Disentangling Popularity and Quality: An Edge Classification Approach for Fair Recommendation
Pith reviewed 2026-05-23 06:24 UTC · model grok-4.3
The pith
A GNN-based recommender adds edge classification to separate popularity bias from genuine item quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
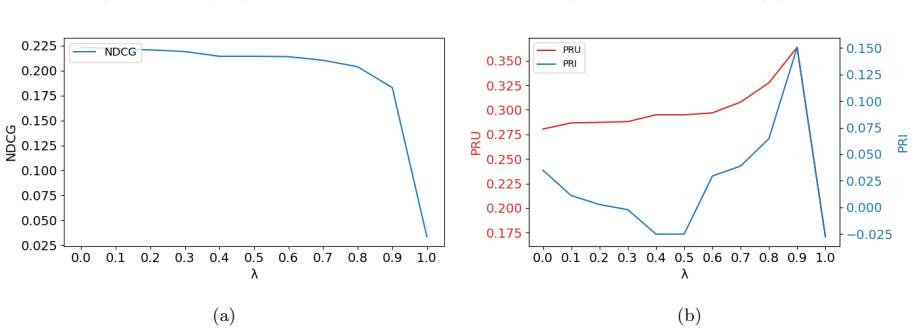
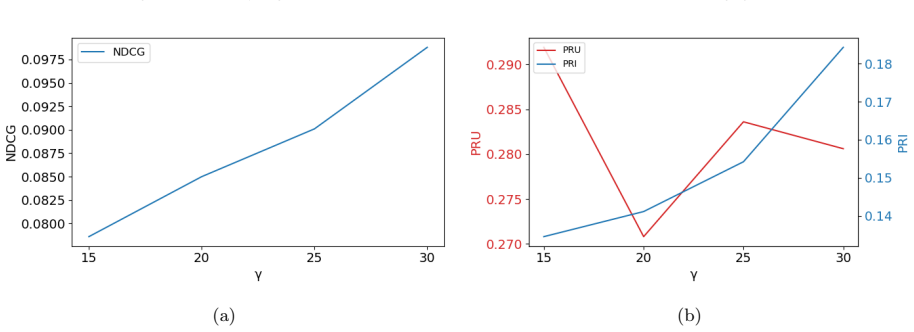
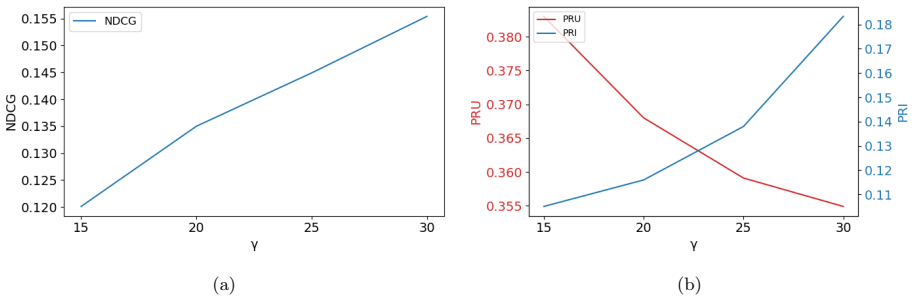
The central claim is that an edge classification technique inside a GNN-based recommendation model can differentiate between popularity bias and genuine quality disparities among items; combined with cost-sensitive learning that adjusts misclassification penalties, this prevents underrepresented yet relevant items from being unfairly disregarded and yields fairness gains of approximately 32 percent on average while accuracy remains comparable to state-of-the-art approaches.
What carries the argument
An edge classification head added to the GNN that labels observed interactions to disentangle popularity bias from quality, paired with cost-sensitive learning to reweight penalties for rare relevant items.
If this is right
- Long-tail items receive exposure based on inferred quality rather than uniform treatment.
- Fairness metrics improve across multiple evaluation scenarios without large accuracy drops.
- The model avoids over-penalizing relevant but low-interaction items through adjusted loss weights.
- Disentanglement happens at the edge level during training rather than through post-processing.
Where Pith is reading between the lines
- If the separation succeeds from graph structure alone, the same edge-classification idea could transfer to other graph tasks where observed links mix multiple latent causes.
- Explicit quality signals, when available, could serve as a validation set to measure how well the classifier recovers ground-truth quality distinctions.
- Treating fairness as an edge-labeling problem suggests that other bias types in recommenders might be addressable by similar auxiliary classification heads.
Load-bearing premise
The interaction graph alone supplies enough signal for the edge classifier to reliably separate bias-driven edges from quality-driven ones without any external quality labels or bias annotations.
What would settle it
Collect independent quality ratings for a set of items and test whether the model's edge classifications match those ratings more closely than a simple popularity baseline or random assignment.
Figures




read the original abstract
Graph neural networks (GNNs) have proven to be an effective tool for enhancing the performance of recommender systems. However, these systems often suffer from popularity bias, leading to an unfair advantage for frequently interacted items, while overlooking high-quality but less popular items. In this paper, we propose a GNN-based recommendation model that disentangles popularity and quality to address this issue. Unlike existing methods that treat all long-tail items uniformly, our approach introduces an edge classification technique to differentiate between popularity bias and genuine quality disparities among items. Furthermore, it uses cost-sensitive learning to adjust the misclassification penalties, ensuring that underrepresented yet relevant items are not unfairly disregarded. Experimental results demonstrate improvements in fairness metrics by approximately $32\%$ on average across different scenarios while maintaining competitive accuracy, with only minor variations compared to state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a GNN-based recommender that introduces an auxiliary edge-classification head to disentangle popularity bias from genuine quality differences among items, combined with cost-sensitive learning to re-weight misclassification penalties for underrepresented items. It claims this yields approximately 32% average improvement in fairness metrics across scenarios while preserving competitive accuracy relative to state-of-the-art methods.
Significance. A method that can reliably separate popularity-driven interactions from quality-driven ones inside the observed graph would be a meaningful advance over uniform long-tail treatments in fair recommendation. The reported fairness gains, if reproducible and attributable to the claimed mechanism rather than degree re-weighting, would be of interest to the IR community.
major comments (2)
- [Abstract / §3] Abstract and §3 (model description): the edge-classification head is asserted to differentiate 'popularity bias' from 'genuine quality disparities' using only the interaction graph, yet no external quality labels, bias annotations, temporal signals, or other supervision are described. Cost-sensitive learning re-weights an existing loss but does not supply the missing ground-truth signal; without it the head cannot be shown to perform the claimed disentanglement rather than recovering degree or embedding magnitude.
- [§4] §4 (experiments): the abstract states 'experimental results demonstrate improvements in fairness metrics by approximately 32% on average,' but the manuscript provides no dataset statistics, baseline implementations, ablation isolating the edge-classification component, or statistical significance tests. This prevents verification that the reported gains are load-bearing on the disentanglement claim rather than on other modeling choices.
minor comments (1)
- [§3] Notation for the edge-classification loss and the cost-sensitive weighting should be introduced with explicit definitions before the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. Below we respond point-by-point to the two major comments, indicating where revisions will be incorporated. We believe the core technical contribution remains valid but agree that additional clarity and experimental rigor are warranted.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (model description): the edge-classification head is asserted to differentiate 'popularity bias' from 'genuine quality disparities' using only the interaction graph, yet no external quality labels, bias annotations, temporal signals, or other supervision are described. Cost-sensitive learning re-weights an existing loss but does not supply the missing ground-truth signal; without it the head cannot be shown to perform the claimed disentanglement rather than recovering degree or embedding magnitude.
Authors: The edge-classification head is trained end-to-end as an auxiliary task on the observed interaction graph; the binary classification objective encourages the GNN embeddings to separate edges whose presence is better explained by item popularity versus those better explained by user-item affinity after controlling for degree. Cost-sensitive re-weighting is applied specifically to the minority (under-represented) class within this auxiliary loss. We acknowledge that, absent external quality annotations, the separation is inferred rather than directly supervised. The fairness gains reported in the experiments are consistent with the intended mechanism, but we agree a stronger defense requires additional analysis. In the revision we will (i) add a dedicated paragraph in §3 clarifying the self-supervised nature of the disentanglement and its assumptions, (ii) include a visualization of edge-classification outputs versus item degree, and (iii) add an explicit comparison against a pure degree-reweighting baseline to isolate the contribution of the learned classification. revision: partial
-
Referee: [§4] §4 (experiments): the abstract states 'experimental results demonstrate improvements in fairness metrics by approximately 32% on average,' but the manuscript provides no dataset statistics, baseline implementations, ablation isolating the edge-classification component, or statistical significance tests. This prevents verification that the reported gains are load-bearing on the disentanglement claim rather than on other modeling choices.
Authors: We apologize that the experimental section did not make these elements sufficiently prominent. Dataset statistics appear in §4.1, baseline descriptions and hyper-parameter settings in §4.2, and component ablations (including removal of the edge-classification head) in §4.3. Nevertheless, we agree that statistical significance testing and a more targeted ablation isolating the edge-classification head are required to substantiate the 32 % fairness claim. In the revised manuscript we will (i) report per-dataset statistics in a dedicated table, (ii) add paired t-tests or Wilcoxon tests with p-values for all fairness and accuracy metrics, and (iii) expand the ablation study to explicitly quantify the marginal contribution of the edge-classification head versus cost-sensitive learning alone. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces an edge classification technique inside the GNN plus cost-sensitive learning as modeling components to address popularity bias. No quoted equations, self-citations, or steps reduce the claimed disentanglement of popularity versus quality to a definition in terms of its own fitted outputs, a renamed known result, or a load-bearing self-citation chain. The derivation remains self-contained with independent architectural choices; any limitations in training signal are a separate methodological concern rather than circularity by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
PBiLoss: Popularity-Aware Regularization to Improve Fairness in Graph-Based Recommender Systems
PBiLoss is a model-agnostic regularization loss with PopPos and PopNeg sampling that reduces popularity bias metrics PRU and PRI by up to 10% in GNN recommenders while preserving accuracy on datasets like MovieLens.
Reference graph
Works this paper leans on
-
[1]
Graph Convolutional Matrix Completion
R. v. d. Berg, T. N. Kipf, and M. Welling, “Graph convolutional matrix completion,” arXiv preprint arXiv:1706.02263, 2017. 17
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Half a decade of graph convolutional networks,
M. H. Chehreghani, “Half a decade of graph convolutional networks,” Nat. Mach. Intell. , vol. 4, no. 3, pp. 192–193, 2022. [Online]. Available: https://doi.org/10.1038/s42256-022-00466-8
-
[3]
Content augmented graph neural networks,
F. Gholamzadeh Nasrabadi, A. Kashani, P. Zahedi, and M. Haghir Chehreghani, “Content augmented graph neural networks,” ACM Trans. Web, Oct. 2024, just Accepted. [Online]. Available: https://doi.org/10.1145/3700790
-
[4]
Lightgcn: Simplifying and powering graph convolution network for recommendation,
X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, “Lightgcn: Simplifying and powering graph convolution network for recommendation,” in Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , 2020, pp. 639–648
work page 2020
-
[5]
Graph convolutional neural networks for web-scale recommender systems,
R. Ying, R. He, K. Chen, P. Eksombatchai, W. L. Hamilton, and J. Leskovec, “Graph convolutional neural networks for web-scale recommender systems,” in Proceedings of the 24th ACM SIGKDD inter- national conference on knowledge discovery & data mining , 2018, pp. 974–983
work page 2018
-
[6]
BPR: Bayesian Personalized Ranking from Implicit Feedback
S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme, “Bpr: Bayesian personalized ranking from implicit feedback,” arXiv preprint arXiv:1205.2618 , 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[7]
Neural graph collaborative filtering,
X. Wang, X. He, M. Wang, F. Feng, and T.-S. Chua, “Neural graph collaborative filtering,” in Pro- ceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval, 2019, pp. 165–174
work page 2019
-
[8]
Dgrec: Graph neural network for recommendation with diversified embedding generation,
L. Yang, S. Wang, Y. Tao, J. Sun, X. Liu, P. S. Yu, and T. Wang, “Dgrec: Graph neural network for recommendation with diversified embedding generation,” in Proceedings of the Sixteenth ACM Interna- tional Conference on Web Search and Data Mining , 2023, pp. 661–669
work page 2023
-
[9]
Disentangled graph collaborative filter- ing,
X. Wang, H. Jin, A. Zhang, X. He, T. Xu, and T.-S. Chua, “Disentangled graph collaborative filter- ing,” in Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval, 2020, pp. 1001–1010
work page 2020
-
[10]
Popularity bias is not always evil: Disentangling benign and harmful bias for recommendation,
Z. Zhao, J. Chen, S. Zhou, X. He, X. Cao, F. Zhang, and W. Wu, “Popularity bias is not always evil: Disentangling benign and harmful bias for recommendation,” IEEE Transactions on Knowledge and Data Engineering, 2022
work page 2022
-
[11]
In- vestigating accuracy-novelty performance for graph-based collaborative filtering,
M. Zhao, L. Wu, Y. Liang, L. Chen, J. Zhang, Q. Deng, K. Wang, X. Shen, T. Lv, and R. Wu, “In- vestigating accuracy-novelty performance for graph-based collaborative filtering,” in 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , 2022, pp. 50–59
work page 2022
-
[12]
Adaptive popularity debiasing aggregator for graph collaborative filtering,
H. Zhou, H. Chen, J. Dong, D. Zha, C. Zhou, and X. Huang, “Adaptive popularity debiasing aggregator for graph collaborative filtering,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , 2023, pp. 7–17
work page 2023
-
[13]
Popularity-opportunity bias in collab- orative filtering,
Z. Zhu, Y. He, X. Zhao, Y. Zhang, J. Wang, and J. Caverlee, “Popularity-opportunity bias in collab- orative filtering,” in Proceedings of the 14th ACM International Conference on Web Search and Data Mining, 2021, pp. 85–93
work page 2021
-
[14]
Heterophily-aware fair recommendation using graph convolu- tional networks,
N. Gholinejad and M. H. Chehreghani, “Heterophily-aware fair recommendation using graph convolu- tional networks,” arXiv preprint arXiv:2402.03365 , 2024. 18
-
[15]
Addressing marketing bias in product recommendations,
M. Wan, J. Ni, R. Misra, and J. McAuley, “Addressing marketing bias in product recommendations,” in Proceedings of the 13th international conference on web search and data mining , 2020, pp. 618–626
work page 2020
-
[16]
User-oriented fairness in recommendation,
Y. Li, H. Chen, Z. Fu, Y. Ge, and Y. Zhang, “User-oriented fairness in recommendation,” in Proceedings of the web conference 2021 , 2021, pp. 624–632
work page 2021
-
[17]
Explainable fairness in recommendation,
Y. Ge, J. Tan, Y. Zhu, Y. Xia, J. Luo, S. Liu, Z. Fu, S. Geng, Z. Li, and Y. Zhang, “Explainable fairness in recommendation,” in Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , 2022, pp. 681–691
work page 2022
-
[18]
Achieving counterfactual fairness for causal bandit,
W. Huang, L. Zhang, and X. Wu, “Achieving counterfactual fairness for causal bandit,” in Proceedings of the AAAI conference on artificial intelligence , vol. 36, no. 6, 2022, pp. 6952–6959
work page 2022
-
[19]
Graph trend filtering networks for recommen- dation,
W. Fan, X. Liu, W. Jin, X. Zhao, J. Tang, and Q. Li, “Graph trend filtering networks for recommen- dation,” in Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , 2022, pp. 112–121
work page 2022
-
[20]
Fgcr: Fused graph context-aware recommender system,
T. Wei and T. W. Chow, “Fgcr: Fused graph context-aware recommender system,” Knowledge-Based Systems, vol. 277, p. 110806, 2023
work page 2023
-
[21]
How powerful is graph filtering for recommendation,
S. Peng, X. Liu, K. Sugiyama, and T. Mine, “How powerful is graph filtering for recommendation,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , 2024, pp. 2388–2399
work page 2024
-
[22]
Simplifying graph convolutional networks,
F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in International conference on machine learning . PMLR, 2019, pp. 6861–6871
work page 2019
-
[23]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
L. Chen, L. Wu, R. Hong, K. Zhang, and M. Wang, “Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach,” in AAAI conference on artificial intelligence , vol. 34, no. 01, 2020, pp. 27–34
work page 2020
-
[25]
Less is more: Removing redundancy of graph convolutional networks for recommendation,
S. Peng, K. Sugiyama, and T. Mine, “Less is more: Removing redundancy of graph convolutional networks for recommendation,” ACM Transactions on Information Systems , vol. 42, no. 3, pp. 1–26, 2024
work page 2024
-
[26]
M. D. Ekstrand, M. Tian, I. M. Azpiazu, J. D. Ekstrand, O. Anuyah, D. McNeill, and M. S. Pera, “All the cool kids, how do they fit in?: Popularity and demographic biases in recommender evaluation and effectiveness,” in Conference on fairness, accountability and transparency . PMLR, 2018, pp. 172–186
work page 2018
-
[27]
B. Rastegarpanah, K. P. Gummadi, and M. Crovella, “Fighting fire with fire: Using antidote data to improve polarization and fairness of recommender systems,” in Proceedings of the twelfth ACM international conference on web search and data mining , 2019, pp. 231–239
work page 2019
-
[28]
Improving recom- mendation fairness via data augmentation,
L. Chen, L. Wu, K. Zhang, R. Hong, D. Lian, Z. Zhang, J. Zhou, and M. Wang, “Improving recom- mendation fairness via data augmentation,” in Proceedings of the ACM Web Conference 2023 , 2023, pp. 1012–1020. 19
work page 2023
-
[29]
Self-supervised graph learning for recom- mendation,
J. Wu, X. Wang, F. Feng, X. He, L. Chen, J. Lian, and X. Xie, “Self-supervised graph learning for recom- mendation,” in 44th international ACM SIGIR conference on research and development in information retrieval, 2021, pp. 726–735
work page 2021
-
[30]
Auditing consumer-and producer-fairness in graph collaborative filtering,
V. W. Anelli, Y. Deldjoo, T. Di Noia, D. Malitesta, V. Paparella, and C. Pomo, “Auditing consumer-and producer-fairness in graph collaborative filtering,” in European Conference on Information Retrieval . Springer, 2023, pp. 33–48
work page 2023
-
[31]
How graph convolutions amplify popularity bias for recommendation?
J. Chen, J. Wu, J. Chen, X. Xin, Y. Li, and X. He, “How graph convolutions amplify popularity bias for recommendation?” Frontiers of Computer Science , vol. 18, no. 5, p. 185603, 2024
work page 2024
-
[32]
Unbiased pairwise learning from implicit feedback,
Y. Saito, “Unbiased pairwise learning from implicit feedback,” in NeurIPS 2019 Workshop on Causal Machine Learning, 2019
work page 2019
-
[33]
Debiased explainable pairwise ranking from implicit feed- back,
K. Damak, S. Khenissi, and O. Nasraoui, “Debiased explainable pairwise ranking from implicit feed- back,” in Proceedings of the 15th ACM Conference on Recommender Systems , 2021, pp. 321–331
work page 2021
-
[34]
The foundations of cost-sensitive learning,
C. Elkan, “The foundations of cost-sensitive learning,” in International joint conference on artificial intelligence, vol. 17, no. 1. Lawrence Erlbaum Associates Ltd, 2001, pp. 973–978
work page 2001
-
[35]
Cost-sensitive learning methods for imbalanced data,
N. Thai-Nghe, Z. Gantner, and L. Schmidt-Thieme, “Cost-sensitive learning methods for imbalanced data,” in The 2010 International joint conference on neural networks (IJCNN) . IEEE, 2010, pp. 1–8
work page 2010
-
[36]
Are graph augmentations necessary? simple graph contrastive learning for recommendation,
J. Yu, H. Yin, X. Xia, T. Chen, L. Cui, and Q. V. H. Nguyen, “Are graph augmentations necessary? simple graph contrastive learning for recommendation,” in Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval , 2022, pp. 1294–1303
work page 2022
-
[37]
Improving recommendation lists through topic diversification,
C.-N. Ziegler, S. M. McNee, J. A. Konstan, and G. Lausen, “Improving recommendation lists through topic diversification,” in Proceedings of the 14th international conference on World Wide Web , 2005, pp. 22–32
work page 2005
-
[38]
R. He and J. McAuley, “Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering,” in proceedings of the 25th international conference on world wide web , 2016, pp. 507–517. 20
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.