Linear Recurrent Unit with Semantic Modulation for Image Super-Resolution
Pith reviewed 2026-06-26 18:04 UTC · model grok-4.3
The pith
A semantic modulating unit adapts linear recurrent units to 2D image data for efficient single-image super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The linear recurrent unit equipped with a semantic modulating unit that carries out LRU modulation, spatial categorization, and feature enhancement through a learned prototype produces a restoration network that surpasses recent state-of-the-art methods in single-image super-resolution while keeping computational complexity on par with existing approaches.
What carries the argument
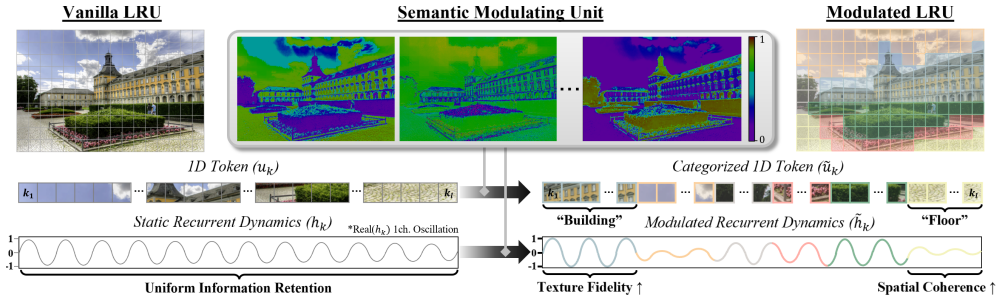
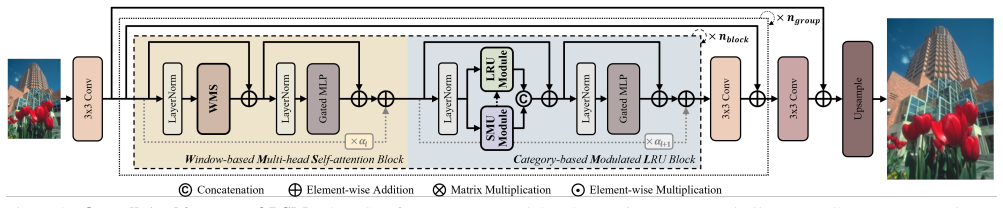
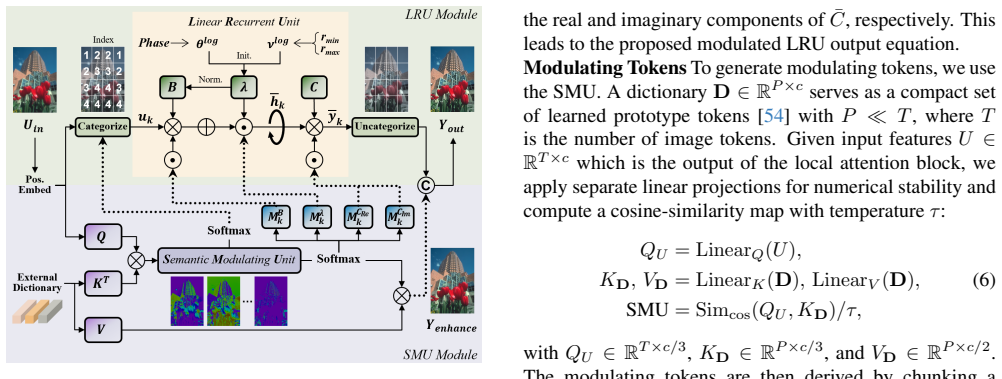
The semantic modulating unit (SMU), which adapts the static 1D LRU to 2D images by modulating recurrence parameters, categorizing spatial regions, and enhancing features with learned prototypes.
If this is right
- The network delivers higher super-resolution quality than prior methods at equivalent computational cost.
- The same LRU-plus-SMU structure can be applied to other image restoration problems that benefit from long-range dependencies.
- Spatial categorization inside the unit enables more targeted feature processing than a plain recurrent scan.
- Prototype-based enhancement provides a learned way to boost features without adding heavy parametric layers.
Where Pith is reading between the lines
- The three-role design of the modulating unit could be tested on video super-resolution or other sequential 2D tasks.
- If the prototype mechanism generalizes, it might reduce the need for deeper convolutional stacks in efficiency-critical pipelines.
- The approach suggests that principled linear recurrence can serve as a drop-in replacement for attention or convolution blocks once properly modulated for 2D structure.
Load-bearing premise
The semantic modulating unit can adapt the 1D-oriented LRU to 2D image data through its three roles without introducing instability or excessive overhead.
What would settle it
Running the network on standard benchmarks such as DIV2K, Set5, or Urban100 and finding that its PSNR or SSIM falls below recent state-of-the-art methods or that its FLOPs rise substantially above comparable models.
Figures



read the original abstract
Linear recurrent unit (LRU), designed with a principled formulation for stable linear recurrence, has demonstrated promising accuracy and robustness on long-range dependency tasks. However, its static parameterization and single-scan method limits its applicability to 2D vision tasks. In this study, we propose a LRU-based restoration network with a semantic modulating unit (SMU) to achieve a harmonious balance between performance and efficiency in single-image super-resolution. The SMU plays three key roles: LRU modulation, spatial categorization, and feature enhancement through learned prototype. Extensive experiments demonstrate that our method quantitatively and qualitatively surpasses recent state-of-the-art methods. Notably, our approach achieves superior performance with computational complexity on par with existing methods. The source code and models are available at https://github.com/MingyuChoi-run/LSM
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a restoration network for single-image super-resolution that replaces standard convolutions with a Linear Recurrent Unit (LRU) augmented by a Semantic Modulating Unit (SMU). The SMU is stated to fulfill three roles—LRU modulation, spatial categorization, and feature enhancement via learned prototypes—thereby adapting the 1D-oriented LRU to 2D image data while preserving linear recurrence stability. The central empirical claim is that the resulting model quantitatively and qualitatively exceeds recent state-of-the-art SISR methods at comparable computational cost; source code is released.
Significance. If the adaptation and performance claims hold after proper validation, the work would supply a concrete, efficiency-oriented extension of stable linear recurrence to dense prediction tasks, potentially useful for other 2D vision problems where long-range dependencies matter. The public release of code is a clear reproducibility asset.
major comments (3)
- [§3 (Method)] §3 (Method) and Eq. (3)–(7): the three roles of the SMU are described at a high level but lack the explicit update equations, modulation matrices, or prototype-learning loss that would allow verification that the adaptation preserves LRU stability and does not introduce hidden quadratic terms or instability.
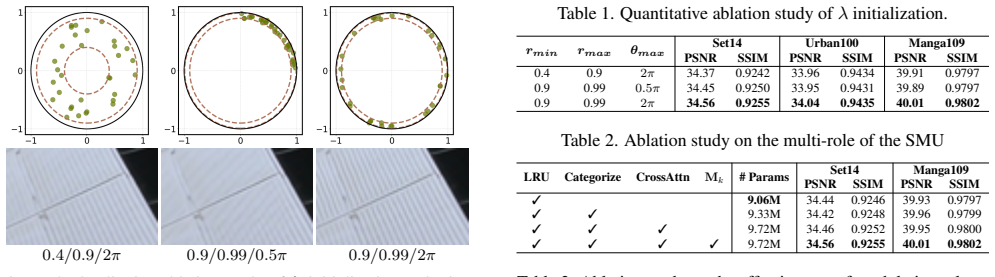
- [Table 2 and §4.3] Table 2 and §4.3 (Ablation): no component-wise ablation isolating the contribution of each SMU role (modulation vs. categorization vs. prototype enhancement) is reported; without these numbers the claim that SMU “successfully adapts” the LRU cannot be assessed and the complexity-parity statement remains unanchored.
- [§4.2] §4.2 (Complexity analysis): the reported FLOPs and parameter counts are asserted to be “on par,” yet the paper supplies neither the exact input-resolution scaling formula nor a breakdown showing how the learned-prototype term scales with spatial size; this directly affects the central efficiency claim.
minor comments (2)
- The abstract and introduction repeatedly use “extensive experiments” without naming the benchmark datasets or the precise metrics (PSNR/SSIM on which sets) until later sections; a one-sentence summary in the abstract would improve readability.
- Notation for the prototype vectors and the spatial categorization mask is introduced without a consolidated table of symbols; readers must hunt across subsections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [§3 (Method)] §3 (Method) and Eq. (3)–(7): the three roles of the SMU are described at a high level but lack the explicit update equations, modulation matrices, or prototype-learning loss that would allow verification that the adaptation preserves LRU stability and does not introduce hidden quadratic terms or instability.
Authors: We agree that the current description of the SMU is high-level. In the revised manuscript we will augment §3 with the explicit update equations, modulation matrices, and prototype-learning loss for each of the three roles, making the preservation of linear recurrence and absence of quadratic terms directly verifiable from the text. revision: yes
-
Referee: [Table 2 and §4.3] Table 2 and §4.3 (Ablation): no component-wise ablation isolating the contribution of each SMU role (modulation vs. categorization vs. prototype enhancement) is reported; without these numbers the claim that SMU “successfully adapts” the LRU cannot be assessed and the complexity-parity statement remains unanchored.
Authors: We concur that component-wise ablations would strengthen the empirical support. We will add the requested ablations to §4.3 (and update Table 2 accordingly) that isolate the contribution of LRU modulation, spatial categorization, and prototype enhancement. revision: yes
-
Referee: [§4.2] §4.2 (Complexity analysis): the reported FLOPs and parameter counts are asserted to be “on par,” yet the paper supplies neither the exact input-resolution scaling formula nor a breakdown showing how the learned-prototype term scales with spatial size; this directly affects the central efficiency claim.
Authors: We will revise §4.2 to include the precise input-resolution scaling formulas together with an explicit breakdown of the learned-prototype term’s dependence on spatial dimensions, thereby anchoring the complexity-parity claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and supplied text present an architectural proposal (LRU extended to 2D SISR via SMU with three explicit roles) whose central claim rests on experimental validation rather than any derivation, equation, or fitting procedure. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems, or ansatzes are described. The result is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unitary evolution recurrent neural networks
Martin Arjovsky, Amar Shah, and Yoshua Bengio. Unitary evolution recurrent neural networks. InInternational confer- ence on machine learning, pages 1120–1128. PMLR, 2016. 2
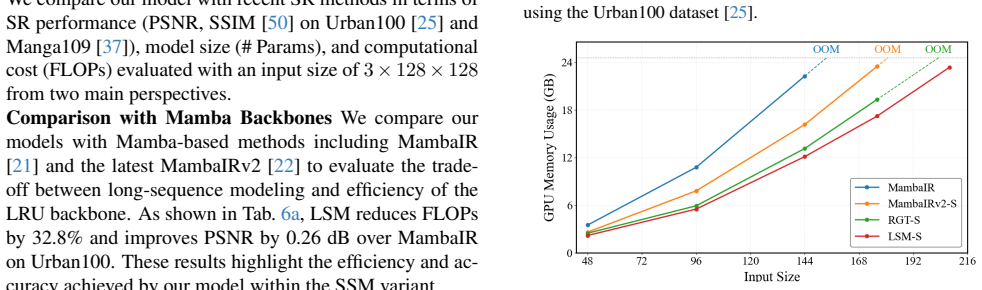
2016
-
[2]
Layer normalization.arXiv preprint arXiv:1607.06450,
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
-
[3]
Learn- ing long-term dependencies with gradient descent is difficult
Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learn- ing long-term dependencies with gradient descent is difficult. IEEE transactions on neural networks, 5(2):157–166, 1994. 1, 2
1994
-
[4]
Low-complexity single-image super-resolution based on nonnegative neighbor embedding
Marco Bevilacqua, Aline Roumy, Christine Guillemot, and Marie Line Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embedding
-
[5]
Quasi-recurrent neural networks.arXiv preprint arXiv:1611.01576, 2016
James Bradbury, Stephen Merity, Caiming Xiong, and Richard Socher. Quasi-recurrent neural networks.arXiv preprint arXiv:1611.01576, 2016. 2
Pith/arXiv arXiv 2016
-
[6]
Pre-trained image processing transformer
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12299–12310, 2021. 2
2021
-
[7]
Activating more pixels in image super- resolution transformer
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. Activating more pixels in image super- resolution transformer. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22367–22377, 2023. 1, 6, 7, 12
2023
-
[8]
Cross aggregation transformer for image restora- tion.Advances in Neural Information Processing Systems, 35:25478–25490, 2022
Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, Xin Yuan, et al. Cross aggregation transformer for image restora- tion.Advances in Neural Information Processing Systems, 35:25478–25490, 2022. 1, 2, 5, 6, 7, 8
2022
-
[9]
Dual aggregation transformer for image super-resolution
Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, Xi- aokang Yang, and Fisher Yu. Dual aggregation transformer for image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 6, 7
2023
-
[10]
Recursive generalization transformer for im- age super-resolution
Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, and Xi- aokang Yang. Recursive generalization transformer for im- age super-resolution. InICLR, 2024. 1, 2, 5, 6, 7, 8
2024
-
[11]
Kyunghyun Cho, Bart Van Merri ¨enboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches.arXiv preprint arXiv:1409.1259, 2014. 2
Pith/arXiv arXiv 2014
-
[12]
Second-order attention network for single im- age super-resolution
Tao Dai, Jianrui Cai, Yongbing Zhang, Shu-Tao Xia, and Lei Zhang. Second-order attention network for single im- age super-resolution. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 11065–11074, 2019. 2
2019
-
[13]
Soham De, Samuel L Smith, Anushan Fernando, Alek- sandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srini- vasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024. 2, 3, 4
Pith/arXiv arXiv 2024
-
[14]
Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015. 2
2015
-
[15]
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 2
Pith/arXiv arXiv 2010
-
[16]
Finding structure in time.Cognitive sci- ence, 14(2):179–211, 1990
Jeffrey L Elman. Finding structure in time.Cognitive sci- ence, 14(2):179–211, 1990. 2, 4, 13
1990
-
[17]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 1, 2
2024
-
[18]
Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing sys- tems, 33:1474–1487, 2020
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christo- pher R´e. Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing sys- tems, 33:1474–1487, 2020. 1
2020
-
[19]
Albert Gu, Karan Goel, and Christopher R ´e. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021. 1, 2
Pith/arXiv arXiv 2021
-
[20]
On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher R ´e. On the parameterization and initialization of diagonal state space models.Advances in Neural Information Processing Systems, 35:35971–35983, 2022. 1, 2
2022
-
[21]
Mambair: A simple baseline for im- age restoration with state-space model
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for im- age restoration with state-space model. InEuropean confer- ence on computer vision, pages 222–241. Springer, 2024. 1, 2, 6, 7, 8
2024
-
[22]
Mambairv2: Atten- tive state space restoration
Hang Guo, Yong Guo, Yaohua Zha, Yulun Zhang, Wenbo Li, Tao Dai, Shu-Tao Xia, and Yawei Li. Mambairv2: Atten- tive state space restoration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28124– 28133, 2025. 1, 2, 6, 7, 8, 12
2025
-
[23]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997. 2
1997
-
[24]
Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982. 2
1982
-
[25]
Single image super-resolution from transformed self-exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5197–5206, 2015. 5, 7, 8
2015
-
[26]
Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016. 4
Pith/arXiv arXiv 2016
-
[27]
Accurate image super-resolution using very deep convolutional net- works
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1646–1654, 2016. 2
2016
-
[28]
Classsr: A general framework to accelerate super- resolution networks by data characteristic
Xiangtao Kong, Hengyuan Zhao, Yu Qiao, and Chao Dong. Classsr: A general framework to accelerate super- resolution networks by data characteristic. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12016–12025, 2021. 12
2021
-
[29]
Local texture estima- tor for implicit representation function
Jaewon Lee and Kyong Hwan Jin. Local texture estima- tor for implicit representation function. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1929–1938, 2022. 2
1929
-
[30]
Effi- cient and explicit modelling of image hierarchies for image restoration
Yawei Li, Yuchen Fan, Xiaoyu Xiang, Denis Demandolx, Rakesh Ranjan, Radu Timofte, and Luc Van Gool. Effi- cient and explicit modelling of image hierarchies for image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18278– 18289, 2023. 2
2023
-
[31]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[32]
1, 2, 5, 6, 7, 8, 12
-
[33]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 136–144, 2017. 2, 5, 6, 7, 12
2017
-
[34]
Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024. 1, 2
2024
-
[35]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 2
2021
-
[36]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 12
Pith/arXiv arXiv 2017
-
[37]
A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics
David Martin, Charless Fowlkes, Doron Tal, and Jitendra Malik. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. InProceedings eighth IEEE international conference on computer vision. ICCV 2001, pages 416–423. IEEE, 2001. 7
2001
-
[38]
Sketch-based manga retrieval using manga109 dataset.Mul- timedia tools and applications, 76(20):21811–21838, 2017
Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Yamasaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset.Mul- timedia tools and applications, 76(20):21811–21838, 2017. 5, 7, 8
2017
-
[39]
Image super- resolution with non-local sparse attention
Yiqun Mei, Yuchen Fan, and Yuqian Zhou. Image super- resolution with non-local sparse attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3517–3526, 2021. 2
2021
-
[40]
Single image super-resolution via a holistic attention network
Ben Niu, Weilei Wen, Wenqi Ren, Xiangde Zhang, Lianping Yang, Shuzhen Wang, Kaihao Zhang, Xiaochun Cao, and Haifeng Shen. Single image super-resolution via a holistic attention network. InEuropean conference on computer vi- sion, pages 191–207. Springer, 2020. 2
2020
-
[41]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fer- nando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. InInternational Conference on Machine Learning, pages 26670–26698. PMLR, 2023. 1, 2, 3, 4, 12
2023
-
[42]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInter- national conference on machine learning, pages 1310–1318. Pmlr, 2013. 1, 2
2013
-
[43]
Promptir: Prompting for all-in- one image restoration.Advances in Neural Information Pro- cessing Systems, 36:71275–71293, 2023
Vaishnav Potlapalli, Syed Waqas Zamir, Salman H Khan, and Fahad Shahbaz Khan. Promptir: Prompting for all-in- one image restoration.Advances in Neural Information Pro- cessing Systems, 36:71275–71293, 2023. 2
2023
-
[44]
Learning internal representations by error prop- agation
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning internal representations by error prop- agation. Technical report, 1985. 2
1985
-
[45]
Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network
Wenzhe Shi, Jose Caballero, Ferenc Husz ´ar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1874–1883, 2016. 5
2016
-
[46]
Simplified state space layers for sequence modeling
Jimmy TH Smith, Andrew Warrington, and Scott W Linder- man. Simplified state space layers for sequence modeling. arXiv preprint arXiv:2208.04933, 2022. 2
Pith/arXiv arXiv 2022
-
[47]
Long range arena: A benchmark for efficient transformers.arXiv preprint arXiv:2011.04006,
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers.arXiv preprint arXiv:2011.04006,
arXiv 2011
-
[48]
Ntire 2017 challenge on single image super-resolution: Methods and results
Radu Timofte, Eirikur Agustsson, Luc Van Gool, Ming- Hsuan Yang, and Lei Zhang. Ntire 2017 challenge on single image super-resolution: Methods and results. InProceed- ings of the IEEE conference on computer vision and pattern recognition workshops, pages 114–125, 2017. 5, 12
2017
-
[49]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 5
2017
-
[50]
Omni aggregation networks for lightweight im- age super-resolution
Hang Wang, Xuanhong Chen, Bingbing Ni, Yutian Liu, and Jinfan Liu. Omni aggregation networks for lightweight im- age super-resolution. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22378–22387, 2023. 2, 6, 7, 12
2023
-
[51]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 7, 8
2004
-
[52]
Image super-resolution via sparse representation.IEEE transactions on image processing, 19(11):2861–2873, 2010
Jianchao Yang, John Wright, Thomas S Huang, and Yi Ma. Image super-resolution via sparse representation.IEEE transactions on image processing, 19(11):2861–2873, 2010. 3
2010
-
[53]
On sin- gle image scale-up using sparse-representations
Roman Zeyde, Michael Elad, and Matan Protter. On sin- gle image scale-up using sparse-representations. InInterna- tional conference on curves and surfaces, pages 711–730. Springer, 2010. 5, 7
2010
-
[54]
Accurate image restoration with attention retractable transformer
Jiale Zhang, Yulun Zhang, Jinjin Gu, Yongbing Zhang, Linghe Kong, and Xin Yuan. Accurate image restoration with attention retractable transformer. InICLR, 2023. 2, 6, 7
2023
-
[55]
Transcending the limit of local window: Ad- vanced super-resolution transformer with adaptive token dic- tionary
Leheng Zhang, Yawei Li, Xingyu Zhou, Xiaorui Zhao, and Shuhang Gu. Transcending the limit of local window: Ad- vanced super-resolution transformer with adaptive token dic- tionary. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2856–2865,
-
[56]
Efficient long-range attention network for image super- resolution
Xindong Zhang, Hui Zeng, Shi Guo, and Lei Zhang. Efficient long-range attention network for image super- resolution. InEuropean conference on computer vision, pages 649–667. Springer, 2022. 2, 6, 7, 12
2022
-
[57]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InProceedings of the European conference on computer vision (ECCV), pages 286–301, 2018. 2, 7
2018
-
[58]
Residual dense network for image super-resolution
Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018. 2
2018
-
[59]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InInternational Conference on Machine Learning,
-
[60]
Training Settings Classic SRFollowing previous works [31, 32], we use DIV2K [47] and Flickr2K [32] as the training datasets
1, 2 Linear Recurrent Unit with Semantic Modulation for Image Super-Resolution Supplementary Material A. Training Settings Classic SRFollowing previous works [31, 32], we use DIV2K [47] and Flickr2K [32] as the training datasets. We train with batch size 32. Patches are augmented by random flips and90 ◦,180 ◦,270 ◦ rotations. Training proceeds in two step...
-
[61]
dataset is used for training unlike the classic SR. To match the batch size with previous works [22, 49, 55], we doubled it compared to the classic SR setting, while keeping all other training strategies identical to those of LSM-S. B. Additional Quantitative Comparison Our objective is to propose an efficient SR backbone based on LRU, a lightweight SSM v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.