StairMaster: Learning to Conquer Risky Hollow Stairs for Agile Quadrupedal Robots
Pith reviewed 2026-06-25 20:56 UTC · model grok-4.3
The pith
A three-stage RL framework with cross-attention and recurrent memory lets quadruped robots climb hollow stairs at 55-degree inclines via zero-shot sim-to-real transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
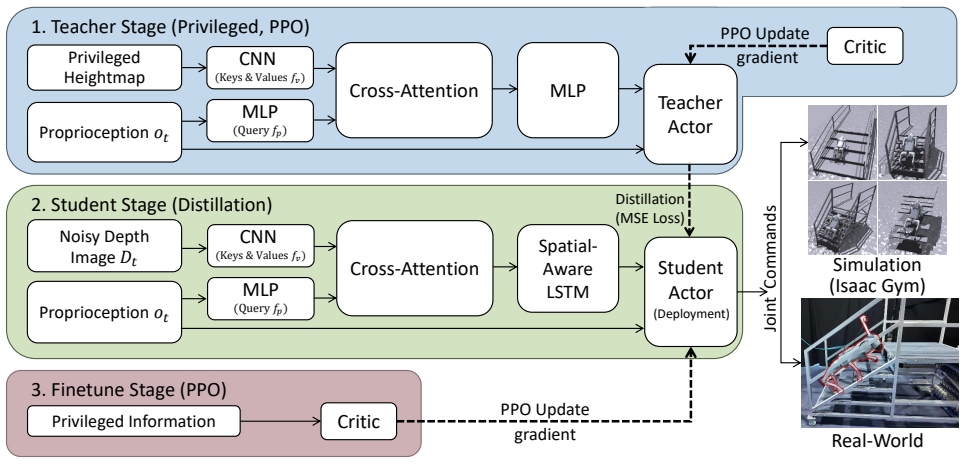
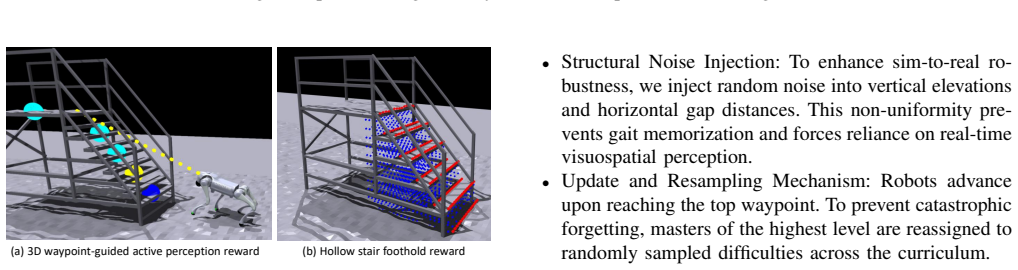
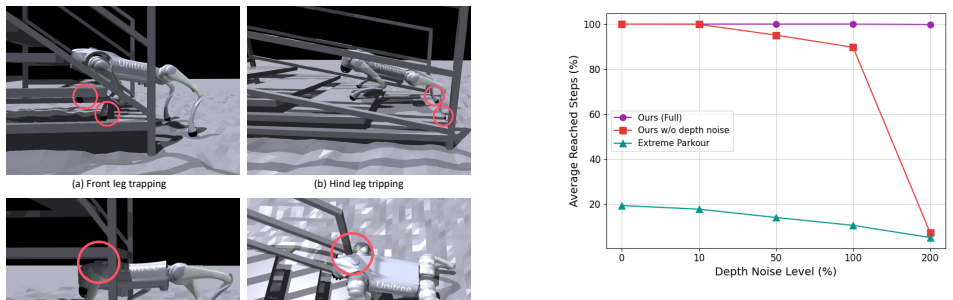
StairMaster is a three-stage reinforcement learning framework that integrates a Cross-Attention mechanism to extract structural features from noisy depth data, a Spatial-aware Recurrent Unit to maintain spatio-temporal memory against perception blind spots, a high-fidelity sim-to-real depth sensor modeling pipeline that replicates real artifacts, a 3D waypoint-guided active perception reward for proactive sensing, and hollow gap kinematic plus stair edge penalties for precise foothold placement. When deployed, the resulting policy enables a Unitree Go2 robot to climb hollow stairs up to 55 degrees in the real world through zero-shot transfer, the first RL-based policy reported to achieve thi
What carries the argument
StairMaster, the three-stage RL architecture that fuses cross-attention for depth feature extraction, a Spatial-aware Recurrent Unit for memory, and a high-fidelity depth sensor simulation pipeline to produce transferable policies.
If this is right
- The policy achieves precise foothold selection that avoids hollow gaps on steep inclines.
- Active perception rewards allow the robot to gather depth information before committing to each step.
- Kinematic penalties combined with stair edge terms reduce the frequency of trapping events.
- Zero-shot transfer succeeds at inclines not previously demonstrated by RL methods on real hardware.
Where Pith is reading between the lines
- The same attention-plus-recurrent structure could be tested on other robots that rely on depth for foothold selection in cluttered spaces.
- Extending the sensor modeling pipeline to different camera models might allow reuse across robot platforms without new training.
- The waypoint reward could be adapted to encourage exploration of alternative routes when stairs become blocked.
Load-bearing premise
The simulation of depth sensor artifacts matches real-world noise and sparsity closely enough that a policy trained only in simulation will work on the physical robot without any real-world retraining.
What would settle it
Run the deployed policy on the physical robot on 55-degree hollow stairs and record whether depth images produce the same artifacts as the simulated sensor model; mismatch that causes leg trapping or falls would falsify the transfer claim.
Figures





read the original abstract
Climbing hollow stairs remains a challenging problem for quadruped robots due to the high risk of leg trapping, severe depth sparsity, and high-frequency depth-sensing noise. In this paper, we propose StairMaster, a novel three-stage reinforcement learning framework for stable locomotion on such extreme discontinuous terrains. Our architecture integrates a Cross-Attention mechanism to extract structural features from noisy depth data, alongside a Spatial-aware Recurrent Unit (SRU) that maintains robust spatio-temporal memory to mitigate perception blind spots. To bridge the sim-to-real gap in depth perception, we propose a high-fidelity sim-to-real depth sensor modeling pipeline that faithfully replicates real-world sensor artifacts. Additionally, we employ a 3D waypoint-guided active perception reward for proactive sensing, alongside hollow gap kinematic and stair edge penalties to ensure precise foothold placement. We successfully deployed StairMaster on a Unitree Go2 robot, demonstrating its ability to conquer hollow stairs with an unprecedented incline of up to 55$^\circ$ through zero-shot transfer. To the best of our knowledge, this is the first RL-based policy to achieve such steep hollow stair climbing in real-world environments. Project Website: https://sivan666666.github.io/StairMaster/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StairMaster, a three-stage RL framework for quadrupedal locomotion on risky hollow stairs. It combines cross-attention for extracting features from noisy/sparse depth, a Spatial-aware Recurrent Unit (SRU) for spatio-temporal memory, a high-fidelity sim-to-real depth sensor modeling pipeline, 3D waypoint-guided active perception rewards, and kinematic/edge penalties. The central empirical claim is successful zero-shot transfer of the policy to a Unitree Go2 robot, enabling traversal of hollow stairs at up to 55° incline—the first such RL result in real-world settings.
Significance. If the zero-shot deployment claim is substantiated with quantitative evidence, the work would advance sim-to-real RL for perception-heavy locomotion on discontinuous, high-risk terrain. The emphasis on depth artifact modeling and proactive perception addresses documented failure modes in stair climbing; successful validation could inform policies for construction, inspection, or disaster-response robots.
major comments (3)
- [Abstract] Abstract: the claim of 'successful deployment' and 'unprecedented incline of up to 55° through zero-shot transfer' is presented without any quantitative metrics (success rate, number of trials, traversal time, failure cases, or statistical comparison to baselines). This absence makes the central empirical result impossible to evaluate.
- [Abstract / depth sensor modeling pipeline] Abstract and methods description of the depth sensor pipeline: the assertion that the 'high-fidelity sim-to-real depth sensor modeling pipeline faithfully replicates real-world sensor artifacts' is load-bearing for the zero-shot transfer claim, yet no validation data (distribution matching, error histograms, sparsity statistics, or terrain-specific comparisons on hollow geometry) are supplied.
- [Abstract] Abstract: the statement 'to the best of our knowledge, this is the first RL-based policy' is unsupported by any literature comparison table or explicit discussion of prior hollow-stair or steep-incline RL results, weakening the novelty claim.
minor comments (2)
- The three-stage architecture is referenced but not enumerated with stage boundaries or loss formulations; a numbered list or diagram would improve clarity.
- No mention of robot mass, actuator limits, or exact depth camera model (e.g., RealSense parameters) used in the sim-to-real pipeline; these details are needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires strengthening with quantitative evidence and supporting details. We will revise the abstract and add relevant sections or figures in the manuscript to address all points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'successful deployment' and 'unprecedented incline of up to 55° through zero-shot transfer' is presented without any quantitative metrics (success rate, number of trials, traversal time, failure cases, or statistical comparison to baselines). This absence makes the central empirical result impossible to evaluate.
Authors: We agree that the abstract should include key quantitative metrics to substantiate the deployment claims. The full manuscript reports these details in the experiments section (success rates over multiple trials, traversal times, and baseline comparisons). We will revise the abstract to incorporate representative metrics such as success rate, number of trials, and failure modes. revision: yes
-
Referee: [Abstract / depth sensor modeling pipeline] Abstract and methods description of the depth sensor pipeline: the assertion that the 'high-fidelity sim-to-real depth sensor modeling pipeline faithfully replicates real-world sensor artifacts' is load-bearing for the zero-shot transfer claim, yet no validation data (distribution matching, error histograms, sparsity statistics, or terrain-specific comparisons on hollow geometry) are supplied.
Authors: We acknowledge that explicit validation data for the depth sensor pipeline would strengthen the zero-shot transfer claim. We will add a dedicated validation subsection or figure presenting error histograms, sparsity statistics, and terrain-specific comparisons between simulated and real depth data on hollow geometries. revision: yes
-
Referee: [Abstract] Abstract: the statement 'to the best of our knowledge, this is the first RL-based policy' is unsupported by any literature comparison table or explicit discussion of prior hollow-stair or steep-incline RL results, weakening the novelty claim.
Authors: We will revise the manuscript to include a literature comparison table and explicit discussion of prior RL results on stair climbing and steep inclines. This will clarify the novelty with respect to hollow stairs at 55 degrees and support the 'first RL-based policy' statement. revision: yes
Circularity Check
No circularity: empirical deployment claim is self-contained
full rationale
The paper reports an empirical real-world deployment result on a physical Unitree Go2 robot achieving 55° hollow stair climbing via zero-shot RL transfer. The abstract and provided text describe a three-stage RL framework, attention mechanisms, recurrent units, a depth sensor modeling pipeline, and reward terms, but present no equations, fitted parameters, or self-citations that reduce the reported success to a definitional or constructional identity with the inputs. The central claim remains an external falsifiable outcome rather than a renaming or self-referential prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[2]
Rma: Rapid motor adaptation for legged robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,”arXiv preprint arXiv:2107.04034, 2021
Pith/arXiv arXiv 2021
-
[3]
Learning agile robotic locomotion skills by imitating animals. arxiv 2020,
X. Peng, E. Coumans, T. Zhang, T. Lee, J. Tan, and S. Levine, “Learning agile robotic locomotion skills by imitating animals. arxiv 2020,”arXiv preprint arXiv:2004.00784, 2020
arXiv 2020
-
[4]
Learning robust and agile legged locomotion using adversarial motion priors,
J. Wu, G. Xin, C. Qi, and Y . Xue, “Learning robust and agile legged locomotion using adversarial motion priors,”IEEE Robotics and Automation Letters, vol. 8, no. 8, pp. 4975–4982, 2023
2023
-
[5]
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,”arXiv preprint arXiv:2309.05665, 2023
arXiv 2023
-
[6]
Agile continuous jumping in discontinuous terrains,
Y . Yang, G. Shi, C. Lin, X. Meng, R. Scalise, M. G. Castro, W. Yu, T. Zhang, D. Zhao, J. Tanet al., “Agile continuous jumping in discontinuous terrains,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 245–10 252
2025
-
[7]
Extreme parkour with legged robots,
X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 443–11 450
2024
-
[8]
Kivi: Kinesthetic-visuospatial integration for dynamic and safe egocentric legged locomotion,
P. Li, H. Li, Y . Ma, L. Chang, X. Yang, R. Yu, Y . Zhang, Y . Cao, Q. Zhu, and G. Sartoretti, “Kivi: Kinesthetic-visuospatial integration for dynamic and safe egocentric legged locomotion,”arXiv preprint arXiv:2509.23650, 2025
Pith/arXiv arXiv 2025
-
[9]
Renet: Fault-tolerant motion control for quadruped robots via redun- dant estimator networks under visual collapse,
Y . Zhang, Q. Qian, T. Hou, P. Zhai, X. Wei, K. Hu, J. Yi, and L. Zhang, “Renet: Fault-tolerant motion control for quadruped robots via redun- dant estimator networks under visual collapse,”IEEE Robotics and Automation Letters, 2025
2025
-
[10]
N. Rudin, J. He, J. Aurand, and M. Hutter, “Parkour in the wild: Learn- ing a general and extensible agile locomotion policy using multi-expert distillation and rl fine-tuning,”arXiv preprint arXiv:2505.11164, 2025
arXiv 2025
-
[11]
Hiking in the wild: A scalable perceptive parkour framework for humanoids,
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao, “Hiking in the wild: A scalable perceptive parkour framework for humanoids,”arXiv preprint arXiv:2601.07718, 2026
arXiv 2026
-
[12]
Spatially-enhanced recurrent memory for long-range mapless naviga- tion via end-to-end reinforcement learning,
F. Yang, P. Frivik, D. Hoeller, C. Wang, C. Cadena, and M. Hutter, “Spatially-enhanced recurrent memory for long-range mapless naviga- tion via end-to-end reinforcement learning,”The International Journal of Robotics Research, p. 02783649251401926, 2025
2025
-
[13]
Mit cheetah 3: Design and control of a robust, dynamic quadruped robot,
G. Bledt, M. J. Powell, B. Katz, J. Di Carlo, P. M. Wensing, and S. Kim, “Mit cheetah 3: Design and control of a robust, dynamic quadruped robot,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 2245–2252
2018
-
[14]
Rapid locomotion via reinforcement learning,
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal, “Rapid locomotion via reinforcement learning,”The International Journal of Robotics Research, vol. 43, no. 4, pp. 572–587, 2024
2024
-
[15]
Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,
G. Ji, J. Mun, H. Kim, and J. Hwangbo, “Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4630–4637, 2022
2022
-
[16]
I. Nahrendra, B. Yu, and H. Myung, “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,”arXiv preprint arXiv:2301.10602, 2023
arXiv 2023
-
[17]
Robust robot walker: Learning agile locomotion over tiny traps,
S. Zhu, R. Huang, L. Mou, and H. Zhao, “Robust robot walker: Learning agile locomotion over tiny traps,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 15 987–15 993
2025
-
[18]
Hybrid internal model: Learning agile legged locomotion with simulated robot response,
J. Long, Z. Wang, Q. Li, J. Gao, L. Cao, and J. Pang, “Hybrid internal model: Learning agile legged locomotion with simulated robot response,”arXiv preprint arXiv:2312.11460, 2023
arXiv 2023
-
[19]
Robust ladder climbing with a quadrupedal robot,
D. V ogel, R. Baines, J. Church, J. Lotzer, K. Werner, and M. Hutter, “Robust ladder climbing with a quadrupedal robot,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 7239–7244
2025
-
[20]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science robotics, vol. 5, no. 47, p. eabc5986, 2020
2020
-
[21]
Deep whole-body control: learning a unified policy for manipulation and locomotion,
Z. Fu, X. Cheng, and D. Pathak, “Deep whole-body control: learning a unified policy for manipulation and locomotion,” inConference on Robot Learning. PMLR, 2023, pp. 138–149
2023
-
[22]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadi7566, 2024
2024
-
[23]
Attention-based map encoding for learning generalized legged loco- motion,
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter, “Attention-based map encoding for learning generalized legged loco- motion,”Science Robotics, vol. 10, no. 105, p. eadv3604, 2025
2025
-
[24]
Ame-2: Agile and gen- eralized legged locomotion via attention-based neural map encoding,
C. Zhang, V . Klemm, F. Yang, and M. Hutter, “Ame-2: Agile and gen- eralized legged locomotion via attention-based neural map encoding,” arXiv preprint arXiv:2601.08485, 2026
arXiv 2026
-
[25]
Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers,
R. Yang, M. Zhang, N. Hansen, H. Xu, and X. Wang, “Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers,”arXiv preprint arXiv:2107.03996, 2021
arXiv 2021
-
[26]
Legged locomotion in challenging terrains using egocentric vision,
A. Agarwal, A. Kumar, J. Malik, and D. Pathak, “Legged locomotion in challenging terrains using egocentric vision,” inConference on robot learning. PMLR, 2023, pp. 403–415
2023
-
[27]
Pie: Parkour with implicit-explicit learning framework for legged robots,
S. Luo, S. Li, R. Yu, Z. Wang, J. Wu, and Q. Zhu, “Pie: Parkour with implicit-explicit learning framework for legged robots,”IEEE Robotics and Automation Letters, vol. 9, no. 11, pp. 9986–9993, 2024
2024
-
[28]
World model-based perception for visual legged locomotion,
H. Lai, J. Cao, J. Xu, H. Wu, Y . Lin, T. Kong, Y . Yu, and W. Zhang, “World model-based perception for visual legged locomotion,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 531–11 537
2025
-
[29]
Walk the planc: Physics-guided rl for agile humanoid locomotion on constrained footholds,
M. Dai, W. D. Compton, J. Li, L. Yang, and A. D. Ames, “Walk the planc: Physics-guided rl for agile humanoid locomotion on constrained footholds,”arXiv preprint arXiv:2601.06286, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.