Copyright Protection for Large Language Models: A Survey of Methods, Challenges, and Trends
Pith reviewed 2026-05-18 22:42 UTC · model grok-4.3
The pith
This survey unifies model watermarking under fingerprinting and introduces transfer and removal techniques for LLM copyright protection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
This work presents the first comprehensive survey focused on model fingerprinting for LLM copyright protection, adopts a unified terminology incorporating model watermarking into fingerprinting, and introduces techniques for fingerprint transfer and removal.
What carries the argument
The unified fingerprinting framework that treats model watermarking as one instance of embedding ownership signals into LLMs and adds categories for transferring and removing those signals.
If this is right
- Researchers gain a single set of terms and categories to compare model fingerprinting methods consistently.
- Fingerprint transfer techniques become available as a distinct research direction for moving ownership marks across models.
- Fingerprint removal methods provide a basis for testing how robust the marks remain against deliberate erasure.
- Standard metrics for effectiveness, harmlessness, robustness, stealthiness, and reliability allow uniform assessment of new proposals.
Where Pith is reading between the lines
- The unified terms could reduce miscommunication when courts or regulators discuss ownership of trained models.
- Transfer and removal ideas might apply directly to other large generative models such as image or audio systems.
- Empirical tests on open models could check whether the summarized techniques hold up at the scale of current production LLMs.
Load-bearing premise
The survey assumes its chosen papers represent the full field and that the new groupings for fingerprint transfer and removal match actual practical differences without leaving out important recent work.
What would settle it
Discovery of several recent papers on LLM model protection whose methods fall outside the survey's categories or contradict the proposed unified terminology would show the coverage and unification are incomplete.
Figures







read the original abstract
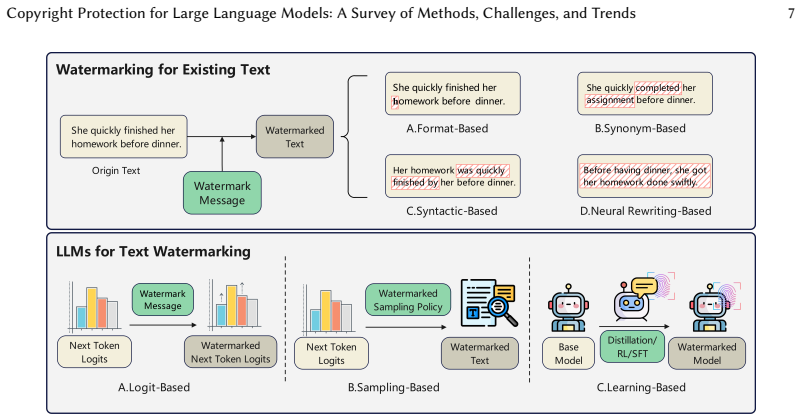
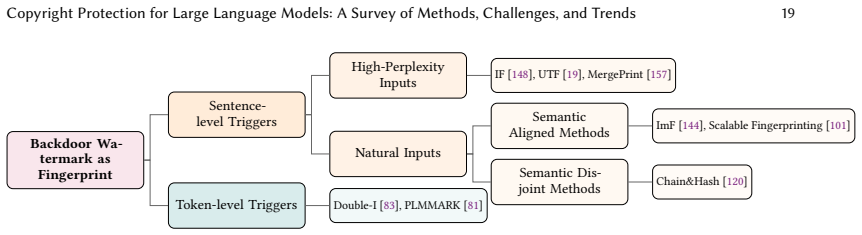
Copyright protection for large language models is of critical importance, given their substantial development costs, proprietary value, and potential for misuse. Existing surveys have predominantly focused on techniques for tracing LLM-generated content-namely, text watermarking-while a systematic exploration of methods for protecting the models themselves (i.e., model watermarking and model fingerprinting) remains absent. Moreover, the relationships and distinctions among text watermarking, model watermarking, and model fingerprinting have not been comprehensively clarified. This work presents a comprehensive survey of the current state of LLM copyright protection technologies, with a focus on model fingerprinting, covering the following aspects: (1) clarifying the conceptual connection from text watermarking to model watermarking and fingerprinting, and adopting a unified terminology that incorporates model watermarking into the broader fingerprinting framework; (2) providing an overview and comparison of diverse text watermarking techniques, highlighting cases where such methods can function as model fingerprinting; (3) systematically categorizing and comparing existing model fingerprinting approaches for LLM copyright protection; (4) presenting, for the first time, techniques for fingerprint transfer and fingerprint removal; (5) summarizing evaluation metrics for model fingerprints, including effectiveness, harmlessness, robustness, stealthiness, and reliability; and (6) discussing open challenges and future research directions. This survey aims to offer researchers a thorough understanding of both text watermarking and model fingerprinting technologies in the era of LLMs, thereby fostering further advances in protecting their intellectual property.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey claims to be the first comprehensive review focused on model fingerprinting for LLM copyright protection. It clarifies conceptual connections from text watermarking to model watermarking and fingerprinting, adopts a unified terminology subsuming model watermarking under fingerprinting, provides an overview and comparison of text watermarking techniques (including cases where they serve as model fingerprints), systematically categorizes and compares model fingerprinting approaches, presents techniques for fingerprint transfer and removal, summarizes evaluation metrics (effectiveness, harmlessness, robustness, stealthiness, reliability), and discusses open challenges and future directions.
Significance. If the literature selection proves representative and the proposed unification plus transfer/removal categories reflect genuine practical distinctions, the survey would offer a valuable standardized framework for a fast-moving area of LLM intellectual property protection. The explicit treatment of transfer and removal techniques, along with the metric summary, could help researchers avoid reinventing methods and focus on unresolved robustness and stealth issues.
major comments (2)
- [Abstract (1) and unification section] Abstract point (1) and the corresponding unification section: subsuming model watermarking under the fingerprinting framework is presented as a clarifying contribution, but the manuscript does not provide a side-by-side comparison showing that prior literature already treats them as overlapping or that the new terminology resolves concrete ambiguities in cited works; without this, the unification risks appearing post-hoc rather than load-bearing for the systematic categorization that follows.
- [Abstract (4) and transfer/removal sections] Abstract point (4) on fingerprint transfer and removal: these are claimed as presented 'for the first time,' yet the categorization into distinct transfer versus removal techniques lacks an explicit decision tree or decision criteria that would demonstrate the categories are non-overlapping in practice; a few missed 2024 black-box extraction or adversarial removal papers could collapse the claimed systematic coverage.
minor comments (2)
- [Abstract and introduction] The abstract states the survey covers 'diverse text watermarking techniques' but does not list the exact inclusion criteria or search strings used; adding a short methods subsection would strengthen reproducibility claims for a survey.
- [Metrics summary section] Evaluation metrics are summarized in point (5), but the manuscript should cross-reference specific cited papers to each metric (e.g., which works report stealthiness under what threat model) to avoid vague aggregation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and indicate the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract (1) and unification section] Abstract point (1) and the corresponding unification section: subsuming model watermarking under the fingerprinting framework is presented as a clarifying contribution, but the manuscript does not provide a side-by-side comparison showing that prior literature already treats them as overlapping or that the new terminology resolves concrete ambiguities in cited works; without this, the unification risks appearing post-hoc rather than load-bearing for the systematic categorization that follows.
Authors: We appreciate this observation. The unification section grounds the subsumption in conceptual analysis and examples from the literature where model-level protections are described with overlapping goals of ownership verification. To strengthen the presentation and demonstrate that the framework addresses real terminological inconsistencies, we will add an explicit side-by-side comparison table in the revised unification section. The table will summarize terminology usage across representative prior works, highlight overlaps, and show how the unified fingerprinting framework provides consistent distinctions that support the subsequent systematic categorization. revision: yes
-
Referee: [Abstract (4) and transfer/removal sections] Abstract point (4) on fingerprint transfer and removal: these are claimed as presented 'for the first time,' yet the categorization into distinct transfer versus removal techniques lacks an explicit decision tree or decision criteria that would demonstrate the categories are non-overlapping in practice; a few missed 2024 black-box extraction or adversarial removal papers could collapse the claimed systematic coverage.
Authors: We agree that explicit decision criteria would better demonstrate the non-overlapping nature of the categories. In the revised manuscript we will add a dedicated subsection with decision criteria and a simple decision tree: techniques are classified as transfer when their primary objective is to propagate an existing fingerprint to new or adapted models, and as removal when the objective is to eliminate or evade detection of the fingerprint. This framework is derived from the functional goals and mechanisms described in the surveyed works. Regarding coverage, the survey reflects a systematic literature search through mid-2024; we will incorporate any additional relevant 2024 papers on black-box extraction or adversarial removal that fit the scope to ensure the categorization remains robust. revision: yes
Circularity Check
No significant circularity in survey synthesis or unification
full rationale
This paper is a literature review that synthesizes existing work on LLM copyright protection techniques. It clarifies relationships among text watermarking, model watermarking, and model fingerprinting, adopts a unified terminology by subsuming the former under fingerprinting, and categorizes approaches including new sections on transfer and removal techniques. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided abstract or structure. Claims such as 'first comprehensive survey' and 'presenting for the first time' rest on literature coverage and organizational synthesis rather than reducing to self-definitional inputs, self-citation chains, or renamed results by construction. Any self-citations serve as references to prior independent work and are not load-bearing for the survey's core structure. The analysis chain is self-contained as a review without tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing LLM copyright protection methods can be systematically categorized and compared under a unified fingerprinting framework that includes model watermarking.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.lean (and Cost/FunctionalEquation.lean)reality_from_one_distinction; washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This work presents a comprehensive survey ... with a focus on model fingerprinting, covering ... clarifying the conceptual connection from text watermarking to model watermarking and fingerprinting, and adopting a unified terminology ... techniques for fingerprint transfer and fingerprint removal ... evaluation metrics ... effectiveness, harmlessness, robustness, stealthiness, and reliability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
RLSpoofer: A Lightweight Evaluator for LLM Watermark Spoofing Resilience
RLSpoofer trains a 4B model on 100 watermarked paraphrase pairs to spoof PF watermarks at 62% success rate, far exceeding baselines trained on up to 10,000 samples.
-
LLM DNA: Tracing Model Evolution via Functional Representations
LLM DNA is introduced as a low-dimensional bi-Lipschitz functional representation proven to satisfy inheritance and genetic determinism, with a training-free extraction pipeline tested on 305 models to reveal relation...
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi and Mario Fritz. 2021. Adversarial watermarking transformer: Towards tracing text provenance with data hiding. In 2021 IEEE Symposium on Security and Privacy (SP) . IEEE, 121–140
work page 2021
-
[2]
Yossi Adi, Carsten Baum, Moustapha Cisse, Benny Pinkas, and Joseph Keshet. 2018. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In 27th USENIX security symposium (USENIX Security 18). 1615–1631
work page 2018
-
[3]
Saeif Alhazbi, Ahmed Hussain, Gabriele Oligeri, and Panos Papadimitratos. 2025. Llms have rhythm: Fingerprinting large language models using inter-token times and network traffic analysis. IEEE Open Journal of the Communications Society (2025)
work page 2025
-
[4]
Mohammed Hazim Alkawaz, Ghazali Sulong, Tanzila Saba, Abdulaziz S Almazyad, and Amjad Rehman. 2016. Concise analysis of current text automation and watermarking approaches. Security and Communication Networks 9, 18 (2016), 6365–6378
work page 2016
-
[5]
Soliman, and Amr Mohamed AbdelAziz
Walid Mohamed Aly, Taysir Hassan A. Soliman, and Amr Mohamed AbdelAziz. 2025. An Evaluation of Large Language Models on Text Summarization Tasks Using Prompt Engineering Techniques. arXiv:2507.05123 [cs.CL] https://arxiv.org/abs/2507.05123
-
[6]
Anthropic. 2025. Claude. https://claude.ai/ Accessed: 2025
work page 2025
-
[7]
Apache Software Foundation. 2025. Apache License, Version 2.0. https://www.apache.org/licenses/LICENSE-2.0 Accessed: 2025
work page 2025
- [8]
-
[9]
Mikhail J Atallah, Victor Raskin, Michael Crogan, Christian Hempelmann, Florian Kerschbaum, Dina Mohamed, and Sanket Naik. 2001. Natural language watermarking: Design, analysis, and a proof-of-concept implementation. In Information Hiding: 4th International Workshop, IH 2001 Pittsburgh, PA, USA, April 25–27, 2001 Proceedings 4 . Springer, 185–200
work page 2001
-
[10]
Xiaofan Bai, Chaoxiang He, Xiaojing Ma, Bin Benjamin Zhu, and Hai Jin. 2024. Intersecting-boundary-sensitive fingerprinting for tampering detection of DNN models. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24). JMLR.org, Article 2236, 12 pages
work page 2024
-
[11]
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv:2302.04023 [cs.CL] https://arxiv.org/abs/2302.04023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [12]
- [13]
-
[14]
Jean Petit Bikim, Carick Appolinaire Atezong Ymele, Azanzi Jiomekong, Allard Oelen, Gollam Rabby, Jennifer D’Souza, and Sören Auer. 2024. Leveraging GPT Models For Semantic Table Annotation. In SemTab@ISWC (CEUR Workshop Proceedings, Vol. 3889). 43–53
work page 2024
- [15]
-
[16]
Adam Block, Ayush Sekhari, and Alexander Rakhlin. 2025. Robust and Efficient Watermarking of Large Language Models Using Error Correction Codes. Proceedings on Privacy Enhancing Technologies (PoPETs) 2025 (2025)
work page 2025
-
[17]
Franziska Boenisch. 2021. A systematic review on model watermarking for neural networks. Frontiers in big Data 4 (2021), 729663
work page 2021
-
[18]
Maxemchuk, and Lawrence O’Gorman
Jack T Brassil, Steven Low, Nicholas F. Maxemchuk, and Lawrence O’Gorman. 1995. Electronic marking and identification techniques to discourage document copying. IEEE Journal on Selected Areas in Communications 13, 8 (1995), 1495–1504
work page 1995
- [19]
-
[20]
Xiaoyu Cao, Jinyuan Jia, and Neil Zhenqiang Gong. 2019. IPGuard: Protecting Intellectual Property of Deep Neural Networks via Fingerprinting the Classification Boundary. arXiv e-prints , Article arXiv:1910.12903 (Oct. 2019), arXiv:1910.12903 pages. arXiv:1910.12903 [cs.CR] doi:10.48550/arXiv.1910.12903
-
[21]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21) . 2633–2650
work page 2021
-
[22]
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St John, Noah Constant, Mario Guajardo- Cespedes, Steve Yuan, Chris Tar, et al . 2018. Universal sentence encoder for English. In Proceedings of the 2018 conference on empirical methods in natural language processing: system demonstrations . 169–174. , Vol. 1, No. 1, Article . Public...
work page 2018
-
[23]
Jialuo Chen, Jingyi Wang, Tinglan Peng, Youcheng Sun, Peng Cheng, Shouling Ji, Xingjun Ma, Bo Li, and Dawn Song
-
[24]
In 2022 IEEE symposium on security and privacy (SP)
Copy, right? a testing framework for copyright protection of deep learning models. In 2022 IEEE symposium on security and privacy (SP) . IEEE, 824–841
work page 2022
-
[25]
Qiguang Chen, Mingda Yang, Libo Qin, Jinhao Liu, Zheng Yan, Jiannan Guan, Dengyun Peng, Yiyan Ji, Hanjing Li, Mengkang Hu, Yimeng Zhang, Yihao Liang, Yuhang Zhou, Jiaqi Wang, Zhi Chen, and Wanxiang Che. 2025. AI4Research: A Survey of Artificial Intelligence for Scientific Research. arXiv:2507.01903 [cs.CL] https://arxiv.org/ abs/2507.01903
-
[26]
Miranda Christ, Sam Gunn, and Or Zamir. 2024. Undetectable watermarks for language models. In The Thirty Seventh Annual Conference on Learning Theory . PMLR, 1125–1139
work page 2024
-
[27]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In Proceedings of NAACL-HLT. 2924–2936
work page 2019
-
[28]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord
-
[29]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Tianshuo Cong, Delong Ran, Zesen Liu, Xinlei He, Jinyuan Liu, Yichen Gong, Qi Li, Anyu Wang, and Xiaoyun Wang
-
[31]
arXiv preprint arXiv:2404.05188 (2024)
Have You Merged My Model? On The Robustness of Large Language Model IP Protection Methods Against Model Merging. arXiv preprint arXiv:2404.05188 (2024)
-
[32]
Creative Commons. 2025. Licenses. https://creativecommons.org/share-your-work/cclicenses/ Accessed: 2025
work page 2025
- [33]
-
[34]
Ioannis Dasoulas, Duo Yang, Xuemin Duan, and Anastasia Dimou. 2023. TorchicTab: Semantic Table Annotation with Wikidata and Language Models. In SemTab@ISWC (CEUR Workshop Proceedings, Vol. 3557). 21–37
work page 2023
-
[35]
Detecting Adversarial Examples via Neural Fingerprinting
Sumanth Dathathri, Stephan Zheng, Tianwei Yin, Richard M. Murray, and Yisong Yue. 2019. Detecting Adversarial Examples via Neural Fingerprinting. arXiv:1803.03870 [cs.LG] https://arxiv.org/abs/1803.03870
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. 2019. The commitmentbank: Investigating projection in naturally occurring discourse. In proceedings of Sinn und Bedeutung , Vol. 23. 107–124
work page 2019
-
[37]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 [cs.CL] https://arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[40]
Haonan Duan, Stephen Zhewen Lu, Caitlin Fiona Harrigan, Nishkrit Desai, Jiarui Lu, Michał Koziarski, Leonardo Cotta, and Chris J. Maddison. 2025. Measuring Scientific Capabilities of Language Models with a Systems Biology Dry Lab. arXiv:2507.02083 [cs.AI] https://arxiv.org/abs/2507.02083
-
[41]
Pierre Fernandez, Antoine Chaffin, Karim Tit, Vivien Chappelier, and Teddy Furon. 2023. Three bricks to consolidate watermarks for large language models. In 2023 IEEE international workshop on information forensics and security (WIFS). IEEE, 1–6
work page 2023
-
[42]
Pierre Fernandez, Guillaume Couairon, Teddy Furon, and Matthijs Douze. 2023. Functional Invariants to Watermark Large Transformers. In ICASSP 2023
work page 2023
-
[43]
Yu Fu, Deyi Xiong, and Yue Dong. 2024. Watermarking conditional text generation for ai detection: Unveiling challenges and a semantic-aware watermark remedy. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 38. 18003–18011
work page 2024
-
[44]
ZhenZhe Gao, Zhenjun Tang, Zhaoxia Yin, Baoyuan Wu, and Yue Lu. 2024. Fragile Model Watermark for integrity protection: leveraging boundary volatility and sensitive sample-pairing. In 2024 IEEE International Conference on Multimedia and Expo (ICME) . 1–6. doi:10.1109/ICME57554.2024.10688355
-
[45]
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B Dolan. 2007. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing . 1–9
work page 2007
-
[46]
Thibaud Gloaguen, Robin Staab, Nikola Jovanović, and Martin Vechev. 2025. Robust LLM Fingerprinting via Domain- Specific Watermarks. arXiv preprint arXiv:2505.16723 (2025). , Vol. 1, No. 1, Article . Publication date: September 2025. 34 Zhenhua Xu, Xubin Yue, Zhebo Wang, Qichen Liu, et al
-
[47]
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. 2024. Arcee’s MergeKit: A Toolkit for Merging Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , Franck Dernoncourt, Daniel Preoţiuc-Pietr...
-
[48]
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. 2016. Deep learning . Vol. 1. MIT press Cambridge
work page 2016
- [49]
-
[50]
Chenchen Gu, Xiang Lisa Li, Percy Liang, and Tatsunori Hashimoto. 2024. On the Learnability of Watermarks for Language Models. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum? id=9k0krNzvlV
work page 2024
- [51]
-
[52]
Martin Gubri, Dennis Thomas Ulmer, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. 2024. TRAP: Targeted Random Adversarial Prompt Honeypot for Black-Box Identification. InFindings of the Association for Computational Linguistics ACL 2024. Association for Computational Linguistics, 11496–11517
work page 2024
-
[53]
Jia Guo and Miodrag Potkonjak. 2018. Watermarking deep neural networks for embedded systems. In Proceedings of the International Conference on Computer-Aided Design (San Diego, California) (ICCAD ’18). Association for Computing Machinery, New York, NY, USA, Article 133, 8 pages. doi:10.1145/3240765.3240862
- [54]
-
[55]
Zhiwei He, Binglin Zhou, Hongkun Hao, Aiwei Liu, Xing Wang, Zhaopeng Tu, Zhuosheng Zhang, and Rui Wang
-
[56]
arXiv preprint arXiv:2402.14007 (2024)
Can watermarks survive translation? on the cross-lingual consistency of text watermark for large language models. arXiv preprint arXiv:2402.14007 (2024)
-
[57]
Jakub Ho’scilowicz, Pawel Popiolek, Jan Rudkowski, Jkedrzej Bieniasz, and Artur Janicki. 2024. Unconditional Token Forcing: Extracting Text Hidden Within LLM. In 2024 19th Conference on Computer Science and Intelligence Systems (FedCSIS). IEEE, 621–624
work page 2024
-
[58]
Abe Bohan Hou, Jingyu Zhang, Tianxing He, Yichen Wang, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, and Yulia Tsvetkov. 2023. Semstamp: A semantic watermark with paraphrastic robustness for text generation. arXiv preprint arXiv:2310.03991 (2023)
- [59]
-
[60]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[61]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [62]
-
[63]
Viet-Phi Huynh, Yoan Chabot, Thomas Labbé, Jixiong Liu, and Raphaël Troncy. 2022. From Heuristics to Language Models: A Journey Through the Universe of Semantic Table Interpretation with DAGOBAH. InSemTab@ISWC (CEUR Workshop Proceedings, Vol. 3320). 45–58
work page 2022
-
[64]
JaeYoung Hwang and SangHoon Oh. 2023. A brief survey of watermarks in generative AI. In 2023 14th International Conference on Information and Communication Technology Convergence (ICTC) . IEEE, 1157–1160
work page 2023
-
[65]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2022. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categorical Reparameterization with Gumbel-Softmax. In International Conference on Learning Representations . https://openreview.net/forum?id=rkE3y85ee
work page 2017
- [67]
-
[68]
Heng Jin, Chaoyu Zhang, Shanghao Shi, Wenjing Lou, and Y Thomas Hou. 2024. Proflingo: A fingerprinting-based intellectual property protection scheme for large language models. In 2024 IEEE Conference on Communications and Network Security (CNS). IEEE, 1–9
work page 2024
-
[69]
E. Jones et al . 2023. Automatically Auditing Large Language Models via Discrete Optimization. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research, Vol. 202), A. Krause et al. (Eds.). PMLR, 15307–15329. https://proceedings.mlr.press/v202/jones23a.html , Vol. 1, No. 1,...
work page 2023
-
[70]
Nurul Shamimi Kamaruddin, Amirrudin Kamsin, Lip Yee Por, and Hameedur Rahman. 2018. A review of text watermarking: theory, methods, and applications. IEEE Access 6 (2018), 8011–8028
work page 2018
-
[71]
Hamid Karimi and Jiliang Tang. 2020. Decision Boundary of Deep Neural Networks: Challenges and Opportunities. In Proceedings of the 13th International Conference on Web Search and Data Mining (Houston, TX, USA) (WSDM ’20). Association for Computing Machinery, New York, NY, USA, 919–920. doi:10.1145/3336191.3372186
-
[72]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8110–8119
work page 2020
-
[73]
Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. 2018. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 252–262
work page 2018
-
[74]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. In International Conference on Machine Learning . PMLR, 17061–17084
work page 2023
-
[75]
Papadopoulos, and Vasilis Efthymiou
Panagiotis Koletsis, Christos Panagiotopoulos, Georgios Th. Papadopoulos, and Vasilis Efthymiou. 2025. Relationship Detection on Tabular Data Using Statistical Analysis and Large Language Models. arXiv:2506.06371 [cs.CL] https: //arxiv.org/abs/2506.06371
-
[76]
Dezhang Kong, Shi Lin, Zhenhua Xu, Zhebo Wang, Minghao Li, Yufeng Li, Yilun Zhang, Hujin Peng, Zeyang Sha, Yuyuan Li, Changting Lin, Xun Wang, Xuan Liu, Ningyu Zhang, Chaochao Chen, Muhammad Khurram Khan, and Meng Han. 2025. A Survey of LLM-Driven AI Agent Communication: Protocols, Security Risks, and Defense Countermeasures. arXiv:2506.19676 [cs.CR] http...
-
[77]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. Similarity of neural network representations revisited. In International conference on machine learning . PMlR, 3519–3529
work page 2019
- [78]
- [79]
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.