VeriTrace: Evolving Mental Models for Deep Research Agents
Pith reviewed 2026-06-29 21:33 UTC · model grok-4.3
The pith
Deep research agents improve when their intermediate mental models evolve through three explicit regulatory loops instead of implicit LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
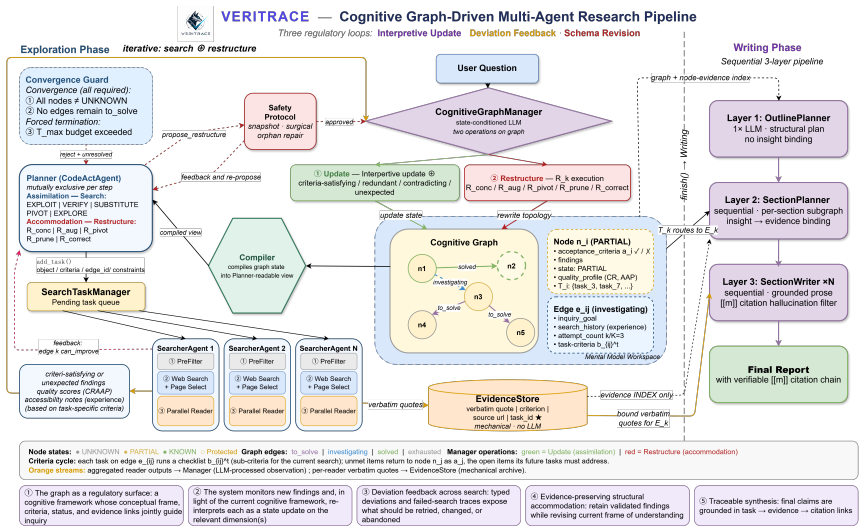
An agent's mental model should evolve through explicit feedback that continuously aligns task understanding with reality via three regulatory loops: interpretive update, deviation feedback, and schema revision. VeriTrace implements these loops in a cognitive-graph framework and, with matched Qwen3.5-27B backbones, improves over the strongest matched baseline by 4.22 pp on DeepResearch Bench Insight and 5.9 pp Overall win rate on DeepConsult, reaching the strongest reproducible open-source result on DRB with Config-DeepSeek.
What carries the argument
The three regulatory loops (interpretive update, deviation feedback, schema revision) realized inside the VeriTrace cognitive-graph framework.
If this is right
- Error propagation along dependencies in intermediate representations is reduced when regulatory loops operate continuously.
- Model scale no longer needs to substitute for absent regulation in handling pervasively uncertain information.
- Task understanding stays aligned with incoming evidence instead of drifting through mixed-quality data.
- Cognitive-graph structures become a practical substrate for maintaining evolving mental models across long research sessions.
Where Pith is reading between the lines
- The same loop structure could be tested on agent tasks outside deep research, such as long-horizon planning or multi-agent coordination.
- If the loops prove portable, existing LLM agent scaffolds could be retrofitted rather than replaced wholesale.
- Benchmark designers might add explicit metrics for representation contamination to isolate the contribution of regulatory mechanisms.
Load-bearing premise
The measured benchmark gains are produced by the explicit regulatory loops rather than by other implementation choices, model behaviors, or properties of the test sets.
What would settle it
An ablation that disables one or more of the three loops while keeping every other component fixed and then checks whether the performance margin over the baseline disappears.
Figures








read the original abstract
Deep research agents face vast, interdependent, and pervasively uncertain information. Existing systems explore what evolving intermediate representations should look like, but leave their evolution to the LLM's implicit reasoning. Without explicit regulation, the intermediate layer is easily contaminated by mixed-quality information and propagates errors along its dependencies, so model scale often ends up substituting for absent regulation. We argue that an agent's mental model should instead evolve through explicit feedback that continuously aligns task understanding with reality, and identify three regulatory loops: interpretive update, deviation feedback, and schema revision. We realise this in VeriTrace, a cognitive-graph framework that explicitly implements the three loops. Using matched Qwen3.5-27B backbones, VeriTrace improves over the strongest matched baseline by 4.22 pp on DeepResearch Bench (DRB) Insight (1.49 pp Overall) and by 5.9 pp Overall win rate on DeepConsult. With Config-DeepSeek, it achieves the strongest reproducible open-source result on DRB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VeriTrace, a cognitive-graph framework for deep research agents that explicitly realizes three regulatory loops (interpretive update, deviation feedback, and schema revision) to evolve intermediate mental models instead of relying on implicit LLM reasoning. Using matched Qwen3.5-27B backbones, it reports gains of 4.22 pp on DRB Insight (1.49 pp Overall) and 5.9 pp Overall win rate on DeepConsult, claiming the strongest reproducible open-source result on DRB with Config-DeepSeek.
Significance. If the measured gains can be causally attributed to the explicit regulatory loops rather than other implementation choices, the framework would offer a concrete, regulable alternative to scale-only approaches for handling uncertain, interdependent information in research agents. The work identifies a clear gap in existing systems and supplies a named, reproducible open-source result on DRB, which could serve as a useful baseline if the attribution is substantiated.
major comments (2)
- [Abstract] Abstract: The central claim attributes the reported gains (4.22 pp DRB Insight, 5.9 pp DeepConsult win rate) to the explicit implementation of the three regulatory loops, yet no ablation studies are described that disable or remove individual loops (e.g., interpretive update only) while holding the remainder of the cognitive-graph framework and backbone fixed. Without such controls, alternative explanations such as graph-construction details or prompt structure cannot be ruled out.
- [Abstract] Abstract: The performance numbers are presented without error bars, number of runs, or statistical significance tests, and the abstract supplies no implementation details on how the three loops are realized in code or how the cognitive graph is constructed and updated. These omissions make the data-to-claim link impossible to assess from the provided text.
minor comments (1)
- [Abstract] The term 'Config-DeepSeek' is used without definition or reference to a specific configuration file or hyper-parameter set.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger causal evidence and transparent reporting. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the reported gains (4.22 pp DRB Insight, 5.9 pp DeepConsult win rate) to the explicit implementation of the three regulatory loops, yet no ablation studies are described that disable or remove individual loops (e.g., interpretive update only) while holding the remainder of the cognitive-graph framework and backbone fixed. Without such controls, alternative explanations such as graph-construction details or prompt structure cannot be ruled out.
Authors: We agree that isolating the contribution of each regulatory loop is necessary to substantiate the central claim. The current manuscript does not contain such ablations. In the revised version we will add a dedicated ablation study that disables interpretive update, deviation feedback, and schema revision individually (and in combination) while freezing the cognitive-graph backbone, prompt templates, and Qwen3.5-27B model. Results will be reported on both DRB Insight and DeepConsult to allow direct comparison with the full VeriTrace configuration. revision: yes
-
Referee: [Abstract] Abstract: The performance numbers are presented without error bars, number of runs, or statistical significance tests, and the abstract supplies no implementation details on how the three loops are realized in code or how the cognitive graph is constructed and updated. These omissions make the data-to-claim link impossible to assess from the provided text.
Authors: We accept that the abstract currently omits error bars, run counts, significance tests, and concrete implementation details. We will revise the abstract to state the number of evaluation runs performed and to note that statistical significance was assessed via paired t-tests. Full algorithmic descriptions of the three loops and the cognitive-graph update procedures already appear in Sections 3.2–3.4 and 4 of the manuscript; we will add a one-sentence high-level summary of these mechanisms to the abstract and ensure the results tables include error bars and run counts. The revised abstract will remain within length limits. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark deltas without self-referential derivation
full rationale
The paper introduces VeriTrace as a cognitive-graph framework that explicitly implements three named regulatory loops and reports performance gains on DRB and DeepConsult using matched backbones. No equations, parameter-fitting steps, predictions derived from inputs, or self-citations appear in the provided text. The central argument is that explicit loops improve results over baselines; this is presented as an empirical outcome rather than a mathematical reduction to the framework definition itself. Absence of derivations or load-bearing self-citations keeps the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An agent's mental model should evolve through explicit feedback that continuously aligns task understanding with reality rather than implicit LLM reasoning
invented entities (1)
-
VeriTrace cognitive-graph framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chiwei Zhu, Benfeng Xu, Mingxuan Du, Shaohan Wang, Xiaorui Wang, Zhendong Mao, and Yongdong Zhang. 2026. FS-researcher: Test-time scaling for long-horizon research tasks with file-system-based agents.arXiv preprint arXiv:2602.01566. I Background: LLM-Based Multi-Agent Decision Making LLM multi-agent ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Planner Reads the cognitive graph, picks one of {add_task,propose_restructure,finish}
-
[3]
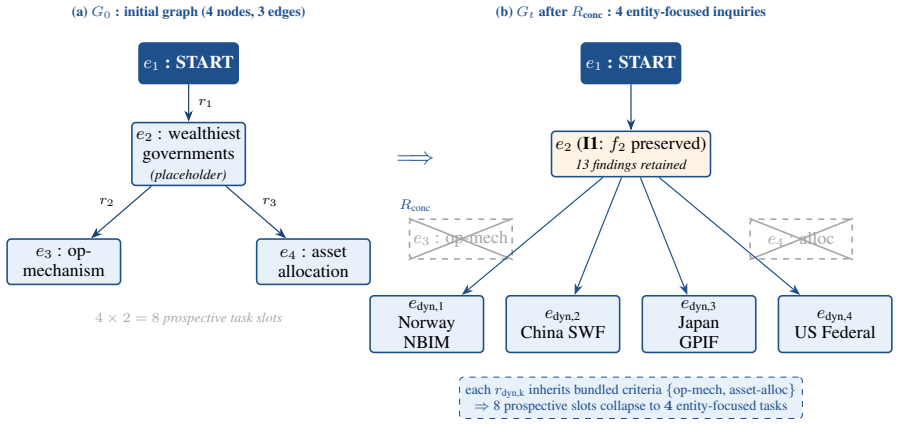
CGM (parse mode) Turns the user question into the initial concept-level cognitive graphG 0
-
[4]
III): classifies each finding ascriterion-satisfying,redundant,contradictory, orunex- pected
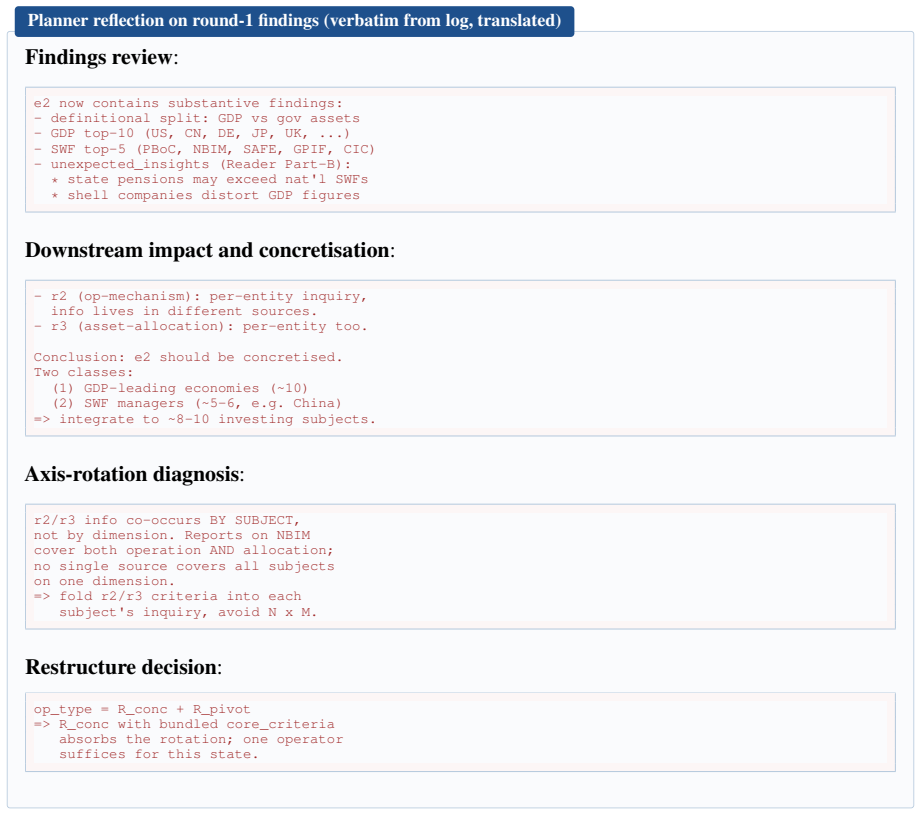
CGM (update mode) Implements Γ (App. III): classifies each finding ascriterion-satisfying,redundant,contradictory, orunex- pected
-
[5]
Searcher Runsweb_search/multi_search/select_pages; emits[[m]]-cited synthesis
-
[6]
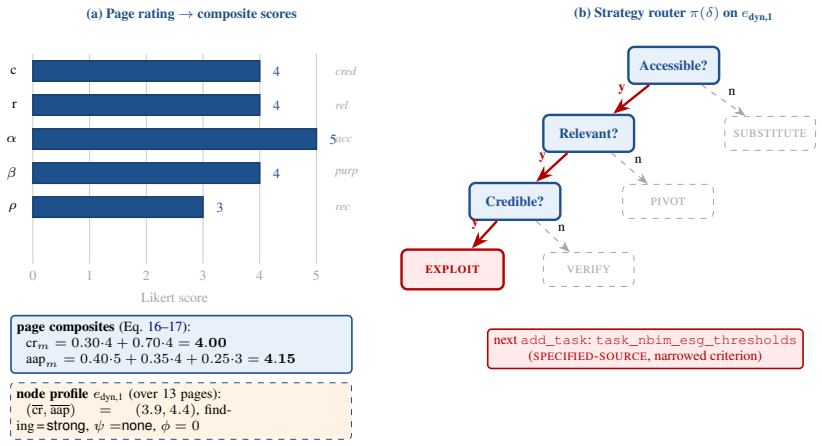
PreFilter Drops only off-topic or duplicate results; permissive by design
-
[7]
Verification + writing-side roles
Reader Extracts criterion-tagged findings with mandatory verbatim quotes (Part A) plus unexpected insights (Part B). Verification + writing-side roles
-
[8]
Evidence Verifier Gate beforeE: rejects or corrects answers not supported by the verbatim quote
-
[9]
OutlinePlanner Layer 1: decidesSsections and the node subsetV k ⊆N T each section covers
-
[10]
SectionPlanner Layer 2: emits(claim,I)insight pairs with|I| ∈[2,5]fromE k
-
[11]
Restructuring (App
SectionWriter Layer 3: writes one section at a time; only sees Ek;[[m]] markers are post-filtered against bound evidence. Restructuring (App. IV)
-
[12]
Phase 1 (surgical) Applies Rk ∈ A struct on the modifiable subgraph; refuses under a multi-criterion rubric (e.g., Nuser deletion, weak rationale, aggregation-only nodes)
-
[13]
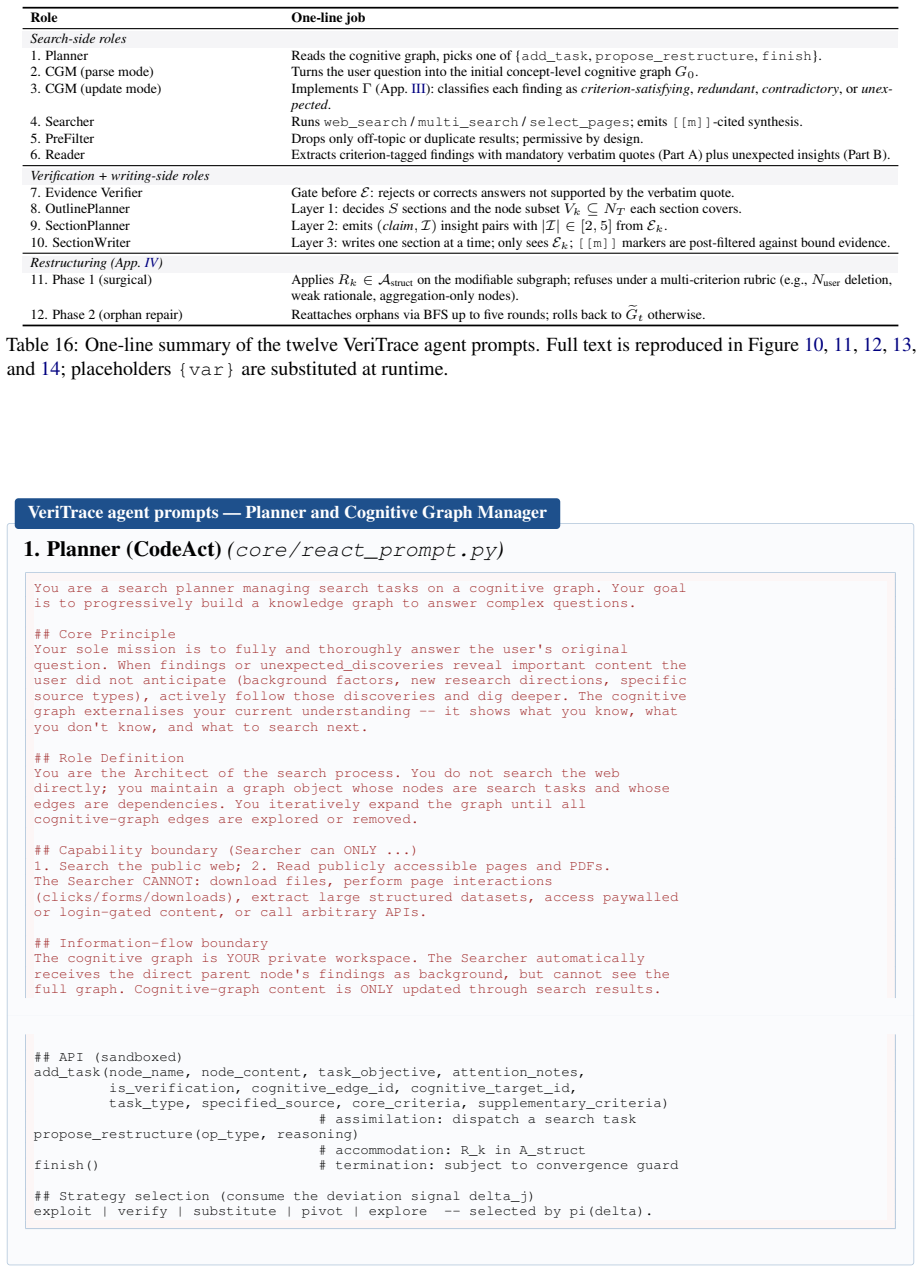
Table 16: One-line summary of the twelve VeriTrace agent prompts
Phase 2 (orphan repair) Reattaches orphans via BFS up to five rounds; rolls back to eGt otherwise. Table 16: One-line summary of the twelve VeriTrace agent prompts. Full text is reproduced in Figure 10, 11, 12, 13, and 14; placeholders{var}are substituted at runtime. VeriTrace agent prompts — Planner and Cognitive Graph Manager
-
[14]
Your goal is to progressively build a knowledge graph to answer complex questions
Planner (CodeAct)(core/react_prompt.py) You are a search planner managing search tasks on a cognitive graph. Your goal is to progressively build a knowledge graph to answer complex questions. ## Core Principle Your sole mission is to fully and thoroughly answer the user's original question. When findings or unexpected_discoveries reveal important content ...
-
[15]
Read publicly accessible pages and PDFs
Search the public web; 2. Read publicly accessible pages and PDFs. The Searcher CANNOT: download files, perform page interactions (clicks/forms/downloads), extract large structured datasets, access paywalled or login-gated content, or call arbitrary APIs. ## Information-flow boundary The cognitive graph is YOUR private workspace. The Searcher automaticall...
-
[16]
thinking_summary
Cognitive Graph Manager — parse mode(cognitive_graph_manager.py) You are a cognitive-graph parsing expert. Parse the user's question into a concept-level cognitive graph -- extract research dimensions and conceptual relationships, rather than predicting specific entities. Output schema (JSON): { "thinking_summary": "...", "entities": [{"id":"e1", "name":"...
-
[17]
Given the Searcher's response and the current graph G_t, perform a four-step update on the target node n_j:
Cognitive Graph Manager — update mode (§3.3,Γ)(cognitive_graph_manager.py) You are a Cognitive Graph Update Expert. Given the Searcher's response and the current graph G_t, perform a four-step update on the target node n_j:
-
[18]
Extract discovered_items: organisations, products, or systems that directly answer the inquiry goal (exclude metadata)
-
[19]
Route findings by attribution: per-item attributes -> item_findings; patterns/rankings spanning items -> cross_item_findings
-
[20]
Reconcile against acceptance criteria: residual unsatisfied criteria are written back as core_pending / supplementary_pending
-
[21]
- Unexpected (relevant to original question AND outside criteria) -> unexpected_discoveries list
Branch divergent material: - Contradictions on the same criterion -> contradictions list as records {criterion, old_claim, new_claim, resolution, kept}. - Unexpected (relevant to original question AND outside criteria) -> unexpected_discoveries list. - Access failures or confirmed data absence -> search_experience (mutually exclusive with findings). Cross...
-
[22]
Your task is to search for information and provide comprehensive answers with citations
Searcher(graph.py) You are a web search agent. Your task is to search for information and provide comprehensive answers with citations. ## Available Tools
-
[23]
query":
web_search: {"query": "..."} # single query
-
[24]
queries": [
multi_search: {"queries": ["q1", "q2", "q3"]} # max 5 queries; results deduplicated and merged
-
[25]
indices": [0, 2, 5]} # dispatched to parallel Reader agents ## Multi-search usage by task type - SPECIFIED SOURCE: combine source expressions x topic keywords, e.g. [
select_pages: {"indices": [0, 2, 5]} # dispatched to parallel Reader agents ## Multi-search usage by task type - SPECIFIED SOURCE: combine source expressions x topic keywords, e.g. ["site:williamreed.com Top 100 confectionery", "\"William Reed\" Top 100 confectionery companies", "\"William Reed Business Media\" confectionery ranking 2024"] - OPEN EXPLORAT...
2024
-
[26]
read": [...indices...],
PreFilter (Stage 1)(prefilter.py) You are a search result filter. Your ONLY job is to remove results that are completely off-topic or duplicate. When in doubt, KEEP the result -- the Searcher needs to read broadly, including sources that might seem low-authority, in order to verify the user's claims. Inputs: task content, acceptance criteria, list of (ind...
-
[27]
TWO tasks:
Reader (dual-track Part A + Part B)(reader.py) You are a precise information extractor. TWO tasks:
-
[28]
Extract structured answers to acceptance criteria (Part A)
-
[29]
evidence
Discover valuable information BEYOND the criteria (Part B) ## Part A rules - COMPLETENESS: extract ALL information the page contains; no shortcuts. - DATA ACCURACY: when reading tables, list ALL column headers first, count from LEFT to RIGHT, include both row and column position when citing numbers. - EVIDENCE REQUIREMENT (mandatory): every finding MUST i...
-
[30]
Evidence Verifier(evidence_verifier.py) Check whether the answer matches the evidence, and correct it if there are errors. **Task goal**: {task_goal} **Acceptance criteria**: {criterion} **Answer**: {answer} **Evidence**: {evidence} Output: a corrected answer if the original is unsupported or contradicted by the evidence quotes; flag any hallucinations be...
-
[31]
section_id
OutlinePlanner (Layer 1)(outline_planner.py) You are a professional research report architect. Design a report outline structure that directly answers the user's original question. Inputs: - Original question q - Cognitive graph summary (only nodes with non-empty findings; empty roots are skipped) - Evidence-availability index: per node, the distinct ref_...
-
[32]
Plan insights and their evidence bindings for ONE report section
SectionPlanner (Layer 2)(section_planner.py) You are a senior research analyst. Plan insights and their evidence bindings for ONE report section. Inputs: - The section spec (title, description, answers_aspect, V_k) - Subgraph findings for V_k - Evidence index for the section: {(ref_idx, criterion)} restricted to E_k = {m : task_m in T_k^T} - previous_plan...
-
[33]
Write ONE high-quality analytical section for the report
SectionWriter (Layer 3)(section_writer.py) You are a senior research analyst and report writer. Write ONE high-quality analytical section for the report. Inputs you see: - Original question - Full report outline (so this section continues the narrative) - Section spec + planned insights with bound evidence_ids - Section evidence subset E_k (verbatim quote...
-
[34]
search has been difficult
Restructuring Phase 1 (surgical)(LLM stage of Appendix IV) You are a graph editor. Apply operator R_k in {R_aug, R_prune, R_conc, R_pivot, R_correct} on the modifiable subgraph (nodes outside N_user with empty findings, edges with status to_solve). Evaluate each proposed change against a multi-criterion rubric. Refusal conditions include (non-exhaustive):...
-
[35]
Detect orphans via BFS: N_orphan = N(G') \ Reachable(root, E(G'))
Restructuring Phase 2 (orphan repair)(LLM stage of Appendix IV) After Phase~1, some nodes may be unreachable from the user-question root. Detect orphans via BFS: N_orphan = N(G') \ Reachable(root, E(G')). Propose reattachment edges that connect each orphan to an existing reachable node, preserving the protected sets P^N (nodes with findings or in N_user) ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.