A₃B₂: Adaptive Asymmetric Adapter for Alleviating Branch Bias in Vision-Language Image Classification with Few-Shot Learning
Pith reviewed 2026-05-20 22:03 UTC · model grok-4.3
The pith
Uncertainty-driven dampening of image-branch adaptation fixes branch bias and lifts few-shot out-of-distribution accuracy in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adapting the image encoder does not always improve performance under out-of-distribution settings in vision-language image classification. A3B2 addresses the resulting branch bias through Uncertainty-Aware Adapter Dampening that suppresses image-branch adaptation when uncertainty is high, paired with a lightweight asymmetric architecture inspired by mixture-of-experts and regularized by load balancing.
What carries the argument
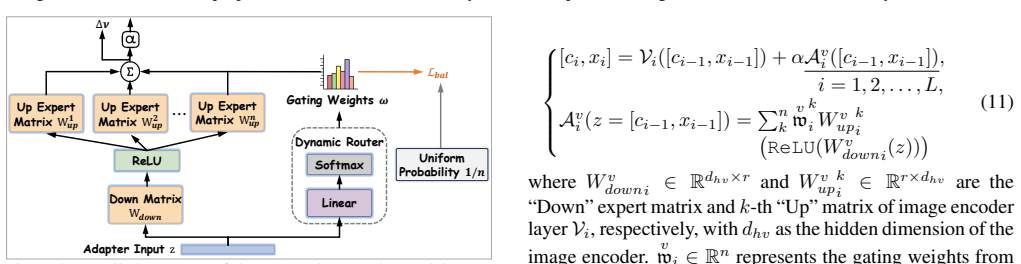
Uncertainty-Aware Adapter Dampening (UAAD), a mechanism that scales down image-branch adaptation strength in response to elevated prediction uncertainty.
If this is right
- A3B2 exceeds 11 prompt- and adapter-based baselines on three few-shot classification tasks spanning 11 datasets.
- The method supplies automatic, data-driven control of branch contributions without per-dataset hyperparameter search.
- Performance on in-distribution data is preserved while gains appear under distribution shift.
- The asymmetric design with load-balancing regularization keeps added parameters minimal.
Where Pith is reading between the lines
- Similar uncertainty-based gating may help other multimodal adapters that currently treat branches symmetrically.
- The approach points toward uncertainty estimation as a general tool for detecting harmful adaptation directions under shift.
- Testing the same dampening rule on larger-scale models or additional modalities would check whether the bias pattern persists.
Load-bearing premise
High prediction uncertainty reliably signals when to reduce image-branch adaptation without lowering accuracy on in-distribution data or requiring manual thresholds.
What would settle it
Replace the uncertainty signal in A3B2 with random or constant values and measure whether the performance advantage over symmetric adapters vanishes on the out-of-distribution test splits.
Figures










read the original abstract
Efficient transfer learning methods for large-scale vision-language models ($e.g.$, CLIP) enable strong few-shot transfer, yet existing adaptation methods follow a fixed fine-tuning paradigm that implicitly assumes a uniform importance of the image and text branches, which has not been systematically studied in image classification. Through extensive analysis, we reveal a Branch Bias issue in vision-language image classification: adapting the image encoder does not always improve performance under out-of-distribution settings. Motivated by this observation, we propose A$_3$B$_2$, an Adaptive Asymmetric Adapter that alleviates Branch Bias in few-shot learning. A$_3$B$_2$ introduces Uncertainty-Aware Adapter Dampening (UAAD), which automatically suppresses image-branch adaptation when prediction uncertainty is high, enabling soft and data-driven control without manual intervention. Architecturally, A$_3$B$_2$ adopts a lightweight asymmetric design inspired by mixture-of-experts with Load Balancing Regularization. Extensive experiments on three few-shot image classification tasks across 11 datasets demonstrate that A$_3$B$_2$ consistently outperforms 11 competitive prompt- and adapter-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a 'Branch Bias' phenomenon in vision-language models (e.g., CLIP) for few-shot image classification, where image-encoder adaptation does not uniformly improve performance under out-of-distribution conditions. It proposes A₃B₂, an Adaptive Asymmetric Adapter that incorporates Uncertainty-Aware Adapter Dampening (UAAD) to automatically suppress image-branch adaptation when prediction uncertainty is high, together with a lightweight asymmetric mixture-of-experts architecture and load-balancing regularization. Experiments across three few-shot tasks on 11 datasets report consistent gains over 11 prompt- and adapter-based baselines.
Significance. If the empirical claims are substantiated with proper controls and ablations, the work supplies a practical, data-driven mechanism for dynamic branch balancing in VLM adaptation that avoids manual tuning and may enhance OOD robustness in few-shot regimes. The explicit analysis of branch bias and the UAAD component represent potentially useful contributions to the adapter and prompt-tuning literature, provided the uncertainty signal proves reliable and the gains are not artifacts of other design choices.
major comments (3)
- [Branch Bias Analysis (Section 3)] The central motivation rests on the Branch Bias observation, yet the manuscript provides no explicit quantification (performance deltas, statistical tests, or controls for dataset shift magnitude) of when and why image-branch adaptation harms OOD accuracy. This detail is required to establish that UAAD's uncertainty trigger is a faithful proxy rather than an ad-hoc heuristic.
- [UAAD Definition (Section 4.2)] UAAD is described as using 'prediction uncertainty' to dampen image-branch adaptation, but neither the exact estimator (e.g., entropy, MC-dropout variance) nor its integration into the adapter update rule is given by equation. Without this, it is impossible to verify that the mechanism does not trigger false suppression on in-distribution data or interact adversely with the load-balancing term.
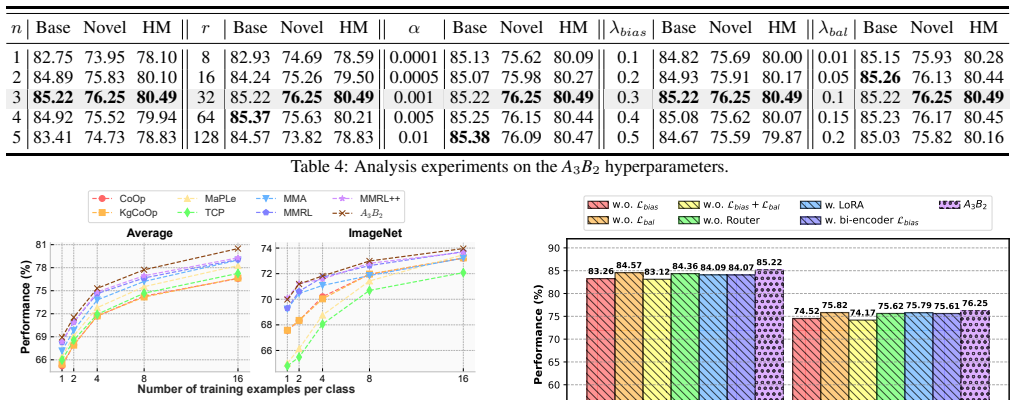
- [Experimental Evaluation (Section 5)] The headline result of consistent outperformance on 11 datasets is load-bearing, yet the text supplies no ablation that isolates UAAD from the asymmetric MoE architecture and load-balancing regularization. Table or figure reporting performance with UAAD disabled versus enabled is needed to attribute gains to the adaptive suppression rather than the overall design.
minor comments (2)
- [Title and Abstract] Clarify the precise meaning of the subscript notation A₃B₂ in the title and introduction for readers unfamiliar with the acronym expansion.
- [Tables in Section 5] Ensure all result tables include standard deviations or confidence intervals across random seeds to support claims of consistent superiority.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications, formalizations, and ablations.
read point-by-point responses
-
Referee: [Branch Bias Analysis (Section 3)] The central motivation rests on the Branch Bias observation, yet the manuscript provides no explicit quantification (performance deltas, statistical tests, or controls for dataset shift magnitude) of when and why image-branch adaptation harms OOD accuracy. This detail is required to establish that UAAD's uncertainty trigger is a faithful proxy rather than an ad-hoc heuristic.
Authors: We agree that explicit quantification would strengthen the motivation for UAAD. In the revised manuscript we will expand Section 3 with performance deltas (adapted vs. frozen image branch) under OOD conditions, include statistical significance tests across multiple random seeds, and add controls for shift magnitude via feature-space distances. These additions will clarify the regimes where image-branch adaptation is harmful and better justify the uncertainty-based trigger. revision: yes
-
Referee: [UAAD Definition (Section 4.2)] UAAD is described as using 'prediction uncertainty' to dampen image-branch adaptation, but neither the exact estimator (e.g., entropy, MC-dropout variance) nor its integration into the adapter update rule is given by equation. Without this, it is impossible to verify that the mechanism does not trigger false suppression on in-distribution data or interact adversely with the load-balancing term.
Authors: We thank the referee for highlighting the missing formalization. UAAD employs predictive entropy of the softmax output as the uncertainty measure; the dampening factor is a monotonic decreasing function of this entropy that multiplicatively scales the image-branch adapter gradients. In the revision we will add the precise equations in Section 4.2, describe the integration with the overall loss (including load-balancing), and include a short analysis confirming limited false suppression on in-distribution data. revision: yes
-
Referee: [Experimental Evaluation (Section 5)] The headline result of consistent outperformance on 11 datasets is load-bearing, yet the text supplies no ablation that isolates UAAD from the asymmetric MoE architecture and load-balancing regularization. Table or figure reporting performance with UAAD disabled versus enabled is needed to attribute gains to the adaptive suppression rather than the overall design.
Authors: We acknowledge that isolating UAAD's contribution is necessary. The revised manuscript will contain a new ablation table in Section 5 that compares the full A₃B₂ model against an otherwise identical variant with UAAD disabled (constant dampening factor of 1). Average accuracy and per-dataset results across the 11 datasets will be reported to quantify the incremental benefit of the adaptive component. revision: yes
Circularity Check
No circularity: empirical observation plus proposed adapter
full rationale
The paper reports an empirical analysis of branch bias in VL models and introduces A3B2 with UAAD as a practical mitigation. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear. The method is motivated by observed performance patterns across datasets and evaluated against baselines; the central claims rest on experimental results rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A3B2 introduces Uncertainty-Aware Adapter Dampening (UAAD), which automatically suppresses image-branch adaptation when prediction uncertainty is high
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
asymmetric design inspired by mixture-of-experts with Load Balancing Regularization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Alayracet al., 2022 ] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information pro- cessing systems, 35:23716–23736,
work page 2022
-
[2]
Food-101–mining discriminative com- ponents with random forests
[Bossardet al., 2014 ] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative com- ponents with random forests. InComputer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part VI 13, pages 446–461. Springer,
work page 2014
-
[3]
[Brownet al., 2020 ] Tom Brown, Benjamin Mann, Nick Ry- der, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing sys- tems, 33:1877–1901,
work page 2020
-
[4]
Markov chains.Springer- Verlag, New York,
[Chung, 1967] Kai Lai Chung. Markov chains.Springer- Verlag, New York,
work page 1967
-
[5]
Describing textures in the wild
[Cimpoiet al., 2014 ] Mircea Cimpoi, Subhransu Maji, Ia- sonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 3606–3613,
work page 2014
-
[6]
Imagenet: A large-scale hierarchical image database
[Denget al., 2009 ] Jia Deng, Wei Dong, Richard Socher, Li- Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee,
work page 2009
-
[7]
[Feduset al., 2022 ] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion param- eter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
work page 2022
-
[8]
[Fei-Feiet al., 2004 ] Li Fei-Fei, Rob Fergus, and Pietro Per- ona. Learning generative visual models from few train- ing examples: An incremental bayesian approach tested on 101 object categories. In2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE,
work page 2004
-
[9]
[Fuet al., 2025 ] Stephanie Fu, Tyler Bonnen, Devin Guil- lory, and Trevor Darrell. Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008,
-
[10]
Higher layers need more lora experts.arXiv preprint arXiv:2402.08562,
[Gaoet al., 2024a ] Chongyang Gao, Kezhen Chen, Jinmeng Rao, Baochen Sun, Ruibo Liu, Daiyi Peng, Yawen Zhang, Xiaoyuan Guo, Jie Yang, and VS Subrahmanian. Higher layers need more lora experts.arXiv preprint arXiv:2402.08562,
-
[11]
[Gonget al., 2025 ] Shizhan Gong, Yankai Jiang, Qi Dou, and Farzan Farnia. Kernel-based unsupervised embedding alignment for enhanced visual representation in vision- language models.arXiv preprint arXiv:2506.02557,
-
[12]
[Guo and Gu, 2025a] Yuncheng Guo and Xiaodong Gu. Mmrl: Multi-modal representation learning for vision- language models.arXiv preprint arXiv:2503.08497,
-
[13]
[Guo and Gu, 2025b] Yuncheng Guo and Xiaodong Gu. Mmrl++: Parameter-efficient and interaction-aware rep- resentation learning for vision-language models.arXiv preprint arXiv:2505.10088,
-
[14]
[Helberet al., 2019 ] Patrick Helber, Benjamin Bischke, An- dreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Top- ics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226,
work page 2019
-
[15]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
[Hendrycks and Gimpel, 2016] Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of- distribution examples in neural networks.arXiv preprint arXiv:1610.02136,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
[Jianget al., 2025 ] Zhonghua Jiang, Kunxi Li, Yiyun Zhou, Sihao Liu, Zhaode Wang, Shengyu Zhang, et al. Purekv: Plug-and-play kv cache optimization with spatial-temporal sparse attention for vision-language large models.arXiv preprint arXiv:2510.25600,
-
[17]
[Jianget al., 2026 ] Zhonghua Jiang, Kui Chen, Kunxi Li, Keting Yin, Yiyun Zhou, Zhaode Wang, Chengfei Lv, and Shengyu Zhang. Acckv: Towards efficient audio-video llms inference via adaptive-focusing and cross-calibration kv cache optimization. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 40, pages 5494– 5502,
work page 2026
-
[18]
Maple: Multi-modal prompt learning
[Khattaket al., 2023 ] Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fa- had Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122,
work page 2023
-
[19]
Shifts in selective visual attention: towards the un- derlying neural circuitry
[Koch and Ullman, 1987] Christof Koch and Shimon Ull- man. Shifts in selective visual attention: towards the un- derlying neural circuitry. InMatters of intelligence: Con- ceptual structures in cognitive neuroscience, pages 115–
work page 1987
-
[20]
3d object representations for fine- grained categorization
[Krauseet al., 2013 ] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE inter- national conference on computer vision workshops, pages 554–561,
work page 2013
-
[21]
Read-only prompt optimization for vision-language few- shot learning
[Leeet al., 2023 ] Dongjun Lee, Seokwon Song, Jihee Suh, Joonmyeong Choi, Sanghyeok Lee, and Hyunwoo J Kim. Read-only prompt optimization for vision-language few- shot learning. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 1401–1411,
work page 2023
-
[22]
Language-driven Semantic Segmentation
[Liet al., 2022 ] Boyi Li, Kilian Q Weinberger, Serge Be- longie, Vladlen Koltun, and Ren´e Ranftl. Language-driven semantic segmentation.arXiv preprint arXiv:2201.03546,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Scaling language-image pre-training via masking
[Liet al., 2023 ] Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, and Kaiming He. Scaling language-image pre-training via masking. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 23390–23400,
work page 2023
-
[24]
[Liet al., 2024 ] Ming Li, Jike Zhong, Chenxin Li, Li- uzhuozheng Li, Nie Lin, and Masashi Sugiyama. Vision- language model fine-tuning via simple parameter-efficient modification.arXiv preprint arXiv:2409.16718,
-
[25]
[Liet al., 2025a ] Kunxi Li, Yufan Xiong, Zhonghua Jiang, Yiyun Zhou, Zhaode Wang, Chengfei Lv, and Shengyu Zhang. Flowmm: Cross-modal information flow guided kv cache merging for efficient multimodal context infer- ence.arXiv preprint arXiv:2511.05534,
-
[26]
Open-vocabulary se- mantic segmentation with mask-adapted clip
[Lianget al., 2023 ] Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary se- mantic segmentation with mask-adapted clip. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7061–7070,
work page 2023
-
[27]
Fine-Grained Visual Classification of Aircraft
[Majiet al., 2013 ] Subhransu Maji, Esa Rahtu, Juho Kan- nala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
arXiv preprint arXiv:2503.07137 , year=
[Mu and Lin, 2025] Siyuan Mu and Sen Lin. A comprehen- sive survey of mixture-of-experts: Algorithms, theory, and applications.arXiv preprint arXiv:2503.07137,
-
[29]
Automated flower classification over a large number of classes
[Nilsback and Zisserman, 2008] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE,
work page 2008
-
[30]
[Parkhiet al., 2012 ] Omkar M Parkhi, Andrea Vedaldi, An- drew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recogni- tion, pages 3498–3505. IEEE,
work page 2012
-
[31]
Understanding fine-tuning clip for open- vocabulary semantic segmentation in hyperbolic space
[Penget al., 2025 ] Zelin Peng, Zhengqin Xu, Zhilin Zeng, Changsong Wen, Yu Huang, Menglin Yang, Feilong Tang, and Wei Shen. Understanding fine-tuning clip for open- vocabulary semantic segmentation in hyperbolic space. In Proceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 4562–4572,
work page 2025
-
[32]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
work page 2021
-
[33]
[Rechtet al., 2019 ] Benjamin Recht, Rebecca Roelofs, Lud- wig Schmidt, and Vaishaal Shankar. Do imagenet classi- fiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400. PMLR,
work page 2019
-
[34]
Inter-module credit assignment in modular reinforcement learning.Neural Networks, 16(7):985–994,
[Samejimaet al., 2003 ] Kazuyuki Samejima, Kenji Doya, and Mitsuo Kawato. Inter-module credit assignment in modular reinforcement learning.Neural Networks, 16(7):985–994,
work page 2003
-
[35]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
[Shazeeret al., 2017 ] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hin- ton, and Jeff Dean. Outrageously large neural net- works: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
[Soomroet al., 2012 ] Khurram Soomro, Amir Roshan Za- mir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[37]
[Tianet al., 2024 ] Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Cheng-Zhong Xu. Hydralora: An asymmet- ric lora architecture for efficient fine-tuning.Advances in Neural Information Processing Systems, 37:9565–9584,
work page 2024
-
[38]
Attention is all you need.Advances in neural information processing systems, 30,
[Vaswaniet al., 2017 ] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30,
work page 2017
-
[39]
[Wanget al., 2019 ] Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32,
work page 2019
-
[40]
Sun database: Large-scale scene recognition from abbey to zoo
[Xiaoet al., 2010 ] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE,
work page 2010
-
[41]
Side adapter network for open- vocabulary semantic segmentation
[Xuet al., 2023 ] Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xiang Bai. Side adapter network for open- vocabulary semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2945–2954,
work page 2023
-
[42]
[Xueet al., 2022 ] Fuzhao Xue, Ziji Shi, Futao Wei, Yuxuan Lou, Yong Liu, and Yang You. Go wider instead of deeper. InProceedings of the AAAI Conference on Artificial Intel- ligence, volume 36, pages 8779–8787,
work page 2022
-
[43]
Mma: Multi-modal adapter for vision-language models
[Yanget al., 2024 ] Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiaohua Xie. Mma: Multi-modal adapter for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23826–23837,
work page 2024
-
[44]
Language-image alignment with fixed text en- coders.arXiv preprint arXiv:2506.04209,
[Yanget al., 2025 ] Jingfeng Yang, Ziyang Wu, Yue Zhao, and Yi Ma. Language-image alignment with fixed text en- coders.arXiv preprint arXiv:2506.04209,
-
[45]
Visual-language prompt tuning with knowledge- guided context optimization
[Yaoet al., 2023 ] Hantao Yao, Rui Zhang, and Changsheng Xu. Visual-language prompt tuning with knowledge- guided context optimization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6757–6767,
work page 2023
-
[46]
Tcp: Textual-based class-aware prompt tuning for visual-language model
[Yaoet al., 2024 ] Hantao Yao, Rui Zhang, and Changsheng Xu. Tcp: Textual-based class-aware prompt tuning for visual-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23438–23448,
work page 2024
-
[47]
Will You Find These Shortcuts?
[Yeet al., 2024 ] Wenqian Ye, Guangtao Zheng, Xu Cao, Yunsheng Ma, and Aidong Zhang. Spurious correla- tions in machine learning: A survey.arXiv preprint arXiv:2402.12715,
-
[48]
[Zhanget al., 2024 ] Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence,
work page 2024
-
[49]
[Zhanget al., 2025 ] Dacao Zhang, Kun Zhang, Shimao Chu, Le Wu, Xin Li, and Si Wei. More: A mixture of low-rank experts for adaptive multi-task learning.arXiv preprint arXiv:2505.22694,
-
[50]
[Zhouet al., 2025a ] Baohang Zhou, Ying Zhang, Yu Zhao, Xuhui Sui, and Xiaojie Yuan. Multimodal graph-based variational mixture of experts network for zero-shot multi- modal information extraction. InProceedings of the ACM on Web Conference 2025, pages 4823–4831,
work page 2025
-
[51]
Disentangled knowledge tracing for alleviating cognitive bias
[Zhouet al., 2025c ] Yiyun Zhou, Zheqi Lv, Shengyu Zhang, and Jingyuan Chen. Disentangled knowledge tracing for alleviating cognitive bias. InProceedings of the ACM on Web Conference 2025, pages 2633–2645,
work page 2025
-
[52]
Cola: Collaborative low-rank adaptation
[Zhouet al., 2025d ] Yiyun Zhou, Chang Yao, and Jingyuan Chen. Cola: Collaborative low-rank adaptation. InFind- ings of the Association for Computational Linguistics: ACL 2025, pages 14115–14130,
work page 2025
-
[53]
[Zhouet al., 2026a ] Yiyun Zhou, Jingwei Shi, Mingjing Xu, Zhonghua Jiang, and Jingyuan Chen. Beyond student: An asymmetric network for neural network inheritance.arXiv preprint arXiv:2602.09509,
-
[54]
This strongly demonstrates the effectiveness of the proposed fixed asymmetric design
From these results, we observe thatA3 generally performs worse than A3 across different tasks. This strongly demonstrates the effectiveness of the proposed fixed asymmetric design. In the following, we analyze the underlying reasons behind this outcome. A.2 Theoretical Support We build upon the theoretical analysis developed in our previ- ous work [Zhouet...
work page 1987
-
[55]
Theoretical Analysis.The one-down-many-ups architec- ture imposes a single shared bottleneck: all information fromXtoYmust pass through the same low-dimensional Z. This meansZmust serve as the representation for the entire mixtureofHexperts. Consequently, to maximize the predictive informationI(Z;Y),Zis forced to encode only those features ofXthat are sal...
work page 2024
-
[56]
The second term penalizes large updates and is non-negative, hence: ∥∇V(x) ℓ′∥ ≤ ∥∇ V(x) ℓ∥
Then: ∇V(x) ℓ′ =∇ V(x) ℓ+ (1−κ(x))∇ V(x) ∥∆v(x)∥2. The second term penalizes large updates and is non-negative, hence: ∥∇V(x) ℓ′∥ ≤ ∥∇ V(x) ℓ∥. Taking expectation: Ceff V (T)≤C V (T). Method ImageNetCaltech101OxfordPetsStanfordCarsFlowers102Food101FGVCAircraftSUN397DTDEuroSATUCF101Average CoCoOp 70.62 94.52 90.47 65.91 71.92 86.02 23.34 66.54 45.51 44.43 ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.