BenchX: Benchmarking AI Models for Cancer Detection and Localization with Demographic and Protocol Biases
Pith reviewed 2026-06-26 00:06 UTC · model grok-4.3
The pith
AI models for cancer detection in CT scans show large performance drops on underrepresented patient subgroups like young female African Americans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
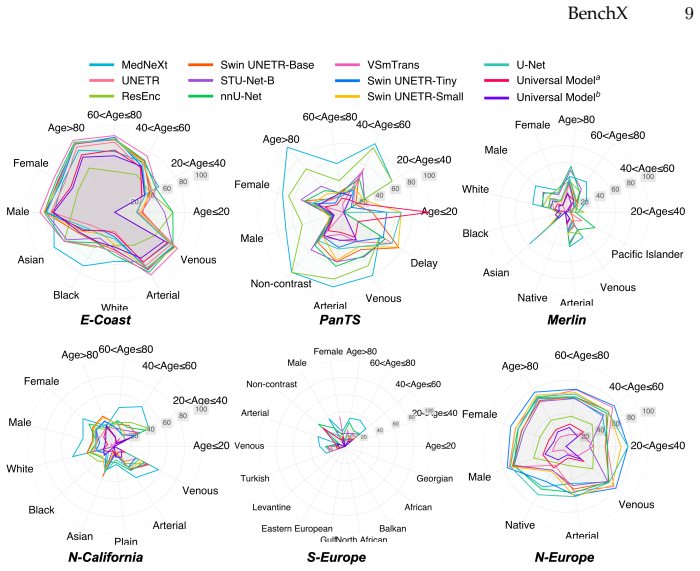
The paper claims that current state-of-the-art AI models for tumor detection and localization, when optimized for average accuracy, exhibit poor performance in rare or underrepresented subgroups such as young, female African Americans, as measured across a large benchmark of CT scans with LLM-derived demographic and protocol labels.
What carries the argument
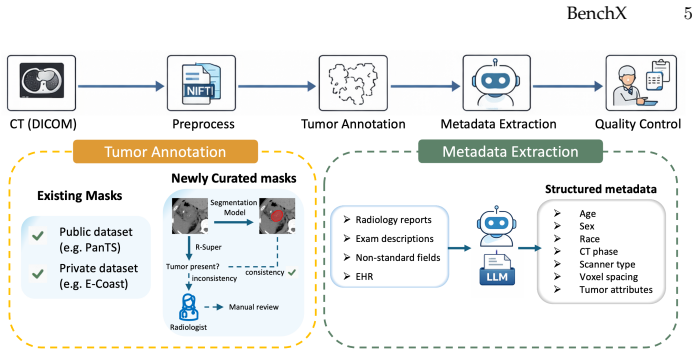
The BenchX benchmark dataset and evaluation protocol that uses LLM-extracted labels to measure model performance across demographic subgroups, tumor characteristics, and imaging protocols.
If this is right
- AI models for medical imaging must be evaluated at the subgroup level rather than by average accuracy alone.
- Collecting enough labeled data for every rare subgroup is often not feasible, so other methods are needed to improve consistency.
- Reliable clinical use of these models requires testing across variations in patient age, sex, race, and scan protocols.
Where Pith is reading between the lines
- The same LLM-labeling approach could be applied to other imaging modalities or diseases to check for similar subgroup gaps.
- Targeted data synthesis or model adaptation techniques might reduce the observed drops without needing massive new annotations.
- Hospitals could use subgroup monitoring to decide when to override or retrain an AI model for specific patient populations.
Load-bearing premise
The large language model extraction of demographic and protocol subgroup labels from clinical reports is accurate and unbiased enough to support the reported performance differences.
What would settle it
Manual re-annotation of a random sample of the clinical reports showing that the LLM labels contain systematic errors large enough to erase or reverse the reported accuracy gaps between subgroups.
Figures



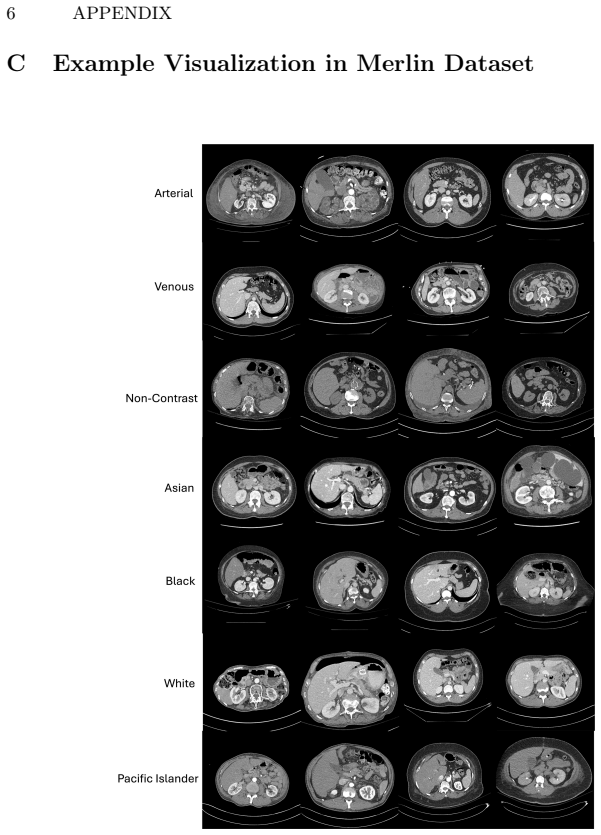
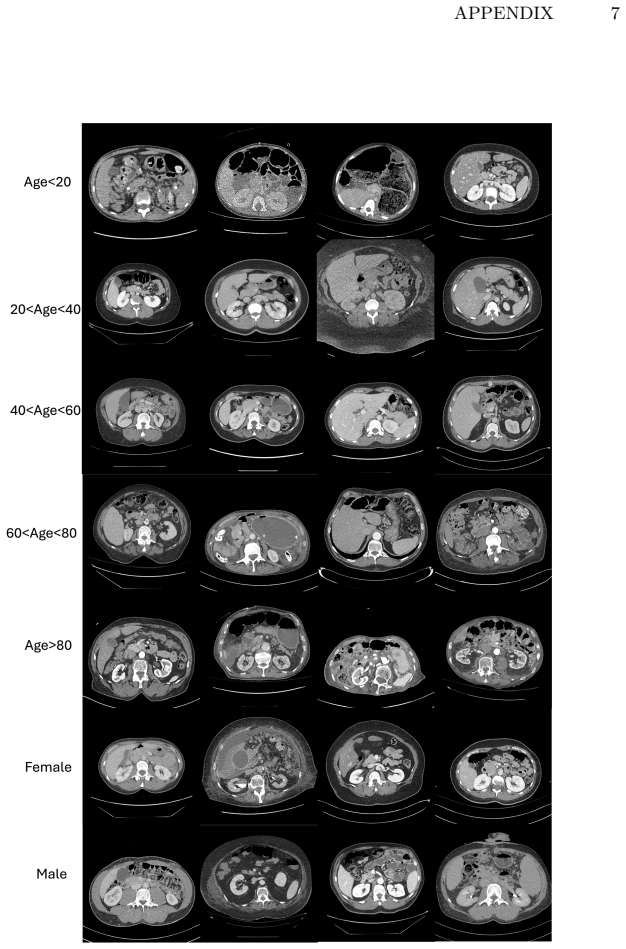
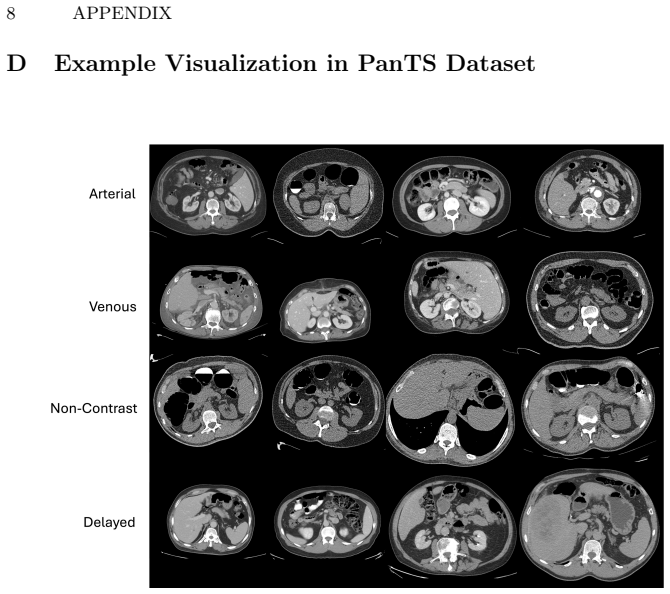
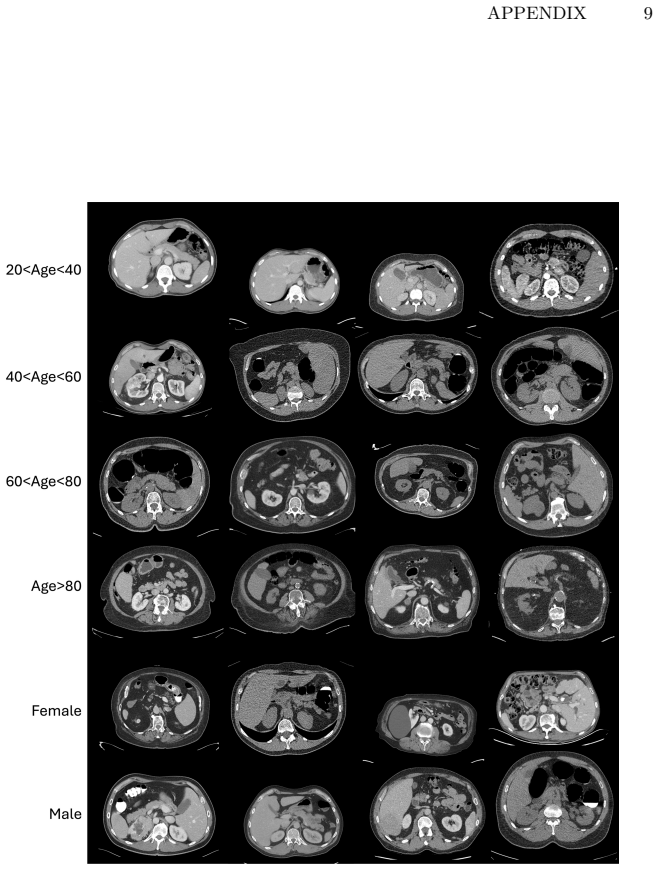





read the original abstract
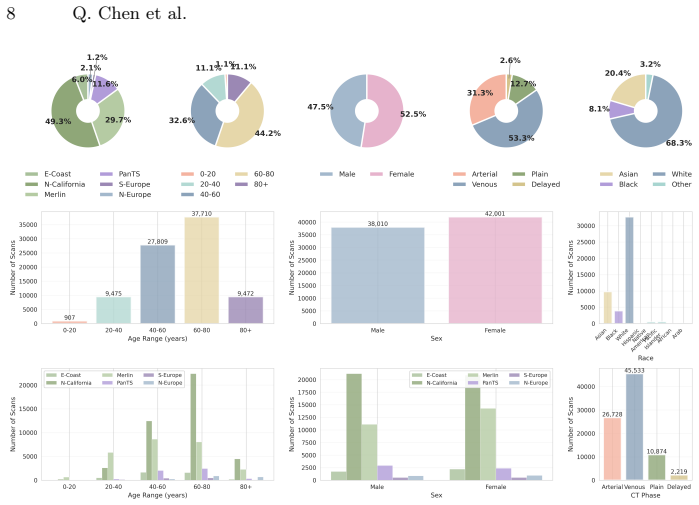
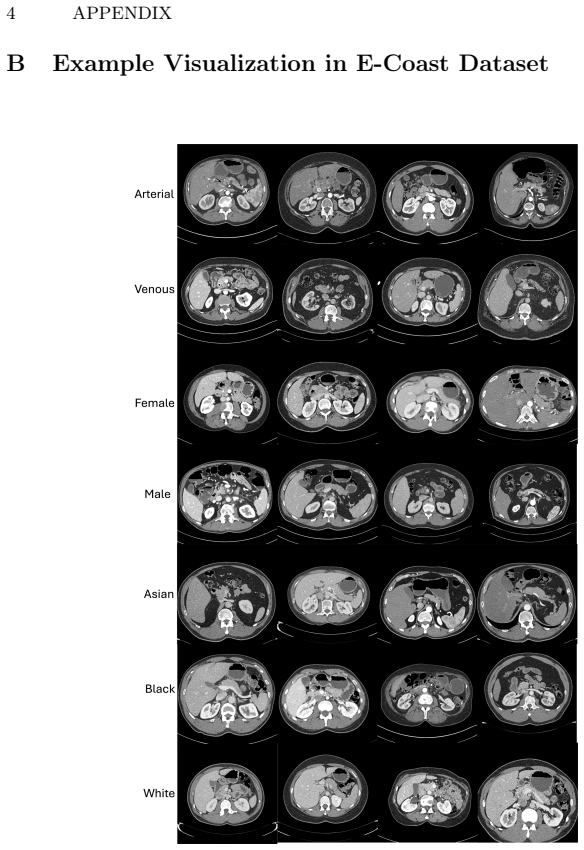
Artificial intelligence (AI) has achieved remarkable success in medical imaging, but it is widely recognized that these models often perform inconsistently across real-world clinical settings. Such inconsistencies occur when patient demographics and imaging protocols vary, for example, in detecting small tumors, analyzing scans from different contrast phases, or evaluating patients of different ages or sexes. To quantify these inconsistencies, we develop a large-scale, open benchmark of 85,355 CT scans that systematically evaluates 12 tumor-detection AI models across tumor size, location, patient subgroup, and imaging protocol. We leverage large language models (LLMs) to extract and organize subgroup information from clinical data, which makes the analysis both scalable and reproducible. Our benchmark reveals that current state-of-the-art AI models, optimized for average accuracy, perform poorly in rare or underrepresented subgroups, such as young, female African Americans. However, collecting sufficient annotated data for these rare cases is often impractical. The benchmark provides a foundation for building more reliable and robust AI models for tumor detection and highlighting the need for rigorous, subgroup-level evaluation in medical imaging and computer vision. Datasets, code
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BenchX, a benchmark of 85,355 CT scans that evaluates 12 tumor-detection AI models across tumor size, location, patient demographic subgroups, and imaging protocols. Subgroup labels are obtained by applying LLMs to clinical reports; the central empirical finding is that average-optimized SOTA models exhibit poor performance on rare or underrepresented subgroups such as young female African Americans, motivating the need for subgroup-level evaluation in medical imaging.
Significance. If the extracted labels prove reliable, the work supplies a large-scale, open benchmark that directly quantifies demographic and protocol biases in tumor-detection models, a practically important gap in the field. The scale (85k scans) and the attempt to make subgroup analysis scalable via LLMs are genuine strengths that could support follow-on research on robust model development.
major comments (1)
- [Methods (LLM label extraction)] Methods section on LLM-based label extraction: no human validation, inter-annotator agreement, or error analysis is reported for the demographic and protocol labels extracted from the 85,355 clinical reports. Because the headline performance gaps (e.g., on young female African-American patients) rest entirely on the correctness of these per-scan labels, the absence of any accuracy quantification on a held-out sample makes the reported disparities impossible to interpret; systematic mislabeling correlated with image features or demographics would artifactually create or inflate the observed differences.
minor comments (1)
- [Abstract] Abstract ends with the fragment 'Datasets, code' without supplying repository URLs or DOIs.
Simulated Author's Rebuttal
We thank the referee for highlighting the critical need for validation of the LLM-extracted labels. This is a substantive methodological point that directly affects interpretability of the subgroup results. We address it below and will incorporate the requested analysis in revision.
read point-by-point responses
-
Referee: Methods section on LLM-based label extraction: no human validation, inter-annotator agreement, or error analysis is reported for the demographic and protocol labels extracted from the 85,355 clinical reports. Because the headline performance gaps (e.g., on young female African-American patients) rest entirely on the correctness of these per-scan labels, the absence of any accuracy quantification on a held-out sample makes the reported disparities impossible to interpret; systematic mislabeling correlated with image features or demographics would artifactually create or inflate the observed differences.
Authors: We agree that the absence of validation makes the reported disparities difficult to interpret with full confidence and that systematic label errors could artifactually influence results. In the revised manuscript we will add a dedicated validation subsection: a random sample of 500 reports will be independently annotated by two human experts (blinded to model outputs and to each other) for all demographic and protocol fields. We will report per-field accuracy, precision, recall, F1, and inter-annotator agreement (Cohen’s kappa). We will also conduct an error analysis stratified by demographic group and protocol to test for systematic mislabeling. If validation accuracy falls below a pre-specified threshold we will discuss the implications for the main findings and, where feasible, provide sensitivity analyses. This addition directly addresses the concern while preserving the scalability argument for LLM extraction. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential steps
full rationale
The paper is a large-scale empirical benchmark evaluating 12 existing tumor-detection models on 85k CT scans, using LLM extraction for subgroup labels. No equations, fitted parameters, or derivations are present that could reduce to inputs by construction. Claims rest on external models, data, and the (unvalidated) LLM labeling step, but this is a data-quality assumption rather than circularity per the enumerated patterns. No self-citation load-bearing or ansatz smuggling occurs in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM extraction of demographic and protocol labels from clinical text is accurate enough for subgroup analysis
Reference graph
Works this paper leans on
-
[1]
zenodo (2024) 8
Alves, N., Schuurmans, M., Rutkowski, D., et al.: The panorama study protocol: Pancreatic cancer diagnosis-radiologists meet ai. zenodo (2024) 8
2024
-
[2]
The Lancet Oncology27(1), 116–124 (2026) 4
Alves, N., Schuurmans, M., Rutkowski, D., Saha, A., Vendittelli, P., Obuchowski, N., Liedenbaum, M.H., Haldorsen, I.S., Molven, A., Yakar, D., et al.: Artificial intelligence and radiologists in pancreatic cancer detection using standard of care ct scans (panorama): an international, paired, non-inferiority, confirmatory, obser- vational study. The Lancet...
2026
-
[3]
Nature communications13(1), 1–13 (2022) 3, 4
Antonelli, M., Reinke, A., Bakas, S., Farahani, K., Kopp-Schneider, A., Landman, B.A., Litjens, G., Menze, B., Ronneberger, O., Summers, R.M., et al.: The medical segmentation decathlon. Nature communications13(1), 1–13 (2022) 3, 4
2022
-
[4]
arXiv preprint arXiv:2106.05735 (2021) 2, 4
Antonelli, M., Reinke, A., Bakas, S., Farahani, K., Landman, B.A., Litjens, G., Menze, B., Ronneberger, O., Summers, R.M., van Ginneken, B., et al.: The medical segmentation decathlon. arXiv preprint arXiv:2106.05735 (2021) 2, 4
-
[5]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Bassi, P.R., Li, W., Chen, J., Zhu, Z., Lin, T., Decherchi, S., Cavalli, A., Wang, K., Yang, Y., Yuille, A.L., Zhou, Z.: Learning segmentation from radiology reports. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 305–315. Springer (2025),https://github.com/MrGiovanni/R- Super5
2025
-
[7]
Bassi, P.R., Li, W., Tang, Y., Isensee, F., Wang, Z., Chen, J., Chou, Y.C., Kirch- hoff, Y., Rokuss, M., Huang, Z., Ye, J., He, J., Wald, T., Ulrich, C., Baumgartner, M., Roy, S., Maier-Hein, K.H., Jaeger, P., Ye, Y., Xie, Y., Zhang, J., Chen, Z., Xia, Y., Xing, Z., Zhu, L., Sadegheih, Y., Bozorgpour, A., Kumari, P., Azad, R., Merhof, D., Shi, P., Ma, T.,...
2024
-
[8]
arXiv preprint arXiv:2510.14803 (2025),https://github
Bassi, P.R., Zhou, X., Li, W., Płotka, S., Chen, J., Chen, Q., Zhu, Z., Prządo, J., Hamamci, I.E., Er, S., Chen, X., Yavuz, M.C., Chou, Y.C., Lin, T., Wang, K., Tang, Y., Cwikla, J.B., Decherchi, S., Cavalli, A., Yang, Y., Yuille, A.L., Zhou, Z.: Scaling artificial intelligence for multi-tumor early detection with more re- ports, fewer masks. arXiv prepri...
-
[9]
arXiv preprint arXiv:1901.04056 (2019) 4
Bilic, P., Christ, P.F., Vorontsov, E., Chlebus, G., Chen, H., Dou, Q., Fu, C.W., Han, X., Heng, P.A., Hesser, J., et al.: The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056 (2019) 4
-
[10]
Research Square pp
Blankemeier, L., Cohen, J.P., Kumar, A., Van Veen, D., Gardezi, S.J.S., Paschali, M., Chen, Z., Delbrouck, J.B., Reis, E., Truyts, C., et al.: Merlin: A vision language foundation model for 3d computed tomography. Research Square pp. rs–3 (2024) 3, 7
2024
-
[11]
In: Conference on fairness, accountability and transparency
Buolamwini, J., Gebru, T.: Gender shades: Intersectional accuracy disparities in commercial gender classification. In: Conference on fairness, accountability and transparency. pp. 77–91. PMLR (2018) 2 BenchX17
2018
-
[12]
Nature medicine29(12), 3033–3043 (2023) 2, 8
Cao,K.,Xia,Y.,Yao,J.,Han,X.,Lambert,L.,Zhang,T.,Tang,W.,Jin,G.,Jiang, H., Fang, X., et al.: Large-scale pancreatic cancer detection via non-contrast ct and deep learning. Nature medicine29(12), 3033–3043 (2023) 2, 8
2023
-
[13]
MONAI: An open-source framework for deep learning in healthcare
Cardoso, M.J., Li, W., Brown, R., Ma, N., Kerfoot, E., Wang, Y., Murrey, B., Myronenko, A., Zhao, C., Yang, D., et al.: Monai: An open-source framework for deep learning in healthcare. arXiv preprint arXiv:2211.02701 (2022) 19
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, J., Xia, Y., Yao, J., Yan, K., Zhang, J., Lu, L., Wang, F., Zhou, B., Qiu, M., Yu, Q., et al.: Cancerunit: Towards a single unified model for effective detection, segmentation, and diagnosis of eight major cancers using a large collection of ct scans. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21327–21338 (2023) 2
2023
-
[15]
In: IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Chen, Q., Chen, X., Song, H., Xiong, Z., Yuille, A., Wei, C., Zhou, Z.: To- wards generalizable tumor synthesis. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR). pp. 11147–11158 (2024),https://github.com/ MrGiovanni/DiffTumor14
2024
-
[16]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Chen, Q., Zhou, X., Liu, C., Chen, H., Li, W., Jiang, Z., Huang, Z., Zhao, Y., Yu, D., He, J., Zheng, Y., Shao, L., Yuille, A., Zhou, Z.: Scaling tumor segmen- tation: Best lessons from real and synthetic data. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 24001–24013 (2025), https://github.com/BodyMaps/AbdomenAtlas2....
2025
-
[17]
Cancer120, 1091–1096 (2014) 2
Chen Jr, M.S., Lara, P.N., Dang, J.H., Paterniti, D.A., Kelly, K.: Twenty years post-nih revitalization act: enhancing minority participation in clinical trials (em- pact): laying the groundwork for improving minority clinical trial accrual: renewing the case for enhancing minority participation in cancer clinical trials. Cancer120, 1091–1096 (2014) 2
2014
-
[18]
Radiology: Artificial Intelligence5(6), e230060 (2023) 3
Glocker, B., Jones, C., Roschewitz, M., Winzeck, S.: Risk of bias in chest radio- graphy deep learning foundation models. Radiology: Artificial Intelligence5(6), e230060 (2023) 3
2023
-
[19]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Gutbrod, M., Rauber, D., Nunes, D.W., Palm, C.: Openmibood: Open medical imaging benchmarks for out-of-distribution detection. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 25874–25886 (2025) 4
2025
-
[20]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Hatamizadeh, A., Tang, Y., Nath, V., Yang, D., Myronenko, A., Landman, B., Roth, H.R., Xu, D.: Unetr: Transformers for 3d medical image segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 574–584 (2022) 12, 16, 26, 27, 28, 29, 30, 31
2022
-
[21]
arXiv preprint arXiv:1904.00445 (2019) 4
Heller, N., Sathianathen, N., Kalapara, A., Walczak, E., Moore, K., Kaluzniak, H., Rosenberg, J., Blake, P., Rengel, Z., Oestreich, M., et al.: The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes. arXiv preprint arXiv:1904.00445 (2019) 4
-
[22]
Holdcroft, A.: Gender bias in research: how does it affect evidence based medicine? (2007) 2
2007
-
[23]
Nature Medicine pp
Hu, C., Xia, Y., Zheng, Z., Cao, M., Zheng, G., Chen, S., Sun, J., Chen, W., Zheng, Q., Pan, S., et al.: Ai-based large-scale screening of gastric cancer from noncontrast ct imaging. Nature Medicine pp. 1–9 (2025) 2
2025
-
[24]
Advances in Neural Information Processing Systems37, 24496–24522 (2024) 2
Hu, K., Li, J., Zhang, Y., Ye, X., Gao, X.: One-to-multiple: A progressive style transfer unsupervised domain-adaptive framework for kidney tumor segmentation. Advances in Neural Information Processing Systems37, 24496–24522 (2024) 2
2024
-
[25]
arXiv preprint arXiv:2304.06716 (2023) 12, 17, 19, 26, 27, 28, 29, 30, 31 18 Q
Huang, Z., Wang, H., Deng, Z., Ye, J., Su, Y., Sun, H., He, J., Gu, Y., Gu, L., Zhang, S., et al.: Stu-net: Scalable and transferable medical image segmen- tation models empowered by large-scale supervised pre-training. arXiv preprint arXiv:2304.06716 (2023) 12, 17, 19, 26, 27, 28, 29, 30, 31 18 Q. Chen et al
-
[26]
Nature Methods18(2), 203–211 (2021) 12, 17, 19, 26, 27, 28, 29, 30, 31
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods18(2), 203–211 (2021) 12, 17, 19, 26, 27, 28, 29, 30, 31
2021
-
[27]
arXiv preprint arXiv:2404.09556 (2024) 12, 17, 19, 26, 27, 28, 29, 30, 31
Isensee, F., Wald, T., Ulrich, C., Baumgartner, M., Roy, S., Maier-Hein, K., Jaeger, P.F.: nnu-net revisited: A call for rigorous validation in 3d medical image segmen- tation. arXiv preprint arXiv:2404.09556 (2024) 12, 17, 19, 26, 27, 28, 29, 30, 31
-
[28]
In: 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC)
Jain, R.K., Sato, T., Watasue, T., Nakagawa, T., Iwamoto, Y., Han, X., Lin, L., Hu, H., Ruan, X., Chen, Y.W.: Unsupervised domain adaptation using adversarial learning and maximum square loss for liver tumors detection in multi-phase ct images. In: 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). pp. ...
2022
-
[29]
Nature Medicine30(4), 1166–1173 (2024) 3
Ktena, I., Wiles, O., Albuquerque, I., Rebuffi, S.A., Tanno, R., Roy, A.G., Azizi, S., Belgrave, D., Kohli, P., Cemgil, T., et al.: Generative models improve fairness of medical classifiers under distribution shifts. Nature Medicine30(4), 1166–1173 (2024) 3
2024
-
[30]
In: Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (2025),https: //github.com/MrGiovanni/PanTS5, 7
Li, W., Zhou, X., Chen, Q., Lin, T., Bassi, P.R., Chen, X., Ye, C., Zhu, Z., Ding, K., Li, H., Wang, K., Yang, Y., Tang, Y., Xu, D., Yuille, A.L., Zhou, Z.: Pants: The pancreatic tumor segmentation dataset. In: Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track (2025),https: //github.com/MrGiovanni/PanTS5, 7
2025
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J., Zhang, Y., Chen, J.N., Xiao, J., Lu, Y., Landman, B.A., Yuan, Y., Yuille, A., Tang, Y., Zhou, Z.: Clip-driven universal model for organ segmentation and tumor detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21152–21164 (2023),https://github.com/ljwztc/CLIP- Driven-Universal-Model12, 26, 27, 28, 29, 30, 31
2023
-
[32]
Medical image analysis98, 103295 (2024) 3, 12, 18, 26, 27, 28, 29, 30, 31
Liu, T., Bai, Q., Torigian, D.A., Tong, Y., Udupa, J.K.: Vsmtrans: A hybrid paradigm integrating self-attention and convolution for 3d medical image segmen- tation. Medical image analysis98, 103295 (2024) 3, 12, 18, 26, 27, 28, 29, 30, 31
2024
-
[33]
Nature communications 15(1), 7465 (2024) 3
Lotter, W.: Acquisition parameters influence ai recognition of race in chest x-rays and mitigating these factors reduces underdiagnosis bias. Nature communications 15(1), 7465 (2024) 3
2024
- [35]
-
[36]
Mastroianni, A.C., Faden, R., Federman, D., et al.: Women and health research: Ethical and legal issues of including women in clinical studies, vol. 1. National Academies Press (1994) 2
1994
-
[37]
IEEE Transactions on pattern analysis and machine intelligence22(10), 1090–1104 (2000) 2
Phillips, P.J., Moon, H., Rizvi, S.A., Rauss, P.J.: The feret evaluation method- ology for face-recognition algorithms. IEEE Transactions on pattern analysis and machine intelligence22(10), 1090–1104 (2000) 2
2000
-
[38]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 234–241. Springer (2015) 12, 16, 19, 26, 27, 28, 29, 30, 31
2015
-
[39]
In: International Conference on Medical Image Computing BenchX19 and Computer-Assisted Intervention
Roy, S., Koehler, G., Ulrich, C., Baumgartner, M., Petersen, J., Isensee, F., Jaeger, P.F., Maier-Hein, K.H.: Mednext: transformer-driven scaling of convnets for medi- cal image segmentation. In: International Conference on Medical Image Computing BenchX19 and Computer-Assisted Intervention. pp. 405–415. Springer (2023) 11, 12, 17, 19, 26, 27, 28, 29, 30, 31
2023
-
[40]
Journal of the Optical Society of America A4(3), 519–524 (1987) 2
Sirovich, L., Kirby, M.: Low-dimensional procedure for the characterization of hu- man faces. Journal of the Optical Society of America A4(3), 519–524 (1987) 2
1987
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tang, Y., Yang, D., Li, W., Roth, H.R., Landman, B., Xu, D., Nath, V., Hatamizadeh, A.: Self-supervised pre-training of swin transformers for 3d medi- cal image analysis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20730–20740 (2022) 12, 16, 26, 27, 28, 29, 30, 31
2022
-
[42]
arXiv preprint arXiv:2311.02189 (2023) 3
Tian, Y., Shi, M., Luo, Y., Kouhana, A., Elze, T., Wang, M.: Fairseg: A large-scale medical image segmentation dataset for fairness learning using segment anything model with fair error-bound scaling. arXiv preprint arXiv:2311.02189 (2023) 3
-
[43]
In: CVPR
Turk, M.A., Pentland, A., et al.: Face recognition using eigenfaces. In: CVPR. vol. 91, pp. 586–591 (1991) 2
1991
-
[44]
EBioMedicine102(2024) 3
Wang, R., Kuo, P.C., Chen, L.C., Seastedt, K.P., Gichoya, J.W., Celi, L.A.: Drop the shortcuts: image augmentation improves fairness and decreases ai detection of race and other demographics from medical images. EBioMedicine102(2024) 3
2024
-
[45]
arXiv preprint arXiv:2406.01264 (2024) 14
Wu, L., Zhuang, J., Ni, X., Chen, H.: Freetumor: Advance tumor segmentation via large-scale tumor synthesis. arXiv preprint arXiv:2406.01264 (2024) 14
-
[46]
medRxiv (2022) 2, 8
Xia, Y., Yu, Q., Chu, L., Kawamoto, S., Park, S., Liu, F., Chen, J., Zhu, Z., Li, B., Zhou, Z., Yuille, A.L., Fishman, E.K., Hruban, R.H.: The felix project: Deep networks to detect pancreatic neoplasms. medRxiv (2022) 2, 8
2022
-
[47]
Journal of medical imaging5(3), 036501 (2018) 3
Yan, K., Wang, X., Lu, L., Summers, R.M.: Deeplesion: automated mining of large- scale lesion annotations and universal lesion detection with deep learning. Journal of medical imaging5(3), 036501 (2018) 3
2018
-
[48]
Yang, Y., Zhang, H., Gichoya, J.W., Katabi, D., Ghassemi, M., et al.: The limits of fairmedicalimagingaiinreal-worldgeneralization.NatureMedicine30,2838–2848 (2024).https://doi.org/10.1038/s41591-024-03113-43
-
[49]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ye, Y., Xie, Y., Zhang, J., Chen, Z., Xia, Y.: Uniseg: A prompt-driven universal segmentation model as well as a strong representation learner. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 508–518. Springer (2023) 19
2023
-
[50]
small-model
Yin, Y., Tang, Z., Huang, Z., Wang, M., Weng, H.: Source free domain adaptation for kidney and tumor image segmentation with wavelet style mining. Scientific Reports14(1), 24849 (2024) 2 20 Q. Chen et al. Appendix Appendix A Dataset Curation Details........................................ 1 A.1 Tumor Annotations Details ................................. 1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.