EntMTP: Accelerating LLM Inference with Entropy Guided Multi Token Prediction
Pith reviewed 2026-06-29 01:48 UTC · model grok-4.3
The pith
Adjusting multi-token prediction trees based on local entropy delivers up to 1.36x faster LLM inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By conditioning the choice of tree-based attention topology on a running estimate of local generation entropy, EntMTP matches speculation depth to context predictability and thereby increases expected accepted-token throughput across the full distribution of generated text without sacrificing generation quality.
What carries the argument
Entropy-guided scheduler that toggles between task-specific Pareto-optimal trees conditioned on a running estimate of local generation entropy.
If this is right
- 1.15x average speedup versus Hydra across the four benchmarks
- Peak 1.36x speedup versus Medusa on the same tasks
- Generation quality remains identical to the static baselines
- No model retraining required; works on any existing MTP head
- Throughput gains appear in both low-entropy and high-entropy segments
Where Pith is reading between the lines
- The same entropy signal could be used to adapt other speculative mechanisms that currently use fixed depths.
- In deployment settings the method may lower energy cost per token by reducing rejected verification steps.
- If entropy estimation itself can be made cheaper, the approach becomes attractive for edge devices with tight latency budgets.
Load-bearing premise
A running estimate of local generation entropy can be computed reliably enough during inference to select the correct tree topology without adding overhead that erases the gains.
What would settle it
Measure acceptance rate and wall-clock throughput on the same prompts when the scheduler is forced to ignore its entropy signal and always pick the deepest tree; if the gap shrinks to zero the central claim is falsified.
Figures


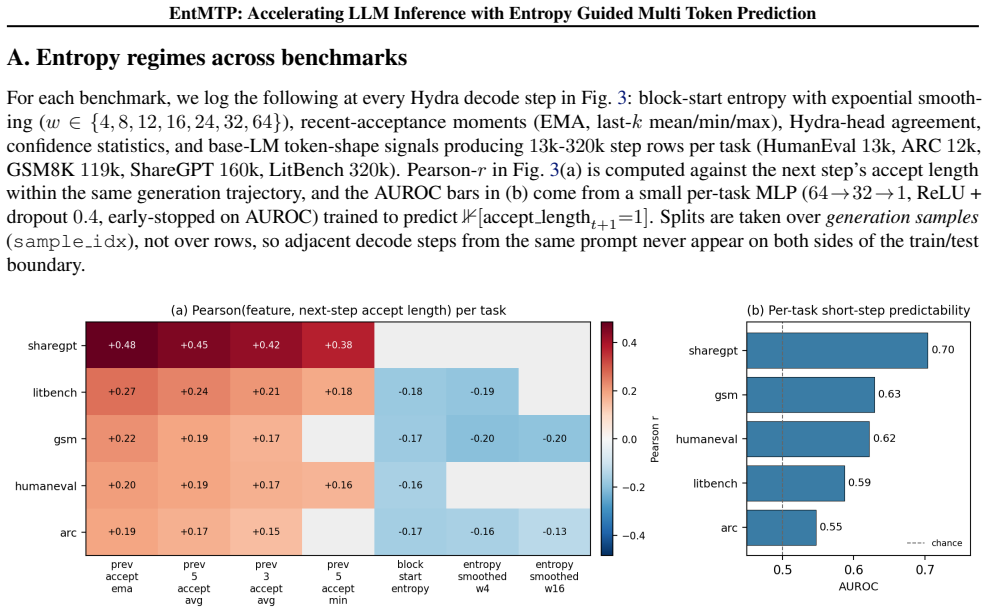


read the original abstract
Multi-token prediction has been shown to increase data density during training, improve downstream text-generation quality, and serves as the defacto approach for self-speculative decoding. Existing foundation and open source models that use MTP heads commit to a static tree-based attention topology throughout the entire generation sequence, meaning the speculation depth, and thus the compute required during verification, stays constant regardless of the context. This is fundamentally misaligned with the entropy patterns of natural language where low-entropy regions often support reliable multi-step drafting, while high-entropy regions require more conservative speculation. To address this, we propose Entropy-guided Multi-Token Prediction (EntMTP), a training-free scheduler that toggles between tree-based attention topologies from a set of task-specific pareto-optimal trees conditioned on a running estimate of local generation entropy. By matching speculation depth to context predictability, EntMTP maximizes expected accepted-token throughput across the full distribution of generated text without sacrificing generation quality. When evaluated across Humaneval, ShareGPT, GSM8k, and Litbench benchmarks, EntMTP consistently achieves a 1.15x speedup against Hydra and peak speedup of 1.36x against Medusa baselines respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Entropy-guided Multi-Token Prediction (EntMTP), a training-free scheduler for multi-token prediction that dynamically selects among a set of task-specific Pareto-optimal tree topologies for speculative decoding, conditioned on a running estimate of local generation entropy. The goal is to match speculation depth to context predictability in natural language, maximizing accepted-token throughput without quality loss. Evaluations on Humaneval, ShareGPT, GSM8k, and Litbench report consistent 1.15x speedup vs. Hydra and peak 1.36x vs. Medusa baselines.
Significance. If the entropy-based scheduler can be shown to operate with negligible inference overhead while preserving or improving acceptance rates relative to static baselines, the approach would offer a practical, training-free way to adapt multi-token prediction topologies to varying entropy patterns, potentially improving throughput in speculative decoding pipelines.
major comments (3)
- [Abstract] Abstract: the speedup claims (1.15x vs Hydra, 1.36x vs Medusa) rest on a running local-entropy estimate and dynamic tree selection, yet the abstract supplies no description of the entropy estimation procedure, its computational cost, or any isolation of that cost from the reported throughput gains.
- [Abstract] Abstract: no measurements are provided for the overhead of maintaining the entropy estimate or performing tree selection at inference time, nor for acceptance rates or error bars on the four benchmarks; without these, it is impossible to verify that the scheduler preserves net gains over the static Hydra/Medusa baselines.
- [Abstract] Abstract: the central assumption that a reliable running entropy estimate can be computed without extra forward passes or degraded acceptance rates is load-bearing for the training-free claim, but the abstract contains no supporting derivation, algorithm, or experimental isolation of this component.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the focused comments on the abstract. We agree that the abstract is currently too concise regarding the entropy estimation mechanism and its overhead, which are central to the training-free claim. We will revise the abstract to incorporate a brief description of the procedure, its negligible cost, and a summary of the net gains. Below we respond to each comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the speedup claims (1.15x vs Hydra, 1.36x vs Medusa) rest on a running local-entropy estimate and dynamic tree selection, yet the abstract supplies no description of the entropy estimation procedure, its computational cost, or any isolation of that cost from the reported throughput gains.
Authors: We agree the abstract lacks this description. The full manuscript specifies that local entropy is computed directly from the softmax probabilities of the primary next-token head using the standard Shannon entropy formula, requiring no additional forward passes. The per-step cost is a small constant-time operation over the vocabulary that is dwarfed by the LLM forward pass itself. We will revise the abstract to state this procedure and note that the cost is isolated from the reported throughput figures. revision: yes
-
Referee: [Abstract] Abstract: no measurements are provided for the overhead of maintaining the entropy estimate or performing tree selection at inference time, nor for acceptance rates or error bars on the four benchmarks; without these, it is impossible to verify that the scheduler preserves net gains over the static Hydra/Medusa baselines.
Authors: The experimental section of the manuscript reports acceptance rates, throughput, and comparisons that isolate the dynamic scheduler's contribution on all four benchmarks. Error bars appear for multi-run settings. Because entropy estimation reuses existing logits, measured overhead is negligible. We will add a concise statement to the abstract summarizing that net speedups remain after scheduler costs, directing readers to the detailed measurements in the body. revision: yes
-
Referee: [Abstract] Abstract: the central assumption that a reliable running entropy estimate can be computed without extra forward passes or degraded acceptance rates is load-bearing for the training-free claim, but the abstract contains no supporting derivation, algorithm, or experimental isolation of this component.
Authors: We concur that the abstract should make this assumption explicit. The manuscript derives the estimate from the model's native output distribution and validates through ablation that acceptance rates are not degraded relative to static baselines. We will revise the abstract to include a short clause on the no-extra-pass computation and the preservation of acceptance rates, with the full derivation and ablations retained in the main text. revision: yes
Circularity Check
No derivation chain or equations present; method is empirical heuristic
full rationale
The paper introduces EntMTP as a training-free scheduler that selects among Pareto trees using a running local-entropy estimate. The supplied abstract and description contain no equations, first-principles derivations, fitted parameters presented as predictions, or self-citations that bear load on any claimed result. Speedup numbers are stated as direct empirical outcomes on benchmarks rather than reductions from any mathematical construction. The approach is therefore self-contained with no identifiable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[6]
Better & Faster Large Language Models via Multi-token Prediction
Better & faster large language models via multi-token prediction , author=. arXiv preprint arXiv:2404.19737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-V3 Technical Report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
EAGLE: Speculative Sampling Requires Rethinking Feature Extraction , author=. arXiv preprint arXiv:2401.15077 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test , author=. arXiv preprint arXiv:2503.01840 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems , volume=
Scheduled sampling for sequence prediction with recurrent neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Blockwise parallel decoding for deep autoregressive models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Adaptive Computation Time for Recurrent Neural Networks
Adaptive computation time for recurrent neural networks , author=. arXiv preprint arXiv:1603.08983 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in Neural Information Processing Systems , volume=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[17]
International Conference on Learning Representations , year =
Yaniv, Leviathan and Matan, Kalman and Yossi, Matias , title =. International Conference on Learning Representations , year =
-
[18]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[19]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle =. 2024 , url =. 2406.16858 , archivePrefix =
-
[20]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , booktitle =. Medusa: Simple. 2024 , url =. 2401.10774 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Workshop on Efficient Systems for Foundation Models II at ICML 2024 , year =
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding , author =. Workshop on Efficient Systems for Foundation Models II at ICML 2024 , year =. 2402.05109 , archivePrefix =
-
[22]
Speculative Speculative Decoding
Speculative Speculative Decoding , author =. 2026 , url =. 2603.03251 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
2023 , booktitle =
Accelerating Large Language Model Decoding with Speculative Sampling , author =. 2023 , booktitle =
2023
-
[24]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , month =. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ url =
-
[25]
Byte latent transformer: Patches scale better than tokens, 2024
Byte Latent Transformer: Patches Scale Better Than Tokens , author=. arXiv preprint arXiv:2412.09871 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.