Content-Style Identification via Differential Independence
Pith reviewed 2026-05-20 12:50 UTC · model grok-4.3
The pith
Content-style differential independence enables factor identification without statistical independence or sparse Jacobians
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce content-style differential independence (CSDI), an alternative structural condition requiring that infinitesimal variations in content and style induce orthogonal directions on the data manifold, thereby enabling identifiability even when content and style are dependent and the Jacobian is dense. We operationalize this condition through a blockwise orthogonality constraint on the Jacobian subspaces associated with content and style. To support high-dimensional generative models, we design a stochastic regularizer based on numerical Jacobian approximation, enabling scalable training in settings such as high-resolution image generation.
What carries the argument
Content-style differential independence (CSDI), defined as the requirement that infinitesimal variations in content and style induce orthogonal directions on the data manifold, which separates the corresponding Jacobian subspaces for identifiability.
Load-bearing premise
That the blockwise orthogonality constraint on Jacobian subspaces for content and style can be enforced reliably by a stochastic regularizer using numerical Jacobian approximations in high-dimensional generative models.
What would settle it
Training the model on synthetic data with known dependent content-style factors and a dense Jacobian, then checking if the extracted content and style remain mixed in downstream tasks, would test the claim; failure to separate them would falsify it.
Figures




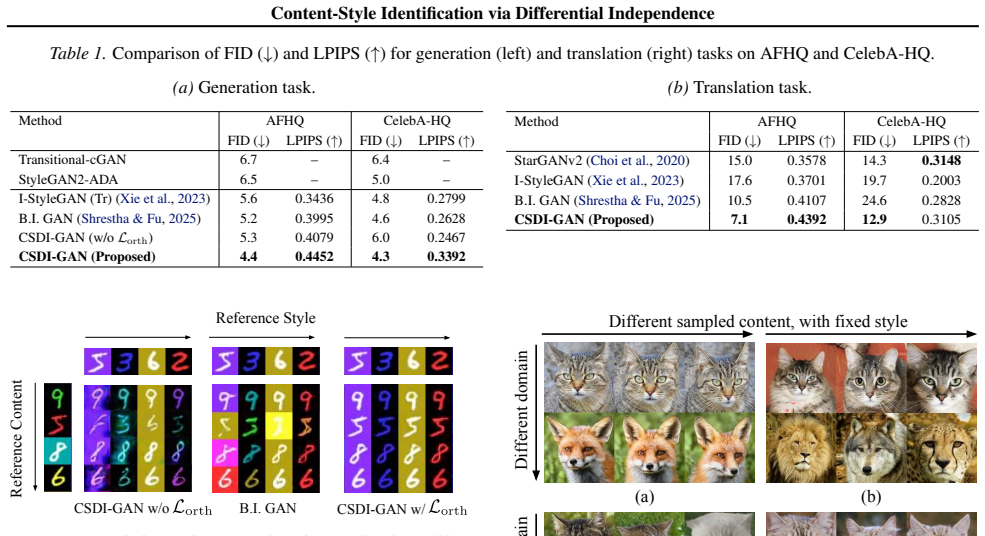


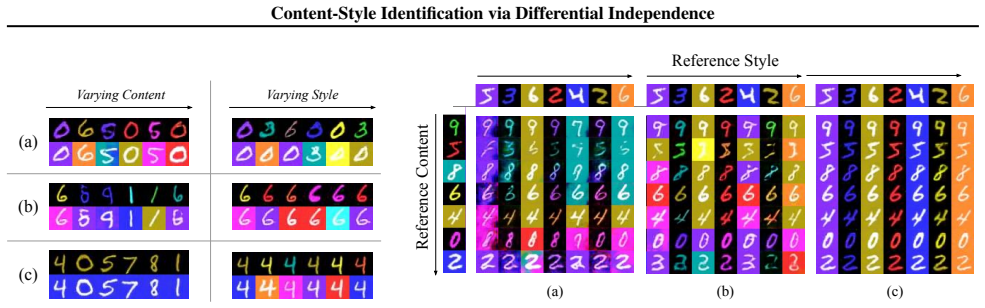


read the original abstract
Generative analysis often models multi-domain observations as nonlinear mixtures of domain-invariant content variables and domain-specific style variables. Identifying both factors from unpaired domains enables tasks such as domain transfer and counterfactual data generation. Prior work establishes identifiability under (block-wise) statistical independence between content and style, or via sparse Jacobian assumptions on the nonlinear mixing function, but such conditions can be restrictive in practice. In this work, we introduce content-style differential independence (CSDI), an alternative structural condition requiring that infinitesimal variations in content and style induce orthogonal directions on the data manifold, thereby enabling identifiability even when content and style are dependent and the Jacobian is dense. We operationalize this condition through a blockwise orthogonality constraint on the Jacobian subspaces associated with content and style. To support high-dimensional generative models, we design a stochastic regularizer based on numerical Jacobian approximation, enabling scalable training in settings such as high-resolution image generation. Experiments across multiple datasets corroborate the identifiability analysis and demonstrate practical benefits on counterfactual generation and domain translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces content-style differential independence (CSDI), a structural condition stating that infinitesimal variations in content and style induce orthogonal directions on the data manifold. This enables identifiability of the factors from unpaired multi-domain observations even when content and style are statistically dependent and the mixing Jacobian is dense. CSDI is operationalized as a blockwise orthogonality constraint on the Jacobian subspaces associated with content and style, enforced via a stochastic regularizer that relies on numerical Jacobian approximations to support scalable training in high-dimensional settings such as image generation. Experiments across multiple datasets are used to corroborate the identifiability analysis and show benefits for counterfactual generation and domain translation.
Significance. If the central claim holds, the work would offer a meaningful relaxation of the independence or sparsity assumptions common in identifiable generative modeling, potentially allowing disentanglement in more realistic scenarios where content and style are correlated. The differential-geometric framing of independence is conceptually novel and could influence future theoretical work on manifold-based identifiability. The scalable regularizer for high-dimensional data addresses a practical bottleneck, though its reliability remains the key open question for the result's impact.
major comments (2)
- [Abstract] Abstract and identifiability section: The identifiability result rests on CSDI being realized exactly through the blockwise orthogonality constraint. No derivation is supplied showing how the numerical Jacobian regularizer converges to this exact condition, nor are error bounds or bias/variance analyses provided for the finite-difference or Monte-Carlo approximations in high-dimensional regimes.
- [Experiments] Experiments section: No direct verification is reported that the learned content and style Jacobian subspaces remain orthogonal when content-style dependence is explicitly controlled (e.g., via synthetic data with known correlation levels). Without such a check, the weaker identifiability claim does not demonstrably follow from the training procedure.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly listed the concrete datasets and metrics used to corroborate identifiability.
- [Method] Notation for the Jacobian subspaces and the regularizer loss could be introduced earlier with an explicit equation reference to aid readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful review of our manuscript on Content-Style Differential Independence (CSDI). Their comments highlight important aspects of the theoretical and empirical validation that we will address in the revision. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract and identifiability section: The identifiability result rests on CSDI being realized exactly through the blockwise orthogonality constraint. No derivation is supplied showing how the numerical Jacobian regularizer converges to this exact condition, nor are error bounds or bias/variance analyses provided for the finite-difference or Monte-Carlo approximations in high-dimensional regimes.
Authors: We agree that a rigorous analysis of the numerical approximation is essential to substantiate the claim that the regularizer enforces CSDI. In the revised manuscript, we will add a dedicated subsection in the identifiability analysis that derives the convergence of the stochastic regularizer to the exact blockwise orthogonality condition. Specifically, we will show that as the perturbation size approaches zero and with sufficient Monte-Carlo samples, the expected value of the regularizer term approaches the desired orthogonality measure. Furthermore, we will include bias and variance bounds under the assumption that the generative function is Lipschitz continuous, which is a mild condition commonly used in related works on nonlinear ICA. This addition will clarify how the practical implementation realizes the theoretical condition. revision: yes
-
Referee: [Experiments] Experiments section: No direct verification is reported that the learned content and style Jacobian subspaces remain orthogonal when content-style dependence is explicitly controlled (e.g., via synthetic data with known correlation levels). Without such a check, the weaker identifiability claim does not demonstrably follow from the training procedure.
Authors: This is a valid point regarding the empirical validation of the training procedure. While our theoretical results establish identifiability under exact CSDI, and our experiments on real-world datasets show improved performance in domain translation and counterfactual generation, we acknowledge the value of controlled synthetic experiments. In the revision, we will include an additional experiment using synthetic data generated from a known nonlinear mixing function with tunable correlation between content and style variables. We will report the measured orthogonality (e.g., via the inner product of the Jacobian subspaces) as a function of the correlation level and training iterations, demonstrating that the regularizer successfully maintains near-orthogonality even under dependence. This will provide direct evidence that the procedure enforces the CSDI condition. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces CSDI as a new structural assumption (orthogonal infinitesimal variations on the manifold) and derives identifiability from it, then proposes a practical regularizer to approximate the associated Jacobian orthogonality constraint. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation, or prior ansatz by construction. The central claim remains an independent modeling choice rather than a tautology or statistical artifact of the training procedure itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 3.1 (Content-Style Differential Independence (CSDI)). The content-induced and style-induced tangent subspaces are orthogonal: R(J_c g(c,s^{(n)})) ⊥ R(J_{s^{(n)}} g(c,s^{(n)})).
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We operationalize this condition through a blockwise orthogonality constraint on the Jacobian subspaces... stochastic regularizer based on numerical Jacobian approximation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Counterfactual generation with identifiability guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
IEEE Transactions on Signal Processing , volume=
Revisiting deep generalized canonical correlation analysis , author=. IEEE Transactions on Signal Processing , volume=. 2023 , publisher=
work page 2023
-
[3]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Unpaired Multi-Domain Causal Representation Learning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[4]
Orthogonal jacobian regularization for unsupervised disentanglement in image generation , author=. Proc. IEEE/CVF international conference on computer vision , pages=
-
[5]
European conference on computer vision , pages=
The hessian penalty: A weak prior for unsupervised disentanglement , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[6]
Communications in Statistics-Simulation and Computation , volume=
A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines , author=. Communications in Statistics-Simulation and Computation , volume=. 1989 , publisher=
work page 1989
-
[7]
Advances in neural information processing systems , volume=
Independent mechanism analysis, a new concept? , author=. Advances in neural information processing systems , volume=
-
[8]
European Conference on Computer Vision , pages=
Multimodal unsupervised image-to-image translation , author=. European Conference on Computer Vision , pages=. 2018 , organization=
work page 2018
-
[9]
Lee, Hsin-Ying and Tseng, Hung-Yu and Mao, Qi and Huang, Jia-Bin and Lu, Yu-Ding and Singh, Maneesh and Yang, Ming-Hsuan , journal=. 2020 , publisher=
work page 2020
-
[10]
Choi, Yunjey and Uh, Youngjung and Yoo, Jaejun and Ha, Jung-Woo , booktitle=
-
[11]
Yang, Heran and Sun, Jian and Carass, Aaron and Zhao, Can and Lee, Junghoon and Prince, Jerry L and Xu, Zongben , journal=. Unsupervised. 2020 , publisher=
work page 2020
-
[12]
Wu, Wayne and Cao, Kaidi and Li, Cheng and Qian, Chen and Loy, Chen Change , booktitle=
-
[13]
Advances in Neural Information Processing Systems , volume=
Function classes for identifiable nonlinear independent component analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Kumar, Abhishek and Poole, Ben , booktitle=. On Implicit Regularization in. 2020 , organization=
work page 2020
-
[15]
Advances in Neural Information Processing Systems , volume=
Embrace the gap: VAEs perform independent mechanism analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Multi-domain image generation and translation with identifiability guarantees , author=. Proc. International Conference on Learning Representations , year=
-
[17]
Understanding latent correlation-based multiview learning and self-supervision: An identifiability perspective , author=. Proc. International Conference on Learning Representations , year=
- [18]
-
[19]
Toward causal representation learning , author=. Proc. IEEE , volume=. 2021 , publisher=
work page 2021
-
[20]
Distributionally Robust Neural Networks , author=. Proc. International Conference on Learning Representations , year=
-
[21]
International Conference on Machine Learning , pages=
Partial disentanglement for domain adaptation , author=. International Conference on Machine Learning , pages=
-
[22]
Advances in Neural Information Processing Systems , volume=
Identifiable shared component analysis of unpaired multimodal mixtures , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author =. Proc. International Conference on Machine Learning , pages =
-
[24]
Representation Learning: A Review and New Perspectives , year=
Bengio, Yoshua and Courville, Aaron and Vincent, Pascal , journal=. Representation Learning: A Review and New Perspectives , year=
-
[25]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Diverse Influence Component Analysis: A Geometric Approach to Nonlinear Mixture Identifiability , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
- [26]
-
[27]
Transactions on Machine Learning Research , issn=
Identifiable Deep Generative Models via Sparse Decoding , author=. Transactions on Machine Learning Research , issn=
-
[28]
Provably Learning Object-Centric Representations , author =. Proc. International Conference on Machine Learning , pages =. 2023 , volume =
work page 2023
-
[29]
Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding , author=. Proc. International Conference on Learning Representations , year=
-
[30]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Additive Decoders for Latent Variables Identification and Cartesian-Product Extrapolation , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[31]
Interaction Asymmetry: A General Principle for Learning Composable Abstractions , author=. Proc. International Conference on Learning Representations , year=
-
[32]
Identifiability Results for Multimodal Contrastive Learning , author=. Proc. International Conference on Learning Representations , year=
-
[33]
Content-Style Learning from Unaligned Domains: Identifiability under Unknown Latent Dimensions , author=. Proc. International Conference on Learning Representations , year=
-
[34]
On Disentangled Representations Learned from Correlated Data , author =. Proc. International Conference on Machine Learning , pages =. 2021 , volume =
work page 2021
-
[35]
Rolinek, Michal and Zietlow, Dominik and Martius, Georg , title =. Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition , month =
-
[36]
Auto-Encoding Variational Bayes , author=. Proc. International Conference on Learning Representations , year=
-
[37]
Karras, Tero and Laine, Samuli and Aittala, Miika and Hellsten, Janne and Lehtinen, Jaakko and Aila, Timo , title =. Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition , month =
-
[38]
Identifiable Object-Centric Representation Learning via Probabilistic Slot Attention , volume =
Kori, Avinash and Locatello, Francesco and Santhirasekaram, Ainkaran and Toni, Francesca and Glocker, Ben and De Sousa Ribeiro, Fabio , booktitle =. Identifiable Object-Centric Representation Learning via Probabilistic Slot Attention , volume =
-
[39]
IEEE Transactions on Wireless Communications , volume=
Cell-edge detection via selective cooperation and generalized canonical correlation , author=. IEEE Transactions on Wireless Communications , volume=. 2021 , publisher=
work page 2021
-
[40]
IEEE Transactions on Signal Processing , volume=
Generalized canonical correlation analysis: A subspace intersection approach , author=. IEEE Transactions on Signal Processing , volume=. 2021 , publisher=
work page 2021
-
[41]
IEEE Transactions on Signal Processing , volume=
Nonlinear multiview analysis: Identifiability and neural network-assisted implementation , author=. IEEE Transactions on Signal Processing , volume=. 2020 , publisher=
work page 2020
-
[42]
Advances in Neural Information Processing Systems , volume=
Self-supervised learning with data augmentations provably isolates content from style , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
work page 2023
-
[45]
Is Generator Conditioning Causally Related to
Odena, Augustus and Buckman, Jacob and Olsson, Catherine and Brown, Tom and Olah, Christopher and Raffel, Colin and Goodfellow, Ian , booktitle =. Is Generator Conditioning Causally Related to. 2018 , volume =
work page 2018
-
[46]
When Is Unsupervised Disentanglement Possible? , volume =
Horan, Daniella and Richardson, Eitan and Weiss, Yair , booktitle =. When Is Unsupervised Disentanglement Possible? , volume =
-
[47]
Goodfellow, Ian J. and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua , booktitle =. Generative Adversarial Nets , volume =
-
[48]
Transactions on Machine Learning Research , issn=
Latent Covariate Shift: Unlocking Partial Identifiability for Multi-Source Domain Adaptation , author=. Transactions on Machine Learning Research , issn=
-
[49]
Domain Intersection and Domain Difference , year=
Benaim, Sagie and Khaitov, Michael and Galanti, Tomer and Wolf, Lior , booktitle=. Domain Intersection and Domain Difference , year=
-
[50]
Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A. , booktitle=. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks , year=
-
[51]
Yang, Karren Dai and Belyaeva, Anastasiya and Venkatachalapathy, Saradha and Damodaran, Karthik and Katcoff, Abigail and Radhakrishnan, Adityanarayanan and Shivashankar, G. V. and Uhler, Caroline , year =. Multi-domain translation between single-cell imaging and sequencing data using autoencoders , volume =. Nature Communications , publisher =
-
[52]
Domain Adaptive Text Style Transfer
Li, Dianqi and Zhang, Yizhe and Gan, Zhe and Cheng, Yu and Brockett, Chris and Dolan, Bill and Sun, Ming-Ting. Domain Adaptive Text Style Transfer. Proc. Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019
work page 2019
-
[53]
Contrastive learning inverts the data generating process , author=. Proc. International Conference on Machine Learning , pages=
-
[54]
Multi-Domain Causal Representation Learning via Weak Distributional Invariances , author =. Proc. International Conference on Artificial Intelligence and Statistics , pages =. 2024 , volume =
work page 2024
-
[55]
Unsupervised Text Style Transfer using Language Models as Discriminators , volume =
Yang, Zichao and Hu, Zhiting and Dyer, Chris and Xing, Eric P and Berg-Kirkpatrick, Taylor , booktitle =. Unsupervised Text Style Transfer using Language Models as Discriminators , volume =
-
[56]
Disentangled Representation Learning for Non-Parallel Text Style Transfer
John, Vineet and Mou, Lili and Bahuleyan, Hareesh and Vechtomova, Olga. Disentangled Representation Learning for Non-Parallel Text Style Transfer. Proc. Annual Meeting of the Association for Computational Linguistics. 2019
work page 2019
-
[58]
Object-Centric Learning with Slot Attention , volume =
Locatello, Francesco and Weissenborn, Dirk and Unterthiner, Thomas and Mahendran, Aravindh and Heigold, Georg and Uszkoreit, Jakob and Dosovitskiy, Alexey and Kipf, Thomas , booktitle =. Object-Centric Learning with Slot Attention , volume =
-
[59]
Diederik P. Kingma and Jimmy Ba , title =. Proc. International Conference on Learning Representations , year =
-
[60]
Explicitly Minimizing the Blur Error of Variational Autoencoders , author=. Proc. International Conference on Learning Representations , year=
-
[61]
IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis , volume =
Huang, Huaibo and Li, Zhihang and He, Ran and Sun, Zhenan and Tan, Tieniu , booktitle =. IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis , volume =
-
[62]
Learning Shared Representations from Unpaired Data , author=. Proc. Annual Conference on Neural Information Processing Systems , year=
-
[63]
UniReps: 3rd Edition of the Workshop on Unifying Representations in Neural Models , year=
Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models , author=. UniReps: 3rd Edition of the Workshop on Unifying Representations in Neural Models , year=
-
[64]
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? , year=
Abdal, Rameen and Qin, Yipeng and Wonka, Peter , booktitle=. Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? , year=
-
[65]
Closed-Form Factorization of Latent Semantics in GANs , year=
Shen, Yujun and Zhou, Bolei , booktitle=. Closed-Form Factorization of Latent Semantics in GANs , year=
-
[66]
Local Disentanglement in Variational Auto-Encoders Using Jacobian L\_1 Regularization , volume =
Rhodes, Travers and Lee, Daniel , booktitle =. Local Disentanglement in Variational Auto-Encoders Using Jacobian L\_1 Regularization , volume =
-
[67]
Multi-Object Representation Learning with Iterative Variational Inference , author =. Proc. International Conference on Machine Learning , pages =. 2019 , volume =
work page 2019
-
[68]
Variational Autoencoders and Nonlinear ICA: A Unifying Framework , author =. Proc. International Conference on Artificial Intelligence and Statistics , pages =. 2020 , volume =
work page 2020
-
[69]
Nonlinear ICA Using Auxiliary Variables and Generalized Contrastive Learning , author =. Proc. International Conference on Artificial Intelligence and Statistics , pages =. 2019 , volume =
work page 2019
-
[70]
Tero Karras and Timo Aila and Samuli Laine and Jaakko Lehtinen , booktitle=. Progressive Growing of
-
[71]
Collapse by Conditioning: Training Class-conditional
Mohamad Shahbazi and Martin Danelljan and Danda Pani Paudel and Luc Van Gool , booktitle=. Collapse by Conditioning: Training Class-conditional
-
[72]
Training Generative Adversarial Networks with Limited Data , volume =
Karras, Tero and Aittala, Miika and Hellsten, Janne and Laine, Samuli and Lehtinen, Jaakko and Aila, Timo , booktitle =. Training Generative Adversarial Networks with Limited Data , volume =
-
[73]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , volume =
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , volume =
-
[74]
and Shechtman, Eli and Wang, Oliver , title =
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , title =. Proc. IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[75]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks , author=. Proc. International Conference on Learning Representations , year=
-
[76]
GAN Inversion: A Survey , year=
Xia, Weihao and Zhang, Yulun and Yang, Yujiu and Xue, Jing-Hao and Zhou, Bolei and Yang, Ming-Hsuan , journal=. GAN Inversion: A Survey , year=
-
[77]
CausalVAE: Disentangled Representation Learning via Neural Structural Causal Models , year=
Yang, Mengyue and Liu, Furui and Chen, Zhitang and Shen, Xinwei and Hao, Jianye and Wang, Jun , booktitle=. CausalVAE: Disentangled Representation Learning via Neural Structural Causal Models , year=
-
[78]
Very deep convolutional networks for large-scale image recognition , author=. Proc. International Conference on Learning Representations , year=
-
[79]
and Rouco, Jose and Novo, Jorge and Ortega, Marcos , booktitle=
Hervella, Alvaro S. and Rouco, Jose and Novo, Jorge and Ortega, Marcos , booktitle=. Deep Multimodal Reconstruction of Retinal Images Using Paired or Unpaired Data , year=
-
[80]
Mechanistic Independence: A Principle for Identifiable Disentangled Representations , author=. Proc. International Conference on Learning Representations , year=
-
[81]
Multi-domain causal representation learning via weak distributional invariances
Ahuja, K., Mansouri, A., and Wang, Y. Multi-domain causal representation learning via weak distributional invariances. In Proc. International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pp.\ 865--873. PMLR, 2024
work page 2024
-
[82]
Domain intersection and domain difference
Benaim, S., Khaitov, M., Galanti, T., and Wolf, L. Domain intersection and domain difference. In Proc. IEEE/CVF International Conference on Computer Vision, pp.\ 3444--3452, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.