LEVIRDet: A Million-Scale 159-Category Dataset and Foundation Model for Universal Remote Sensing Object Detection
Pith reviewed 2026-06-25 21:28 UTC · model grok-4.3
The pith
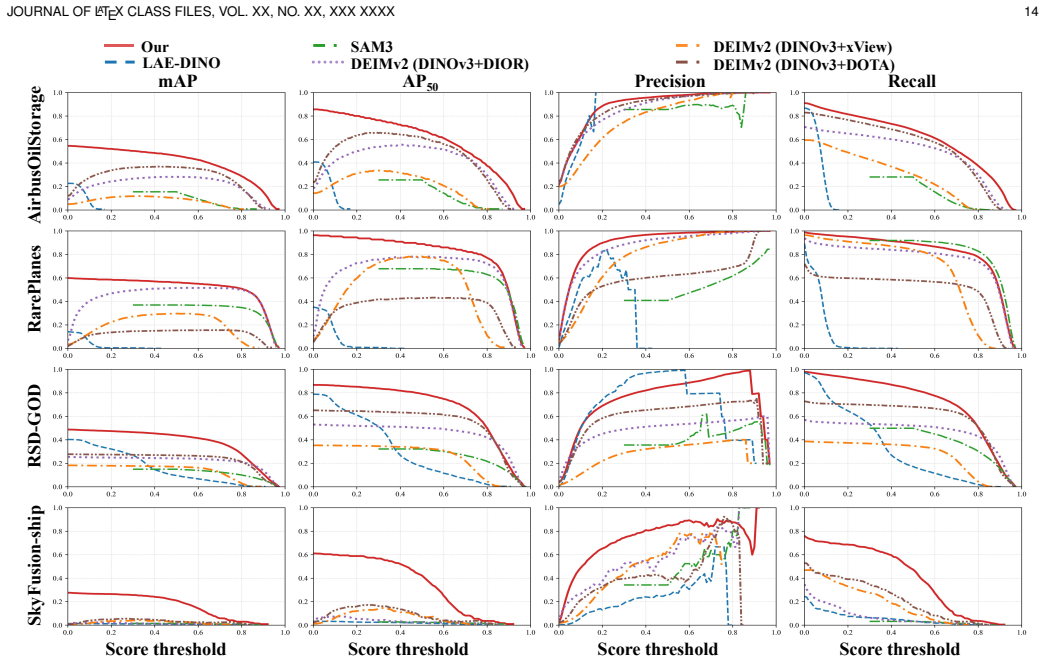
A new 159-category remote sensing dataset trains a model that detects objects zero-shot across nine external benchmarks, outperforming fully supervised methods by 5.02 mAP on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
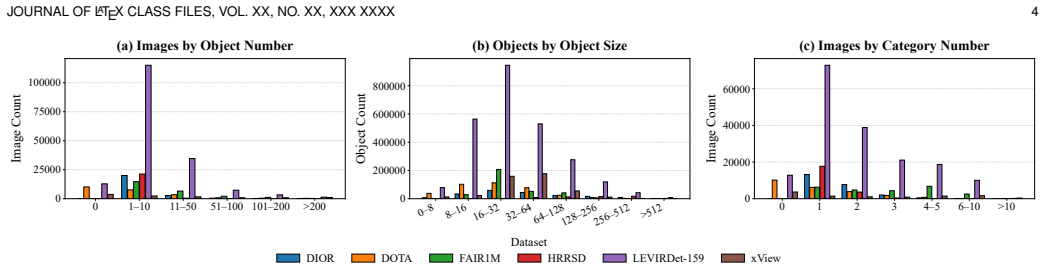
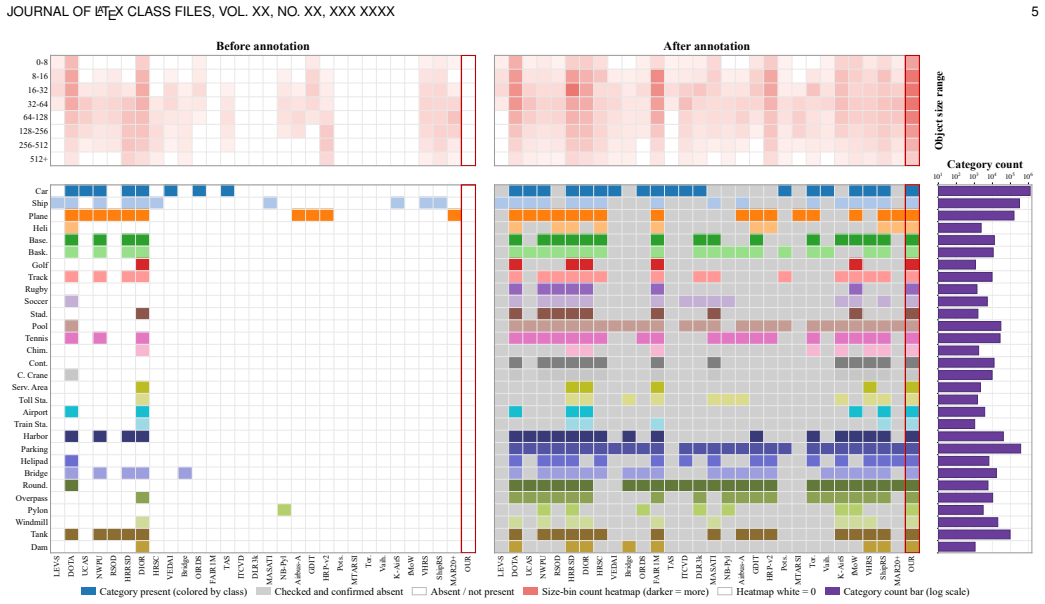
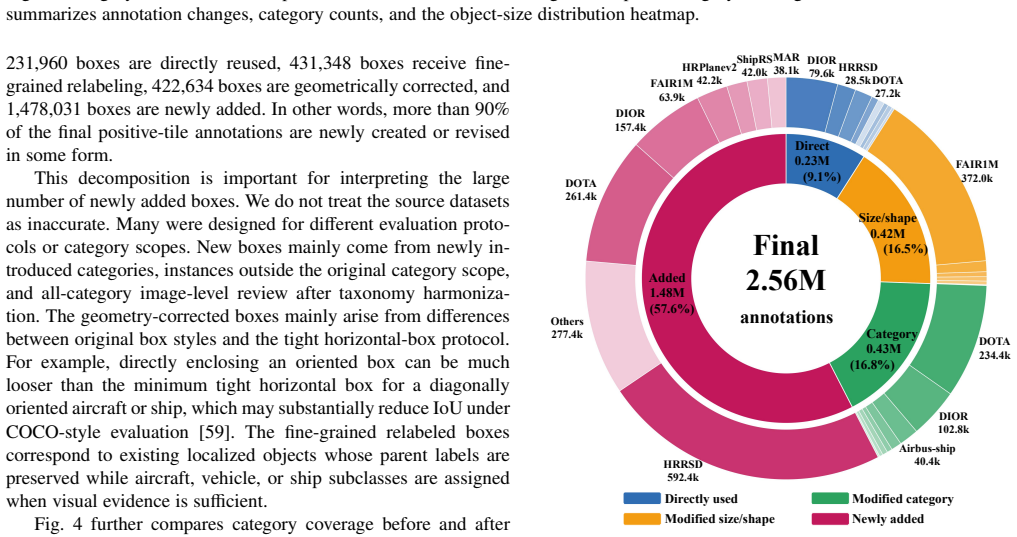
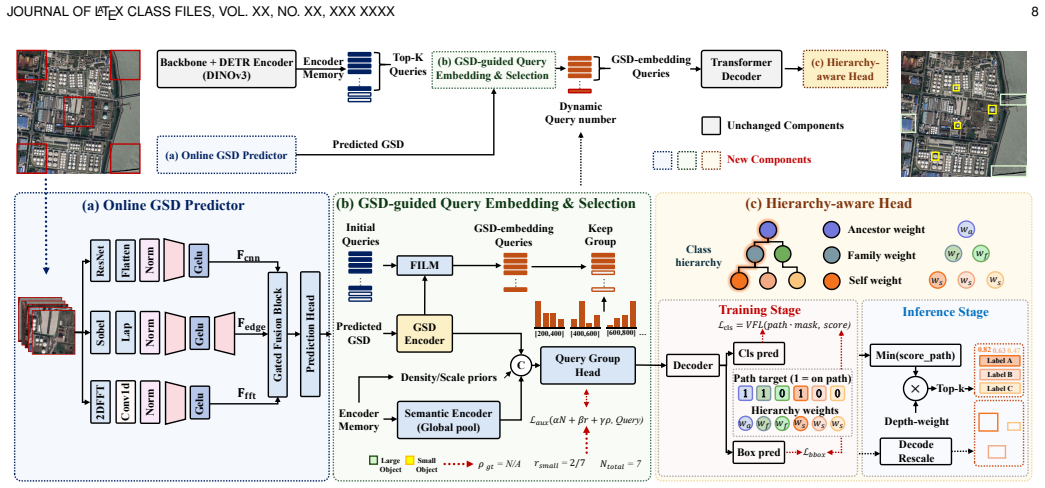
LEVIRDet-159 supplies 159 categories, 2.56 million bounding boxes, and 700k fine-grained annotations under a multi-level taxonomy, exceeding prior datasets by factors of roughly 7x in images, 6x in instances, and 4x in categories. LEVIRDetNet adds online visual GSD prediction, GSD-conditioned query modulation and allocation, and a hierarchy-aware detection head. Without any target-domain training or fine-tuning, the model reaches state-of-the-art detection performance on nine external benchmarks and improves the strongest fully supervised competitors by 5.02 mAP on average under each benchmark's primary metric.
What carries the argument
LEVIRDetNet, which couples online visual Ground Sampling Distance prediction, GSD-conditioned query modulation and allocation, and a hierarchy-aware detection head for mixed-granularity supervision.
If this is right
- A single trained detector can be deployed across multiple sensors and resolutions without per-domain retraining.
- Multi-level taxonomy supervision enables detection at both coarse and fine category granularities within one forward pass.
- Online GSD prediction removes the need for manual scale metadata at inference time.
- Cross-domain generalization reduces the cost of building new remote sensing detection systems.
Where Pith is reading between the lines
- The same GSD-conditioning pattern could be tested on non-remote-sensing imagery where object scale varies strongly with acquisition distance.
- Releasing the dataset and weights allows direct measurement of whether further scaling the number of categories produces additional zero-shot gains.
- The hierarchy-aware head suggests a route for unifying detection and fine-grained classification in one architecture.
Load-bearing premise
The nine external benchmarks used for zero-shot evaluation are sufficiently diverse in sensors, resolutions, and category systems to demonstrate universal generalization across real-world remote sensing conditions.
What would settle it
Performance of the released model measured on a tenth remote sensing benchmark whose sensor type, resolution range, or category system lies outside the training distribution and the nine evaluation sets; if the average gain falls below the reported 5.02 mAP or drops below the supervised baseline, the universal claim is falsified.
Figures




read the original abstract
Remote sensing object detection has advanced rapidly with the development of large-scale benchmarks and modern detection architectures. However, existing datasets and detectors remain fragmented. Most benchmarks focus on limited categories, fixed spatial resolutions, or a single sensor, while detectors still struggle to work across different sensors and categorical systems. In this paper, we introduce LEVIRDet-159, the largest and most comprehensive remote sensing object detection dataset to date, with 159 categories, 2.56 million bounding boxes, and 700k fine-grained annotations under a multi-level taxonomy. In each key scale dimension, LEVIRDet-159 exceeds the corresponding largest existing remote sensing object detection dataset, containing approximately (7x) more images, (6x) more object instances, and (4x) more categories. Based on this dataset, we design LEVIRDetNet, a scale-hierarchy-aware detection foundation model for universal remote sensing object detection. LEVIRDetNet couples online visual Ground Sampling Distance (GSD) prediction, GSD-conditioned query modulation and allocation, and a hierarchy-aware detection head for mixed-granularity remote sensing supervision. Under stringent evaluation settings, LEVIRDetNet demonstrates strong cross-domain generalization. Even without target-domain training or fine-tuning, it achieves state-of-the-art detection performance on 9 external benchmarks, improving the strongest fully supervised competing methods by 5.02 mAP on average under each benchmark's primary metric. We hope this study will facilitate the development of strongly generalizable remote sensing object detection across diverse category systems, spatial resolutions, and sensor platforms. The dataset and trained models will be released at https://qinzheyang.github.io/LEVIRDet/, accompanying the final paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEVIRDet-159, the largest remote sensing object detection dataset to date (159 categories, 2.56 million bounding boxes, 700k fine-grained annotations under a multi-level taxonomy), exceeding prior datasets by factors of ~7x images, ~6x instances, and ~4x categories. It also presents LEVIRDetNet, a scale-hierarchy-aware foundation model incorporating online GSD prediction, GSD-conditioned query modulation/allocation, and a hierarchy-aware detection head. The central claim is that, without any target-domain training or fine-tuning, LEVIRDetNet achieves SOTA zero-shot detection on 9 external benchmarks and improves the strongest fully supervised competing methods by 5.02 mAP on average under each benchmark's primary metric.
Significance. If the zero-shot generalization claim holds after verification of benchmark diversity and training details, the work would be significant for the field: it supplies both a large-scale, multi-taxonomy dataset and a model architecture explicitly designed for cross-sensor, cross-resolution, and cross-category remote sensing detection, potentially reducing reliance on per-domain fine-tuning. The planned public release of the dataset and models is a clear strength.
major comments (2)
- [Abstract] Abstract: The claim that LEVIRDetNet demonstrates 'strong cross-domain generalization' and 'universal remote sensing object detection' across 'diverse category systems, spatial resolutions, and sensor platforms' is load-bearing for the 5.02 mAP average improvement result. However, the manuscript supplies no quantitative breakdown (sensor distribution, GSD statistics, or category intersection sizes) of the 9 external benchmarks relative to LEVIRDet-159. Without this, it is impossible to confirm that the benchmarks collectively span meaningfully different conditions rather than predominantly similar high-resolution optical sources.
- [Methods/Evaluation (implied by absence)] The provided manuscript text contains no training protocols, data-overlap checks between LEVIRDet-159 and the 9 external benchmarks, ablation studies on the GSD-prediction or hierarchy-aware components, or error analysis. These elements are required to evaluate whether the reported zero-shot gains are robust or could be explained by data leakage or benchmark similarity.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit evidence of benchmark diversity and evaluation rigor to support the zero-shot claims. We will revise the manuscript to incorporate the requested quantitative breakdowns, protocols, and analyses, which will strengthen the presentation without altering the core results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that LEVIRDetNet demonstrates 'strong cross-domain generalization' and 'universal remote sensing object detection' across 'diverse category systems, spatial resolutions, and sensor platforms' is load-bearing for the 5.02 mAP average improvement result. However, the manuscript supplies no quantitative breakdown (sensor distribution, GSD statistics, or category intersection sizes) of the 9 external benchmarks relative to LEVIRDet-159. Without this, it is impossible to confirm that the benchmarks collectively span meaningfully different conditions rather than predominantly similar high-resolution optical sources.
Authors: We agree that the current abstract and main text lack a consolidated quantitative breakdown of benchmark diversity. In the revision we will add a dedicated table (new Table 2) reporting, for each of the 9 external benchmarks: primary sensor type(s), GSD range statistics, number of images/instances, and category intersection size with LEVIRDet-159 (both exact and hierarchical matches). This table will also include a summary row showing the aggregate coverage across optical, SAR, and multi-spectral sources to demonstrate that the benchmarks are not dominated by high-resolution optical imagery similar to the training distribution. revision: yes
-
Referee: [Methods/Evaluation (implied by absence)] The provided manuscript text contains no training protocols, data-overlap checks between LEVIRDet-159 and the 9 external benchmarks, ablation studies on the GSD-prediction or hierarchy-aware components, or error analysis. These elements are required to evaluate whether the reported zero-shot gains are robust or could be explained by data leakage or benchmark similarity.
Authors: The full manuscript contains a Methods section describing the overall training setup, but we acknowledge that explicit data-overlap verification, component ablations, and error analysis are insufficiently detailed. We will expand Section 4 (Experiments) with: (i) a data-overlap analysis confirming zero instance-level leakage via image-hash and geographic-coordinate checks; (ii) ablation tables isolating the contribution of online GSD prediction and the hierarchy-aware head; and (iii) a qualitative error analysis highlighting failure modes across sensor/GSD regimes. These additions will be placed before the main zero-shot results to allow readers to assess robustness directly. revision: yes
Circularity Check
No circularity: empirical zero-shot results on distinct external benchmarks
full rationale
The paper trains LEVIRDetNet on the newly introduced LEVIRDet-159 dataset and reports mAP improvements on nine explicitly external benchmarks under zero-shot conditions with no target-domain training or fine-tuning. This performance claim is an empirical measurement on held-out data and does not reduce by construction to any fitted parameter, self-definition, or self-citation chain within the paper. No equations, uniqueness theorems, or ansatzes are shown that would make the reported 5.02 mAP average gain tautological with the training inputs. The central derivation chain (dataset construction → model design → cross-benchmark evaluation) remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Object detection in aerial images: A large-scale benchmark and challenges,
J. Ding, N. Xue, G.-S. Xia, X. Bai, W. Yang, M. Y . Yang, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Object detection in aerial images: A large-scale benchmark and challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 11, pp. 7778– 7796, 2022
2022
-
[2]
Object detection in 20 years: A survey,
Z. Zou, K. Chen, Z. Shi, Y . Guo, and J. Ye, “Object detection in 20 years: A survey,”Proceedings of the IEEE, vol. 111, no. 3, pp. 257–276, 2023
2023
-
[3]
Dota: A large-scale dataset for object detection in aerial images,
G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Dota: A large-scale dataset for object detection in aerial images,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3974–3983
2018
-
[4]
Object detection in optical remote sensing images: A survey and a new benchmark,
K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,”ISPRS journal of photogrammetry and remote sensing, vol. 159, pp. 296–307, 2020
2020
-
[5]
Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery,
X. Sun, P. Wang, Z. Yan, F. Xu, R. Wang, W. Diao, J. Chen, J. Li, Y . Feng, T. Xuet al., “Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 184, pp. 116–130, 2022
2022
-
[6]
Towards large-scale small object detection: Survey and benchmarks,
G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, X. Xie, and J. Han, “Towards large-scale small object detection: Survey and benchmarks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 13 467–13 488, 2023
2023
-
[7]
A degraded recon- struction enhancement-based method for tiny ship detection in remote sensing images with a new large-scale dataset,
J. Chen, K. Chen, H. Chen, Z. Zou, and Z. Shi, “A degraded recon- struction enhancement-based method for tiny ship detection in remote sensing images with a new large-scale dataset,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022
2022
-
[8]
Orientation robust object detection in aerial images using deep convolutional neural network,
H. Zhu, X. Chen, W. Dai, K. Fu, Q. Ye, and J. Jiao, “Orientation robust object detection in aerial images using deep convolutional neural network,” in2015 IEEE International Conference on Image Processing (ICIP), 2015, pp. 3735–3739
2015
-
[9]
Multi-class geospatial object detection and geographic image classification based on collection of part detectors,
G. Cheng, J. Han, P. Zhou, and L. Guo, “Multi-class geospatial object detection and geographic image classification based on collection of part detectors,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 98, pp. 119–132, 2014
2014
-
[10]
Accurate object localization in remote sensing images based on convolutional neural networks,
Y . Long, Y . Gong, Z. Xiao, and Q. Liu, “Accurate object localization in remote sensing images based on convolutional neural networks,”IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 5, pp. 2486–2498, 2017
2017
-
[11]
Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection,
Y . Zhang, Y . Yuan, Y . Feng, and X. Lu, “Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection,”IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 8, pp. 5535–5548, 2019
2019
-
[12]
Learning spatial context: Using stuffto find things,
G. Heitz and D. Koller, “Learning spatial context: Using stuffto find things,” inEuropean conference on computer vision. Springer, 2008, pp. 30–43
2008
-
[13]
A high resolution optical satellite image dataset for ship recognition and some new baselines,
Z. Liu, L. Yuan, L. Weng, and Y . Yang, “A high resolution optical satellite image dataset for ship recognition and some new baselines,” inInternational conference on pattern recognition applications and methods, vol. 2. SciTePress, 2017, pp. 324–331
2017
-
[14]
Vehicle detection in aerial imagery: A small target detection benchmark,
S. Razakarivony and F. Jurie, “Vehicle detection in aerial imagery: A small target detection benchmark,”Journal of Visual Communication and Image Representation, vol. 34, pp. 187–203, 2016
2016
-
[15]
Vehicle detection in aerial images,
M. Y . Yang, W. Liao, X. Li, Y . Cao, and B. Rosenhahn, “Vehicle detection in aerial images,”Photogrammetric Engineering&Remote Sensing, vol. 85, no. 4, pp. 297–304, 2019
2019
-
[16]
Fast multiclass vehicle detection on aerial images,
K. Liu and G. Mattyus, “Fast multiclass vehicle detection on aerial images,”IEEE Geoscience and Remote Sensing Letters, vol. 12, no. 9, pp. 1938–1942, 2015
1938
-
[17]
A tool for bridge detection in major infrastructure works using satellite images,
K. Nogueira, C. Cesar, P. H. Gama, G. L. Machado, and J. A. dos Santos, “A tool for bridge detection in major infrastructure works using satellite images,” in2019 XV Workshop de Vis˜ ao Computacional (WVC). IEEE, 2019, pp. 72–77
2019
-
[18]
Overhead imagery research data set—an annotated data library & tools to aid in the development of computer vision algorithms,
F. Tanner, B. Colder, C. Pullen, D. Heagy, M. Eppolito, V . Carlan, C. Oertel, and P. Sallee, “Overhead imagery research data set—an annotated data library & tools to aid in the development of computer vision algorithms,” in2009 IEEE Applied Imagery Pattern Recognition Workshop (AIPR 2009). IEEE, 2009, pp. 1–8
2009
-
[19]
Mar20: A benchmark for military aircraft recognition in remote sensing images,
Y . Wenqi, C. Gong, W. Meijun, Y . Yanqing, X. Xingxing, Y . Xiwen, and H. Junwei, “Mar20: A benchmark for military aircraft recognition in remote sensing images,”National Remote Sensing Bulletin, vol. 27, no. 12, pp. 2688–2696, 2024
2024
-
[20]
Vhrships: An extensive bench- mark dataset for scalable deep learning-based ship detection applica- tions,
S. Kızılkaya, U. Alganci, and E. Sertel, “Vhrships: An extensive bench- mark dataset for scalable deep learning-based ship detection applica- tions,”ISPRS International Journal of Geo-Information, vol. 11, no. 8, p. 445, 2022
2022
-
[21]
Shiprsimagenet: A large-scale fine-grained dataset for ship detection in high-resolution optical remote sensing images,
Z. Zhang, L. Zhang, Y . Wang, P. Feng, and R. He, “Shiprsimagenet: A large-scale fine-grained dataset for ship detection in high-resolution optical remote sensing images,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 8458– 8472, 2021
2021
-
[22]
A new spatial-oriented object detection framework for remote sensing images,
D. Yu and S. Ji, “A new spatial-oriented object detection framework for remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2021
2021
-
[23]
A benchmark dataset for deep learning-based airplane detection: Hrplanes,
T. Bakırman and E. Sertel, “A benchmark dataset for deep learning-based airplane detection: Hrplanes,”International Journal of Engineering and Geosciences, vol. 8, no. 3, pp. 212–223, 2023
2023
-
[24]
Drone-based object counting by spatially regularized regional proposal network,
M.-R. Hsieh, Y .-L. Lin, and W. H. Hsu, “Drone-based object counting by spatially regularized regional proposal network,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 4145–4153
2017
-
[25]
Vhrv: Very high- resolution benchmark dataset for vessel detection,
F. B ¨uy¨ukkanber, M. Yanalak, and N. Musao ˘glu, “Vhrv: Very high- resolution benchmark dataset for vessel detection,”Remote Sensing Applications: Society and Environment, vol. 39, p. 101641, 2025
2025
-
[26]
Performance evolution of yolo models in remote sensing images,
I. Hassan and Z. Xinyou, “Performance evolution of yolo models in remote sensing images,” in2024 21st International Computer Confer- ence on Wavelet Active Media Technology and Information Processing (ICCWAMTIP). IEEE, 2024, pp. 1–4
2024
-
[27]
Com- plex optical remote-sensing aircraft detection dataset and benchmark,
T. Shi, J. Gong, S. Jiang, X. Zhi, G. Bao, Y . Sun, and W. Zhang, “Com- plex optical remote-sensing aircraft detection dataset and benchmark,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–9, 2023
2023
-
[28]
A benchmark dataset for aircraft detection in optical remote sensing imagery,
J. Hu, X. Zhi, B. Zhang, T. Shi, Q. Cui, and X. Sun, “A benchmark dataset for aircraft detection in optical remote sensing imagery,”Remote Sensing, vol. 16, no. 24, p. 4699, 2024
2024
-
[29]
Efficient remote sensing instance segmentation with linear-time state space distilled visual foun- dation models,
Q. Yang, K. Chen, J. Xu, Z. Shi, and Z. Zou, “Efficient remote sensing instance segmentation with linear-time state space distilled visual foun- dation models,”IEEE Transactions on Geoscience and Remote Sensing, pp. 1–1, 2026
2026
-
[30]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137–1149, 2016
2016
-
[31]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6154–6162
2018
-
[32]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779– 788
2016
-
[33]
Ssd: Single shot multibox detector,
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” inEuropean conference on computer vision. Springer, 2016, pp. 21–37. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. XX, XXX XXXX 17
2016
-
[34]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988
2017
-
[35]
Fcos: Fully convolutional one- stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one- stage object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9627–9636
2019
-
[36]
X. Zhou, D. Wang, and P. Kr¨ahenb¨uhl, “Objects as points,”arXiv preprint arXiv:1904.07850, 2019
Pith/arXiv arXiv 1904
-
[37]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inEu- ropean conference on computer vision. Springer, 2020, pp. 213–229
2020
-
[38]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020
Pith/arXiv arXiv 2010
-
[39]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,”arXiv preprint arXiv:2203.03605, 2022
Pith/arXiv arXiv 2022
-
[40]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 965–16 974
2024
-
[41]
Deim: Detr with improved matching for fast convergence,
S. Huang, Z. Lu, X. Cun, Y . Yu, X. Zhou, and X. Shen, “Deim: Detr with improved matching for fast convergence,” inProceedings of the computer vision and pattern recognition conference, 2025, pp. 15 162–15 171
2025
-
[42]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean conference on computer vision. Springer, 2024, pp. 38–55
2024
-
[43]
Locate anything on earth: Advancing open-vocabulary object detection for remote sensing community,
J. Pan, Y . Liu, Y . Fu, M. Ma, J. Li, D. P. Paudel, L. Van Gool, and X. Huang, “Locate anything on earth: Advancing open-vocabulary object detection for remote sensing community,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 6, 2025, pp. 6281– 6289
2025
-
[44]
Simple open-vocabulary object detection,
M. Minderer, A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Mahendran, A. Arnab, M. Dehghani, Z. Shenet al., “Simple open-vocabulary object detection,” inEuropean conference on computer vision. Springer, 2022, pp. 728–755
2022
-
[45]
Learning to holistically detect bridges from large-size vhr remote sensing imagery,
Y . Li, J. Luo, Y . Zhang, Y . Tan, J.-G. Yu, and S. Bai, “Learning to holistically detect bridges from large-size vhr remote sensing imagery,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 11 507–11 523, 2024
2024
-
[46]
Rareplanes: Synthetic data takes flight,
J. Shermeyer, T. Hossler, A. Van Etten, D. Hogan, R. Lewis, and D. Kim, “Rareplanes: Synthetic data takes flight,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 207–217
2021
-
[47]
A benchmark data set for aircraft type recognition from remote sensing images,
Z. Wu, S. Wan, X. Wang, M. Tan, L. Zou, X. Li, and Y . Chen, “A benchmark data set for aircraft type recognition from remote sensing images,”Applied Soft Computing, vol. 89, p. 106132, 2020
2020
-
[48]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in2017 IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 936–944
2017
-
[49]
Detecting tiny objects in aerial images: A normalized wasserstein distance and a new benchmark,
C. Xu, J. Wang, , W. Yang, H. Yu, L. Yu, and G.-S. Xia, “Detecting tiny objects in aerial images: A normalized wasserstein distance and a new benchmark,”ISPRS Journal of Photogrammetry and Remote Sensing, 2022
2022
-
[50]
Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing,
X. Yang, J. Yan, W. Liao, X. Yang, J. Tang, and T. He, “Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 2384–2399, 2023
2023
-
[51]
Target detection in hyperspectral remote sensing image: Current status and challenges,
B. Chen, L. Liu, Z. Zou, and Z. Shi, “Target detection in hyperspectral remote sensing image: Current status and challenges,”Remote Sensing, vol. 15, no. 13, p. 3223, 2023
2023
-
[52]
State space models meet remote sensing: A survey,
Q. Yang, C. Liu, J. Xu, Z. Shi, and Z. Zou, “State space models meet remote sensing: A survey,”SCIENCE CHINA Information Sciences, 2026
2026
-
[53]
xview: Objects in context in overhead imagery,
D. Lam, R. Kuzma, K. McGee, S. Dooley, M. Laielli, M. Klaric, Y . Bulatov, and B. McCord, “xview: Objects in context in overhead imagery,”arXiv preprint arXiv:1802.07856, 2018
Pith/arXiv arXiv 2018
-
[54]
Use of the stair vision library within the isprs 2d semantic labeling benchmark (vaihingen),
I. Markus Gerke, “Use of the stair vision library within the isprs 2d semantic labeling benchmark (vaihingen),”Use of the stair vision library within the isprs 2d semantic labeling benchmark (vaihingen), 2014
2014
-
[55]
Functional map of the world,
G. Christie, N. Fendley, J. Wilson, and R. Mukherjee, “Functional map of the world,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6172–6180
2018
-
[56]
Automatic ship classification from optical aerial images with convolutional neural networks,
A.-J. Gallego, A. Pertusa, and P. Gil, “Automatic ship classification from optical aerial images with convolutional neural networks,”Remote Sensing, vol. 10, no. 4, p. 511, 2018
2018
-
[57]
Airbus ship detection challenge,
Airbus, “Airbus ship detection challenge,”Kaggle, 2018
2018
-
[58]
Airbus aircraft detection challenge,
——, “Airbus aircraft detection challenge,”Kaggle, 2021
2021
-
[59]
Gliding vertex on the horizontal bounding box for multi-oriented object detection,
Y . Xu, M. Fu, Q. Wang, Y . Wang, K. Chen, G.-S. Xia, and X. Bai, “Gliding vertex on the horizontal bounding box for multi-oriented object detection,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 43, no. 4, pp. 1452–1459, 2021
2021
-
[60]
Multi-oriented object detection in aerial images with double horizontal rectangles,
G. Nie and H. Huang, “Multi-oriented object detection in aerial images with double horizontal rectangles,”IEEE Transactions on Pattern Analy- sis and Machine Intelligence, vol. 45, no. 4, pp. 4932–4944, 2023
2023
-
[61]
Mmdetection: Open mmlab detection toolbox and benchmark,
K. Chen, J. Wang, J. Pang, Y . Cao, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Xuet al., “Mmdetection: Open mmlab detection toolbox and benchmark,”arXiv preprint arXiv:1906.07155, 2019
Pith/arXiv arXiv 1906
-
[62]
MMEngine: Openmmlab foundational library for train- ing deep learning models,
M. Contributors, “MMEngine: Openmmlab foundational library for train- ing deep learning models,” 2022
2022
-
[63]
A large contextual dataset for classification, detection and counting of cars with deep learning,
T. N. Mundhenk, G. Konjevod, W. A. Sakla, and K. Boakye, “A large contextual dataset for classification, detection and counting of cars with deep learning,” inEuropean conference on computer vision. Springer, 2016, pp. 785–800
2016
-
[64]
Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,
E. Maggiori, Y . Tarabalka, G. Charpiat, and P. Alliez, “Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,” in2017 IEEE International geoscience and remote sensing symposium (IGARSS). IEEE, 2017, pp. 3226–3229
2017
-
[65]
Bigearthnet: A large-scale benchmark archive for remote sensing image understanding,
G. Sumbul, M. Charfuelan, B. Demir, and V . Markl, “Bigearthnet: A large-scale benchmark archive for remote sensing image understanding,” arXiv preprint arXiv:1902.06148, 2019
arXiv 1902
-
[66]
Deep high-resolution representation learning for visual recognition,
J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y . Zhao, D. Liu, Y . Mu, M. Tan, X. Wanget al., “Deep high-resolution representation learning for visual recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 10, pp. 3349–3364, 2020
2020
-
[67]
Fast r-cnn,
R. Girshick, “Fast r-cnn,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448
2015
-
[68]
You only look one-level feature,
Q. Chen, Y . Wang, T. Yang, X. Zhang, J. Cheng, and J. Sun, “You only look one-level feature,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13 039–13 048
2021
-
[69]
Sparse r-cnn: An end-to-end framework for object detection,
P. Sun, R. Zhang, Y . Jiang, T. Kong, C. Xu, W. Zhan, M. Tomizuka, Z. Yuan, and P. Luo, “Sparse r-cnn: An end-to-end framework for object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 15 650–15 664, 2023
2023
-
[70]
Rtmdet: An empirical study of designing real-time object detectors,
C. Lyu, W. Zhang, H. Huang, Y . Zhou, Y . Wang, Y . Liu, S. Zhang, and K. Chen, “Rtmdet: An empirical study of designing real-time object detectors,”arXiv preprint arXiv:2212.07784, 2022
arXiv 2022
-
[71]
Efficientdet: Scalable and efficient object detection,
M. Tan, R. Pang, and Q. V . Le, “Efficientdet: Scalable and efficient object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 781–10 790
2020
-
[72]
Scale-aware trident networks for object detection,
Y . Li, Y . Chen, N. Wang, and Z. Zhang, “Scale-aware trident networks for object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6054–6063
2019
-
[73]
Yolox: Exceeding yolo series in 2021,
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021
Pith/arXiv arXiv 2021
-
[74]
Yolov12: Attention-centric real-time object detectors,
Y . Tian, Q. Ye, and D. Doermann, “Yolov12: Attention-centric real-time object detectors,”Advances in neural information processing systems, vol. 38, pp. 78 433–78 457, 2026
2026
-
[75]
You only look once based-c2fghost using efficient siou loss function for airplane detection,
M.-T. Do, M.-H. Ha, D.-C. Nguyen, and O. T.-C. Chen, “You only look once based-c2fghost using efficient siou loss function for airplane detection,” in2024 9th International Conference on Frontiers of Signal Processing (ICFSP). IEEE, 2024, pp. 1–5
2024
-
[76]
Real-time object detection meets dinov3,
S. Huang, Y . Hou, L. Liu, X. Yu, and X. Shen, “Real-time object detection meets dinov3,”arXiv preprint arXiv:2509.20787, 2025
arXiv 2025
-
[77]
Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,
K. Chen, C. Liu, B. Chen, W. Li, Z. Zou, and Z. Shi, “Dynamicvis: An efficient and general visual foundation model for remote sensing image understanding,”arXiv preprint arXiv:2503.16426, 2025
arXiv 2025
-
[78]
What is yolov5: A deep look into the internal features of the popular object detector,
R. Khanam and M. Hussain, “What is yolov5: A deep look into the internal features of the popular object detector,”arXiv preprint arXiv:2407.20892, 2024
arXiv 2024
-
[79]
Small object detection in unmanned aerial vehicle images using multi-scale hybrid attention,
G. Song, H. Du, X. Zhang, F. Bao, and Y . Zhang, “Small object detection in unmanned aerial vehicle images using multi-scale hybrid attention,” Engineering Applications of Artificial Intelligence, vol. 128, p. 107455, 2024
2024
-
[80]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.