Audio-Image Cross-Modal Retrieval with Onomatopoeic Images
Pith reviewed 2026-05-19 22:26 UTC · model grok-4.3
The pith
Training modality-specific projection heads on paired onomatopoeic data enables bidirectional audio-image retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
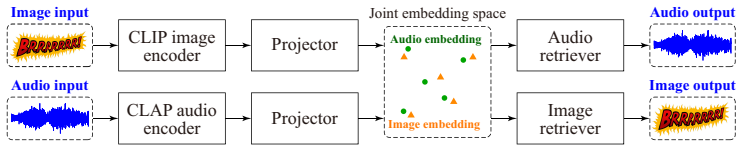
Instead of directly comparing embeddings from pretrained image and audio encoders, training modality-specific projection heads to re-align them on the Multimodal Image-Audio Onomatopoeia dataset enables effective bidirectional retrieval between onomatopoeic images and corresponding sound clips, outperforming a zero-shot baseline.
What carries the argument
Modality-specific projection heads that re-align embeddings for visual onomatopoeia and their matching sounds.
If this is right
- Retrieval works in both directions: onomatopoeic image to sound and sound to onomatopoeic image.
- Performance exceeds that of using the pretrained encoders without additional training.
- The framework applies directly to the 50 sound event classes covered by the new paired dataset.
- The approach addresses the manual search problem in multimedia production workflows.
Where Pith is reading between the lines
- The same projection-head approach could be tested on onomatopoeic styles from languages or comic traditions not represented in the current data.
- If the re-aligned embeddings prove stable, they could support retrieval inside larger commercial sound libraries.
- A natural next measurement would be how well the method handles novel artistic variations of the same sound class.
Load-bearing premise
That training modality-specific projection heads on the MIAO dataset will produce embeddings that generalize to unseen onomatopoeic images and sounds outside the 50 classes.
What would settle it
A drop in retrieval accuracy when the system is tested on onomatopoeic images and sounds drawn from sound event classes absent from the original 50-class training set.
Figures


read the original abstract
Finding sound effects or environmental sounds that match a creator's intended impression remains a largely manual process in multimedia production. This is especially relevant for comics and other visual media, where visually stylized onomatopoeic expressions convey auditory impressions through letter shapes, strokes, layouts, and decorative patterns. However, cross-modal retrieval between onomatopoeic images and general sounds has been largely unexplored. This paper thus introduces a bidirectional retrieval framework between onomatopoeic images and the corresponding sound clips. Instead of directly comparing embeddings extracted from pretrained image and audio encoder, we train modality-specific projection heads that re-align the embeddings for visual onomatopoeia and corresponding sounds. We then construct the Multimodal Image-Audio Onomatopoeia dataset (MIAO), which contains paired onomatopoeic images and sound clips across 50 sound event classes. Experimental results show that the proposed method substantially outperforms a zero-shot baseline using pretrained CLIP and CLAP embeddings. These results demonstrate that adapting pretrained representations enables effective retrieval in both directions: from onomatopoeic images to sounds and from sounds to onomatopoeic images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a bidirectional cross-modal retrieval framework for onomatopoeic images and corresponding sound clips. It constructs the MIAO dataset of paired onomatopoeic images and audio across 50 sound event classes, trains modality-specific projection heads atop pretrained CLIP and CLAP embeddings to re-align the two modalities, and reports that the resulting system substantially outperforms a zero-shot baseline that directly compares the original embeddings.
Significance. If the reported gains are shown to arise from a generalizable alignment rather than class-specific memorization, the work would be a useful contribution to multimedia production tools, particularly for automated sound-effect selection in comics and visual media. The construction of the MIAO dataset itself is a concrete asset that could support follow-on research in this previously unexplored niche.
major comments (3)
- [§5.2] §5.2 (Evaluation Protocol): The manuscript does not state whether the train/test split of the 50 MIAO classes holds out entire sound-event categories or permits label overlap. If the same classes appear in both sets, the observed improvement over the CLIP+CLAP zero-shot baseline can be explained by the projection heads simply memorizing class-specific visual-acoustic correspondences rather than learning a reusable mapping that would apply to novel onomatopoeic styles or sounds outside these 50 events.
- [§5.1] §5.1 and Table 1: No ablation studies are provided that isolate the contribution of the learned projection heads from other design choices (e.g., loss function, embedding dimensionality, or training schedule). Without these controls it is difficult to attribute the reported gains specifically to the proposed re-alignment step.
- [§5.3] §5.3: The paper contains no experiments on out-of-distribution onomatopoeic images or sounds drawn from classes outside the 50-event MIAO vocabulary. Such tests are necessary to substantiate the claim that the method learns a general cross-modal correspondence rather than fitting the training distribution.
minor comments (3)
- [Abstract] Abstract: The claim of 'substantial outperformance' is stated without any numerical metrics, making the abstract less informative than it could be.
- [Figure 1] Figure 1: The framework diagram would be clearer if the dimensions of the CLIP and CLAP embeddings and the projection-head outputs were labeled explicitly.
- [§3.1] §3.1: The notation for the two projection heads (W_v and W_a) is introduced without stating their input/output dimensionalities or whether they are linear or non-linear.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify important areas for clarification and strengthening of the claims. We respond point-by-point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§5.2] §5.2 (Evaluation Protocol): The manuscript does not state whether the train/test split of the 50 MIAO classes holds out entire sound-event categories or permits label overlap. If the same classes appear in both sets, the observed improvement over the CLIP+CLAP zero-shot baseline can be explained by the projection heads simply memorizing class-specific visual-acoustic correspondences rather than learning a reusable mapping that would apply to novel onomatopoeic styles or sounds outside these 50 events.
Authors: We agree that the evaluation protocol requires explicit description to rule out memorization. The current manuscript does not detail the split. In the revision we will add a precise statement in §5.2 that the 50 classes are partitioned in a class-disjoint manner (40 classes for training the projection heads, 10 classes held out entirely for testing). We will also report the exact numbers of pairs per split and include a short analysis showing that retrieval performance remains strong on the unseen classes, supporting that the learned mapping is reusable rather than class-specific. revision: yes
-
Referee: [§5.1] §5.1 and Table 1: No ablation studies are provided that isolate the contribution of the learned projection heads from other design choices (e.g., loss function, embedding dimensionality, or training schedule). Without these controls it is difficult to attribute the reported gains specifically to the proposed re-alignment step.
Authors: We acknowledge the absence of ablations. We will add a dedicated ablation subsection (or expanded Table 1) in the revised manuscript that systematically varies the projection-head architecture, loss function (contrastive vs. alternatives), embedding dimensionality, and training schedule while keeping all other factors fixed. These controls will allow readers to attribute performance differences directly to the re-alignment step. revision: yes
-
Referee: [§5.3] §5.3: The paper contains no experiments on out-of-distribution onomatopoeic images or sounds drawn from classes outside the 50-event MIAO vocabulary. Such tests are necessary to substantiate the claim that the method learns a general cross-modal correspondence rather than fitting the training distribution.
Authors: We concur that explicit OOD evaluation would strengthen the generalization claim. The present study is scoped to the newly introduced MIAO dataset. In the revision we will expand §5.3 with a limitations paragraph that discusses the 50-class scope and reports preliminary qualitative results on a small number of external onomatopoeic examples collected from public sources. We will also move a more comprehensive OOD benchmark to future work. revision: partial
Circularity Check
No circularity: standard supervised adaptation on new paired dataset
full rationale
The paper constructs the MIAO dataset of paired onomatopoeic images and sounds across 50 classes, then trains modality-specific projection heads to re-align pretrained CLIP and CLAP embeddings for bidirectional retrieval. The central claim is an empirical performance improvement over a zero-shot baseline. This is conventional supervised training and evaluation on held-out pairs from the same distribution; no equations, predictions, or results reduce to the inputs by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citation chains appear. The derivation remains self-contained and externally falsifiable via standard retrieval metrics on the new data.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of modality-specific projection heads
axioms (1)
- domain assumption Pretrained CLIP and CLAP embeddings contain transferable features relevant to onomatopoeic images and sounds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
train modality-specific projection heads that re-align the embeddings for visual onomatopoeia and corresponding sounds... Lalign = ∥z̃img − z̃aud∥₂² ... Lcls = CE(simg,y) + CE(saud,y)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MIAO dataset... 50 sound event classes... split by illustrator
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural languag e supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Aga rwal, G. Sastry, A. Askell, P . Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural languag e supervision,” Proc. International Conference on Machine Learning (ICML), pp. 8748– 8763, 2021
work page 2021
-
[2]
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining wit h feature fusion and keyword-to-caption augmentation,” Proc. IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, 2023
work page 2023
-
[3]
AudioCLIP: Ex tending clip to image, text and audio,
A. Guzhov, F. Raue, J. Hees, and A. Dengel, “AudioCLIP: Ex tending clip to image, text and audio,” Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 976–980, 2022
work page 2022
-
[4]
Wav2 CLIP: Learning robust audio representations from clip,
H.-H. Wu, P . Seetharaman, K. Kumar, and J. P . Bello, “Wav2 CLIP: Learning robust audio representations from clip,” Proc. IEEE Interna- tional Conference on Acoustics, Speech and Signal Processi ng (ICASSP), pp. 4563–4567, 2022
work page 2022
-
[5]
ImageBind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “ImageBind: One embedding space to bind them all,” Proc. IEEE/CVF Conference on Computer Vision and Pattern Recogni tion (CVPR), pp. 15 180–15 190, 2023
work page 2023
-
[6]
S. Ikawa and K. Kashino, “Acoustic event search with an on omatopoeic query: Measuring distance between onomatopoeic words and s ounds,” Proc. Detection and Classification of Acoustic Scenes and Ev ents W ork- shop, pp. 59–63, 2018
work page 2018
-
[7]
Onoma-to-wave: Environmental sound synthe sis from onomatopoeic words,
Y . Okamoto, K. Imoto, S. Takamichi, R. Y amanishi, T. Fuku mori, and Y . Y amashita, “Onoma-to-wave: Environmental sound synthe sis from onomatopoeic words,” APSIPA Transactions on Signal and Information Processing, vol. 11, no. 1, 2022
work page 2022
-
[8]
Visuali zing video sounds with sound word animation to enrich user experience,
F. Wang, H. Nagano, K. Kashino, and T. Igarashi, “Visuali zing video sounds with sound word animation to enrich user experience, ” IEEE Transactions on Multimedia , vol. 19, no. 2, pp. 418–429, 2017
work page 2017
-
[9]
H. Ohnaka, S. Takamichi, K. Imoto, Y . Okamoto, K. Fujii, a nd H. Saruwatari, “Visual onoma-to-wave: Environmental soun d synthesis from visual onomatopoeias and sound-source images,” Proc. IEEE International Conference on Acoustics, Speech and Signal P rocessing (ICASSP), pp. 1–5, 2023
work page 2023
-
[10]
FS D50K: An open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “FS D50K: An open dataset of human-labeled sound events,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 30, pp. 829–852, 2022
work page 2022
-
[11]
HTS-A T: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “HTS-A T: A hierarchical token-semantic audio transformer for sound classification and detection,” Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 646–650, 2022
work page 2022
-
[12]
Decoupled weight decay re gularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay re gularization,” Proc. International Conference on Learning Representatio ns (ICLR), pp. 1–8, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.