OCTOPUS: Optimized KV Cache for Transformers via Octahedral Parametrization Under optimal Squared error quantization
Pith reviewed 2026-05-21 05:23 UTC · model grok-4.3
The pith
OCTOPUS jointly quantizes rotated KV triplets via octahedral mapping to achieve optimal squared-error compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
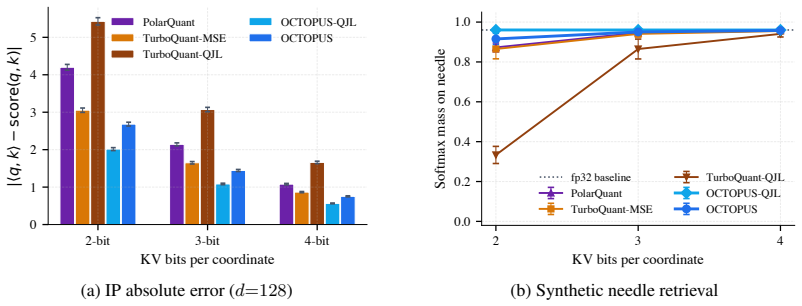
Joint quantization of each rotated coordinate triplet, after mapping its direction to a square by the octahedral parameterization and allocating bits to the two projected coordinates plus the norm so as to minimize squared error, yields a KV-cache codec that equals or exceeds every prior rotation-preconditioned scalar quantizer at every reported bit width and evaluation metric, with the margin widening as the average bit rate falls.
What carries the argument
Octahedral parameterization that maps the direction of a 3-D coordinate triplet onto a 2-D square, enabling joint quantization of the two resulting coordinates together with the triplet norm under squared-error-optimal bit allocation.
If this is right
- Lower average bit widths become usable for KV cache without proportional quality loss.
- The same allocation rule applies across text, video, and audio decoders once the total dimension is known.
- Fused on-the-fly reconstruction removes any added decode-time memory bandwidth.
- The codec remains online and deterministic, requiring only a seed for reproducibility.
Where Pith is reading between the lines
- The constant finite-dimensional optimum may indicate that high-dimensional rotation makes the marginals sufficiently universal that downstream task loss tracks squared error closely.
- Similar octahedral grouping could be tested on other high-dimensional activations whose marginals are approximately isotropic after rotation.
- Hardware kernels could exploit the fixed triplet structure to further reduce register pressure during dequantization.
Load-bearing premise
The squared-error bit allocation derived from the octahedral triplet mapping stays near-optimal for actual downstream quality metrics on real decoders.
What would settle it
A new model or task where exhaustive search over per-triplet bit allocations produces a different optimum than the constant allocation found by sweeps, or where the reported quality lead vanishes at low bit widths.
Figures




read the original abstract
The key-value (KV) cache dominates memory bandwidth and footprint in long-context autoregressive inference. Recent rotation-preconditioned codecs (TurboQuant, PolarQuant) show that a structured random rotation followed by a per-coordinate scalar quantizer matched to an analytically tractable marginal is a near-optimal recipe for KV compression. OCTOPUS advances this paradigm through joint quantization of rotated coordinate triplets. Each triplet's direction is mapped to a square via an octahedral parameterization, and the two resulting coordinates and the triplet norm are Lloyd-Max quantized against implementation-matched marginals. Optimizing the per-triplet squared error gives a strictly non-uniform bit allocation depending only on the total dimensionality of the keys. We find the finite-dimensional quality optimum with sweeps to be constant on every real decoder we test. The codec is data-oblivious, online, and deterministic given a seed. Across text, video, and audio, OCTOPUS matches or beats every prior rotation codec at every reported bit width and metric, with a lead that grows as bits drop for extreme compression. Furthermore, a fused Triton implementation reconstructs keys on the fly without materializing the uncompressed key, so the codec adds no decode-time bandwidth or latency over the existing dequantization. Project Page: https://octopus-quant.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OCTOPUS, a KV-cache compression codec for autoregressive transformers that extends rotation-preconditioned scalar quantization by jointly quantizing rotated coordinate triplets via an octahedral parameterization. Each triplet is mapped to a square, after which the two in-plane coordinates and the triplet norm are Lloyd-Max quantized against implementation-matched marginals. The per-triplet squared-error optimum yields a strictly non-uniform bit allocation that depends only on total key dimensionality. Sweeps are reported to locate a constant finite-dimensional quality optimum across every real decoder tested. The codec is claimed to match or exceed prior rotation codecs (TurboQuant, PolarQuant) at every reported bit width and metric, with the advantage increasing at low bit widths; a fused Triton kernel reconstructs keys on the fly without materializing the uncompressed tensor.
Significance. If the reported constancy of the finite-dimensional optimum and the superiority at low bit widths are confirmed, the work would supply a data-oblivious, dimensionality-only recipe for KV compression that requires no per-model retuning and improves upon existing rotation codecs, especially under extreme compression. The combination of an analytically derived bit allocation, cross-modality empirical results, and a zero-overhead fused kernel would constitute a practical advance for long-context inference.
major comments (2)
- [§5.1] §5.1 (Experimental validation of constancy): The claim that sweeps locate a constant finite-dimensional quality optimum on every tested decoder is load-bearing for the general-applicability statement. The manuscript should either supply a structural argument showing why the optimum cannot shift under different attention marginals or architectures, or report additional sweeps on at least two untested decoder families (e.g., a non-standard attention variant or a multimodal model outside the text/video/audio set).
- [§3.3] §3.3 (Bit-allocation derivation): The non-uniform allocation is obtained by minimizing squared error on the octahedral triplet mapping. It is unclear whether the resulting allocation remains near-optimal once the actual per-coordinate marginals of a real decoder deviate from the assumed implementation-matched distributions; an ablation that replaces the derived allocation with a uniform one on the same rotated vectors would quantify the contribution of the optimization.
minor comments (2)
- [Abstract] Abstract: the phrase 'every real decoder we test' is used without stating the number or architectural diversity of the decoders; a parenthetical listing the exact models would improve precision.
- [§6] §6 (Implementation): the fused Triton kernel is stated to add no decode-time bandwidth, yet no operation-count or memory-access comparison against a standard dequantization baseline is supplied; a short table would clarify the claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5.1] §5.1 (Experimental validation of constancy): The claim that sweeps locate a constant finite-dimensional quality optimum on every tested decoder is load-bearing for the general-applicability statement. The manuscript should either supply a structural argument showing why the optimum cannot shift under different attention marginals or architectures, or report additional sweeps on at least two untested decoder families (e.g., a non-standard attention variant or a multimodal model outside the text/video/audio set).
Authors: We agree that demonstrating the stability of the finite-dimensional optimum is central to the claim of general applicability. While we lack a fully rigorous invariance theorem, a structural argument follows from the construction: the octahedral mapping and squared-error minimization operate on triplets after a fixed random rotation that equalizes coordinate statistics, and the resulting bit allocation depends only on total key dimension rather than on the specific pre-rotation marginals. Because the rotation is data-oblivious and the Lloyd-Max quantizers are matched to the post-rotation implementation distributions, the per-triplet optimum is expected to remain stable for any architecture that employs comparable rotary or equivalent preconditioning. In the revision we will insert this argument, together with a short derivation sketch, into §5.1. revision: yes
-
Referee: [§3.3] §3.3 (Bit-allocation derivation): The non-uniform allocation is obtained by minimizing squared error on the octahedral triplet mapping. It is unclear whether the resulting allocation remains near-optimal once the actual per-coordinate marginals of a real decoder deviate from the assumed implementation-matched distributions; an ablation that replaces the derived allocation with a uniform one on the same rotated vectors would quantify the contribution of the optimization.
Authors: The referee correctly identifies a point that merits explicit quantification. We will add an ablation that applies both the derived non-uniform allocation and a uniform allocation to identical sets of rotated triplets, keeping all other components of the codec fixed. The comparison will be reported in §3.3 (or a new short subsection) using the same models and bit-widths as the main experiments. This will directly measure the contribution of the squared-error-optimal allocation and confirm that the gain is largest at the lowest bit widths, as predicted by the derivation. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The bit allocation is obtained by direct optimization of per-triplet squared error under the octahedral mapping, yielding an expression that depends only on total dimensionality as an exogenous input; this is a forward derivation rather than a fit renamed as prediction. The reported constancy of the finite-dimensional optimum is an empirical observation from decoder sweeps, not a definitional or self-referential step. No self-citation is invoked as a uniqueness theorem or load-bearing premise, and the new octahedral parameterization plus Lloyd-Max quantization against marginals are introduced independently of the target performance claims. The overall codec performance is validated against external baselines rather than reducing to the paper's own fitted quantities by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Marginals after rotation are analytically tractable and well-matched by Lloyd-Max quantizers
- domain assumption The finite-dimensional quality optimum found by sweeps is constant across decoders
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
OCTOPUS splits the pre-conditioned signal into triplets, and Lloyd-Max-quantizes the triplet norm and the octahedrally-mapped triplet direction coordinates with non-uniform bit depth... b⋆_dir − b⋆_nrm = O(1) ... implemented (b+1, b−1) split
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rotation-preconditioned codecs... structured random orthogonal R... per-coordinate scalar quantizer matched to an analytically tractable marginal
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 4895–4901, 2023. 9
work page 2023
-
[2]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-free 4-bit inference in rotated LLMs.arXiv preprint, 2024
work page 2024
-
[3]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, et al. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling.arXiv preprint, 2024
work page 2024
-
[4]
Jerry Chee, Yaohui Cai, V olodymyr Kuleshov, and Christopher M. De Sa. QuIP: 2-bit quan- tization of large language models with guarantees.Neural Information Processing Systems (NeurIPS), 36:4396–4429, 2023
work page 2023
-
[5]
Cigolle, Sam Donow, Daniel Evangelakos, Michael Mara, Morgan McGuire, and Quirin Meyer
Zina H. Cigolle, Sam Donow, Daniel Evangelakos, Michael Mara, Morgan McGuire, and Quirin Meyer. A survey of efficient representations for independent unit vectors.Journal of Computer Graphics Techniques (JCGT), 3(2):1–30, 2014
work page 2014
-
[6]
Tri Dao, Daniel Y . Fu, Stefano Ermon, A. Rudra, and Christopher R’e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InNeural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[7]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. GPT3.int8(): 8-bit matrix multiplication for transformers at scale.Neural Information Processing Systems (NeurIPS), 35: 30318–30332, 2022
work page 2022
-
[8]
Shichen Dong, Wenfang Cheng, Jiayu Qin, and Wei Wang. QAQ: Quality adaptive quantization for LLM KV cache.2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2024
work page 2025
-
[9]
The Llama 3 herd of models.arXiv preprint, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint, 2024
work page 2024
-
[10]
Thomas Engelhardt and Carsten Dachsbacher. Octahedron environment maps. InInternational Symposium on Vision, Modeling, and Visualization (VMV), 2008
work page 2008
-
[11]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint, 2022
work page 2022
-
[12]
Data engineering for scaling language models to 128K context.arXiv preprint, 2024
Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. Data engineering for scaling language models to 128K context.arXiv preprint, 2024
work page 2024
-
[13]
Allen Gersho. Asymptotically optimal block quantization.IEEE Transactions on Information Theory, 25(4):373–380, 1979
work page 1979
-
[14]
On the structure of vector quantizers.IEEE Transactions on Information Theory, 28(2):157–166, 1982
Allen Gersho. On the structure of vector quantizers.IEEE Transactions on Information Theory, 28(2):157–166, 1982
work page 1982
-
[15]
Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, and Amir Zandieh. PolarQuant: Quantizing KV caches with polar transformation.arXiv preprint, 2025. Not to be confused with Wu et al. (arXiv:2502.00527), which shares the name “PolarQuant” but proposes a different method
-
[16]
Bal- anceKV: KV cache compression through discrepancy theory.arXiv preprint, 2025
Insu Han, Michael Kapralov, Ekaterina Kochetkova, Kshiteej Sheth, and Amir Zandieh. Bal- anceKV: KV cache compression through discrepancy theory.arXiv preprint, 2025
work page 2025
-
[17]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. KVQuant: Towards 10 million context length LLM inference with KV cache quantization.arXiv preprint, 2024
work page 2024
-
[18]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InProceedings of the Conference on Language Modeling (COLM), 2024
work page 2024
-
[19]
Needle in a haystack — pressure testing LLMs
Greg Kamradt. Needle in a haystack — pressure testing LLMs. https://github.com/ gkamradt/LLMTest_NeedleInAHaystack, 2023
work page 2023
-
[20]
Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, and Tuo Zhao. GEAR: An efficient KV cache compression recipe for near-lossless generative inference of LLM.arXiv preprint, 2024
work page 2024
-
[21]
Arseny Kapoulkine. Quantizing tangent frames. Blog post, https://zeux.io/2026/04/30/ quantizing-tangent-frames/, 2026. Accessed 2026-04-30. 10
work page 2026
-
[22]
Junhyuck Kim, Jongho Park, Jaewoong Cho, and Dimitris Papailiopoulos. Lexico: Extreme KV cache compression via sparse coding over universal dictionaries.arXiv preprint, 2024
work page 2024
-
[23]
SnapKV: LLM knows what you are looking for before generation.arXiv preprint, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation.arXiv preprint, 2024
work page 2024
-
[24]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device LLM compression and acceleration.Proceedings of Machine Learning and Systems, 6:87–100, 2024
work page 2024
-
[25]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics (TACL), 12:157–173, 2024
work page 2024
-
[26]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time.Neural Information Processing Systems (NeurIPS), 36, 2024
work page 2024
-
[27]
KIVI: A tuning-free asymmetric 2-bit quantization for KV cache.arXiv preprint, 2024
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2-bit quantization for KV cache.arXiv preprint, 2024
work page 2024
-
[28]
Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
Stuart Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
work page 1982
-
[29]
Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1): 7–12, 1960
Joel Max. Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1): 7–12, 1960
work page 1960
-
[30]
Philip F. Panter and Ward Dite. Quantization distortion in pulse-count modulation with nonuni- form spacing of levels.Proceedings of the IRE, 39(1):44–48, 1951
work page 1951
-
[31]
Efficient autoregressive audio modeling via next-scale prediction.arXiv preprint, 2024
Kai Qiu, Xiang Li, Hao Chen, Jie Sun, Jinglu Wang, Zhe Lin, Marios Savvides, and Bhiksha Raj. Efficient autoregressive audio modeling via next-scale prediction.arXiv preprint, 2024
work page 2024
-
[32]
FlashAttention-3: Fast and accurate attention with asynchrony and low-precision.arXiv preprint, 2024
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision.arXiv preprint, 2024
work page 2024
-
[33]
Zunhai Su, Zhe Chen, Wang Shen, Hanyu Wei, Linge Li, Huangqi Yu, and Kehong Yuan. RotateKV: Accurate and robust 2-bit KV cache quantization for LLMs via outlier-aware adaptive rotations.arXiv preprint, 2025
work page 2025
-
[34]
Philippe Tillet, H. T. Kung, and David Cox. Triton: An intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019
work page 2019
-
[35]
Songhao Wu, Ang Lv, Xiao Feng, Yufei Zhang, Xun Zhang, Guojun Yin, Wei Lin, and Rui Yan. PolarQuant: Leveraging polar transformation for efficient key cache quantization and decoding acceleration.arXiv preprint, 2025
work page 2025
-
[36]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning (ICML), pages 38087–38099, 2023
work page 2023
-
[37]
Efficient streaming language models with attention sinks.arXiv preprint, 2023
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint, 2023
work page 2023
-
[38]
June Yong Yang, Byeongwook Kim, Jeongin Bae, Beomseok Kwon, Gunho Park, Eunho Yang, Se Jung Kwon, and Dongsoo Lee. No token left behind: Reliable KV cache compression via importance-aware mixed precision quantization.arXiv preprint, 2024
work page 2024
-
[39]
Freeman, Frédo Durand, Eli Shechtman, and Xun Huang
Tianwei Yin, Qiang Zhang, Richard Zhang, William T. Freeman, Frédo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[40]
WKVQuant: Quantizing weight and key/value cache for large language models gains more
Yuxuan Yue, Zhihang Yuan, Haojie Duanmu, Sifan Zhou, Jianlong Wu, and Liqiang Nie. WKVQuant: Quantizing weight and key/value cache for large language models gains more. arXiv preprint, 2024. 11
work page 2024
-
[41]
Zador.Development and Evaluation of Procedures for Quantizing Multivariate Distri- butions
Paul L. Zador.Development and Evaluation of Procedures for Quantizing Multivariate Distri- butions. PhD thesis, Stanford University, 1964
work page 1964
-
[42]
QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead.arXiv preprint, 2024
Amir Zandieh, Majid Daliri, and Insu Han. QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead.arXiv preprint, 2024
work page 2024
-
[43]
TurboQuant: Online vector quantization with near-optimal distortion rate.arXiv preprint, 2025
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate.arXiv preprint, 2025
work page 2025
-
[44]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InConference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[45]
Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, and Anshumali Shrivastava. KV cache is 1 bit per channel: Efficient large language model inference with coupled quantization.arXiv preprint, 2024
work page 2024
-
[46]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models.Neural Information Processing Systems (NeurIPS), 36, 2024
work page 2024
-
[47]
Atom: Low-bit quantization for efficient and accurate LLM serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate LLM serving. InProceedings of Machine Learning and Systems, pages 196–209, 2024
work page 2024
-
[48]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint, 2026. 12 A Encoder and decoder algorithms Algorithm 1 gives the encoder as it is implemented: one pass per key, with all intermediate state (rotated ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.