Adaptive Cost-Efficient Evaluation for Reliable Patent Claim Generation
Pith reviewed 2026-05-14 21:59 UTC · model grok-4.3
The pith
Hybrid system routes uncertain patent claims to LLMs via entropy, hitting 94.95% F1 at 78% lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
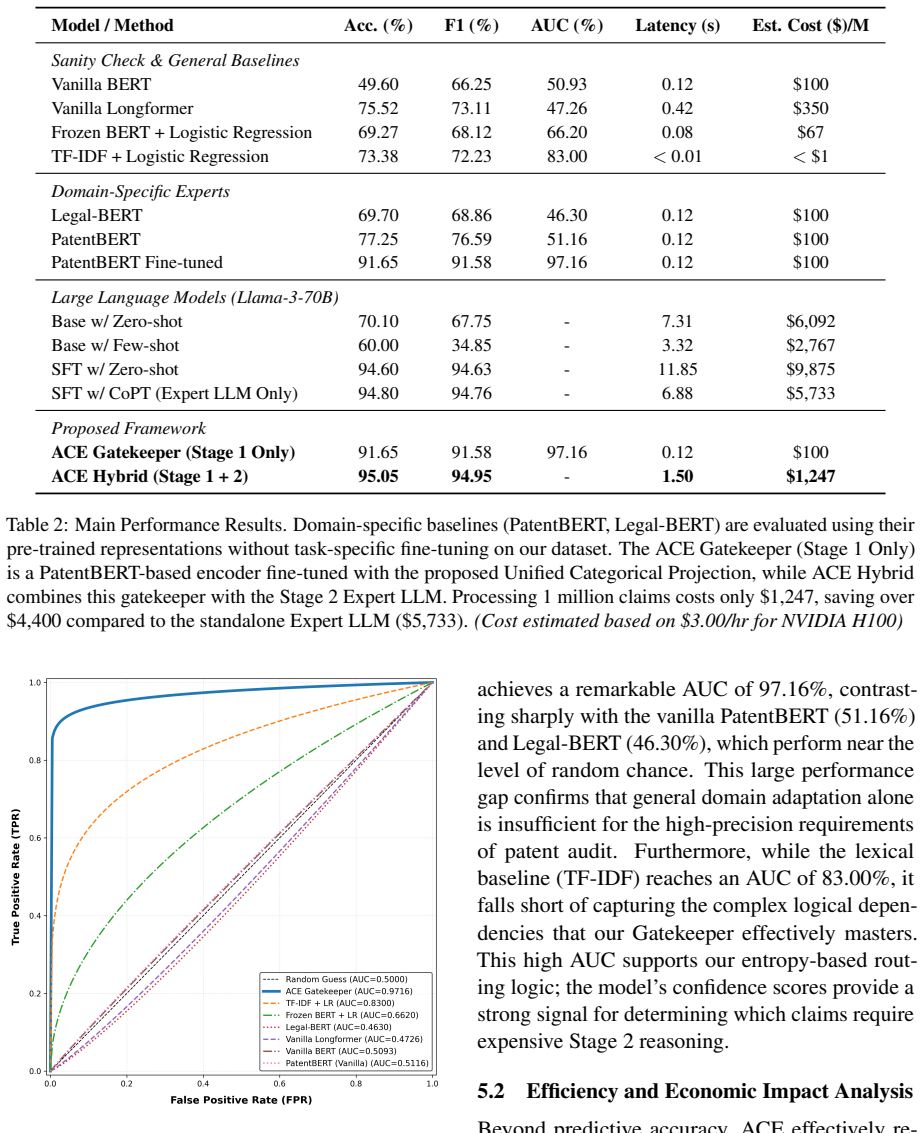
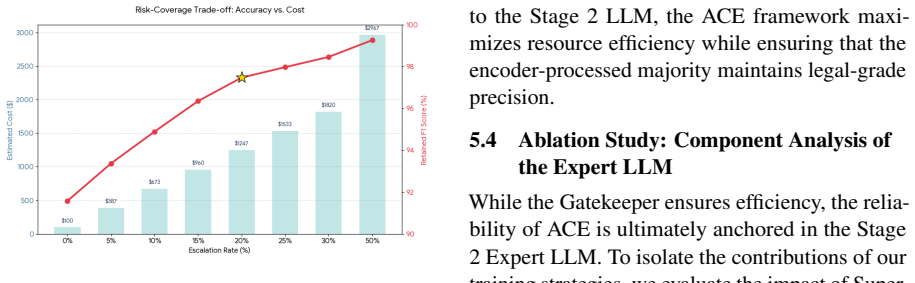
ACE combines a lightweight encoder with an expert LLM: predictive entropy flags claims that need deeper legal analysis, and the CoPT protocol guides the LLM through 35 U.S.C. statutory requirements to resolve long-range dependencies that encoder-only models miss. On the ACE-40k benchmark the method reaches 94.95% F1 while reducing operational costs by 78% versus standalone LLM use, and the routing threshold transfers unchanged to a corpus of 204 authentic USPTO §112(b) rejections.
What carries the argument
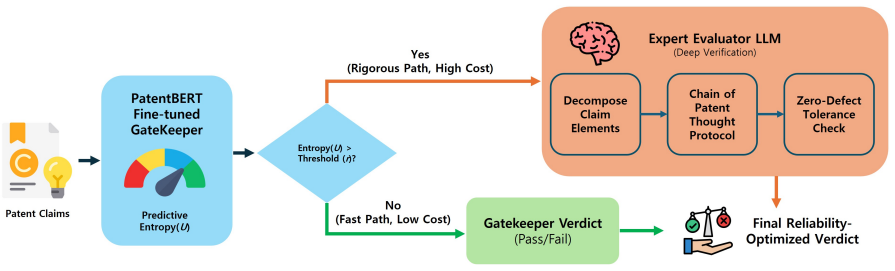
ACE framework that applies predictive entropy routing to decide when to invoke an LLM running the Chain of Patent Thought (CoPT) protocol grounded in statutory standards.
If this is right
- Large patent offices could review far more claims at current budgets without sacrificing accuracy.
- The released ACE-40k and ACE-Real112b datasets provide a standardized testbed for other hybrid legal-AI systems.
- Cost reductions make repeated or iterative claim checking feasible during patent prosecution.
- The CoPT protocol offers a template for applying LLMs to other statute-driven legal tasks without task-specific fine-tuning.
Where Pith is reading between the lines
- The same entropy-routing idea could apply to contract review or regulatory compliance where complexity varies across documents.
- If entropy correlates with human expert disagreement, the method might also surface claims likely to face litigation.
- Wider adoption would shift patent examination toward human review only on the highest-uncertainty subset, changing examiner workload patterns.
Load-bearing premise
Predictive entropy from the lightweight encoder reliably identifies claims that contain long-range legal dependencies the encoder cannot resolve.
What would settle it
A new set of real USPTO rejections where the entropy threshold either routes too many correct encoder predictions to the LLM or leaves many actual §112(b) errors with the encoder alone.
Figures

read the original abstract
Automated patent claim validation demands low error tolerance. However, existing approaches face a rigidity-resource dilemma: lightweight encoders cannot track long-range legal dependencies, while exhaustive LLM verification incurs 4-5X higher overhead at million-claim scale. A naive confidence-based cascade cannot resolve this because binary validity scores fail to distinguish structurally distinct error types which require different reasoning depths. We propose a two-stage framework: Adaptive Cost-efficient Evaluation (ACE), which exploits the categorical structure of patent errors for uncertainty-aware routing. In the first stage, a fine-tuned encoder projects claims into a K+1 distribution over legal error types, whose predictive entropy serves as the routing signal. Claims exceeding an entropy threshold are escalated to the second stage, where an expert LLM executes a schema-constrained Chain-of-Patent-Thought (CoPT) protocol to map claim elements against 35 U.S.C. standards whose schema constraint reduces per-claim latency by 42% while producing legally grounded verdicts. We further present a 40,000-claim dataset ACE-40k with MPEP-grounded annotations, where ACE surpasses competitive baselines including a supervised 70B-parameter LLM while reducing costs by 78%. On real USPTO rejection data, the routing mechanism transfers without re-calibration, reducing inference time by 60% while maintaining competitive recall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ACE, a hybrid framework for patent claim validation that employs predictive entropy from a lightweight encoder to route high-uncertainty claims to an LLM executing a Chain of Patent Thought (CoPT) protocol grounded in 35 U.S.C. standards. It reports an F1 of 94.95% on a constructed 40k-claim benchmark (ACE-40k), a 78% cost reduction versus standalone LLM evaluation, and direct transfer of the entropy routing threshold to a 204-example corpus of authentic USPTO §112(b) rejections (ACE-Real112b) without recalibration. The authors release both datasets to support reproducibility.
Significance. If the entropy-routing and CoPT components prove robust, the work offers a concrete path to high-accuracy, low-cost validation of legally critical documents. The release of ACE-40k with MPEP-grounded annotations and the real-world stress-test corpus ACE-Real112b are concrete strengths that facilitate follow-on research in computational law and cost-sensitive NLP.
major comments (3)
- [Abstract and ACE-Real112b evaluation section] Abstract and the ACE-Real112b transfer experiment: the claim that the entropy threshold 'transfers directly ... without re-calibration' is load-bearing for the headline robustness result, yet the manuscript provides no entropy histograms, mean/variance statistics, or distributional tests (e.g., Kolmogorov-Smirnov) comparing the synthetic benchmark to the 204 real rejections. With such a small real corpus, even a modest scale shift would require threshold adjustment and erode the reported F1 and cost figures.
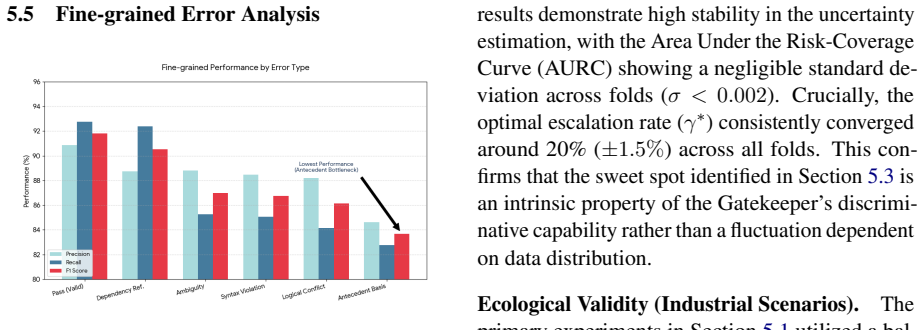
- [Experimental setup and results sections] Experimental setup and baseline descriptions: implementation details for the standalone LLM and encoder-only baselines (model versions, prompt templates, decoding parameters) are insufficient to reproduce the 94.95% F1 and 78% cost numbers. No statistical significance tests or error analysis on the F1 gains are reported, leaving the 'best F1' claim only moderately supported.
- [Method and routing-threshold subsection] Threshold selection procedure: the manuscript does not describe how the entropy routing threshold was chosen (validation-set tuning, sensitivity analysis, or fixed a priori), nor does it report performance variance across nearby threshold values. This detail is required to assess whether the 78% cost saving is stable or an artifact of a single operating point.
minor comments (2)
- [Method section] Notation: the definition of predictive entropy (encoder output) should be stated explicitly with the exact formula and temperature setting used, rather than left implicit.
- [Results figures] Figure clarity: cost-breakdown plots would benefit from confidence intervals or bootstrap error bars to convey variability across the 40k claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity and empirical support. We address each major comment below and will revise the manuscript to incorporate additional details and analyses where needed.
read point-by-point responses
-
Referee: [Abstract and ACE-Real112b evaluation section] Abstract and the ACE-Real112b transfer experiment: the claim that the entropy threshold 'transfers directly ... without re-calibration' is load-bearing for the headline robustness result, yet the manuscript provides no entropy histograms, mean/variance statistics, or distributional tests (e.g., Kolmogorov-Smirnov) comparing the synthetic benchmark to the 204 real rejections. With such a small real corpus, even a modest scale shift would require threshold adjustment and erode the reported F1 and cost figures.
Authors: We agree that distributional comparisons would provide stronger evidence for the direct transfer claim. In the revised manuscript, we will add entropy histograms for both ACE-40k and ACE-Real112b, report mean/variance statistics, and include a Kolmogorov-Smirnov test between the two distributions. These additions will empirically support the observed transferability of the threshold despite the modest size of the real corpus. revision: yes
-
Referee: [Experimental setup and results sections] Experimental setup and baseline descriptions: implementation details for the standalone LLM and encoder-only baselines (model versions, prompt templates, decoding parameters) are insufficient to reproduce the 94.95% F1 and 78% cost numbers. No statistical significance tests or error analysis on the F1 gains are reported, leaving the 'best F1' claim only moderately supported.
Authors: We acknowledge the need for greater reproducibility. The revised experimental setup section will specify exact model versions and checkpoints, include the full prompt templates used for the LLM and CoPT protocol, and detail all decoding parameters. We will also add McNemar's tests for statistical significance of F1 differences and a dedicated error analysis subsection examining cases where ACE improves over baselines. revision: yes
-
Referee: [Method and routing-threshold subsection] Threshold selection procedure: the manuscript does not describe how the entropy routing threshold was chosen (validation-set tuning, sensitivity analysis, or fixed a priori), nor does it report performance variance across nearby threshold values. This detail is required to assess whether the 78% cost saving is stable or an artifact of a single operating point.
Authors: The threshold was selected via grid search on the validation split of ACE-40k to jointly optimize F1 and cost reduction. In the revision, we will explicitly describe this procedure in the routing-threshold subsection and add a sensitivity analysis table/figure showing F1 and cost metrics across a range of nearby threshold values to demonstrate stability of the reported savings. revision: yes
Circularity Check
No significant circularity; derivation uses independent encoder and held-out evaluation
full rationale
The ACE routing relies on predictive entropy computed by a separate lightweight encoder model, with the threshold applied zero-shot to the distinct ACE-Real112b corpus of genuine USPTO rejections. All reported metrics (F1, cost savings) are measured on constructed held-out benchmarks (ACE-40k) whose annotations are MPEP-grounded and independent of the routing decision. No equations, fitted parameters, or self-citations are shown to reduce the claimed transfer or performance gains to the inputs by construction. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy routing threshold
axioms (1)
- domain assumption Lightweight encoders produce predictive entropy that correlates with actual legal reasoning difficulty
invented entities (1)
-
Chain of Patent Thought (CoPT)
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.