples. Code is released.
Significance. If the central claim holds after controlling for training differences, the result would guide practitioners toward x-prediction models for TFG and supply a new diagnostic metric (Child FID) for manifold adherence. The open-source code is a clear strength for reproducibility.
major comments (2)
- [§4] §4 (Experiments, bird and style-transfer sections): the manuscript does not state whether the x-, ε-, and v-prediction models share identical architecture, training data, optimizer, capacity, or schedule. Without this control, the reported Child FID gains cannot be attributed to the inference-time prediction target rather than differences in the learned data manifold, which directly undermines the claim that x-prediction is the decisive factor.
- [§3] §3 (Theoretical analysis): the derivation assumes a fixed pretrained model and isolates only the estimation accuracy of â from noisy states; it does not address how training-induced differences in the support of the learned distribution would interact with the guidance drift analysis, leaving the link between theory and the reported empirical gains incomplete.
minor comments (2)
- The definition and computation of Child FID should be given an explicit equation or algorithm box so readers can reproduce the metric without reference to the GitHub repository.
- Figure captions for the bird and style-transfer qualitative results should include the exact guidance scale, number of sampling steps, and classifier/energy model used so that the visual comparisons are self-contained.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. Below we provide point-by-point responses to the major comments and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments, bird and style-transfer sections): the manuscript does not state whether the x-, ε-, and v-prediction models share identical architecture, training data, optimizer, capacity, or schedule. Without this control, the reported Child FID gains cannot be attributed to the inference-time prediction target rather than differences in the learned data manifold, which directly undermines the claim that x-prediction is the decisive factor.
Authors: The referee correctly notes that the manuscript does not explicitly describe the training details for the compared models. To address this, we will revise the Experiments section to state that the x-, ε-, and v-prediction models were trained with identical architecture, data, optimizer, capacity, and schedule, differing solely in the prediction target. This control ensures the gains are due to the inference-time prediction target. We will also include this information in the revised manuscript. revision: yes
-
Referee: [§3] §3 (Theoretical analysis): the derivation assumes a fixed pretrained model and isolates only the estimation accuracy of â from noisy states; it does not address how training-induced differences in the support of the learned distribution would interact with the guidance drift analysis, leaving the link between theory and the reported empirical gains incomplete.
Authors: Our theoretical analysis in §3 deliberately considers a fixed pretrained model to focus on how the prediction target affects the estimation of the clean image from noisy states during guidance. This isolates the source of manifold drift at inference time. The empirical results validate this by showing consistent advantages for x-prediction. We disagree that the link is incomplete, as the theory provides the mechanism explaining the empirical observations. However, we will add a brief discussion in the revised version to clarify the connection between the fixed-model theory and the training variations in the experiments. revision: partial
Circularity Check
No significant circularity; derivation follows from standard prediction-target definitions
full rationale
The paper's central theoretical analysis examines how ε-, v-, and x-prediction targets affect clean-image estimation accuracy during training-free guidance. This follows directly from the established mathematical definitions of each target (noise prediction, velocity prediction, direct clean-image prediction) without any reduction to author-fitted parameters, self-defined quantities, or self-citation chains. The introduced Child FID metric is a new evaluation construct, not a renaming or refit of prior results. No load-bearing step equates a claimed prediction to its own inputs by construction, and the motivation for x-prediction superiority is definitional rather than circular. The analysis remains self-contained against external diffusion-model benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision (2024)
Ahn, D., Cho, H., Min, J., Jang, W., Kim, J., Kim, S., Park, H.H., Jin, K.H., Kim, S.: Self-rectifying diffusion sampling with perturbed-attention guidance. In: European Conference on Computer Vision (2024)
2024
-
[2]
Journal of Machine Learning Research (2023)
Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E.: Stochastic interpolants: A unifying framework for flows and diffusions. Journal of Machine Learning Research (2023)
2023
-
[3]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Bansal, A., Chu, H.M., Schwarzschild, A., Sengupta, S., Goldblum, M., Geiping, J., Goldstein, T.: Universal guidance for diffusion models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
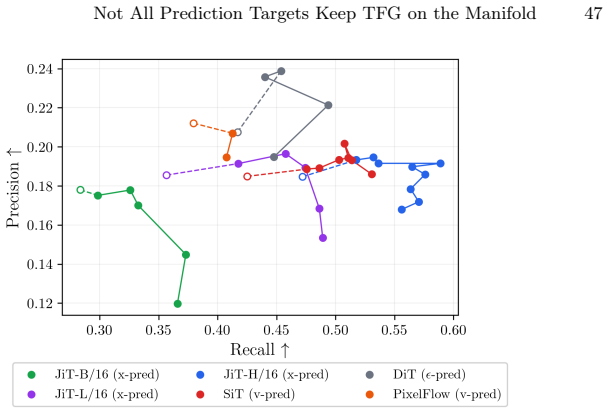
2023
-
[4]
arXiv preprint arXiv:2505.21179 (2025)
Chen,D.Y.,Bandyopadhyay,H.,Zou,K.,Song,Y.Z.:Normalizedattentionguidance: Universal negative guidance for diffusion models. arXiv preprint arXiv:2505.21179 (2025)
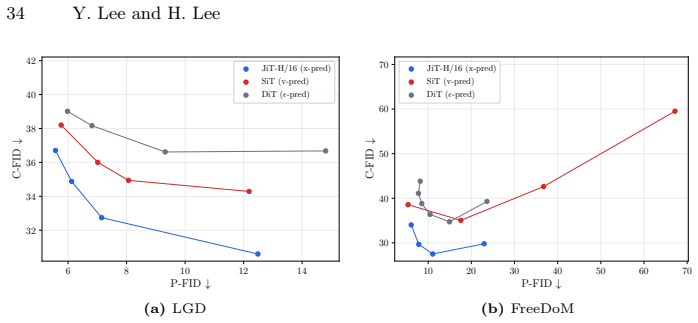
-
[5]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
-
[6]
In: Advances in Neural Information Processing Systems (2024)
Chidambaram, M., Gatmiry, K., Chen, S., Lee, H., Lu, J.: What does guidance do? A fine-grained analysis in a simple setting. In: Advances in Neural Information Processing Systems (2024)
2024
-
[7]
In: International Conference on Learning Representations (2023)
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sam- pling for general noisy inverse problems. In: International Conference on Learning Representations (2023)
2023
-
[8]
In: International Conference on Learning Representations (2025)
Chung, H., Kim, J., Park, G.Y., Nam, H., Ye, J.C.: CFG++: Manifold-constrained classifier free guidance for diffusion models. In: International Conference on Learning Representations (2025)
2025
-
[9]
In: European Conference on Computer Vision (2024)
Dai, X., Liang, K., Xiao, B.: AdvDiff: Generating unrestricted adversarial examples using diffusion models. In: European Conference on Computer Vision (2024)
2024
-
[10]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2009)
2009
-
[11]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[12]
Efron, B.: Tweedie’s formula and selection bias. Journal of the American Statistical Association106(496), 1602–1614 (2011).https://doi.org/10.1198/jasa.2011. tm11181
-
[13]
arXiv preprint arXiv:2510.02305 (2025)
Farghly, T., Potaptchik, P., Howard, S., Deligiannidis, G., Pidstrigach, J.: Diffusion models and the manifold hypothesis: Log-domain smoothing is geometry adaptive. arXiv preprint arXiv:2510.02305 (2025)
-
[14]
Journal of the American Mathematical Society29(4), 983–1049 (2016)
Fefferman, C., Mitter, S., Narayanan, H.: Testing the manifold hypothesis. Journal of the American Mathematical Society29(4), 983–1049 (2016)
2016
-
[15]
In: International Conference on Machine Learning (2025)
Feng, R., Yu, C., Deng, W., Hu, P., Wu, T.: On the guidance of flow matching. In: International Conference on Machine Learning (2025)
2025
-
[16]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
2016
-
[17]
Hairer, E., Nørsett, S.P., Wanner, G.: Solving Ordinary Differential Equations I: Nonstiff Problems, Springer Series in Computational Mathematics, vol. 8. Springer, 2nd edn. (1993)
1993
-
[18]
In: International Conference on Computer Vision (2023) Not All Prediction Targets Keep TFG on the Manifold 17
Hang, T., Gu, S., Li, C., Bao, J., Chen, D., Hu, H., Geng, X., Guo, B.: Efficient diffusion training via min-SNR weighting strategy. In: International Conference on Computer Vision (2023) Not All Prediction Targets Keep TFG on the Manifold 17
2023
-
[19]
In: International Conference on Learning Representations (2024)
He, Y., Murata, N., Lai, C.H., Takida, Y., Uesaka, T., Kim, D., Liao, W.H., Mitsufuji, Y., Kolter, J.Z., Salakhutdinov, R., Ermon, S.: Manifold preserving guided diffusion. In: International Conference on Learning Representations (2024)
2024
-
[20]
Advances in Neural Information Processing Systems30(2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in Neural Information Processing Systems30(2017)
2017
-
[21]
In: Advances in Neural Information Processing Systems (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (2020)
2020
-
[22]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
In: Advances in Neural Information Processing Systems (2024)
Hong, S.: Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention. In: Advances in Neural Information Processing Systems (2024)
2024
-
[24]
In: IEEE/CVF International Conference on Computer Vision (2023)
Hong, S., Lee, G., Jang, W., Kim, S.: Improving sample quality of diffusion models using self-attention guidance. In: IEEE/CVF International Conference on Computer Vision (2023)
2023
-
[25]
arXiv preprint arXiv:2601.21419 (2026)
Jin, Q., Wang, C.: Revisiting diffusion model predictions through dimensionality. arXiv preprint arXiv:2601.21419 (2026)
-
[26]
In: Advances in Neural Information Processing Systems (2022)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion- based generative models. In: Advances in Neural Information Processing Systems (2022)
2022
-
[27]
In: Advances in Neural Information Processing Systems (2022)
Kawar, B., Elad, M., Ermon, S., Song, J.: Denoising diffusion restoration models. In: Advances in Neural Information Processing Systems (2022)
2022
-
[28]
In: Advances in Neural Information Processing Systems
Kim, K., Ye, J.C.: Noise2score: Tweedie’s approach to self-supervised image denois- ing without clean images. In: Advances in Neural Information Processing Systems. vol. 34, pp. 864–874 (2021)
2021
-
[29]
In: International Conference on Learning Representations (2025)
Kim, S., Kim, M., Park, D.: Test-time alignment of diffusion models without reward over-optimization. In: International Conference on Learning Representations (2025)
2025
-
[30]
Back to Basics: Let Denoising Generative Models Denoise
Li, T., He, K.: Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
arXiv preprint arXiv:2509.24912 (2025)
Li, X., Shen, Z., Hsieh, Y.P., He, N.: When scores learn geometry: Rate separations under the manifold hypothesis. arXiv preprint arXiv:2509.24912 (2025)
-
[32]
In: International Conference on Learning Representations (2023)
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: International Conference on Learning Representations (2023)
2023
-
[33]
In: International Conference on Learning Representations (2023)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: International Conference on Learning Representations (2023)
2023
-
[34]
arXiv preprint arXiv:2505.09922 (2025)
Liu, Z., Zhang, W., Li, T.: Improving the euclidean diffusion generation of manifold data by mitigating score function singularity. arXiv preprint arXiv:2505.09922 (2025)
-
[35]
In: European Conference on Computer Vision (2024)
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In: European Conference on Computer Vision (2024)
2024
-
[36]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Ma, N., Tong, S., Jia, H., Hu, H., Su, Y.C., Zhang, M., Yang, X., Li, Y., Jaakkola, T., Jia, X., Xie, S.: Inference-time scaling for diffusion models beyond scaling denoising steps. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[37]
In: International Conference on Machine Learning (2020) 18 Y
Naeem, M.F., Oh, S.J., Uh, Y., Choi, Y., Yoo, J.: Reliable fidelity and diversity metrics for generative models. In: International Conference on Machine Learning (2020) 18 Y. Lee and H. Lee
2020
-
[38]
Advances in Neural Information Processing Systems23(2010)
Narayanan, H., Mitter, S.: Sample complexity of testing the manifold hypothesis. Advances in Neural Information Processing Systems23(2010)
2010
-
[39]
In: International Conference on Machine Learning (2022)
Nie, W., Guo, B., Huang, Y., Xiao, C., Vahdat, A., Anandkumar, A.: Diffusion mod- els for adversarial purification. In: International Conference on Machine Learning (2022)
2022
-
[40]
Transactions on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research (2024)
2024
-
[41]
In: International Conference on Computer Vision (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: International Conference on Computer Vision (2023)
2023
-
[42]
Advances in Neural Information Processing Systems35, 35852–35865 (2022)
Pidstrigach, J.: Score-based generative models detect manifolds. Advances in Neural Information Processing Systems35, 35852–35865 (2022)
2022
-
[43]
Kaggle (2023), https: //www.kaggle.com/datasets/gpiosenka/100- bird- species , cC0: Public Do- main
Piosenka, G.: 525 bird species – image classification. Kaggle (2023), https: //www.kaggle.com/datasets/gpiosenka/100- bird- species , cC0: Public Do- main. HuggingFace mirror:https://huggingface.co/datasets/chriamue/bird- species-dataset. Accessed 30 June 2026
2023
-
[44]
Kaggle (2023), https://www.kaggle.com/datasets/gpiosenka/butterfly- images40- species , accessed 30 June 2026
Piosenka, G.: Butterfly & moths image classification 100 species. Kaggle (2023), https://www.kaggle.com/datasets/gpiosenka/butterfly- images40- species , accessed 30 June 2026
2023
-
[45]
In: International Conference on Learning Representations (2021)
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., Goldstein, T.: The intrinsic dimension of images and its impact on learning. In: International Conference on Learning Representations (2021)
2021
-
[46]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
2021
-
[47]
In: International Conference on Machine Learning (2025)
Räisä, O., van Breugel, B., van der Schaar, M.: Position: All current generative fidelity and diversity metrics are flawed. In: International Conference on Machine Learning (2025)
2025
-
[48]
In: Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability
Robbins, H.: An empirical Bayes approach to statistics. In: Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability. vol. 1, pp. 157–163. University of California Press (1956)
1956
-
[49]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution im- age synthesis with latent diffusion models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[50]
In: Advances in Neural Information Processing Systems (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to- image diffusion models with deep language understanding. In: Advances in Neural Information Processing Systems (2022)
2022
-
[51]
In: International Conference on Learning Representations (2022)
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: International Conference on Learning Representations (2022)
2022
-
[52]
In: Advances in Neural Information Processing Systems (2024)
Shen, Y., Jiang, X., Wang, Y., Yang, Y., Han, D., Li, D.: Understanding and improv- ing training-free loss-based diffusion guidance. In: Advances in Neural Information Processing Systems (2024)
2024
-
[53]
Singhal, R., Horvitz, Z., Teehan, R., Ren, M., Yu, Z., McKeown, K., Ranganath, R.: A general framework for inference-time scaling and steering of diffusion models. arXiv preprint arXiv:2501.06848 (2025)
-
[54]
In: International Conference on Learning Representations (2023) Not All Prediction Targets Keep TFG on the Manifold 19
Song, J., Vahdat, A., Mardani, M., Kautz, J.: Pseudoinverse-guided diffusion models for inverse problems. In: International Conference on Learning Representations (2023) Not All Prediction Targets Keep TFG on the Manifold 19
2023
-
[55]
In: International Conference on Machine Learning
Song, J., Zhang, Q., Yin, H., Mardani, M., Liu, M.Y., Kautz, J., Chen, Y., Vahdat, A.: Loss-guided diffusion models for plug-and-play controllable generation. In: International Conference on Machine Learning. vol. 202, pp. 32483–32498 (2023)
2023
-
[56]
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- basedgenerativemodelingthroughstochasticdifferentialequations.In:International Conference on Learning Representations (2021)
2021
-
[57]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
Stutz, D., Hein, M., Schiele, B.: Disentangling adversarial robustness and general- ization. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[58]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021)
2021
-
[59]
Vershynin, R.: High-Dimensional Probability: An Introduction with Applications in Data Science. No. 47 in Cambridge Series in Statistical and Probabilistic Mathemat- ics,CambridgeUniversityPress(2018). https://doi.org/10.1017/9781108231596
-
[60]
In: International Conference on Learning Representations (2025)
Wang, L., Hu, C., Zhao, Y., Wu, A., Guo, Y., Li, Z.: Training free guided flow match- ing with optimal control. In: International Conference on Learning Representations (2025)
2025
-
[61]
In: Advances in Neural Information Processing Systems (2024)
Ye, H., Lin, H., Han, J., Xu, M., Liu, S., Liang, Y., Ma, J., Zou, J., Ermon, S.: Tfg: Unified training-free guidance for diffusion models. In: Advances in Neural Information Processing Systems (2024)
2024
-
[62]
In: International Conference on Computer Vision (2023)
Yu, J., Wang, Y., Zhao, C., Ghanem, B., Zhang, J.: Freedom: Training-free energy- guided conditional diffusion model. In: International Conference on Computer Vision (2023)
2023
-
[63]
Manifold Preserving Guided Diffusion
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) 20 Y. Lee and H. Lee Supplementary Material: Table of Contents – Appendix A– Manifold Hypothesis and Score Theory – Appendi...
2018
-
[64]
196,608 pixel dimensions)
Latent compression: DiT [41] and Stable Diffusion [49] operate in VAE latent space (4,096 dimensions vs. 196,608 pixel dimensions)
-
[65]
Cascaded generation: Imagen [50] and DALL-E 2 generate at low resolution first
-
[66]
Alternativetargets:PixelFlow[5]uses v-prediction;JiT[30]uses x-prediction. This pattern is consistent with the dimension scaling argument (Remark 4): ϵ-prediction requires resolving allD ambient dimensions of the noise, giving base prediction error∥δ ϵ∥2 ∼ √ D. E.4 Controlled Evidence from JiT The main body (Sec. 4.1) cites the43×FID gap betweenx- andϵ-pr...
-
[67]
Crossed-lines ablation (fully controlled, identical architecture; Sec. 5.1)
-
[68]
SiT (controlled latent pair,ϵ < v)
DiT vs. SiT (controlled latent pair,ϵ < v)
-
[69]
DiT (capacity-reversed, 131Mxbeats 675Mϵ)
JiT-B vs. DiT (capacity-reversed, 131Mxbeats 675Mϵ)
-
[70]
PixelFlow C-FID reversal (same pixel space as JiT,v < x; Sec. 5.2)
-
[71]
The conjunction is difficult to explain by any single confound
Consistent ordering across four tasks (birds, style, deblur, super-resolution; Appendix G). The conjunction is difficult to explain by any single confound. Scope.Our analysis applies to gradient-based TFG methods, those computing ∇zt E(ˆx), including DPS [7], LGD [55], TFG [61], FreeDoM [62], and Flow Guidance [15]. Attention-based methods (SAG [24], PAG ...
-
[72]
Computational overhead:Decoder forward pass required for every guidance step
-
[73]
Memory overhead:Decoder gradients must be stored for backpropagation throughD
-
[74]
Potential reconstruction error:VAE reconstruction artifacts may affect guidance quality For pixel-spacex-prediction (JiT), guidance operates directly: gt =ρ∇ xt logp(y|ˆx)(33) withnodecodesteprequired.Thisgivespixel-spacemodelsanefficiencyadvantage beyond the prediction target effects analyzed in Sec. 3.2. G Experimental Protocols and Full Results G.1 Fac...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.