Gated Bidirectional Linear Attention for Generative Retrieval
Pith reviewed 2026-06-27 20:36 UTC · model grok-4.3
The pith
A hybrid encoder interleaving self-attention and gated bidirectional linear attention in a 1:2 ratio matches full bidirectional self-attention quality on long user histories while delivering up to 8.2 times layer speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
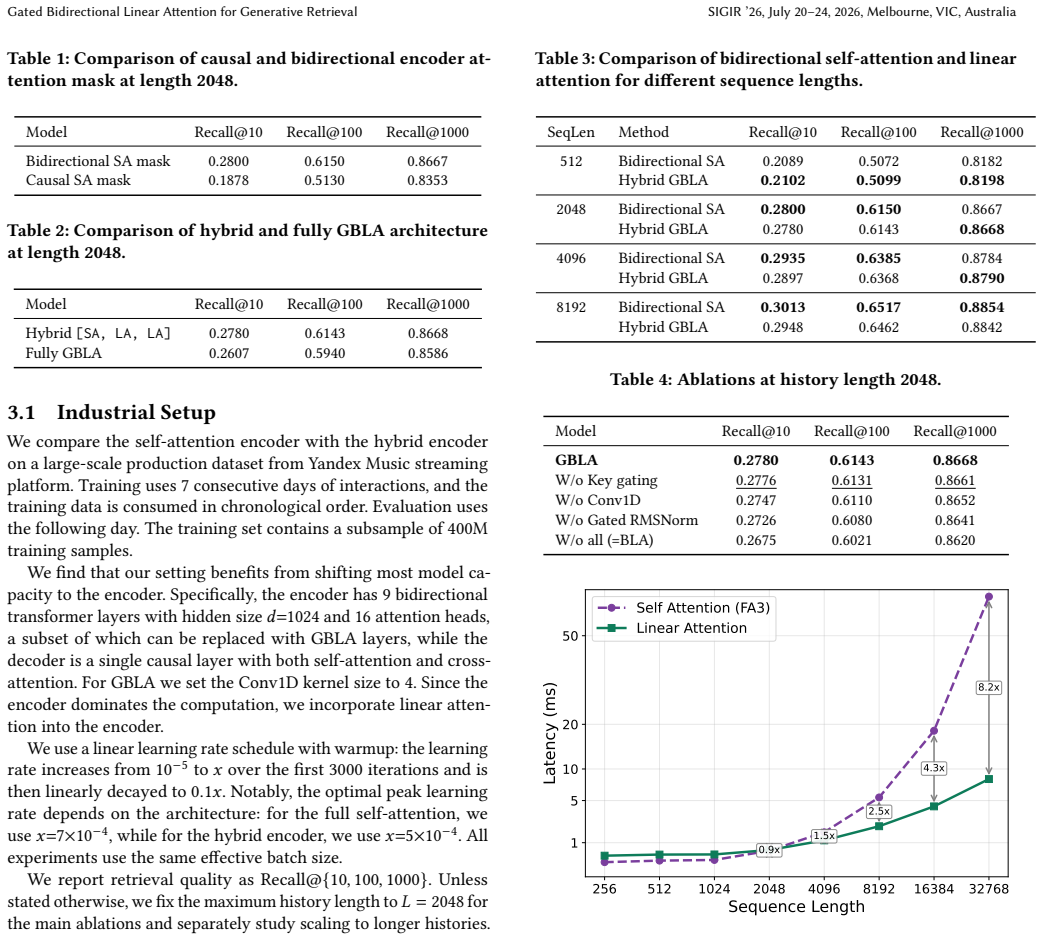
Gated Bidirectional Linear Attention (GBLA) recovers the quality of bidirectional self-attention when self-attention and GBLA blocks are interleaved 1:2 in the encoder. GBLA is built by adding Conv1D local causal mixing, sequence-level key gating, and gated RMSNorm to kernelized linear attention. On the Yandex Music dataset this hybrid encoder matches full self-attention retrieval metrics; on H100 GPUs a single GBLA layer is up to 8.2 times faster than FlashAttention-v3 at history length 32768. The hybrid design also preserves quality on public Amazon retrieval benchmarks.
What carries the argument
Gated Bidirectional Linear Attention (GBLA) that augments kernelized linear attention with Conv1D local causal mixing, sequence-level key gating for soft forgetting, and gated RMSNorm.
If this is right
- The 1:2 SA-GBLA hybrid encoder matches bidirectional self-attention retrieval quality on the Yandex Music dataset.
- GBLA achieves up to 8.2 times single-layer speedup versus FlashAttention-v3 on H100 GPUs at sequence length 32768.
- The same hybrid architecture preserves self-attention retrieval quality on the public Amazon benchmarks.
- GBLA removes the quadratic latency term from the encoder, allowing history lengths to grow without proportional slowdown.
Where Pith is reading between the lines
- The hybrid ratio may transfer to other long-context sequence tasks where full attention remains the quality ceiling.
- Removing the remaining self-attention blocks entirely could be tested by increasing the GBLA proportion further.
- The key-gating and Conv1D additions might be portable to causal linear attention in autoregressive language models.
Load-bearing premise
The three added components together suffice to recover full bidirectional self-attention quality when GBLA replaces two-thirds of the self-attention blocks, as shown only by end-to-end empirical results.
What would settle it
Training the identical 1:2 hybrid encoder on a fresh large-scale retrieval dataset with different interaction statistics and measuring whether its retrieval metrics fall measurably below those of a pure bidirectional self-attention encoder.
Figures

read the original abstract
In recommender systems, generative retrieval typically uses an encoder-decoder setup: an encoder processes a user interaction history, and an autoregressive decoder then generates recommended items. In large-scale streaming services, active users accumulate very long histories over time. As histories grow, the encoder becomes a major latency bottleneck because softmax attention scales quadratically with sequence length. In our experiments, using bidirectional attention in the encoder substantially improves quality. However, most sub-quadratic attention methods focus on causal attention. We propose Gated Bidirectional Linear Attention (GBLA), a linear-time bidirectional attention layer that extends kernelized linear attention with three lightweight components: local causal mixing (Conv1D), sequence-level key gating for soft forgetting, and a gated RMSNorm output. On a large-scale Yandex Music dataset, a hybrid encoder that interleaves self-attention (SA) and GBLA in a 1:2 ratio (one SA block followed by two GBLA blocks) matches bidirectional self-attention quality. On H100 GPUs, GBLA reaches up to an $8.2\times$ single-layer speedup at a history length of 32768, compared to FlashAttention-v3. Finally, we show that the same hybrid design generalizes beyond our proprietary setting, consistently preserving self-attention retrieval quality on public Amazon benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gated Bidirectional Linear Attention (GBLA), which augments kernelized linear attention with three components (Conv1D local causal mixing, sequence-level key gating, and gated RMSNorm) to enable efficient bidirectional processing in the encoder of generative retrieval models. It reports that a hybrid encoder interleaving self-attention and GBLA blocks in a 1:2 ratio matches the retrieval quality of full bidirectional self-attention on a large proprietary Yandex Music dataset while delivering up to 8.2× single-layer speedup versus FlashAttention-v3 at sequence length 32768 on H100 GPUs; the same hybrid is shown to preserve quality on public Amazon benchmarks.
Significance. If the quality-parity result holds under controlled conditions, the work would be significant for large-scale recommender systems that must encode very long user histories without quadratic latency. The reported GPU speedup and the generalization experiment on public Amazon data are concrete strengths; the absence of component ablations and error bars, however, leaves the attribution of parity to the three GBLA extensions weakly supported.
major comments (2)
- [Experiments (Yandex Music)] Experiments section (Yandex Music results): the central claim that the 1:2 SA:GBLA hybrid recovers bidirectional self-attention quality rests solely on end-to-end metrics; no ablation removes any one of the three added components (Conv1D, key gating, gated RMSNorm) while retaining the hybrid ratio, nor compares against a hybrid using unmodified kernelized linear attention. This omission is load-bearing because the observed parity could be driven by the retained SA blocks rather than the proposed extensions.
- [Abstract and §4] Abstract and evaluation protocol description: no error bars, confidence intervals, or statistical significance tests accompany the quality metrics on the proprietary Yandex Music dataset, and training/evaluation details (optimizer, learning-rate schedule, negative sampling, exact metric definitions) are not provided. These omissions weaken the empirical support for the quality-parity claim given that the main result is reported on a single non-public corpus.
minor comments (2)
- [§3] Notation for the three GBLA components is introduced in the abstract but the precise mathematical definitions (especially the sequence-level key gating and gated RMSNorm) should be cross-referenced to the corresponding equations in §3 for clarity.
- [Experiments (speedup)] The speedup figure (8.2× at length 32768) should specify whether it is measured for a single GBLA layer in isolation or within the full hybrid encoder, and whether it includes the overhead of the interleaved SA blocks.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and for acknowledging the potential impact of this work on large-scale recommender systems. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Experiments section (Yandex Music results): the central claim that the 1:2 SA:GBLA hybrid recovers bidirectional self-attention quality rests solely on end-to-end metrics; no ablation removes any one of the three added components (Conv1D, key gating, gated RMSNorm) while retaining the hybrid ratio, nor compares against a hybrid using unmodified kernelized linear attention. This omission is load-bearing because the observed parity could be driven by the retained SA blocks rather than the proposed extensions.
Authors: We concur that the lack of ablations limits the strength of the claim. The GBLA components were developed to overcome limitations of kernelized linear attention in bidirectional contexts, specifically for local dependencies, long-sequence forgetting, and training stability. In the revised manuscript, we will add an experiment comparing the 1:2 hybrid with unmodified kernelized linear attention to better isolate the contribution of the proposed extensions. We will also elaborate on the design rationale for each component. revision: partial
-
Referee: Abstract and evaluation protocol description: no error bars, confidence intervals, or statistical significance tests accompany the quality metrics on the proprietary Yandex Music dataset, and training/evaluation details (optimizer, learning-rate schedule, negative sampling, exact metric definitions) are not provided. These omissions weaken the empirical support for the quality-parity claim given that the main result is reported on a single non-public corpus.
Authors: We will update the manuscript to provide complete details on the optimizer, learning-rate schedule, negative sampling, and metric definitions in the evaluation protocol section. For the Yandex Music results, the experiments were performed with a single training run due to the scale of the dataset and associated costs. We will add a statement clarifying this and highlight the corroborating results on the public Amazon datasets. Statistical significance testing can be added for the Amazon experiments in the revision. revision: partial
- We cannot provide error bars or results from multiple independent runs on the Yandex Music dataset, as repeating the full-scale training is computationally prohibitive.
Circularity Check
No circularity: empirical quality claims rest on direct held-out comparisons
full rationale
The paper advances an empirical claim that a 1:2 SA+GBLA hybrid recovers bidirectional self-attention retrieval quality on Yandex Music and Amazon benchmarks. This is supported by end-to-end experimental results against FlashAttention-v3 and self-attention baselines on held-out data. No equations, fitted parameters, or self-citations are shown to reduce the reported metrics to quantities defined inside the same experiment. The three added components are motivated by extension of prior kernelized linear attention but the performance parity is not derived from them by construction; it is measured directly. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results appears in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- hybrid interleaving ratio
axioms (1)
- domain assumption Kernelized linear attention can be made bidirectional by adding local causal mixing, sequence-level key gating, and gated RMSNorm
invented entities (1)
-
Gated Bidirectional Linear Attention (GBLA)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
-
[3]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment.arXiv preprint arXiv:2502.18965(2025). arXiv:2502.18965 [cs.IR]
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Albert Gu and Tri Dao. 2023. Mamba: Linear-Time Sequence Modeling with Selec- tive State Spaces.arXiv preprint arXiv:2312.00752(2023). arXiv:2312.00752 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[8]
Transformers are rnns: Fast autoregressive transformers with linear attention, 2020
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention.arXiv preprint arXiv:2006.16236(2020). arXiv:2006.16236 [cs.LG]
-
[9]
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret
-
[10]
InInternational conference on machine learning
Transformers are rnns: Fast autoregressive transformers with linear atten- tion. InInternational conference on machine learning. PMLR, 5156–5165
- [11]
-
[12]
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, Wentao Li, Enzhe Lu, Weizhou Liu, Yanru Chen, Weixin Xu, Longhui Yu, Yejie Wang, Yu Fan, Longguang Zhong, Enming Yuan, Dehao Zhang, Yizhi Zhang, T. Y. Liu, Haiming Wang, Shengjun Fang, Weiran He, Shaowei Liu, Yiwei Li, Jianlin Su, Jiezh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. Pinner- Former: Sequence Modeling for User Representation at Pinterest.arXiv preprint arXiv:2205.04507(2022). arXiv:2205.04507 [cs.LG] doi:10.48550/arXiv.2205.04507
- [14]
-
[15]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision.arXiv preprint arXiv:2407.08608(2024). arXiv:2407.08608 [cs.LG] doi:10.48550/arXiv.2407.08608
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.08608 2024
-
[16]
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, et al. 2024. Better generalization with semantic ids: A case study in ranking for recommendations. InProceedings of the 18th ACM Conference on Recommender Systems. 1039–1044
2024
-
[17]
Dan Tito Svenstrup, Jonas Hansen, and Ole Winther. 2017. Hash embeddings for efficient word representations.Advances in neural information processing systems 30 (2017)
2017
-
[18]
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. 2024. Gated Delta Networks: Improving Mamba2 with Delta Rule.arXiv preprint arXiv:2412.06464(2024). arXiv:2412.06464 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Jun Zhai et al . 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations.arXiv preprint arXiv:2402.17152(2024). arXiv:2402.17152 [cs.IR]
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.