Neural Language Model Based Training Data Augmentation for Weakly Supervised Early Rumor Detection
Pith reviewed 2026-05-24 21:09 UTC · model grok-4.3
The pith
Neural language model augments rumor data to boost detection F-score by 12.1%
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a neural language model on large credibility-focused Twitter corpora, context-sensitive representations of rumor tweets can be learned to augment limited labeled data with semantically related unlabeled event tweets, resulting in expanded datasets and improved performance of deep learning rumor detection models.
What carries the argument
The neural language model providing context-sensitive tweet representations for identifying augmentable unlabeled data based on semantic relatedness to labeled rumors.
Load-bearing premise
Semantic relatedness learned by the neural language model between labeled rumor tweets and unlabeled data is enough to keep the rumor spreading patterns and correct class labels without too much noise.
What would settle it
A test showing that models trained with the augmented data do not achieve higher F-score than those with original data on a standard rumor detection benchmark would disprove the benefit.
Figures

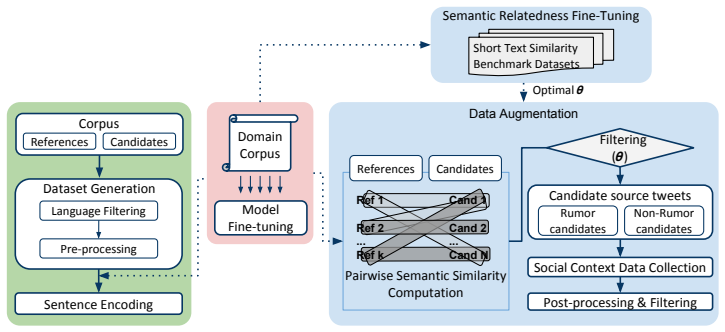
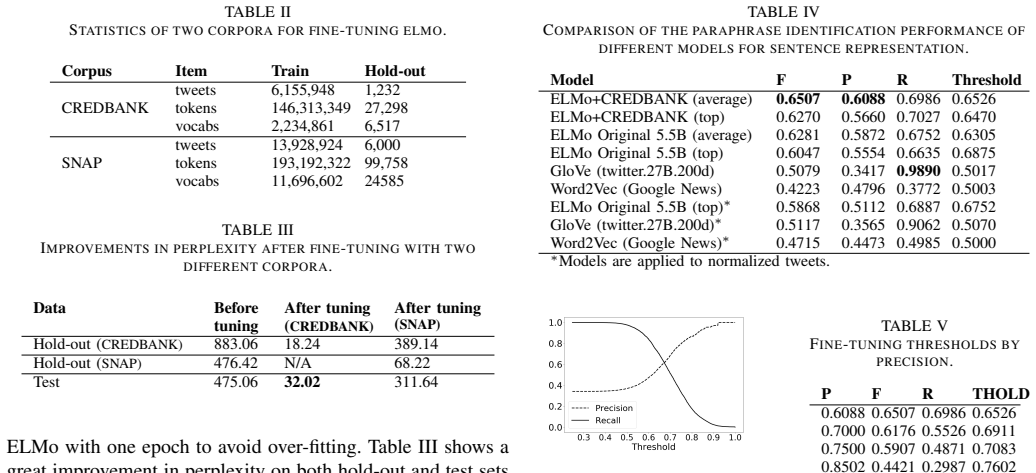
read the original abstract
The scarcity and class imbalance of training data are known issues in current rumor detection tasks. We propose a straight-forward and general-purpose data augmentation technique which is beneficial to early rumor detection relying on event propagation patterns. The key idea is to exploit massive unlabeled event data sets on social media to augment limited labeled rumor source tweets. This work is based on rumor spreading patterns revealed by recent rumor studies and semantic relatedness between labeled and unlabeled data. A state-of-the-art neural language model (NLM) and large credibility-focused Twitter corpora are employed to learn context-sensitive representations of rumor tweets. Six different real-world events based on three publicly available rumor datasets are employed in our experiments to provide a comparative evaluation of the effectiveness of the method. The results show that our method can expand the size of an existing rumor data set nearly by 200% and corresponding social context (i.e., conversational threads) by 100% with reasonable quality. Preliminary experiments with a state-of-the-art deep learning-based rumor detection model show that augmented data can alleviate over-fitting and class imbalance caused by limited train data and can help to train complex neural networks (NNs). With augmented data, the performance of rumor detection can be improved by 12.1% in terms of F-score. Our experiments also indicate that augmented training data can help to generalize rumor detection models on unseen rumors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a data augmentation technique for early rumor detection that exploits a neural language model trained on large credibility-focused Twitter corpora to expand limited labeled rumor source tweets using unlabeled event data. The approach relies on semantic relatedness and established rumor spreading patterns to generate additional training examples and their conversational threads. Experiments across six real-world events drawn from three public rumor datasets show that the method nearly doubles the size of existing rumor datasets (200% for source tweets, 100% for threads) with reasonable quality, alleviates overfitting and class imbalance, yields a 12.1% F-score gain when training a state-of-the-art deep learning rumor detector, and improves generalization to unseen rumors.
Significance. If the central claim holds, the work would be significant for addressing data scarcity and imbalance in social-media rumor detection, a persistent practical bottleneck. The method is presented as general-purpose, grounded in prior rumor-propagation studies, and evaluated via cross-event and cross-dataset protocols on publicly available data; these are clear strengths. The reported ability to expand training sets while improving neural-network performance on limited labels could have downstream utility for weakly supervised settings, provided the augmentation quality and label preservation are rigorously demonstrated.
major comments (2)
- [Abstract] Abstract: the augmentation mechanism is described only at a high level with no concrete specification of how semantic relatedness is computed (e.g., similarity metric, threshold, or selection criterion), how class labels are transferred to new examples, or how spreading-pattern fidelity is enforced. This detail is load-bearing for the 12.1% F-score claim and the assertion that augmented data preserves underlying rumor patterns.
- [Abstract] Abstract: no quantitative validation of augmented-data quality (human or automatic), no statistical significance tests, no error bars, and no full experimental protocol (train/test splits across the six events, baseline details) are reported. These omissions directly affect assessment of whether the reported gains are reliable or attributable to the augmentation rather than other factors.
minor comments (1)
- [Abstract] Abstract: the reported expansion rates (nearly 200% and 100%) are given without base dataset sizes or exact counts, which would improve reproducibility and context for the scale of the augmentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract to provide greater specificity while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the augmentation mechanism is described only at a high level with no concrete specification of how semantic relatedness is computed (e.g., similarity metric, threshold, or selection criterion), how class labels are transferred to new examples, or how spreading-pattern fidelity is enforced. This detail is load-bearing for the 12.1% F-score claim and the assertion that augmented data preserves underlying rumor patterns.
Authors: We agree the abstract is high-level. The manuscript body specifies that semantic relatedness is obtained via context-sensitive representations learned by the NLM on credibility-focused Twitter corpora, with examples selected according to established rumor propagation patterns from prior studies; labels are transferred directly from the source labeled tweets to the generated examples and threads. To make this load-bearing information accessible from the abstract, we will add a concise clause describing the NLM-based representation similarity and label-transfer rule. revision: yes
-
Referee: [Abstract] Abstract: no quantitative validation of augmented-data quality (human or automatic), no statistical significance tests, no error bars, and no full experimental protocol (train/test splits across the six events, baseline details) are reported. These omissions directly affect assessment of whether the reported gains are reliable or attributable to the augmentation rather than other factors.
Authors: The abstract already states the key quantitative outcomes (200% source-tweet expansion, 100% thread expansion, 12.1% F-score gain) obtained from experiments on six events drawn from three public datasets under cross-event and cross-dataset protocols. We will expand the abstract by one sentence that references the evaluation protocol and notes that augmented-data quality was assessed via downstream detector performance. The full manuscript supplies the train/test splits, baseline descriptions, and dataset details; if the original experiments lack formal significance tests or error bars, we can add them in revision where feasible. revision: partial
Circularity Check
No significant circularity in empirical augmentation pipeline
full rationale
The paper describes an empirical data-augmentation pipeline that trains an NLM on external Twitter corpora, computes semantic relatedness to expand labeled rumor tweets and threads, and evaluates the resulting classifier on six public events with cross-dataset testing. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or method outline; the reported 12.1% F-score lift is measured against held-out data rather than being definitionally forced by the augmentation step itself. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- semantic similarity threshold or quality filter
axioms (1)
- domain assumption Semantic similarity via NLM preserves rumor class labels and propagation patterns
Lean theorems connected to this paper
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a straight-forward and general-purpose data augmentation technique which is beneficial to early rumor detection relying on event propagation patterns. The key idea is to exploit massive unlabeled event data sets on social media to augment limited labeled rumor source tweets.
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ELMo is adopted to learn effective representation of tweets... cosine similarity between vector representation of two sentences is a common metric for measuring semantic similarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rumor Detection over Varying Time Windows,
S. Kwon, M. Cha, and K. Jung, “Rumor Detection over Varying Time Windows,” PLOS ONE, vol. 12, no. 1, pp. 1–19, 2017
work page 2017
-
[2]
Rumor detection on twitter with tree- structured recursive neural networks,
K.-F. Wong, W. Gao, and J. Ma, “Rumor detection on twitter with tree- structured recursive neural networks,” in ACL, 2018
work page 2018
-
[3]
Verifying information with multimedia content on twitter,
C. Boididou, S. E. Middleton, Z. Jin, S. Papadopoulos, D.-T. Dang- Nguyen, G. Boato, and Y . Kompatsiaris, “Verifying information with multimedia content on twitter,” Multimedia Tools and Applications , vol. 77, no. 12, pp. 15 545–15 571, 2018
work page 2018
-
[4]
All-in-one: Multi-task learn- ing for rumour verification,
E. Kochkina, M. Liakata, and A. Zubiaga, “All-in-one: Multi-task learn- ing for rumour verification,” in Proceedings of the 27th International Conference on Computational Linguistics , 2018, pp. 3402–3413
work page 2018
-
[5]
Learning reporting dynamics during breaking news for rumour detection in social media,
A. Zubiaga, M. Liakata, and R. Procter, “Learning reporting dynamics during breaking news for rumour detection in social media,” CoRR, 2016
work page 2016
-
[6]
Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection,
T. Chen, X. Li, H. Yin, and J. Zhang, “Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining . Springer, 2018, pp. 40–52
work page 2018
-
[7]
Detecting rumors from microblogs with recurrent neural networks,
J. Ma, W. Gao, P. Mitra, S. Kwon, B. J. Jansen, K.-F. Wong, and M. Cha, “Detecting rumors from microblogs with recurrent neural networks,” in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, ser. IJCAI’16, 2016, pp. 3818–3824
work page 2016
-
[8]
G. Zhong, L.-N. Wang, X. Ling, and J. Dong, “An overview on data representation learning: From traditional feature learning to recent deep learning,” The Journal of Finance and Data Science , vol. 2, no. 4, pp. 265–278, 2016
work page 2016
-
[9]
Stance classification in out-of-domain rumours: A case study around mental health disorders,
A. Aker, A. Zubiaga, K. Bontcheva, A. Kolliakou, R. Procter, and M. Liakata, “Stance classification in out-of-domain rumours: A case study around mental health disorders,” in International Conference on Social Informatics. Springer, 2017, pp. 53–64
work page 2017
-
[10]
Y . Liu, X. Jin, H. Shen, and X. Cheng, “Do rumors diffuse differently from non-rumors? a systematically empirical analysis in sina weibo for rumor identification,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining . Springer, 2017, pp. 407–420
work page 2017
-
[11]
Scalable rumor source detection under independent cascade model in online social networks,
W. Xu and H. Chen, “Scalable rumor source detection under independent cascade model in online social networks,” in 2015 11th International Conference on Mobile Ad-hoc and Sensor Networks (MSN) . IEEE, 2015, pp. 236–242
work page 2015
-
[12]
Exploiting context for rumour detection in social media,
A. Zubiaga, M. Liakata, and R. Procter, “Exploiting context for rumour detection in social media,” in International Conference on Social Infor- matics. Springer, 2017, pp. 109–123
work page 2017
-
[13]
Characterizing online rumoring behavior using multi- dimensional signatures,
J. Maddock, K. Starbird, H. J. Al-Hassani, D. E. Sandoval, M. Orand, and R. M. Mason, “Characterizing online rumoring behavior using multi- dimensional signatures,” in Proceedings of the 18th ACM conference on computer supported cooperative work & social computing. ACM, 2015, pp. 228–241
work page 2015
-
[14]
Social media and the gen- eration, propagation, and debunking of rumours,
C. Baxter, P. Barratt, and M. Thomson, “Social media and the gen- eration, propagation, and debunking of rumours,” Report on behalf of Department of National Defence, Canada. Ontario: Human Systems Incorporated, 2015
work page 2015
-
[15]
How information snowballs: Exploring the role of exposure in online rumor propagation,
A. Arif, K. Shanahan, F.-J. Chou, Y . Dosouto, K. Starbird, and E. S. Spiro, “How information snowballs: Exploring the role of exposure in online rumor propagation,” in Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing. ACM, 2016, pp. 466–477
work page 2016
-
[16]
Enquiring minds: Early detection of rumors in social media from enquiry posts,
Z. Zhao, P. Resnick, and Q. Mei, “Enquiring minds: Early detection of rumors in social media from enquiry posts,” in Proceedings of the 24th International Conference on World Wide Web , ser. WWW ’15. International World Wide Web Conferences Steering Committee, 2015, pp. 1395–1405
work page 2015
-
[17]
Deep contextualized word representations
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” arXiv preprint arXiv:1802.05365, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Character-level convolutional networks for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional networks for text classification,” in Advances in neural information processing systems, 2015, pp. 649–657
work page 2015
-
[19]
Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder,
S. V osoughi, P. Vijayaraghavan, and D. Roy, “Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder,” in Pro- ceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval , 2016, pp. 1041–1044
work page 2016
-
[20]
DeepStance at SemEval-2016 Task 6: Detecting Stance in Tweets Using Character and Word-Level CNNs
P. Vijayaraghavan, I. Sysoev, S. V osoughi, and D. Roy, “Deepstance at semeval-2016 task 6: Detecting stance in tweets using character and word-level cnns,” arXiv preprint arXiv:1606.05694 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Contextual augmentation: Data augmentation by words with paradigmatic relations,
S. Kobayashi, “Contextual augmentation: Data augmentation by words with paradigmatic relations,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) . New Orleans, Louisiana: Association for Computational Linguistics, Jun. 2018, pp. 452–457
work page 2018
-
[22]
A text data augmentation approach for improving the performance of cnn,
M. Abulaish and K. Sah, Amit, “A text data augmentation approach for improving the performance of cnn,” in Proceedings of the MINDS Workshop,the 11th International Conference on Communication Systems and Networks (COMSNETS) , Banglore, India, 2019, pp. 1–6
work page 2019
-
[23]
Atalaya at tass 2018: Sentiment analysis with tweet embeddings and data augmentation,
F. M. Luque and J. M. P ´erez, “Atalaya at tass 2018: Sentiment analysis with tweet embeddings and data augmentation,” Proceedings of TASS , vol. 2172, 2018
work page 2018
-
[24]
What to expect when the unexpected happens: Social media communications across crises,
A. Olteanu, S. Vieweg, and C. Castillo, “What to expect when the unexpected happens: Social media communications across crises,” in Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing . ACM, 2015, pp. 994–1009
work page 2015
-
[25]
A longitudinal assessment of the persistence of twitter datasets,
A. Zubiaga, “A longitudinal assessment of the persistence of twitter datasets,” JASIST, vol. 69, pp. 974–984, 2018
work page 2018
-
[26]
Extract- ing lexically divergent paraphrases from Twitter,
W. Xu, A. Ritter, C. Callison-Burch, W. B. Dolan, and Y . Ji, “Extract- ing lexically divergent paraphrases from Twitter,” Transactions of the Association for Computational Linguistics , 2014
work page 2014
-
[27]
Credbank: A large-scale social media corpus with associated credibility annotations,
T. Mitra and E. Gilbert, “Credbank: A large-scale social media corpus with associated credibility annotations,” in Ninth International AAAI Conference on Web and Social Media , 2015
work page 2015
-
[28]
Patterns of temporal variation in online media,
J. Yang and J. Leskovec, “Patterns of temporal variation in online media,” in Proceedings of the fourth ACM international conference on Web search and data mining . ACM, 2011, pp. 177–186
work page 2011
-
[29]
Event detection in twitter using ag- gressive filtering and hierarchical tweet clustering,
G. Ifrim, B. Shi, and I. Brigadir, “Event detection in twitter using ag- gressive filtering and hierarchical tweet clustering,” in Second Workshop on Social News on the Web (SNOW), Seoul, Korea . ACM, 2014
work page 2014
-
[30]
Reading the riots on twitter: method- ological innovation for the analysis of big data,
R. Procter, F. Vis, and A. V oss, “Reading the riots on twitter: method- ological innovation for the analysis of big data,” International journal of social research methodology , vol. 16, no. 3, pp. 197–214, 2013
work page 2013
-
[31]
Convolutional Neural Networks for Sentence Classification
Y . Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Evaluation of sentence embeddings in downstream and linguistic probing tasks
C. S. Perone, R. Silveira, and T. S. Paula, “Evaluation of sentence embeddings in downstream and linguistic probing tasks,” arXiv preprint arXiv:1806.06259, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.