Symbolic and Abstractive Reasoning with Complex Visual Queries
Pith reviewed 2026-06-27 16:44 UTC · model grok-4.3
The pith
A pipeline generates complex visual queries from knowledge graphs to test and train symbolic reasoning in multi-modal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
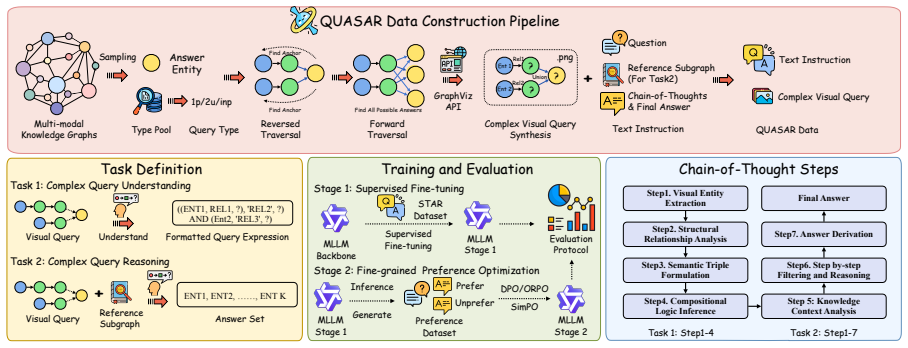
We propose a scalable pipeline for synthesizing CVQs grounded in large-scale multi-modal knowledge graphs, generating a diverse dataset encompassing 14 distinct query types via systematic combinations of first-order logic operators. We further introduce a two-stage training framework that progressively equips MLLMs with robust visual reasoning capabilities.
What carries the argument
The complex visual query, an abstract data type formed by combining first-order logic operators on elements from multi-modal knowledge graphs to require symbolic and abstractive visual reasoning.
If this is right
- MLLMs trained with the two-stage framework show improved reasoning on the 14 CVQ types.
- Performance metrics on CVQs serve as a measure of neuro-symbolic capability.
- The training yields better cross-task and cross-scenario generalization on visual reasoning problems.
Where Pith is reading between the lines
- The synthesis approach could extend to queries requiring higher-order logic or integration with external tools.
- Success on these queries might predict performance on real-world tasks like diagram interpretation or visual puzzle solving.
Load-bearing premise
Queries created by combining logic operators on knowledge graphs force models to use genuine symbolic reasoning instead of surface-level statistical patterns.
What would settle it
Models achieving high accuracy on the generated CVQ dataset without the two-stage training, or by exploiting correlations unrelated to the logic structure, would indicate the queries do not probe the intended reasoning.
Figures







read the original abstract
Understanding and reasoning over abstract visual content remains a challenge for current multi-modal large language models (MLLMs). In this paper, we explore a novel abstract data type termed complex visual query (CVQ), designed to probe symbolic and abstractive reasoning, which is a critical yet underexplored dimension of human-like neuro-symbolic reasoning for MLLMs. We present a comprehensive investigation from three perspectives: \textbf{Data $\times$ Paradigm $\times$ Exploration}. Specifically, we propose a scalable pipeline for synthesizing CVQs grounded in large-scale multi-modal knowledge graphs, generating a diverse dataset encompassing 14 distinct query types via systematic combinations of first-order logic operators. We further introduce a two-stage training framework that progressively equips MLLMs with robust visual reasoning capabilities. We conduct extensive experiments to rigorously evaluate MLLMs across multiple dimensions, including reasoning performance on CVQs, as well as cross-task and cross-scenario generalization. We believe our work opens new perspectives and avenues for advancing the reasoning frontiers of MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Complex Visual Queries (CVQs) as a novel data type to probe symbolic and abstractive reasoning in MLLMs. It describes a scalable synthesis pipeline that generates a dataset of 14 query types by composing first-order logic operators over multi-modal knowledge graphs, proposes a two-stage training framework to improve MLLM visual reasoning, and reports extensive experiments evaluating reasoning performance along with cross-task and cross-scenario generalization.
Significance. If the CVQs genuinely require execution of the logical operators rather than surface statistics and if the two-stage framework produces measurable gains, the work would supply both a new benchmark construction method and a training approach that could advance neuro-symbolic capabilities in MLLMs beyond current statistical pattern matching.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that the synthesized CVQs probe symbolic and abstractive reasoning (rather than statistical shortcuts such as entity co-occurrence or template regularities) is not supported by any reported controls (e.g., answer permutation while preserving marginals, or evaluation on operator combinations absent from training). Without such isolation, the dataset and training results cannot substantiate the symbolic-reasoning interpretation.
- [Abstract] Abstract: the manuscript states that 'extensive experiments' were conducted to evaluate reasoning performance and generalization, yet supplies no quantitative results, baselines, error analysis, or validation metrics. This absence is load-bearing because the paper's contribution rests on demonstrating that the pipeline and framework achieve the claimed improvements.
minor comments (2)
- [Abstract] The three-perspective framing (Data × Paradigm × Exploration) is introduced in the abstract but never given explicit section headings or a clear mapping to the manuscript structure.
- [Introduction] The term 'Complex Visual Query (CVQ)' is introduced as an invented entity without a formal definition or distinguishing criteria relative to existing visual question-answering formats.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address each major comment below with clarifications from the full manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that the synthesized CVQs probe symbolic and abstractive reasoning (rather than statistical shortcuts such as entity co-occurrence or template regularities) is not supported by any reported controls (e.g., answer permutation while preserving marginals, or evaluation on operator combinations absent from training). Without such isolation, the dataset and training results cannot substantiate the symbolic-reasoning interpretation.
Authors: The CVQ synthesis pipeline constructs each of the 14 query types through explicit, systematic composition of first-order logic operators over multi-modal knowledge graphs. This design ensures that solving a query requires executing the specified logical operations on the underlying entities and relations rather than relying on co-occurrence statistics or fixed templates, as the operator combinations and grounding vary per instance. That said, we agree that explicit controls would further isolate the reasoning component. We will add experiments involving answer permutation (preserving marginals) and evaluation on operator combinations held out from training in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that 'extensive experiments' were conducted to evaluate reasoning performance and generalization, yet supplies no quantitative results, baselines, error analysis, or validation metrics. This absence is load-bearing because the paper's contribution rests on demonstrating that the pipeline and framework achieve the claimed improvements.
Authors: The abstract follows standard conventions by summarizing contributions at a high level. The full Experiments section reports quantitative results across the 14 query types, baseline comparisons, error analyses, and cross-task/cross-scenario generalization metrics. To address the concern, we will revise the abstract to include key quantitative highlights and validation metrics. revision: yes
Circularity Check
No circularity: methodological proposal with no derivations or self-referential reductions
full rationale
The paper presents a data synthesis pipeline and two-stage training framework for CVQs based on FOL operator combinations over multi-modal KGs. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. The central claims rest on the construction of the dataset and training procedure rather than any reduction of outputs to inputs by definition or self-citation. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale multi-modal knowledge graphs exist and can ground visual queries via first-order logic combinations
invented entities (1)
-
Complex Visual Query (CVQ)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Visualsem: a high-quality knowledge graph for vision and language.CoRR, abs/2008.09150. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhi- fang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025. Qwen3-...
arXiv 2008
-
[2]
Translating embeddings for modeling multi- relational data. InNIPS, pages 2787–2795. Nurendra Choudhary and Chandan K. Reddy. 2023. Complex logical reasoning over knowledge graphs using large language models.CoRR, abs/2305.01157. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image databas...
arXiv 2023
-
[3]
IEEE Computer Society. John Ellson, Emden R. Gansner, Eleftherios Koutsofios, Stephen C. North, and Gordon Woodhull. 2004. Graphviz and dynagraph - static and dynamic graph drawing tools. InGraph Drawing Software, pages 127–148. Springer. Ling Fu, Biao Yang, Zhebin Kuang, Jiajun Song, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Mingxin Huang, Zha...
Pith/arXiv arXiv 2004
-
[4]
InECCV (4), Lecture Notes in Computer Science, pages 235–
A diagram is worth a dozen images. InECCV (4), Lecture Notes in Computer Science, pages 235–
-
[5]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee
Springer. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved baselines with visual instruc- tion tuning. 9 Xiao Liu, Shiyu Zhao, Kai Su, Yukuo Cen, Jiezhong Qiu, Mengdi Zhang, Wei Wu, Yuxiao Dong, and Jie Tang. 2022. Mask and reason: Pre-training knowl- edge graph transformers for complex logical queries. InKDD, pages 1120–1130. ACM. Pa...
2023
-
[6]
InNeurIPS
Direct preference optimization: Your language model is secretly a reward model. InNeurIPS. Hongyu Ren, Weihua Hu, and Jure Leskovec. 2020. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. InICLR. Open- Review.net. Hongyu Ren and Jure Leskovec. 2020. Beta embed- dings for multi-hop logical reasoning in knowledge graphs. InNe...
2020
-
[7]
Towards vqa models that can read. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8317–8326. Shezheng Song, Xiaopeng Li, and Shasha Li. 2023. How to bridge the gap between modalities: A compre- hensive survey on multimodal large language model. CoRR, abs/2311.07594. Fabian M. Suchanek, Gjergji Kasneci, and Gerhard ...
arXiv 2023
-
[8]
{ head1 }
Arrow from "{ head1 }" to " Entity Set A " with label "'{ relation1 }'"
-
[9]
Entity Set A
Dashed arrow from " Entity Set A " to the " Intersection " symbol with label "'{ relation2 }'"
-
[10]
{ head2 }
A RED dashed arrow ( labeled [ NOT ]) from "{ head2 }" to the " Intersection " symbol with label "'{ relation3 }'"
-
[11]
Intersection
A dashed arrow points from the " Intersection " symbol to " Entity Set B ". Step 3: Semantic Triplet Formulation Based on the visual components , I formulate the semantic triplets : We are looking for a target entity set [? y ] ( Entity Set B ) that satisfies a 2 - hop positive path while excluding a negative condition . Positive Condition ( Path ) : - Tr...
-
[12]
Projection 1: Find intermediate entities [ Entity Set A ] connected to [{ head1 }] via ['{ relation1 }']
-
[13]
Projection 2: Find potential targets connected to [ Entity Set A ] via ['{ relation2 }']
-
[14]
Negative Search : Find entities connected to [{ head2 }] via ['{ relation3 }']
-
[15]
Difference Operation : Subtract the results of the Negative Search from the results of Projection 2
-
[16]
</ think > < Answer > (({ head1 } ,'{ relation1 }', ?) ,'{ relation2 }', ?) AND ( NOT ({ head2 } ,'{ relation3 }', ?) ) </ Answer > Figure 9: The CoT prompt template for Task1 CQU
Result : Entity Set B . </ think > < Answer > (({ head1 } ,'{ relation1 }', ?) ,'{ relation2 }', ?) AND ( NOT ({ head2 } ,'{ relation3 }', ?) ) </ Answer > Figure 9: The CoT prompt template for Task1 CQU. We only present pin query for demonstration due to the huge volume of 14 full templates. We submit the full templates in the supplemental materials. 14 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.