Toward Robust and Efficient ML-Based GPU Caching for Modern Inference
Pith reviewed 2026-05-18 14:24 UTC · model grok-4.3
The pith
Learning-augmented LRU guarantees 1-consistency and O(k)-robustness for GPU inference caches with low overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose learning-augmented LRU, a deployment-oriented learning-augmented caching algorithm that guarantees 1-consistency and O(k)-robustness, incurs low time and space overhead, and maintains strong compatibility. We further build a GPU cache, called LCR, on top of learning-augmented LRU to benefit from its theoretical guarantees and translate them into practical performance. In experiments, LCR reduces P99 time-to-first-token by up to 28.3% on LLM workloads and increases throughput by up to 24.2% on DLRM workloads, with graceful degradation under poor predictions.
What carries the argument
Learning-augmented LRU, which integrates predictions into LRU eviction to achieve consistency and robustness guarantees while remaining efficient.
If this is right
- Cache performance approaches the offline optimum when predictions are accurate.
- Performance remains bounded relative to standard LRU under arbitrary prediction errors.
- Low time and space overhead allows deployment in existing GPU inference pipelines.
- The same guarantees apply across both LLM and DLRM inference workloads.
Where Pith is reading between the lines
- Production inference systems could adopt this as a safer way to incorporate ML predictors into caching.
- The robustness bound may allow the policy to replace LRU without additional monitoring of predictor quality.
- The integration technique could be tested on other base policies beyond LRU.
Load-bearing premise
The theoretical consistency and robustness properties can be realized in a practical implementation that meets strict time and space efficiency constraints on real GPU hardware.
What would settle it
Measure LCR performance under deliberately inaccurate predictions on GPU hardware and check whether it stays within the stated O(k) factor of plain LRU or violates the bounds.
Figures











read the original abstract
In modern GPU inference, cache efficiency remains a major bottleneck, and heuristic policies such as \textsc{LRU} can perform far worse than the offline optimum. Existing learning-based caching systems improve hit rates mainly through predictor design, but often follow learned predictions blindly, making performance unreliable when predictions are inaccurate. In contrast, emerging learning-augmented caching algorithms~\cite{pmlr-v80-lykouris18a,mitzenmacher2022algorithms} provide performance guarantees by carefully integrating predictions into caching policies, achieving both \emph{consistency} (near-optimality under perfect predictions) and \emph{robustness} (bounded worst-case performance under prediction errors). However, deployment remains challenging. A practical algorithm should satisfy strict time and space efficiency constraints, which some theoretical work overlooks, while also incurring low deployment overhead. We propose learning-augmented LRU, a deployment-oriented learning-augmented caching algorithm that guarantees \emph{1-consistency} and \emph{$O(k)$-robustness}, incurs low time and space overhead, and maintains strong compatibility. We further build a GPU cache, called \textsc{LCR}, on top of learning-augmented LRU to benefit from its theoretical guarantees and translate them into practical performance. In experiments, \textsc{LCR} reduces P99 time-to-first-token (TTFT) by up to 28.3\% on LLM workloads and increases throughput by up to 24.2\% on deep learning recommendation (DLRM) workloads. Even with poor predictions, performance degrades gracefully and remains close to \textsc{LRU}, demonstrating robustness with practical value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learning-augmented LRU, a caching algorithm that integrates predictions to achieve 1-consistency and O(k)-robustness while incurring low time and space overhead and maintaining compatibility with existing systems. It then builds the LCR GPU cache on this policy and reports empirical gains of up to 28.3% reduction in P99 TTFT on LLM workloads and 24.2% throughput improvement on DLRM workloads, with graceful degradation under inaccurate predictions.
Significance. If the claimed consistency and robustness properties are preserved under the low-overhead implementation and the experiments adequately control for prediction quality and workload selection, the work would meaningfully advance the practical deployment of learning-augmented algorithms in GPU inference systems, closing a noted gap between theoretical guarantees and real hardware constraints.
major comments (2)
- [Experimental Evaluation] The central claim requires that the O(k)-robustness bound survives the practical implementation; however, the manuscript provides no micro-benchmark or per-request latency breakdown isolating the auxiliary predictor state and eviction-score recomputation costs relative to plain LRU (see the experimental setup and LCR implementation sections). Without this, it is impossible to confirm that the added overhead remains within the strict per-operation budget of modern GPU inference kernels.
- [Learning-Augmented LRU] The abstract asserts 1-consistency and O(k)-robustness for learning-augmented LRU, yet the manuscript contains no derivation steps, pseudocode, or reduction showing how the low-overhead modifications preserve these properties from the cited prior literature (pmlr-v80-lykouris18a, mitzenmacher2022algorithms). This derivation is load-bearing for the deployment-oriented positioning.
minor comments (2)
- [Theoretical Analysis] Notation for the robustness parameter k is introduced without an explicit definition or relation to cache size in the theoretical section.
- [Experiments] Figure captions for the TTFT and throughput plots should include error bars or the number of runs to clarify statistical significance of the reported 28.3% and 24.2% gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address the major comments point by point below, and we are prepared to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central claim requires that the O(k)-robustness bound survives the practical implementation; however, the manuscript provides no micro-benchmark or per-request latency breakdown isolating the auxiliary predictor state and eviction-score recomputation costs relative to plain LRU (see the experimental setup and LCR implementation sections). Without this, it is impossible to confirm that the added overhead remains within the strict per-operation budget of modern GPU inference kernels.
Authors: We agree that providing a micro-benchmark or per-request latency breakdown to isolate the costs of the auxiliary predictor state and eviction-score recomputation would help confirm that the overhead is low enough for modern GPU inference kernels. Our current experiments focus on end-to-end performance metrics, which show improvements without apparent overhead penalties. To address this, we will add a new subsection in the experimental evaluation with micro-benchmarks comparing the per-operation costs to plain LRU. revision: yes
-
Referee: [Learning-Augmented LRU] The abstract asserts 1-consistency and O(k)-robustness for learning-augmented LRU, yet the manuscript contains no derivation steps, pseudocode, or reduction showing how the low-overhead modifications preserve these properties from the cited prior literature (pmlr-v80-lykouris18a, mitzenmacher2022algorithms). This derivation is load-bearing for the deployment-oriented positioning.
Authors: We appreciate this observation. The low-overhead modifications to the learning-augmented LRU are intended to preserve the 1-consistency and O(k)-robustness guarantees from the referenced works by maintaining the core integration of predictions while optimizing for efficiency. However, we acknowledge that the manuscript would benefit from explicit derivation steps and pseudocode. We will add a new section or appendix that provides the derivation, including how the modifications reduce to the original bounds, along with pseudocode for the algorithm. revision: yes
Circularity Check
No significant circularity; guarantees rest on external literature
full rationale
The paper's core proposal of learning-augmented LRU with 1-consistency and O(k)-robustness is explicitly positioned as building on cited prior work (Lykouris et al. 2018 and Mitzenmacher 2022) rather than deriving those properties from quantities fitted or defined inside this manuscript. No equations, self-citations, or ansatzes are shown reducing the claimed guarantees or experimental gains (28.3% TTFT, 24.2% throughput) to tautological inputs. The contribution centers on practical GPU deployment and compatibility, which is independently assessed via experiments; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard definitions of 1-consistency and O(k)-robustness from learning-augmented caching literature
Forward citations
Cited by 2 Pith papers
-
One Pool, Two Caches: Adaptive HBM Partitioning for Accelerating Generative Recommender Serving
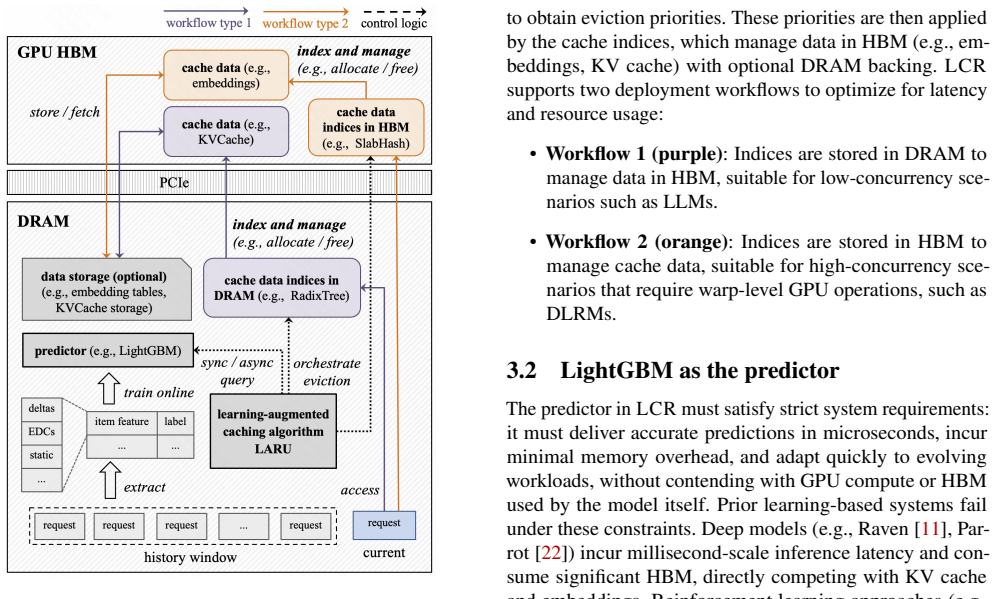
HELM adaptively partitions HBM between EMB and KV caches via a three-layer PPO controller and EMB-KV-aware scheduling, reducing P99 latency by 24-38% while achieving 93.5-99.6% SLO satisfaction on production workloads.
-
SCION: Size-aware Policy Orchestration for Nonstationary Object Caches (Long Paper Version)
SCION is a lightweight orchestration layer that picks among six deployable cache policies via an offline-trained linear selector on short-prefix size and reuse fingerprints, improving cacheable miss ratio over SIEVE o...
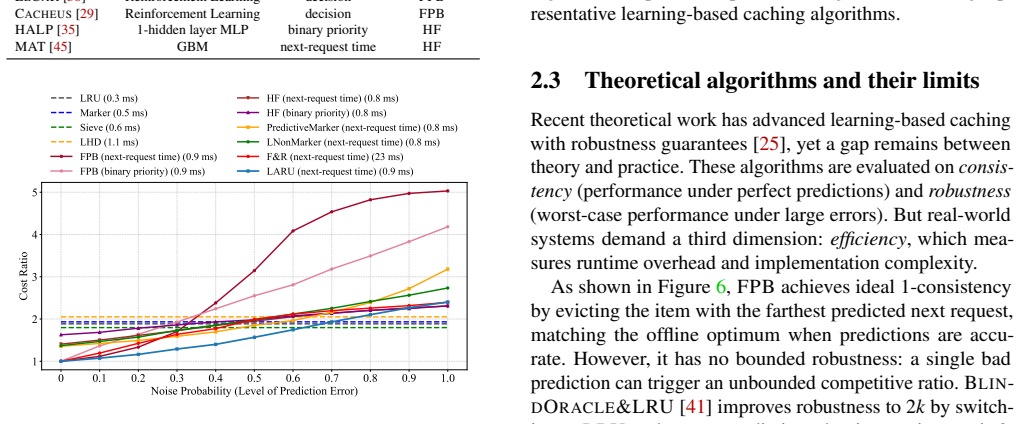
Reference graph
Works this paper leans on
-
[1]
URL https://huggingface.co/ datasets/philschmid/sharegpt-raw/tree/main/ sharegpt_90k_raw_dataset
Sharegpt raw. URL https://huggingface.co/ datasets/philschmid/sharegpt-raw/tree/main/ sharegpt_90k_raw_dataset
-
[2]
URL https://crc2.ece.tamu.edu/
The 2nd cache replacement championship, 2017. URL https://crc2.ece.tamu.edu/
work page 2017
-
[3]
A dynamic hash table for the gpu
Saman Ashkiani, Martin Farach-Colton, and John D Owens. A dynamic hash table for the gpu. In2018 IEEE international parallel and distributed processing symposium (IPDPS), pages 419–429. IEEE, 2018
work page 2018
-
[4]
{LHD}: Improving cache hit rate by maximizing hit density
Nathan Beckmann, Haoxian Chen, and Asaf Cidon. {LHD}: Improving cache hit rate by maximizing hit density. In15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), pages 389–403, 2018
work page 2018
-
[5]
Online computation and competitive analysis, 1998
Allan Borodin and Ran El-Yaniv. Online computation and competitive analysis, 1998
work page 1998
-
[6]
Updlrm: Accelerating personalized recommendation using real-world pim architecture
Sitian Chen, Haobin Tan, Amelie Chi Zhou, Yusen Li, and Pavan Balaji. Updlrm: Accelerating personalized recommendation using real-world pim architecture. In Proceedings of the 61st ACM/IEEE Design Automation Conference, pages 1–6, 2024
work page 2024
-
[7]
Ecco: Improving mem- ory bandwidth and capacity for llms via entropy-aware cache compression
Feng Cheng, Cong Guo, Chiyue Wei, Junyao Zhang, Changchun Zhou, Edward Hanson, Jiaqi Zhang, Xiaox- iao Liu, Hai Li, and Yiran Chen. Ecco: Improving mem- ory bandwidth and capacity for llms via entropy-aware cache compression. InProceedings of the 52nd An- nual International Symposium on Computer Architec- ture, pages 793–807, 2025
work page 2025
-
[8]
Assaf Eisenman, Maxim Naumov, Darryl Gardner, Misha Smelyanskiy, Sergey Pupyrev, Kim Hazelwood, Asaf Cidon, and Sachin Katti. Bandana: Using non- volatile memory for storing deep learning models.Pro- ceedings of machine learning and systems, 1:40–52, 2019
work page 2019
-
[9]
Compet- itive paging algorithms.Journal of Algorithms, 12(4): 685–699, 1991
Amos Fiat, Richard M Karp, Michael Luby, Lyle A Mc- Geoch, Daniel D Sleator, and Neal E Young. Compet- itive paging algorithms.Journal of Algorithms, 12(4): 685–699, 1991
work page 1991
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Raven: belady-guided, predictive (deep) learning for in-memory and content caching
Xinyue Hu, Eman Ramadan, Wei Ye, Feng Tian, and Zhi-Li Zhang. Raven: belady-guided, predictive (deep) learning for in-memory and content caching. InProceed- ings of the 18th International Conference on emerging Networking EXperiments and Technologies, pages 72– 90, 2022
work page 2022
-
[12]
Akanksha Jain and Calvin Lin. Back to the future: Lever- aging belady’s algorithm for improved cache replace- ment.ACM SIGARCH Computer Architecture News, 44 (3):78–89, 2016
work page 2016
-
[13]
Wenqi Jiang, Zhenhao He, Shuai Zhang, Thomas B Preußer, Kai Zeng, Liang Feng, Jiansong Zhang, Tongx- uan Liu, Yong Li, Jingren Zhou, et al. Microrec: Effi- cient recommendation inference by hardware and data structure solutions.Proceedings of Machine Learning and Systems, 3:845–859, 2021
work page 2021
-
[14]
Fleetrec: Large-scale recommendation inference on hybrid gpu-fpga clusters
Wenqi Jiang, Zhenhao He, Shuai Zhang, Kai Zeng, Liang Feng, Jiansong Zhang, Tongxuan Liu, Yong Li, Jingren Zhou, Ce Zhang, et al. Fleetrec: Large-scale recommendation inference on hybrid gpu-fpga clusters. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 3097– 3105, 2021
work page 2021
-
[15]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
work page 2017
-
[16]
Rec- nmp: Accelerating personalized recommendation with near-memory processing
Liu Ke, Udit Gupta, Benjamin Youngjae Cho, David Brooks, Vikas Chandra, Utku Diril, Amin Firoozshahian, Kim Hazelwood, Bill Jia, Hsien-Hsin S Lee, et al. Rec- nmp: Accelerating personalized recommendation with near-memory processing. In2020 ACM/IEEE 47th An- nual International Symposium on Computer Architec- ture (ISCA), pages 790–803. IEEE, 2020
work page 2020
-
[17]
Daniar H Kurniawan, Ruipu Wang, Kahfi S Zulkifli, Fandi A Wiranata, John Bent, Ymir Vigfusson, and Haryadi S Gunawi. Evstore: Storage and caching ca- pabilities for scaling embedding tables in deep recom- mendation systems. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol-...
work page 2023
-
[18]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023. 13
work page 2023
-
[19]
Youngeun Kwon, Yunjae Lee, and Minsoo Rhu. Tensor- dimm: A practical near-memory processing architecture for embeddings and tensor operations in deep learning. InProceedings of the 52nd Annual IEEE/ACM Interna- tional Symposium on Microarchitecture, pages 740–753, 2019
work page 2019
-
[20]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache manage- ment. In18th USENIX Symposium on Operating Sys- tems Design and Implementation (OSDI 24), pages 155– 172, 2024
work page 2024
-
[21]
Merci: efficient embedding reduction on commodity hardware via sub-query memoization
Yejin Lee, Seong Hoon Seo, Hyunji Choi, Hyoung Uk Sul, Soosung Kim, Jae W Lee, and Tae Jun Ham. Merci: efficient embedding reduction on commodity hardware via sub-query memoization. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, pages 302–313, 2021
work page 2021
-
[22]
An imitation learn- ing approach for cache replacement
Evan Liu, Milad Hashemi, Kevin Swersky, Parthasarathy Ranganathan, and Junwhan Ahn. An imitation learn- ing approach for cache replacement. InInternational Conference on Machine Learning, pages 6237–6247. PMLR, 2020
work page 2020
-
[23]
Competitive caching with machine learned advice
Thodoris Lykouris and Sergei Vassilvtiskii. Competitive caching with machine learned advice. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th Inter- national Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 3296–3305. PMLR, 10–15 Jul 2018. URL https:// proceedings.mlr.press/v80/lykouris18a.html
work page 2018
-
[24]
Algo- rithms with predictions.Commun
Michael Mitzenmacher and Sergei Vassilvitskii. Algo- rithms with predictions.Commun. ACM, 65(7):33–35, June 2022. ISSN 0001-0782. doi: 10.1145/3528087. URLhttps://doi.org/10.1145/3528087
-
[25]
Algo- rithms with predictions.Communications of the ACM, 65(7):33–35, 2022
Michael Mitzenmacher and Sergei Vassilvitskii. Algo- rithms with predictions.Communications of the ACM, 65(7):33–35, 2022
work page 2022
-
[26]
Yudi Qiu, Lingfei Lu, Shiyan Yi, Minge Jing, Xiaoyang Zeng, Yang Kong, and Yibo Fan. Flips: A flexible par- titioning strategy near memory processing architecture for recommendation system.IEEE Transactions on Parallel and Distributed Systems, 2025
work page 2025
-
[27]
Pol G. Recasens, Ferran Agullo, Yue Zhu, Chen Wang, Eun Kyung Lee, Olivier Tardieu, Jordi Torres, and Josep Ll. Berral. Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference, 2025. URL https://arxiv.org/abs/2503.08311
-
[28]
Machine learning-guided memory optimization for dlrm infer- ence on tiered memory
Jie Ren, Bin Ma, Shuangyan Yang, Benjamin Francis, Ehsan K Ardestani, Min Si, and Dong Li. Machine learning-guided memory optimization for dlrm infer- ence on tiered memory. In2025 IEEE International Symposium on High Performance Computer Architec- ture (HPCA), pages 1631–1647. IEEE, 2025
work page 2025
-
[29]
Learning cache replacement with {CACHEUS}
Liana V Rodriguez, Farzana Yusuf, Steven Lyons, Eysler Paz, Raju Rangaswami, Jason Liu, Ming Zhao, and Giri Narasimhan. Learning cache replacement with {CACHEUS}. In19th USENIX Conference on File and Storage Technologies (FAST 21), pages 341–354, 2021
work page 2021
-
[30]
Near-optimal bounds for online caching with machine learned advice
Dhruv Rohatgi. Near-optimal bounds for online caching with machine learned advice. InProceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1834–1845. SIAM, 2020
work page 2020
-
[31]
Al- gorithms for caching and MTS with reduced number of predictions
Karim Ahmed Abdel Sadek and Marek Elias. Al- gorithms for caching and MTS with reduced number of predictions. InThe Twelfth International Confer- ence on Learning Representations, 2024. URL https: //openreview.net/forum?id=QuIiLSktO4
work page 2024
-
[32]
Applying deep learning to the cache replacement problem
Zhan Shi, Xiangru Huang, Akanksha Jain, and Calvin Lin. Applying deep learning to the cache replacement problem. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 413–425, 2019
work page 2019
-
[33]
Ugache: A unified gpu cache for embedding- based deep learning
Xiaoniu Song, Yiwen Zhang, Rong Chen, and Haibo Chen. Ugache: A unified gpu cache for embedding- based deep learning. InProceedings of the 29th Sympo- sium on Operating Systems Principles, pages 627–641, 2023
work page 2023
-
[34]
Learning relaxed belady for content distribution network caching
Zhenyu Song, Daniel S Berger, Kai Li, Anees Shaikh, Wyatt Lloyd, Soudeh Ghorbani, Changhoon Kim, Aditya Akella, Arvind Krishnamurthy, Emmett Witchel, et al. Learning relaxed belady for content distribution network caching. In17th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 20), pages 529–544, 2020
work page 2020
-
[35]
{HALP}: Heuristic aided learned preference eviction policy for {YouTube} content delivery network
Zhenyu Song, Kevin Chen, Nikhil Sarda, Deniz Al- tınbüken, Eugene Brevdo, Jimmy Coleman, Xiao Ju, Pawel Jurczyk, Richard Schooler, and Ramki Gummadi. {HALP}: Heuristic aided learned preference eviction policy for {YouTube} content delivery network. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 1149–1163, 2023
work page 2023
-
[36]
Qwen Team. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
The AIBrix Team, Jiaxin Shan, Varun Gupta, Le Xu, Haiyang Shi, Jingyuan Zhang, Ning Wang, Linhui Xu, 14 Rong Kang, Tongping Liu, et al. Aibrix: Towards scal- able, cost-effective large language model inference in- frastructure.arXiv preprint arXiv:2504.03648, 2025
-
[38]
Driving cache replacement with {ML-based}{LeCaR}
Giuseppe Vietri, Liana V Rodriguez, Wendy A Martinez, Steven Lyons, Jason Liu, Raju Rangaswami, Ming Zhao, and Giri Narasimhan. Driving cache replacement with {ML-based}{LeCaR}. In10th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 18), 2018
work page 2018
-
[39]
Kvcache cache in the wild: Char- acterizing and optimizing kvcache cache at a large cloud provider
Jiahao Wang, Jinbo Han, Xingda Wei, Sijie Shen, Dingyan Zhang, Chenguang Fang, Rong Chen, Wenyuan Yu, and Haibo Chen. Kvcache cache in the wild: Char- acterizing and optimizing kvcache cache at a large cloud provider. In2025 USENIX Annual Technical Confer- ence (USENIX ATC 25). USENIX Association, July
-
[40]
URL https://www.usenix.org/conference/ atc25/presentation/wang-jiahao
-
[41]
Abel, Xu Guo, Jianbing Dong, Ji Shi, and Kunlun Li
Zehuan Wang, Yingcan Wei, Minseok Lee, Matthias Langer, Fan Yu, Jie Liu, Shijie Liu, Daniel G. Abel, Xu Guo, Jianbing Dong, Ji Shi, and Kunlun Li. Merlin hugectr: Gpu-accelerated recommender system training and inference. InProceedings of the 16th ACM Con- ference on Recommender Systems, RecSys ’22, page 534–537, New York, NY , USA, 2022. Association for ...
-
[42]
Better and simpler learning-augmented online caching.arXiv preprint arXiv:2005.13716, 2020
Alexander Wei. Better and simpler learning-augmented online caching.arXiv preprint arXiv:2005.13716, 2020
-
[43]
A gpu-specialized inference parameter server for large-scale deep recom- mendation models
Yingcan Wei, Matthias Langer, Fan Yu, Minseok Lee, Jie Liu, Ji Shi, and Zehuan Wang. A gpu-specialized inference parameter server for large-scale deep recom- mendation models. InProceedings of the 16th ACM Conference on Recommender Systems, pages 408–419, 2022
work page 2022
-
[44]
Fleche: an efficient gpu embedding cache for personalized recommendations
Minhui Xie, Youyou Lu, Jiazhen Lin, Qing Wang, Jian Gao, Kai Ren, and Jiwu Shu. Fleche: an efficient gpu embedding cache for personalized recommendations. In Proceedings of the Seventeenth European Conference on Computer Systems, pages 402–416, 2022
work page 2022
-
[45]
Learning from op- timal caching for content delivery
Gang Yan, Jian Li, and Don Towsley. Learning from op- timal caching for content delivery. InProceedings of the 17th International Conference on emerging Networking EXperiments and Technologies, pages 344–358, 2021
work page 2021
-
[46]
A learned cache eviction framework with mini- mal overhead.arXiv preprint arXiv:2301.11886, 2023
Dongsheng Yang, Daniel S Berger, Kai Li, and Wyatt Lloyd. A learned cache eviction framework with mini- mal overhead.arXiv preprint arXiv:2301.11886, 2023
-
[47]
{GL-Cache}: Group-level learning for efficient and high-performance caching
Juncheng Yang, Ziming Mao, Yao Yue, and KV Rashmi. {GL-Cache}: Group-level learning for efficient and high-performance caching. In21st USENIX Confer- ence on File and Storage Technologies (FAST 23), pages 115–134, 2023
work page 2023
-
[48]
{GPU-Disaggregated} serving for deep learning recommendation models at scale
Lingyun Yang, Yongchen Wang, Yinghao Yu, Qizhen Weng, Jianbo Dong, Kan Liu, Chi Zhang, Yanyi Zi, Hao Li, Zechao Zhang, et al. {GPU-Disaggregated} serving for deep learning recommendation models at scale. In 22nd USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 25), pages 847–863, 2025
work page 2025
-
[49]
Guanghu Yuan, Fajie Yuan, Yudong Li, Beibei Kong, Shujie Li, Lei Chen, Min Yang, Chenyun Yu, Bo Hu, Zang Li, et al. Tenrec: A large-scale multipurpose benchmark dataset for recommender systems.Advances in Neural Information Processing Systems, 35:11480– 11493, 2022
work page 2022
-
[50]
{SIEVE} is simpler than {LRU}: an efficient {Turn-Key} eviction algorithm for web caches
Yazhuo Zhang, Juncheng Yang, Yao Yue, Ymir Vig- fusson, and KV Rashmi. {SIEVE} is simpler than {LRU}: an efficient {Turn-Key} eviction algorithm for web caches. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 1229–1246, 2024
work page 2024
-
[51]
Two-level graph caching for expediting distributed gnn training
Zhe Zhang, Ziyue Luo, and Chuan Wu. Two-level graph caching for expediting distributed gnn training. InIEEE INFOCOM 2023-IEEE Conference on Computer Com- munications, pages 1–10. IEEE, 2023
work page 2023
-
[52]
Song: Approxi- mate nearest neighbor search on gpu
Weijie Zhao, Shulong Tan, and Ping Li. Song: Approxi- mate nearest neighbor search on gpu. In2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 1033–1044. IEEE, 2020
work page 2020
-
[53]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in Neural Information Pro- cessing Systems, 37:62557–62583, 2024
work page 2024
-
[54]
Deep inter- est evolution network for click-through rate prediction
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep inter- est evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial in- telligence, volume 33, pages 5941–5948, 2019
work page 2019
-
[55]
{3L-Cache}: Low overhead and precise learning-based eviction policy for caches
Wenbin Zhou, Zhixiong Niu, Yongqiang Xiong, Juan Fang, and Qian Wang. {3L-Cache}: Low overhead and precise learning-based eviction policy for caches. In 23rd USENIX Conference on File and Storage Technolo- gies (FAST 25), pages 237–254, 2025. 15 Artifact Appendix Abstract The provided artifacts include all code and non-confidential traces to reproduce the...
work page 2025
-
[56]
SLS-Cache-Bench.For DLRMs, we develop a dedi- cated benchmark that isolates the SparseLengthsSum (SLS) operation from the HugeCTR framework and integrates LCR. The benchmark supports direct com- parison of GPU embedding cache policies, including FPB (following predictions blindly), LARU, and clas- sical LRU. We implement an alternative GPU cache in the fl...
-
[57]
LCR-on-SGLang.For LLMs, we integrate LCR into SGLang (version 0.4.9.post2) by adding Light- GBM support, implementing an online training frame- work, and replacing the default RadixTree cache (radix_cache.py) with LARU. This integration en- ables systematic comparison of GPU KV cache policies, including FPB, LARU, and classical LRU. It comprises over 5K l...
-
[58]
DLRMs: CUDA 12.4, PyTorch 2.6.0, and either devtoolset-9orgcc-9
-
[59]
LLMs: CUDA 12.6, PyTorch 2.6.0, and the required third-party Python packages, lightgbm. The hardware used to generate the results in this paper is described in Section 4.1 for DLRMs and Section 5.1 for LLMs. Nevertheless, the experiments can also be conducted on other GPUs, provided that the available HBM capacity is sufficient to accommodate both the ML ...
-
[60]
Bounded robustness.The robustness of LARU is O(k), as proved in Technical Appendix D. In other words, re- gardless of predictor accuracy, its competitive ratio is bounded by O(k), matching LRU’s k-competitive ra- tio asymptotically and safeguarding against catastrophic performance degradation or systemic risk
-
[61]
Ideal consistency.The consistency of LARU is 1, as proved in Technical Appendix E. Under perfect predic- tions, LARU matches the offline optimal algorithm, fully leveraging accurate machine-learned predictions
-
[62]
Low time complexity.The algorithm runs in O(logk) amortized time per request, which is practical since k is small in practice. In DLRMs, embedding caches are partitioned into buckets (e.g., SlabHash in HugeCTR), each holding only tens of items (e.g., 64). In LLMs, KV cache vectors are typically organized viaRadixTrees in SGLang or paged-attention in vLLM,...
-
[63]
Reduced predictor usage.In asynchronous mode, pre- diction tasks are triggered only under specific conditions, such as at most once per fixed interval or after the pre- vious task has completed, preventing excessive usage. In synchronous mode, once a prediction-induced cache miss is detected (Line 14 in Algorithm 1), LARU falls back to LRU once, limiting ...
-
[64]
the requested item is a new item that has not yet been evicted in the current phase
-
[65]
The number of occurrences of case (1) equals the num- ber of distinct new items, ci
the requested item was previously evicted by LRU’s policy within the same phase. The number of occurrences of case (1) equals the num- ber of distinct new items, ci. Note that after logb(k) occur- rences of case (2), λ has become 1/blogb(k), the candidate set L shrinks to size 1, and the eviction step at Line 25 degener- ates to LRU’s policy. Hence, the n...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.