LEGO: Leveraging Experience in Roadmap Generation for Sampling-Based Planning
Pith reviewed 2026-05-24 17:45 UTC · model grok-4.3
The pith
LEGO trains CVAEs on bottleneck samples from prior paths to generate sparse effective roadmaps for sampling-based motion planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
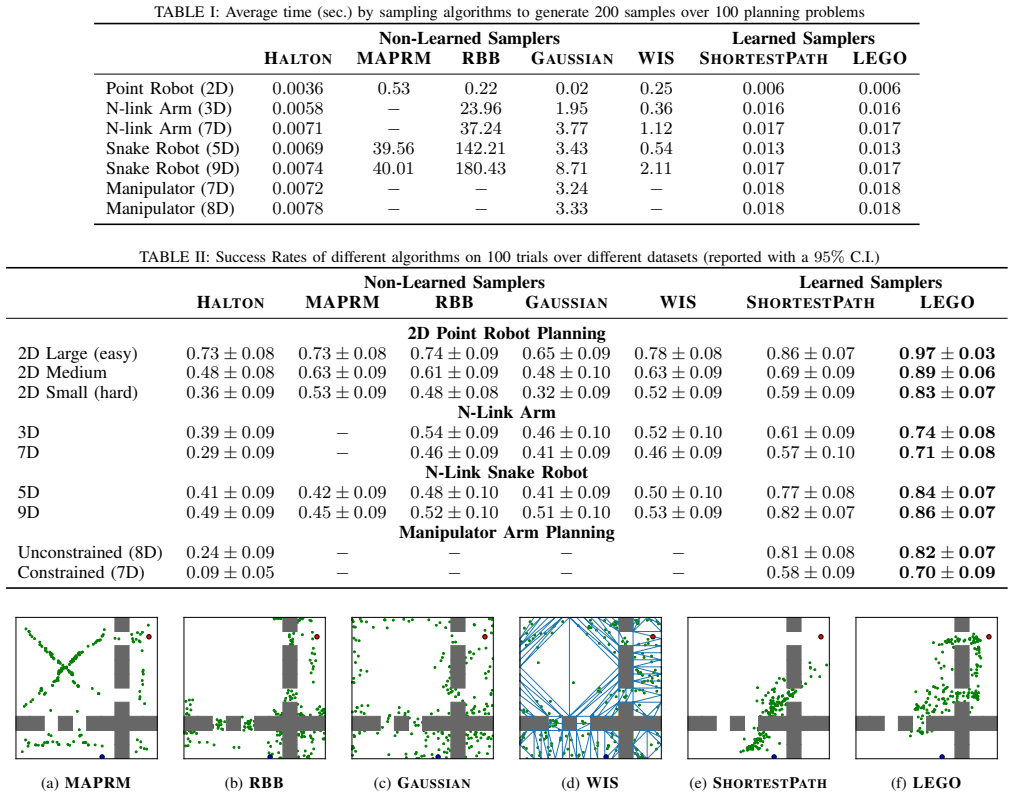
LEGO trains the CVAE with target samples drawn exclusively from bottleneck regions along near-optimal paths that are otherwise difficult to sample uniformly, while also ensuring the samples are distributed across diverse regions to maximize the chance a feasible path exists. These properties are formally defined, and performance guarantees are proved for the algorithm that uses them.
What carries the argument
Two explicit criteria for choosing CVAE target samples: membership in bottleneck regions of near-optimal paths, plus spread across diverse regions.
If this is right
- Roadmaps produced by LEGO are sparser yet more likely to contain low-cost feasible paths than those trained on complete shortest paths.
- Formal performance guarantees apply once the two selection criteria are satisfied.
- Significant improvements appear on robot-arm and other motion-planning benchmarks relative to both heuristics and prior learned methods.
- The approach mitigates failures that occur with complex obstacle layouts or train-test mismatch.
Where Pith is reading between the lines
- If bottleneck extraction from the prior data set is noisy, the training targets lose their intended advantage over uniform sampling.
- The reported gains may shrink when test environments introduce obstacle configurations far outside the training distribution.
- The same bottleneck-plus-diversity filter could be applied to improve other learned samplers beyond CVAEs.
Load-bearing premise
The prior dataset supplies shortest-path solutions from which bottleneck regions can be extracted reliably, and the learned distribution generalizes to test scenes whose obstacles may differ from training.
What would settle it
A held-out environment in which a LEGO-generated roadmap finds no feasible path within the allotted samples while a uniform sampler or a shortest-path-trained CVAE succeeds.
Figures














read the original abstract
We consider the problem of leveraging prior experience to generate roadmaps in sampling-based motion planning. A desirable roadmap is one that is sparse, allowing for fast search, with nodes spread out at key locations such that a low-cost feasible path exists. An increasingly popular approach is to learn a distribution of nodes that would produce such a roadmap. State-of-the-art is to train a conditional variational auto-encoder (CVAE) on the prior dataset with the shortest paths as target input. While this is quite effective on many problems, we show it can fail in the face of complex obstacle configurations or mismatch between training and testing. We present an algorithm LEGO that addresses these issues by training the CVAE with target samples that satisfy two important criteria. Firstly, these samples belong only to bottleneck regions along near-optimal paths that are otherwise difficult-to-sample with a uniform sampler. Secondly, these samples are spread out across diverse regions to maximize the likelihood of a feasible path existing. We formally define these properties and prove performance guarantees for LEGO. We extensively evaluate LEGO on a range of planning problems, including robot arm planning, and report significant gains over heuristics as well as learned baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEGO, an algorithm for leveraging prior experience to generate roadmaps in sampling-based motion planning. It trains a CVAE on target samples from bottleneck regions along near-optimal paths (hard for uniform sampling) that are also diverse, formally defines these properties, proves performance guarantees, and reports significant empirical gains over heuristics and learned baselines on problems including robot arm planning.
Significance. If the formal definitions, performance guarantees, and empirical gains hold under distribution shift, LEGO could provide a more reliable method than standard CVAE training for producing sparse, effective roadmaps from prior data, addressing documented failure modes in complex or mismatched environments.
major comments (1)
- [Abstract and performance guarantees] Abstract and performance guarantees section: the two criteria (bottleneck samples on near-optimal paths + diversity) are claimed to address mismatch between training and testing environments, but the guarantees appear conditioned only on the prior dataset providing reliable shortest-path solutions; no formal analysis or bounds are provided for generalization when obstacle configurations differ between train and test, which the abstract identifies as a failure mode for the baseline CVAE.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will make corresponding revisions to clarify the scope of our claims and guarantees.
read point-by-point responses
-
Referee: [Abstract and performance guarantees] Abstract and performance guarantees section: the two criteria (bottleneck samples on near-optimal paths + diversity) are claimed to address mismatch between training and testing environments, but the guarantees appear conditioned only on the prior dataset providing reliable shortest-path solutions; no formal analysis or bounds are provided for generalization when obstacle configurations differ between train and test, which the abstract identifies as a failure mode for the baseline CVAE.
Authors: We agree with the observation. The formal performance guarantees are conditioned on the prior dataset containing reliable near-optimal paths; they establish that the two criteria produce roadmaps with the desired sparsity and coverage properties under that assumption. The abstract's statement that the criteria address mismatch is supported by the empirical results (including on problems with complex obstacles and train-test differences), but we do not provide formal generalization bounds for arbitrary changes in obstacle configurations. We will revise the abstract to more precisely distinguish the theoretical guarantees from the empirical benefits under mismatch, and we will add a paragraph in the discussion section explicitly acknowledging this limitation of the analysis. revision: yes
Circularity Check
No circularity detected; derivation relies on external prior data and formal proofs
full rationale
The abstract and provided text describe training a CVAE on an external prior dataset of shortest paths, with target samples selected according to explicitly defined criteria (bottleneck regions and diversity). The paper claims to formally define these properties and prove performance guarantees, but no equations, self-citations, or reductions are visible that make any prediction equivalent to its inputs by construction. The central claims depend on the independent prior dataset and stated proofs rather than tautological fitting or self-referential definitions, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shortest paths in the prior dataset identify bottleneck regions that are difficult for uniform sampling.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formally define these properties and prove performance guarantees for LEGO.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
training the CVAE with target samples that satisfy two important criteria... bottleneck regions... diverse regions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L.E. Kavraki, P. Svestka, J.C. Latombe, and M.H. Overmars. Proba- bilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE TRO, 1996
work page 1996
-
[2]
S. M. LaValle. Planning Algorithms . Cambridge University Press, Cambridge, U.K., 2006. Available at http://planning.cs.uiuc.edu/
work page 2006
-
[3]
A formal basis for the heuristic determination of minimum cost paths
Peter E Hart, Nils J Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths. IEEE transactions on Systems Science and Cybernetics , 1968
work page 1968
-
[4]
J. H. Halton. On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numerische Mathematik, 2:84–90, 1960. 2004006008001000Number of Samples0.0 0.2 0.4 0.6 0.8 1.0Success RateHaltonShortestPathLEGO20040060080010001200Number of Samples0.0 0.2 0.4 0.6 0.8 1.0Success RateHaltonShortestPathLEGO20040060080010001...
work page 1960
-
[5]
Deterministic Sampling-Based Motion Planning: Optimality, Complexity, and Performance
Lucas Janson, Brian Ichter, and Marco Pavone. Deterministic sampling- based motion planning: Optimality, complexity, and performance. arXiv preprint arXiv:1505.00023, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
A framework for using the workspace medial axis in PRM planners
Christopher Holleman and Lydia E Kavraki. A framework for using the workspace medial axis in PRM planners. In ICRA, 2000
work page 2000
-
[7]
Hybrid prm sampling with a cost-sensitive adaptive strategy
D Hsu, G Sánchez-Ante, and Z Sun. Hybrid prm sampling with a cost-sensitive adaptive strategy. In ICRA, 2005
work page 2005
-
[8]
Sampling-based motion planning using predictive models
Brendan Burns and Oliver Brock. Sampling-based motion planning using predictive models. In ICRA, 2005
work page 2005
-
[9]
On the probabilistic foundations of probabilistic roadmap planning
D Hsu, J Latombe, and H Kurniawati. On the probabilistic foundations of probabilistic roadmap planning. IJRR, 2006
work page 2006
-
[10]
Workspace-based connectivity oracle: An adaptive sampling strategy for prm planning
H Kurniawati and D Hsu. Workspace-based connectivity oracle: An adaptive sampling strategy for prm planning. In Algorithmic Foundation of Robotics VII , pages 35–51. Springer, 2008
work page 2008
-
[11]
Learning sampling distributions for robot motion planning
Brian Ichter, James Harrison, and Marco Pavone. Learning sampling distributions for robot motion planning. In ICRA, 2018
work page 2018
-
[12]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 , 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [13]
-
[14]
MAPRM: A probabilistic roadmap planner with sampling on the medial axis of the free space
Steven A Wilmarth, Nancy M Amato, and Peter F Stiller. MAPRM: A probabilistic roadmap planner with sampling on the medial axis of the free space. In ICRA, 1999
work page 1999
-
[15]
The bridge test for sampling narrow passages with probabilistic roadmap planners
D Hsu, T Jiang, J Reif, and Z Sun. The bridge test for sampling narrow passages with probabilistic roadmap planners. In ICRA, 2003
work page 2003
-
[16]
Workspace importance sampling for probabilistic roadmap planning
H Kurniawati and D Hsu. Workspace importance sampling for probabilistic roadmap planning. In IROS
-
[17]
Adapting the sampling distribution in prm planners based on an approximated medial axis
Yuandong Yang and Oliver Brock. Adapting the sampling distribution in prm planners based on an approximated medial axis. In ICRA, 2004
work page 2004
-
[18]
Using workspace information as a guide to non-uniform sampling in probabilistic roadmap planners
Jur P Van den Berg and Mark H Overmars. Using workspace information as a guide to non-uniform sampling in probabilistic roadmap planners. IJRR, 2005
work page 2005
-
[19]
OBPRM: An obstacle-based PRM for 3D workspaces
Nancy M Amato, O Burchan Bayazit, and Lucia K Dale. OBPRM: An obstacle-based PRM for 3D workspaces. 1998
work page 1998
-
[20]
The gaussian sampling strategy for probabilistic roadmap planners
Valérie Boor, Mark H Overmars, and A Frank Van Der Stappen. The gaussian sampling strategy for probabilistic roadmap planners. In ICRA, pages 1018–1023, 1999
work page 1999
-
[21]
A machine learning approach for feature-sensitive motion planning
M Morales, L Tapia, R Pearce, S Rodriguez, and N M Amato. A machine learning approach for feature-sensitive motion planning. In Algorithmic Foundations of Robotics VI, pages 361–376. Springer, 2005
work page 2005
-
[22]
Resampl: A region-sensitive adaptive motion planner
S Rodriguez, S Thomas, R Pearce, and N M Amato. Resampl: A region-sensitive adaptive motion planner. In Algorithmic Foundation of Robotics VII, pages 285–300. Springer, 2008
work page 2008
-
[23]
Linear dimensionality reduction in random motion planning
Sébastien Dalibard and Jean-Paul Laumond. Linear dimensionality reduction in random motion planning. IJRR, 2011
work page 2011
-
[24]
Faster sample-based motion planning using instance-based learning
Jia Pan, Sachin Chitta, and Dinesh Manocha. Faster sample-based motion planning using instance-based learning. In WAFR, 2012
work page 2012
-
[25]
Pareto-optimal search over configuration space beliefs for anytime motion planning
Shushman Choudhury, Christopher M Dellin, and Siddhartha S Srini- vasa. Pareto-optimal search over configuration space beliefs for anytime motion planning. In IROS, 2016
work page 2016
-
[26]
An obstacle-based rapidly-exploring random tree
Xinyu Tang, Jyh-Ming Lien, and Nancy Amato. An obstacle-based rapidly-exploring random tree. In ICRA, 2006
work page 2006
-
[27]
Toward optimal configuration space sampling
Brendan Burns and Oliver Brock. Toward optimal configuration space sampling. In RSS, 2005
work page 2005
-
[28]
Randomized statistical path planning
Rosen Diankov and James Kuffner. Randomized statistical path planning. In IROS, 2007
work page 2007
-
[29]
Adaptive workspace biasing for sampling-based planners
Matt Zucker, James Kuffner, and J Andrew Bagnell. Adaptive workspace biasing for sampling-based planners. In ICRA, 2008
work page 2008
-
[30]
Deep sequential models for sampling-based planning
Yen-Ling Kuo, Andrei Barbu, and Boris Katz. Deep sequential models for sampling-based planning. arXiv preprint arXiv:1810.00804 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Learning dimensional descent for optimal motion planning in high-dimensional spaces
Paul Vernaza and Daniel D Lee. Learning dimensional descent for optimal motion planning in high-dimensional spaces. In AAAI, 2011
work page 2011
-
[32]
Tutorial on variational autoencoders,
Carl Doersch. Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908, 2016
-
[33]
Dynamic movement primitives in latent space of time-dependent variational autoencoders
N Chen, M Karl, and P van der Smagt. Dynamic movement primitives in latent space of time-dependent variational autoencoders. In Humanoids, 2016
work page 2016
-
[34]
Jung-Su Ha, Hyeok-Joo Chae, and Han-Lim Choi. Approximate inference-based motion planning by learning and exploiting low- dimensional latent variable models. IEEE RAL, 2018
work page 2018
-
[35]
Robot Motion Planning in Learned Latent Spaces
Brian Ichter and Marco Pavone. Robot motion planning in learned latent spaces. arXiv preprint arXiv:1807.10366 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Learning Implicit Sampling Distributions for Motion Planning
C Zhang, J Huh, and D D Lee. Learning implicit sampling distributions for motion planning. arXiv preprint arXiv:1806.01968 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Deeply informed neural sampling for robot motion planning
A H Qureshi and M C Yip. Deeply informed neural sampling for robot motion planning. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 6582–6588. IEEE, 2018
work page 2018
-
[38]
Learning structured output representation using deep conditional generative models
K Sohn, H Lee, and X Yan. Learning structured output representation using deep conditional generative models. In NIPS, 2015
work page 2015
-
[39]
A threshold of ln n for approximating set cover
Uriel Feige. A threshold of ln n for approximating set cover. Journal of the ACM (JACM) , 1998
work page 1998
-
[40]
S. Srinivasa, D. Berenson, M. Cakmak, A. C. Romea, M. Dogar, A. Dragan, R. Knepper, T. Niemueller, K. Strabala, J. M. Vandeweghe, and J. Ziegler. Herb 2.0: Lessons learned from developing a mobile manipulator for the home. Proceedings of the IEEE , 100(8):1–19, July 2012
work page 2012
-
[41]
TensorFlow: Large-scale machine learning on heterogeneous systems
Martín Abadi et al. TensorFlow: Large-scale machine learning on heterogeneous systems. URL https://www.tensorflow.org/
-
[42]
R Vernwal, A Mandalika, S Choudhury, and S Srinivasa. Supplementary Material. 2018. URL http://adityavk.com/LEGO_Supplementary.pdf
work page 2018
-
[43]
Domain randomization for transferring deep neural networks from simulation to the real world
J Tobin, R Fong, A Ray, J Schneider, W Zaremba, and P Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In IROS, 2017
work page 2017
-
[44]
Informed RRT*: Optimal incremental path planning focused through an admissible ellipsoidal heuristic
J D Gammell, S S Srinivasa, and T D Barfoot. Informed RRT*: Optimal incremental path planning focused through an admissible ellipsoidal heuristic. In IROS, 2014
work page 2014
-
[45]
Generating long-term trajectories using deep hierarchical networks
Stephan Zheng, Yisong Yue, and Jennifer Hobbs. Generating long-term trajectories using deep hierarchical networks. In NIPS, 2016
work page 2016
-
[46]
Tackling Over-pruning in Variational Autoencoders
Serena Yeung, Anitha Kannan, Yann Dauphin, and Li Fei-Fei. Tackling over-pruning in variational autoencoders. arXiv preprint arXiv:1706.03643, 2017. APPENDIX A CVAE F RAMEWORK We refer the reader to [ 32] for technical details and a comprehensive tutorial on CV AE. In SectionA-A we describe the CV AE architecture implemented to train LEGO and SHORTEST PAT...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.