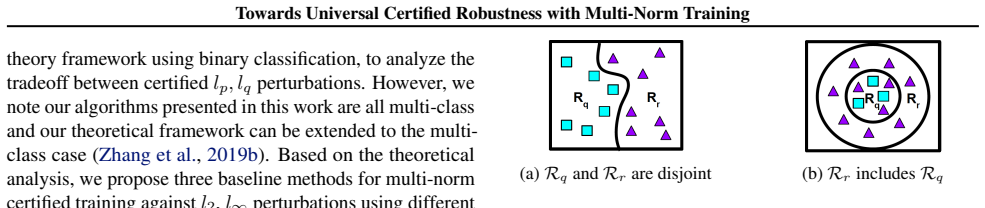
Towards Generalized Certified Robustness with Multi-Norm Training
Pith reviewed 2026-05-23 19:58 UTC · model grok-4.3
The pith
A multi-norm certified training framework called CURE improves union robustness against different perturbation norms on image datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
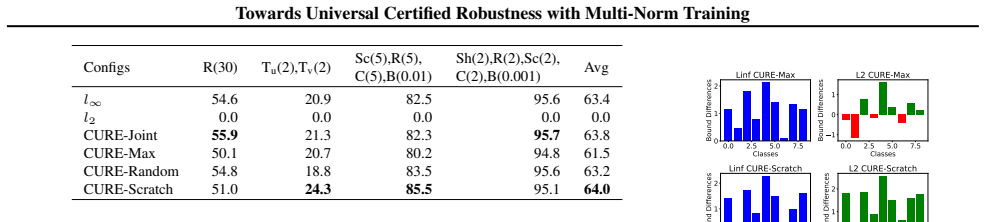
By constructing a theoretical framework to analyze and mitigate the tradeoff between norms, the authors propose the first multi-norm certified training framework CURE consisting of several multi-norm certified training methods. Inspired by the theoretical findings, bound alignment and the connection between natural training and certified training are devised to attain better union robustness when training from scratch or fine-tuning a pre-trained certified model. Compared with state-of-the-art certified training, CURE improves union robustness to 32.0 percent on MNIST, 25.8 percent on CIFAR-10, and 10.6 percent on TinyImagenet across different epsilon values, and leads to better performance,
What carries the argument
The CURE multi-norm certified training framework, which uses bound alignment together with the link between natural and certified training to handle multiple norms at once.
If this is right
- Union robustness rises across multiple epsilon values on MNIST, CIFAR-10, and TinyImagenet.
- Certified accuracy improves on unseen geometric and patch perturbations on CIFAR-10.
- The same methods work both when training models from scratch and when fine-tuning already-certified models.
- The approach opens a route to certified robustness that covers more than one perturbation family.
Where Pith is reading between the lines
- The same bound-alignment idea might be tested on norms beyond l-infinity and l-2 or on non-image data such as graphs or audio.
- If union robustness scales with more norms, practitioners could replace separate per-norm models with one CURE-trained model.
- The connection between natural and certified training might be applied to other certified methods that currently ignore natural accuracy.
Load-bearing premise
The theoretical analysis of norm tradeoffs actually produces the reported union-robustness gains without hidden per-norm hyper-parameter tuning that would make comparisons unfair.
What would settle it
A controlled experiment in which single-norm baselines, when given equivalent total hyper-parameter search effort, reach the same union robustness numbers as CURE on the same datasets and epsilon ranges.
Figures





read the original abstract
Existing certified training methods can only train models to be robust against a certain perturbation type (e.g. $l_\infty$ or $l_2$). However, an $l_\infty$ certifiably robust model may not be certifiably robust against $l_2$ perturbation (and vice versa) and also has low robustness against other perturbations (e.g. geometric and patch transformation). By constructing a theoretical framework to analyze and mitigate the tradeoff, we propose the first multi-norm certified training framework \textbf{CURE}, consisting of several multi-norm certified training methods, to attain better \emph{union robustness} when training from scratch or fine-tuning a pre-trained certified model. Inspired by our theoretical findings, we devise bound alignment and connect natural training with certified training for better union robustness. Compared with SOTA-certified training, \textbf{CURE} improves union robustness to $32.0\%$ on MNIST, $25.8\%$ on CIFAR-10, and $10.6\%$ on TinyImagenet across different epsilon values. It leads to better generalization on a diverse set of challenging unseen geometric and patch perturbations to $6.8\%$ and $16.0\%$ on CIFAR-10. Overall, our contributions pave a path towards \textit{generalized certified robustness}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CURE, the first multi-norm certified training framework for achieving union robustness across perturbation norms (e.g., l_infty, l_2) and types (including geometric and patch). It constructs a theoretical framework to analyze norm tradeoffs, proposes bound alignment and a connection between natural and certified training, and reports improved union robustness over SOTA single-norm methods: 32.0% on MNIST, 25.8% on CIFAR-10, and 10.6% on TinyImagenet, plus gains on unseen perturbations (6.8% and 16.0% on CIFAR-10).
Significance. If the theoretical analysis and numerical gains are shown to arise from the proposed methods under matched hyperparameter budgets, the work would meaningfully advance generalized certified robustness by addressing the single-norm limitation of prior certified training. The explicit connection of natural and certified objectives and the multi-norm bound alignment are potentially reusable ideas.
major comments (1)
- [Abstract] Abstract: the central claim that CURE improves union robustness over SOTA-certified training rests on the reported percentages (32.0% MNIST, 25.8% CIFAR-10, 10.6% TinyImagenet). The abstract provides no information on whether the same hyperparameter search budget, epsilon schedule, or per-norm tuning procedure was applied to both CURE and the single-norm baselines; if CURE implicitly relaxes this constraint, the union-robustness numbers are not directly comparable and the improvement cannot be attributed to the framework.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit experimental details in the abstract. We address this concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that CURE improves union robustness over SOTA-certified training rests on the reported percentages (32.0% MNIST, 25.8% CIFAR-10, 10.6% TinyImagenet). The abstract provides no information on whether the same hyperparameter search budget, epsilon schedule, or per-norm tuning procedure was applied to both CURE and the single-norm baselines; if CURE implicitly relaxes this constraint, the union-robustness numbers are not directly comparable and the improvement cannot be attributed to the framework.
Authors: We agree that the abstract is too concise on this point and does not explicitly state the experimental protocol. In the full paper (Section 4 and Appendix), all methods—including the single-norm SOTA baselines—were trained under identical hyperparameter search budgets, the same epsilon schedules, and the same per-norm tuning procedures to ensure direct comparability. The reported union-robustness gains are therefore attributable to the multi-norm framework rather than relaxed constraints. We will revise the abstract to include a short clause clarifying that comparisons use matched hyperparameter budgets. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a theoretical framework to analyze norm tradeoffs, then proposes CURE methods with bound alignment and natural/certified training connections. No equations, self-citations, or fitted parameters are shown reducing the union-robustness claims or improvements (32.0% MNIST etc.) to inputs by construction. The derivation chain remains independent of the reported empirical gains, which are presented as outcomes of the new framework rather than tautological renamings or self-referential fits. This is the common honest non-finding for papers whose central claims rest on external comparisons to SOTA baselines.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Lipschitz Optimization for Formal Verification of Homographies
Formal verification method using Lipschitz optimization on homographies to certify vision network robustness to camera pose changes in predominantly planar scenes.
-
BEAVER: An Efficient Deterministic LLM Verifier
BEAVER is the first practical deterministic verifier that maintains sound probability bounds on LLM safety properties using token tries and frontier data structures, finding 2-3x more violations than sampling at 1/10 ...
Reference graph
Works this paper leans on
-
[1]
Adversarial training and provable defenses: Bridging the gap
Mislav Balunovi \'c and Martin Vechev. Adversarial training and provable defenses: Bridging the gap. In 8th International Conference on Learning Representations (ICLR 2020)(virtual). International Conference on Learning Representations, 2020
work page 2020
-
[2]
Certifying geometric robustness of neural networks
Mislav Balunovic, Maximilian Baader, Gagandeep Singh, Timon Gehr, and Martin Vechev. Certifying geometric robustness of neural networks. Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[3]
Unlabeled data improves adversarial robustness
Yair Carmon, Aditi Raghunathan, Ludwig Schmidt, John C Duchi, and Percy S Liang. Unlabeled data improves adversarial robustness. Advances in neural information processing systems, 32, 2019
work page 2019
-
[4]
Francesco Croce and Matthias Hein. Adversarial robustness against multiple and single l\_p -threat models via quick fine-tuning of robust classifiers. In International Conference on Machine Learning, pages 4436--4454. PMLR, 2022
work page 2022
-
[5]
Sumanth Dathathri, Krishnamurthy Dvijotham, Alexey Kurakin, Aditi Raghunathan, Jonathan Uesato, Rudy R Bunel, Shreya Shankar, Jacob Steinhardt, Ian Goodfellow, Percy S Liang, et al. Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming. Advances in Neural Information Processing Systems, 33: 0 5318--5331, 2020
work page 2020
-
[6]
Scaling the convex barrier with active sets
Alessandro De Palma, Harkirat S Behl, Rudy Bunel, Philip Torr, and M Pawan Kumar. Scaling the convex barrier with active sets. In Proceedings of the ICLR 2021 Conference. Open Review, 2021
work page 2021
-
[7]
Adversarially robust vision transformers, 2022
Edoardo Debenedetti and Carmela Troncoso—EPFL. Adversarially robust vision transformers, 2022
work page 2022
-
[8]
Ai2: Safety and robustness certification of neural networks with abstract interpretation
Timon Gehr, Matthew Mirman, Dana Drachsler-Cohen, Petar Tsankov, Swarat Chaudhuri, and Martin Vechev. Ai2: Safety and robustness certification of neural networks with abstract interpretation. In 2018 IEEE symposium on security and privacy (SP), pages 3--18. IEEE, 2018
work page 2018
-
[9]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
On the effectiveness of interval bound propagation for training verifiably robust models
Sven Gowal, Krishnamurthy Dvijotham, Robert Stanforth, Rudy Bunel, Chongli Qin, Jonathan Uesato, Relja Arandjelovic, Timothy Mann, and Pushmeet Kohli. On the effectiveness of interval bound propagation for training verifiably robust models. arXiv preprint arXiv:1810.12715, 2018
-
[11]
Uncovering the limits of adversarial training against norm-bounded adversarial examples,
Sven Gowal, Chongli Qin, Jonathan Uesato, Timothy Mann, and Pushmeet Kohli. Uncovering the limits of adversarial training against norm-bounded adversarial examples. arXiv preprint arXiv:2010.03593, 2020
-
[12]
A recipe for improved certifiable robustness: Capacity and data
Kai Hu, Klas Leino, Zifan Wang, and Matt Fredrikson. A recipe for improved certifiable robustness: Capacity and data. arXiv preprint arXiv:2310.02513, 2023
-
[13]
Unlocking deterministic robustness certification on imagenet
Kai Hu, Andy Zou, Zifan Wang, Klas Leino, and Matt Fredrikson. Unlocking deterministic robustness certification on imagenet. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[14]
Ramp: Boosting adversarial robustness against multiple l\_p perturbations
Enyi Jiang and Gagandeep Singh. Ramp: Boosting adversarial robustness against multiple l\_p perturbations. arXiv preprint arXiv:2402.06827, 2024
-
[15]
Transfer of Adversarial Robustness Between Perturbation Types
Daniel Kang, Yi Sun, Tom Brown, Dan Hendrycks, and Jacob Steinhardt. Transfer of adversarial robustness between perturbation types. arXiv preprint arXiv:1905.01034, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[16]
Reluplex: An efficient smt solver for verifying deep neural networks
Guy Katz, Clark Barrett, David L Dill, Kyle Julian, and Mykel J Kochenderfer. Reluplex: An efficient smt solver for verifying deep neural networks. In Computer Aided Verification: 29th International Conference, CAV 2017, Heidelberg, Germany, July 24-28, 2017, Proceedings, Part I 30, pages 97--117. Springer, 2017
work page 2017
-
[17]
Torchattacks: A pytorch repository for adversarial attacks
Hoki Kim. Torchattacks: A pytorch repository for adversarial attacks. arXiv preprint arXiv:2010.01950, 2020
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[20]
Adversarial examples in the physical world
Alexey Kurakin, Ian J Goodfellow, and Samy Bengio. Adversarial examples in the physical world. In Artificial intelligence safety and security, pages 99--112. Chapman and Hall/CRC, 2018
work page 2018
-
[21]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. URL https://api.semanticscholar.org/CorpusID:16664790
work page 2015
-
[22]
Mnist handwritten digit database
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
work page 2010
-
[23]
Towards defending multiple adversarial perturbations via gated batch normalization
Aishan Liu, Shiyu Tang, Xianglong Liu, Xinyun Chen, Lei Huang, Zhuozhuo Tu, Dawn Song, and Dacheng Tao. Towards defending multiple adversarial perturbations via gated batch normalization. arXiv preprint arXiv:2012.01654, 2020
-
[24]
Learning to generate noise for multi-attack robustness
Divyam Madaan, Jinwoo Shin, and Sung Ju Hwang. Learning to generate noise for multi-attack robustness. In International Conference on Machine Learning, pages 7279--7289. PMLR, 2021
work page 2021
-
[25]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Adversarial robustness against the union of multiple perturbation models
Pratyush Maini, Eric Wong, and Zico Kolter. Adversarial robustness against the union of multiple perturbation models. In International Conference on Machine Learning, pages 6640--6650. PMLR, 2020
work page 2020
-
[27]
Perturbation type categorization for multiple adversarial perturbation robustness
Pratyush Maini, Xinyun Chen, Bo Li, and Dawn Song. Perturbation type categorization for multiple adversarial perturbation robustness. In Uncertainty in Artificial Intelligence, pages 1317--1327. PMLR, 2022
work page 2022
-
[28]
Is certifyingℓ p robustness still worthwhile?arXiv preprint arXiv:2310.09361, 2023
Ravi Mangal, Klas Leino, Zifan Wang, Kai Hu, Weicheng Yu, Corina Pasareanu, Anupam Datta, and Matt Fredrikson. Is certifying l_p robustness still worthwhile? arXiv preprint arXiv:2310.09361, 2023
-
[29]
Connecting certified and adversarial training
Yuhao Mao, Mark M \"u ller, Marc Fischer, and Martin Vechev. Connecting certified and adversarial training. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[30]
Differentiable abstract interpretation for provably robust neural networks
Matthew Mirman, Timon Gehr, and Martin Vechev. Differentiable abstract interpretation for provably robust neural networks. In International Conference on Machine Learning, pages 3578--3586. PMLR, 2018
work page 2018
-
[32]
u ller, Gleb Makarchuk, Gagandeep Singh, Markus P \
Mark Niklas M \"u ller, Gleb Makarchuk, Gagandeep Singh, Markus P \"u schel, and Martin Vechev. Prima: general and precise neural network certification via scalable convex hull approximations. Proceedings of the ACM on Programming Languages, 6 0 (POPL): 0 1--33, 2022 b
work page 2022
-
[33]
Certified adversarial robustness within multiple perturbation bounds
Soumalya Nandi, Sravanti Addepalli, Harsh Rangwani, and R Venkatesh Babu. Certified adversarial robustness within multiple perturbation bounds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2298--2305, 2023
work page 2023
-
[34]
Approximate manifold defense against multiple adversarial perturbations
Jay Nandy, Wynne Hsu, and Mong Li Lee. Approximate manifold defense against multiple adversarial perturbations. In 2020 International Joint Conference on Neural Networks (IJCNN), pages 1--8. IEEE, 2020
work page 2020
-
[35]
Robust principles: Architectural design principles for adversarially robust cnns
ShengYun Peng, Weilin Xu, Cory Cornelius, Matthew Hull, Kevin Li, Rahul Duggal, Mansi Phute, Jason Martin, and Duen Horng Chau. Robust principles: Architectural design principles for adversarially robust cnns. arXiv preprint arXiv:2308.16258, 2023
-
[36]
Semidefinite relaxations for certifying robustness to adversarial examples
Aditi Raghunathan, Jacob Steinhardt, and Percy S Liang. Semidefinite relaxations for certifying robustness to adversarial examples. Advances in neural information processing systems, 31, 2018
work page 2018
-
[37]
Understanding and mitigating the tradeoff between robustness and accuracy
Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. Understanding and mitigating the tradeoff between robustness and accuracy. arXiv preprint arXiv:2002.10716, 2020
-
[38]
Fast certified robust training with short warmup
Zhouxing Shi, Yihan Wang, Huan Zhang, Jinfeng Yi, and Cho-Jui Hsieh. Fast certified robust training with short warmup. Advances in Neural Information Processing Systems, 34: 0 18335--18349, 2021
work page 2021
-
[39]
Fast and effective robustness certification
Gagandeep Singh, Timon Gehr, Matthew Mirman, Markus P \"u schel, and Martin Vechev. Fast and effective robustness certification. Advances in neural information processing systems, 31, 2018
work page 2018
-
[40]
An abstract domain for certifying neural networks
Gagandeep Singh, Timon Gehr, Markus P \"u schel, and Martin Vechev. An abstract domain for certifying neural networks. Proceedings of the ACM on Programming Languages, 3 0 (POPL): 0 1--30, 2019 a
work page 2019
-
[41]
Boosting robustness certification of neural networks
Gagandeep Singh, Timon Gehr, Markus P \"u schel, and Martin Vechev. Boosting robustness certification of neural networks. In International conference on learning representations, 2019 b
work page 2019
-
[42]
Evaluating Robustness of Neural Networks with Mixed Integer Programming
Vincent Tjeng, Kai Xiao, and Russ Tedrake. Evaluating robustness of neural networks with mixed integer programming. arXiv preprint arXiv:1711.07356, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Adversarial training and robustness for multiple perturbations
Florian Tramer and Dan Boneh. Adversarial training and robustness for multiple perturbations. Advances in neural information processing systems, 32, 2019
work page 2019
-
[44]
Ensemble Adversarial Training: Attacks and Defenses
Florian Tram \`e r, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, and Patrick McDaniel. Ensemble adversarial training: Attacks and defenses. arXiv preprint arXiv:1705.07204, 2017
-
[45]
Shiqi Wang, Huan Zhang, Kaidi Xu, Xue Lin, Suman Jana, Cho-Jui Hsieh, and J Zico Kolter. Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network robustness verification. Advances in Neural Information Processing Systems, 34: 0 29909--29921, 2021
work page 2021
-
[46]
Improving adversarial robustness requires revisiting misclassified examples
Yisen Wang, Difan Zou, Jinfeng Yi, James Bailey, Xingjun Ma, and Quanquan Gu. Improving adversarial robustness requires revisiting misclassified examples. In ICLR, 2020
work page 2020
-
[47]
Better diffusion models further improve adversarial training
Zekai Wang, Tianyu Pang, Chao Du, Min Lin, Weiwei Liu, and Shuicheng Yan. Better diffusion models further improve adversarial training. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machin...
work page 2023
-
[48]
Scaling provable adversarial defenses
Eric Wong, Frank Schmidt, Jan Hendrik Metzen, and J Zico Kolter. Scaling provable adversarial defenses. Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[49]
Adversarial weight perturbation helps robust generalization
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. Adversarial weight perturbation helps robust generalization. Advances in Neural Information Processing Systems, 33: 0 2958--2969, 2020
work page 2020
-
[50]
Jiancong Xiao, Zeyu Qin, Yanbo Fan, Baoyuan Wu, Jue Wang, and Zhi-Quan Luo. Adaptive smoothness-weighted adversarial training for multiple perturbations with its stability analysis. arXiv preprint arXiv:2210.00557, 2022
-
[51]
Mixture of robust experts (more): A robust denoising method towards multiple perturbations
Kaidi Xu, Chenan Wang, Hao Cheng, Bhavya Kailkhura, Xue Lin, and Ryan Goldhahn. Mixture of robust experts (more): A robust denoising method towards multiple perturbations. arXiv preprint arXiv:2104.10586, 2021
-
[52]
Lot: Layer-wise orthogonal training on improving l2 certified robustness
Xiaojun Xu, Linyi Li, and Bo Li. Lot: Layer-wise orthogonal training on improving l2 certified robustness. Advances in Neural Information Processing Systems, 35: 0 18904--18915, 2022
work page 2022
-
[53]
Provable defense against geometric transformations
Rem Yang, Jacob Laurel, Sasa Misailovic, and Gagandeep Singh. Provable defense against geometric transformations. arXiv preprint arXiv:2207.11177, 2022
-
[54]
Theoretically principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. In International conference on machine learning, pages 7472--7482. PMLR, 2019 a
work page 2019
-
[55]
Efficient Neural Network Robustness Certification with General Activation Functions
Huan Zhang, Tsui-Wei Weng, Pin-Yu Chen, Cho-Jui Hsieh, and Luca Daniel. Efficient neural network robustness certification with general activation functions. Advances in Neural Information Processing Systems, 31: 0 4939--4948, 2018. URL https://arxiv.org/pdf/1811.00866.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
Towards stable and efficient training of verifiably robust neural networks
Huan Zhang, Hongge Chen, Chaowei Xiao, Sven Gowal, Robert Stanforth, Bo Li, Duane Boning, and Cho-Jui Hsieh. Towards stable and efficient training of verifiably robust neural networks. arXiv preprint arXiv:1906.06316, 2019 b
-
[57]
Geometry-aware instance-reweighted adversarial training
Jingfeng Zhang, Jianing Zhu, Gang Niu, Bo Han, Masashi Sugiyama, and Mohan Kankanhalli. Geometry-aware instance-reweighted adversarial training. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=iAX0l6Cz8ub
work page 2021
-
[58]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[59]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[60]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.