ELEMENT: Multi-Modal Retinal Vessel Segmentation Based on a Coupled Region Growing and Machine Learning Approach
Pith reviewed 2026-05-21 06:46 UTC · model grok-4.3
The pith
ELEMENT segments retinal vessels by coupling region growing with machine learning on grey-level and connectivity features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The ELEMENT method achieves superior vessel segmentation accuracy across multiple ocular imaging modalities by extracting complementary grey-level and connectivity features and propagating the connectivity information seamlessly through pixels during the machine-learning classification stage.
What carries the argument
Coupled region-growing and machine-learning classification that extracts and propagates vessel-connectivity features alongside grey-level evidence.
If this is right
- Faster and more consistent vessel maps become available for diagnosing diabetic retinopathy, glaucoma and macular degeneration.
- The same feature set and propagation step works without retraining across fundus, SLO and FA modalities.
- Reduced need for post-processing corrections compared with methods that produce fragmented vessel segments.
- Potential to lower the time cost of manual or interactive segmentation in clinical workflows.
Where Pith is reading between the lines
- The explicit connectivity propagation step may let the method maintain accuracy when training data are scarce, unlike purely data-driven networks.
- The framework could be inserted as a connectivity-regularization module inside existing deep networks to improve their boundary consistency.
- Clinical deployment would benefit from measuring wall-clock segmentation time on standard hospital hardware rather than only reporting accuracy.
Load-bearing premise
The proposed features capture complementary evidence based on grey level and vessel connectivity properties, and this connectivity information is seamlessly propagated through the pixels at the classification phase to reduce inconsistencies.
What would settle it
Re-evaluate the method on a new set of images containing heavy noise or vessel-disrupting pathologies where the connectivity-propagation step produces more labeling errors than a pure intensity or deep-learning baseline.
Figures

read the original abstract
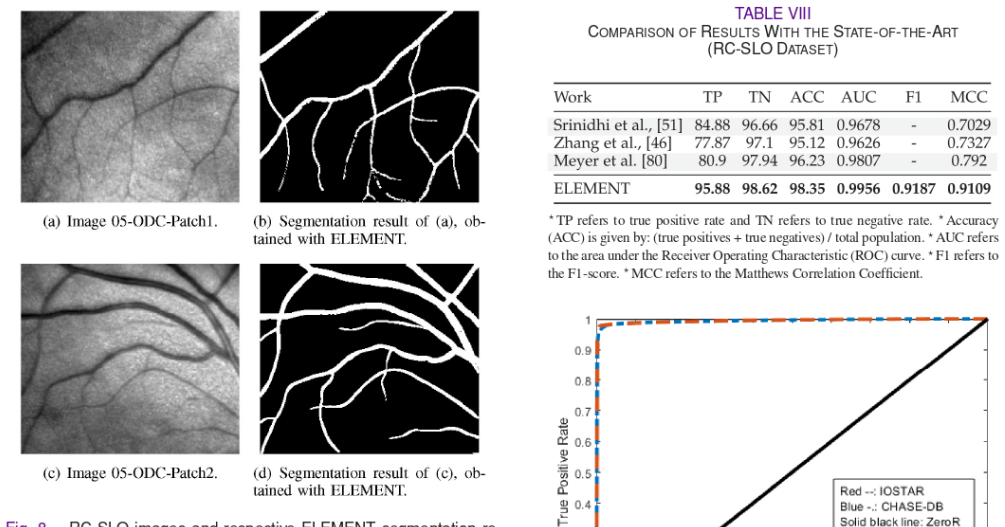
Vascular structures in the retina contain important information for the detection and analysis of ocular diseases, including age-related macular degeneration, diabetic retinopathy and glaucoma. Commonly used modalities in diagnosis of these diseases are fundus photography, scanning laser ophthalmoscope (SLO) and fluorescein angiography (FA). Typically, retinal vessel segmentation is carried out either manually or interactively, which makes it time consuming and prone to human errors. In this research, we propose a new multi-modal framework for vessel segmentation called ELEMENT (vEsseL sEgmentation using Machine lEarning and coNnecTivity). This framework consists of feature extraction and pixel-based classification using region growing and machine learning. The proposed features capture complementary evidence based on grey level and vessel connectivity properties. The latter information is seamlessly propagated through the pixels at the classification phase. ELEMENT reduces inconsistencies and speeds up the segmentation throughput. We analyze and compare the performance of the proposed approach against state-of-the-art vessel segmentation algorithms in three major groups of experiments, for each of the ocular modalities. Our method produced higher overall performance, with an overall accuracy of 97.40%, compared to 25 of the 26 state-of-the-art approaches, including six works based on deep learning, evaluated on the widely known DRIVE fundus image dataset. In the case of the STARE, CHASE-DB, VAMPIRE FA, IOSTAR SLO and RC-SLO datasets, the proposed framework outperformed all of the state-of-the-art methods with accuracies of 98.27%, 97.78%, 98.34%, 98.04% and 98.35%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ELEMENT, a multi-modal framework for retinal vessel segmentation that couples region growing with machine learning for pixel classification. Features are extracted from grey-level and vessel connectivity properties, with the latter propagated during classification to reduce inconsistencies. The work reports superior performance on six public datasets, claiming 97.40% accuracy on DRIVE (outperforming 25 of 26 SOTA methods including six deep-learning approaches) and accuracies of 98.27%, 97.78%, 98.34%, 98.04%, and 98.35% on STARE, CHASE-DB, VAMPIRE FA, IOSTAR SLO, and RC-SLO respectively.
Significance. If the reported accuracies are robustly validated, the hybrid non-deep-learning approach could be significant for retinal vessel segmentation in ocular disease analysis, offering a potentially more efficient and interpretable alternative to deep networks while leveraging multi-modal data and connectivity cues across fundus, SLO, and FA modalities.
major comments (3)
- [Methods] The methods description of the classification phase states that connectivity information 'is seamlessly propagated through the pixels' but provides no explicit mechanism, graph-based term, CRF integration, or pseudocode for this propagation; without an ablation isolating its effect, the performance gains cannot be confidently attributed to the claimed multi-modal complementarity rather than tuning.
- [Experiments] The experimental evaluation reports overall accuracies and outperformance claims but supplies no information on training-test splits, cross-validation strategy, hyper-parameter search, or statistical significance tests for the DRIVE results; this omission is load-bearing for the central claim of beating 25/26 prior methods including deep-learning baselines.
- [Results] Table or results section comparing to SOTA lacks a baseline ablation removing the connectivity feature or region-growing component, making it impossible to verify that the reported improvements stem from the proposed coupled approach rather than dataset-specific factors.
minor comments (2)
- [Methods] Clarify the exact machine-learning classifier used (e.g., random forest, SVM) and list all free hyperparameters with their search ranges.
- [Figures] Add zoomed insets or error maps in the qualitative figures to illustrate where inconsistencies are reduced by the connectivity propagation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on the ELEMENT framework. We address each major comment point by point below, outlining how we will strengthen the paper through revisions where appropriate.
read point-by-point responses
-
Referee: [Methods] The methods description of the classification phase states that connectivity information 'is seamlessly propagated through the pixels' but provides no explicit mechanism, graph-based term, CRF integration, or pseudocode for this propagation; without an ablation isolating its effect, the performance gains cannot be confidently attributed to the claimed multi-modal complementarity rather than tuning.
Authors: We agree that the current description of connectivity propagation during classification is insufficiently detailed. In the revised manuscript, we will expand the methods section to provide an explicit description of the propagation mechanism, including how vessel connectivity properties are updated and passed to neighboring pixels. We will also include pseudocode for the classification phase and add an ablation experiment that removes the connectivity propagation to isolate its contribution to the reported performance. revision: yes
-
Referee: [Experiments] The experimental evaluation reports overall accuracies and outperformance claims but supplies no information on training-test splits, cross-validation strategy, hyper-parameter search, or statistical significance tests for the DRIVE results; this omission is load-bearing for the central claim of beating 25/26 prior methods including deep-learning baselines.
Authors: We acknowledge that these experimental details are critical for reproducibility and for substantiating the outperformance claims. In the revision, we will add a dedicated experimental setup subsection specifying the standard training-test splits for each dataset (e.g., the 20/20 split for DRIVE), any cross-validation strategy used, the hyper-parameter search procedure, and statistical significance tests (such as McNemar's test) comparing ELEMENT against the baselines on DRIVE. revision: yes
-
Referee: [Results] Table or results section comparing to SOTA lacks a baseline ablation removing the connectivity feature or region-growing component, making it impossible to verify that the reported improvements stem from the proposed coupled approach rather than dataset-specific factors.
Authors: We concur that ablation studies are needed to attribute gains to the coupled region-growing and machine-learning components. We will incorporate new ablation experiments in the results section, reporting performance when the connectivity feature is removed and when the region-growing component is disabled, across the evaluated datasets, to demonstrate the contribution of the proposed coupling. revision: yes
Circularity Check
No circularity in empirical segmentation pipeline
full rationale
The paper presents an empirical multi-modal vessel segmentation framework (ELEMENT) that extracts grey-level and connectivity features, applies region growing, and performs pixel classification via machine learning, with performance measured by accuracy on public benchmarks (DRIVE, STARE, CHASE-DB, etc.). No mathematical derivations, predictions, or first-principles results are claimed that reduce to fitted parameters or self-referential inputs by construction. The central performance claims rest on direct comparison to external state-of-the-art methods rather than any internal reduction or self-citation chain, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- machine-learning classifier hyperparameters
axioms (1)
- domain assumption Grey-level and vessel-connectivity features provide complementary information that improves pixel classification when propagated together.
Reference graph
Works this paper leans on
-
[1]
L. Ortega-Arjona, “Parallel multiscale feature extraction and region growing: Application in retinal blood vessel detection,” IEEE Trans. Inf. Technol. Biomedicine, vol. 14, no. 2. pp. S00-506, Mar. 2010. C. Lorenz, C. Carlsen, T. M. Buzug, C. Fassnacht, and J. Weese, “A multi- scale line filter with automatic scale selection based on the hessian matrix f...
work page 2010
-
[2]
Theoretical foundations of anisotropic diffusion in image processing
Weickert, “Theoretical foundations of anisotropic diffusion in image processing.” Theor. Found. Comput. Vision, Comput. Suppl.. vol. 11, pp. 221-236, 1996. E. O. Rodrigues, “Combining minkowski and cheyshev: New distance pro- posal and survey of distance metrics using k-nearest neighbours classificr.” Pattem Recognit. Lett...vol. 110, no. 15, pp. 66-71, 2...
work page 1996
-
[3]
Retinal vessel segmentation using the 2-d gabor wavelet and supervised classification
1. V.B. Soares. ]. 1. G. Leandro, R. M. Cesar, H. F. Jelinek. and M. J. Cree, “Retinal vessel segmentation using the 2-d gabor wavelet and supervised classification.” IEEE Trans. Med. Imag., vol. 25, no. 9, pp. 1214-1222, Sep. 2006. D. Marin, A. Aquino, M. E. Gegundez-Arias, and J. M. Bravo, “A new supervised method for blood vessel segmentation in retina...
work page 2006
-
[4]
Locating blood vessels in retinal images by piccewise threshold probing of a matched filter response
[Online]. Available: hitps://www.sciencedirect.com/sciencefarticle/ abs/pii/S 1361841519300982 [61] [62] [63] [67] [68] [69] [70] 7 m) 1) [74] [75] [76] mm [78] 791 A.D. Hoover, V. Kouznetsova, and M. Goldbaum, “Locating blood vessels in retinal images by piccewise threshold probing of a matched filter response.” IEEE Trans. Med. Imag., vol. 19, 0. 3, pp....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.