Recognition: 3 theorem links
One Pool, Two Caches: Adaptive HBM Partitioning for Accelerating Generative Recommender Serving
Pith reviewed 2026-05-08 17:42 UTC · model grok-4.3
The pith
HELM dynamically partitions GPU HBM between embedding and KV caches to cut P99 latency 24-38% while meeting 93-99% SLOs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HELM jointly manages HBM allocation and request routing at runtime through two components: Adaptive Memory Allocation, a three-layer PPO controller (frozen base policy, online residual adapter, burst-aware recovery) that reaches 32 μs decisions and stays within 0.024-0.029 of the offline-optimal EMB-KV ratio, plus EMB-KV-Aware Scheduling that routes requests while considering KV residency, embedding locality, and node load. This combination reduces P99 latency 24-38% versus the best static policy and achieves 93.5-99.6% SLO satisfaction across Steady, Trend, and Burst workloads.
What carries the argument
The three-layer PPO controller (frozen base policy, online residual adapter, and burst-aware recovery controller) that tracks the optimal EMB-KV memory ratio at 32 μs latency without introducing H2D refill traffic.
If this is right
- Joint allocation and routing decisions eliminate routing inefficiencies that appear when caches are managed separately under heterogeneous node states.
- The controller maintains throughput parity while cutting tail latency because it avoids PCIe data movement on the serving path.
- Production-scale evaluation on three datasets over 32 A100 nodes confirms the gains hold across steady, trending, and bursty request patterns.
- The same framework applies to any serving system in which two or more cache types compete for a single fast memory pool.
Where Pith is reading between the lines
- The same low-overhead controller pattern could be reused for other competing GPU memory structures such as activation caches and parameter shards in large-model inference.
- Because the optimal ratio changes with workload statistics, similar adaptive partitioning may become necessary as model sizes and context lengths continue to grow.
- Extending the burst-aware recovery layer to incorporate short-term traffic predictions could further shrink the residual tracking error below 0.02.
Load-bearing premise
The three-layer PPO controller can track the shifting optimal EMB-KV ratio within 0.024-0.029 while keeping 32 μs decision latency and avoiding H2D refill traffic on the critical path under real production workload shifts.
What would settle it
Running the same Steady, Trend, and Burst workloads with the controller frozen at a static ratio shows P99 latency improvement dropping below 10% or SLO satisfaction falling below 90%.
Figures











read the original abstract
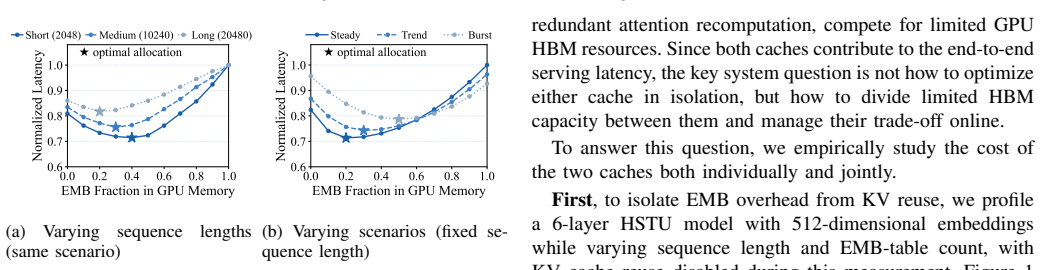
Generative Recommender (GR) inference places embedding hot caches (EMB) and KV caches in direct competition for limited GPU HBM: allocating more memory to one improves its efficiency but degrades the other. Existing systems optimize them in isolation, overlooking that the optimal EMB-KV allocation ratio can shift by up to 0.35 across workload regimes, leaving 20-30\% latency improvement unrealized. While online reallocation is required to close this gap, naive approaches introduce H2D refill traffic on the critical path, causing P99 SLO violations. To address this, we present HELM, which jointly manages HBM allocation and request routing at runtime through two key components: (1) Adaptive Memory Allocation, a three-layer PPO-based controller (frozen base policy, online residual adapter, and burst-aware recovery controller) that achieves $32\,\mathrm{\mu s}$ decision latency while staying within 0.024-0.029 of the offline-optimal ratio; and (2) EMB-KV-Aware Scheduling, which routes requests by jointly considering KV residency, embedding locality, and node load to avoid routing inefficiencies under heterogeneous allocations. Evaluations on three production-scale datasets over a 32-node A100 cluster show that HELM reduces P99 latency by 24-38\% over the best static policy and achieves 93.5-99.6\% SLO satisfaction across Steady, Trend, and Burst workloads, significantly outperforming state-of-the-art baselines without sacrificing throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HELM, a system for generative recommender serving that jointly manages HBM allocation between embedding (EMB) caches and KV caches via a three-layer PPO controller (frozen base, online residual adapter, burst-aware recovery) achieving 32 μs decisions and 0.024-0.029 deviation from offline-optimal ratios, combined with EMB-KV-aware request scheduling. On three production datasets over a 32-node A100 cluster, it reports 24-38% P99 latency reduction versus the best static policy and 93.5-99.6% SLO satisfaction across Steady/Trend/Burst workloads, outperforming baselines without throughput loss.
Significance. If the adaptive control and scheduling deliver the claimed overhead-free tracking, the work addresses a genuine and previously under-optimized tension in HBM resource allocation for large-scale GR inference, where optimal EMB-KV ratios can shift by up to 0.35. The production-scale empirical evaluation on real hardware provides concrete, falsifiable latency and SLO numbers that could influence practical serving systems.
major comments (3)
- [Abstract and evaluation] Abstract and evaluation sections: the headline 24-38% P99 reduction and 93.5-99.6% SLO claims rest on the three-layer PPO controller tracking the optimal EMB-KV ratio within 0.024-0.029 at 32 μs latency without introducing H2D refill traffic. No histograms of per-decision latency, time-series of controller error, or ablation isolating the residual adapter and burst-recovery components are provided, making it impossible to confirm that the observed gains are attributable to adaptive partitioning rather than other system factors.
- [Evaluation] Evaluation on 32-node A100 cluster: the reported results lack error bars, detailed characterization of how the Steady/Trend/Burst traces induce ratio shifts, and implementation specifics for the static-policy and SOTA baselines. This weakens verification of the cross-workload robustness claims.
- [EMB-KV-Aware Scheduling] EMB-KV-Aware Scheduling description: it is stated that the policy routes requests considering KV residency, embedding locality, and node load to avoid inefficiencies under heterogeneous allocations, but no quantitative breakdown of refill volume or critical-path H2D traffic under the measured controller deviations is given, leaving the central 'no refill on critical path' assumption unverified.
minor comments (2)
- [Abstract] The abstract and text would benefit from explicit workload characterization (e.g., request-rate distributions or embedding-access patterns) to contextualize the 0.35 ratio-shift claim.
- [Adaptive Memory Allocation] Notation for the three-layer controller components is introduced without a diagram or pseudocode; a small figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight opportunities to strengthen the empirical support for our claims regarding the three-layer PPO controller and scheduling policy. We will incorporate additional visualizations, error bars, workload characterizations, and quantitative breakdowns in the revised manuscript. Below we respond point-by-point to each major comment.
read point-by-point responses
-
Referee: [Abstract and evaluation] Abstract and evaluation sections: the headline 24-38% P99 reduction and 93.5-99.6% SLO claims rest on the three-layer PPO controller tracking the optimal EMB-KV ratio within 0.024-0.029 at 32 μs latency without introducing H2D refill traffic. No histograms of per-decision latency, time-series of controller error, or ablation isolating the residual adapter and burst-recovery components are provided, making it impossible to confirm that the observed gains are attributable to adaptive partitioning rather than other system factors.
Authors: We agree that the current presentation leaves the attribution of gains to the adaptive controller less direct than ideal. In the revision we will add: (1) histograms of per-decision controller latency across all workloads, (2) time-series plots of instantaneous controller error relative to the offline-optimal ratio, and (3) an ablation study that isolates the residual adapter and burst-aware recovery layers. These additions will show that the 0.024-0.029 tracking accuracy is achieved at 32 μs and directly correlates with the reported P99 reductions, while the static baselines exhibit larger deviations and higher latency. revision: yes
-
Referee: [Evaluation] Evaluation on 32-node A100 cluster: the reported results lack error bars, detailed characterization of how the Steady/Trend/Burst traces induce ratio shifts, and implementation specifics for the static-policy and SOTA baselines. This weakens verification of the cross-workload robustness claims.
Authors: We will add error bars (standard deviation over five independent runs) to all latency and SLO figures. We will also expand the evaluation section with a characterization subsection that plots the time-varying optimal EMB-KV ratio for each trace and quantifies the magnitude and frequency of shifts (up to 0.35). Finally, we will include a table or appendix entry detailing the exact configurations and hyper-parameters used for the static policies and SOTA baselines, enabling exact reproduction. revision: yes
-
Referee: [EMB-KV-Aware Scheduling] EMB-KV-Aware Scheduling description: it is stated that the policy routes requests considering KV residency, embedding locality, and node load to avoid inefficiencies under heterogeneous allocations, but no quantitative breakdown of refill volume or critical-path H2D traffic under the measured controller deviations is given, leaving the central 'no refill on critical path' assumption unverified.
Authors: We will add a new figure and accompanying text that reports measured H2D refill volumes and the fraction of traffic on the critical path, broken down by workload and under the observed controller deviations of 0.024-0.029. The data will demonstrate that the EMB-KV-aware scheduler keeps critical-path refills below 1% of total H2D traffic, confirming that the small tracking error does not translate into SLO violations. revision: yes
Circularity Check
No circularity; empirical system evaluation with direct measurements
full rationale
The paper presents HELM as an empirical systems contribution: a three-layer PPO controller for runtime HBM partitioning between EMB and KV caches, combined with EMB-KV-aware scheduling. Central claims (24-38% P99 latency reduction, 93.5-99.6% SLO satisfaction) rest on cluster measurements across Steady/Trend/Burst workloads on three production datasets. No derivation chain, equations, or first-principles predictions exist that reduce to fitted inputs or self-citations by construction. The controller's tracking bounds (0.024-0.029) and 32 μs latency are stated as design targets and validated via end-to-end runs rather than derived tautologically. Any self-citations (if present in full text) are not load-bearing for the reported results, which are externally falsifiable via the described 32-node A100 experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- PPO residual adapter and recovery controller parameters
axioms (1)
- domain assumption Optimal EMB-KV allocation ratio shifts by up to 0.35 across workload regimes
invented entities (2)
-
Three-layer PPO controller (frozen base + online residual adapter + burst-aware recovery)
no independent evidence
-
EMB-KV-Aware Scheduling policy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Avazu click-through rate prediction,
“Avazu click-through rate prediction,” https://www.kaggle.com/c/avazu- ctr-prediction
-
[2]
Kdd cup 2012 track 2: Predicting clicks on advertisements,
“Kdd cup 2012 track 2: Predicting clicks on advertisements,” https:// www.kdd.org/kdd-cup/view/kdd-cup-2012-track-2
2012
-
[3]
Meta synthetic datasets for embedding lookup workloads,
“Meta synthetic datasets for embedding lookup workloads,” https:// github.com/facebookresearch/dlrm datasets
-
[4]
Taobao user behavior dataset,
“Taobao user behavior dataset,” https://tianchi.aliyun.com/dataset/ dataDetail?dataId=649
-
[5]
K. J. ˚Astr¨om and T. H ¨agglund,PID Controllers: Theory, Design and Tuning, 2nd ed. Research Triangle Park, NC: Instrument Society of America, 1995. [Online]. Available: https://portal.research.lu.se/en/ publications/pid-controllers-theory-design-and-tuning
1995
-
[6]
Longer: Scaling up long sequence modeling in industrial recommenders,
Z. Chai, Q. Ren, X. Xiao, H. Yang, B. Han, S. Zhang, D. Chen, H. Lu, W. Zhao, L. Yuet al., “Longer: Scaling up long sequence modeling in industrial recommenders,” inProceedings of the Nineteenth ACM Conference on Recommender Systems, 2025, pp. 247–256. [Online]. Available: https://doi.org/10.1145/3705328.3748065
-
[7]
Toward Robust and Efficient ML-Based GPU Caching for Modern Inference
P. Chen, J. Zhang, H. Zhao, Y . Zhang, J. Yu, X. Tang, Y . Wang, H. Li, J. Zou, G. Xionget al., “Toward robust and efficient ml-based gpu caching for modern inference,”arXiv preprint arXiv:2509.20979, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.20979
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20979 2025
-
[8]
R. Chen, J. Wu, H. Shi, Y . Li, X. Liu, and G. Wang, “Drlpart: A deep reinforcement learning framework for optimally efficient and robust resource partitioning on commodity servers,” inProceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing, 2021, pp. 175–188. [Online]. Available: https://doi.org/10.1145/3431...
-
[9]
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794. [Online]. Available: https://doi.org/10.1145/2939672.2939785
-
[10]
Meta’s second generation ai chip: Model-chip co-design and productionization experiences,
J. Coburn, C. Tang, S. A. Asal, N. Agrawal, R. Chinta, H. Dixit, B. Dodds, S. Dwarakapuram, A. Firoozshahian, C. Gaoet al., “Meta’s second generation ai chip: Model-chip co-design and productionization experiences,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, 2025, pp. 1689–1702. [Online]. Available: https://doi.org/...
-
[11]
Criteo 1tb click logs dataset,
Criteo AI Lab, “Criteo 1tb click logs dataset,” https://ailab.criteo.com/ criteo-1tb-click-logs-dataset/, accessed: 2026
2026
-
[12]
H. Feng, B. Zhang, F. Ye, M. Si, C.-H. Chu, J. Tian, C. Yin, S. Deng, Y . Hao, P. Balajiet al., “Accelerating communication in deep learning recommendation model training with dual-level adaptive lossy compression,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–16. [Online]. Available:...
-
[13]
Fast state restoration in llm serving with hcache,
S. Gao, Y . Chen, and J. Shu, “Fast state restoration in llm serving with hcache,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, pp. 128–143. [Online]. Available: https://www.doi.org/10.1145/3689031.3696072
-
[14]
Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin,
L. Guan, J.-Q. Yang, Z. Zhao, B. Zhang, B. Sun, X. Luo, J. Ni, X. Li, Y . Qi, Z. Fanet al., “Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin,”arXiv preprint arXiv:2511.06077,
work page internal anchor Pith review arXiv
-
[15]
Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin,
[Online]. Available: https://doi.org/10.48550/arXiv.2511.06077
work page internal anchor Pith review doi:10.48550/arxiv.2511.06077
-
[16]
Flame: A serving system optimized for large-scale generative recommendation with efficiency,
X. Guo, B. Huang, X. Wu, G. Wu, F. Li, S. Wang, Q. Xiao, C. Luo, and Y . Li, “Flame: A serving system optimized for large-scale generative recommendation with efficiency,”arXiv preprint arXiv:2509.22681,
-
[17]
Flame: A serving system optimized for large-scale generative recommendation with efficiency,
[Online]. Available: https://doi.org/10.48550/arXiv.2509.22681
-
[18]
The architectural implications of facebook’s dnn-based personalized recommendation,
U. Gupta, C.-J. Wu, X. Wang, M. Naumov, B. Reagen, D. Brooks, B. Cottel, K. Hazelwood, M. Hempstead, B. Jiaet al., “The architectural implications of facebook’s dnn-based personalized recommendation,” in 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 488–501. [Online]. Available: https://doi.org/10.1109...
-
[19]
Gurobi Optimizer Reference Man- ual,
Gurobi Optimization, LLC, “Gurobi Optimizer Reference Man- ual,” https://www.gurobi.com/documentation/current/refman/index.html, 2021
2021
-
[20]
Mtgr: Industrial-scale generative recommendation framework in meituan,
R. Han, B. Yin, S. Chen, H. Jiang, F. Jiang, X. Li, C. Ma, M. Huang, X. Li, C. Jinget al., “Mtgr: Industrial-scale generative recommendation framework in meituan,” inProceedings of the 34th ACM International Conference on Information and Knowledge Management, 2025, pp. 5731–5738. [Online]. Available: https: //www.doi.org/10.1145/3746252.3761565
-
[21]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Y . Hou, J. Li, Z. He, A. Yan, X. Chen, and J. McAuley, “Bridging language and items for retrieval and recommendation,” arXiv preprint arXiv:2403.03952, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2403.03952
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.03952 2024
-
[22]
Towards large-scale generative ranking.arXiv preprint arXiv:2505.04180, 2025
Y . Huang, Y . Chen, X. Cao, R. Yang, M. Qi, Y . Zhu, Q. Han, Y . Liu, Z. Liu, X. Yaoet al., “Towards large-scale generative ranking,”arXiv preprint arXiv:2505.04180, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.04180
-
[23]
Fbgemm: Enabling high-performance low-precision deep learning inference
D. Khudia, J. Huang, P. Basu, S. Deng, H. Liu, J. Park, and M. Smelyanskiy, “Fbgemm: Enabling high-performance low-precision deep learning inference,”arXiv preprint arXiv:2101.05615, 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2101.05615
-
[24]
T. Kim, Y . Lee, J. Lim, and M. Rhu, “A characterization of generative recommendation models: Study of hierarchical sequential transduction unit,”IEEE Computer Architecture Letters, 2025. [Online]. Available: https://doi.org/10.1109/LCA.2025.3546811
-
[25]
and Zhang, Hao and Stoica, Ion , booktitle =
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626. [Online]. Available: https://dl.acm.org/doi/10.1145/3600006.3613165
-
[26]
Embedding samples dispatching for recommendation model training in edge environments,
G. Li, H. Tan, C. Zhang, H. Ni, Z. Wang, X. Zhang, Y . Xu, and H. Tian, “Embedding samples dispatching for recommendation model training in edge environments,”arXiv preprint arXiv:2512.21615, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2512.21615
-
[27]
X. Lian, B. Yuan, X. Zhu, Y . Wang, Y . He, H. Wu, L. Sun, H. Lyu, C. Liu, X. Donget al., “Persia: An open, hybrid system scaling 11 deep learning-based recommenders up to 100 trillion parameters,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 3288–3298. [Online]. Available: https://doi.org/10.1145/3534...
-
[28]
Tbgrecall: A generative retrieval model for e-commerce recommendation scenarios,
Z. Liang, C. Wu, D. Huang, W. Sun, Z. Wang, Y . Yan, J. Wu, Y . Jiang, B. Zheng, K. Chenet al., “Tbgrecall: A generative retrieval model for e-commerce recommendation scenarios,” inProceedings of the 34th ACM International Conference on Information and Knowledge Management, 2025, pp. 5863–5870. [Online]. Available: https://dl.acm.org/doi/10.1145/3746252.3761557
-
[29]
Near-memory computing with compressed embedding table for personalized recommendation,
J. Lim, Y . G. Kim, S. W. Chung, F. Koushanfar, and J. Kong, “Near-memory computing with compressed embedding table for personalized recommendation,”IEEE Transactions on Emerging Topics in Computing, vol. 12, pp. 938–951, 2024. [Online]. Available: https://www.doi.org/10.1109/tetc.2023.3345870
-
[30]
H. Lin, L. Yang, H. Guo, and J. Cao, “Decentralized task offloading in edge computing: An offline-to-online reinforcement learning approach,” IEEE Transactions on Computers, vol. 73, pp. 1603–1615, 2024. [Online]. Available: https://www.doi.org/10.1109/tc.2024.3377912
-
[31]
DLRMv3: Generative recommendation benchmark in MLPerf in- ference,
L. Ma, H. Kassa, Y . Lee, C. Liu, Z. Kong, Z. Jiang, P. Palangappa, R. Brugarolas, X. Cao, M. Hodak, C.-J. Wu, X. Liu, and J. Zhai, “DLRMv3: Generative recommendation benchmark in MLPerf in- ference,” https://mlcommons.org/2026/02/dlrmv3-inference-meta/, Feb. 2026, mLCommons Technical Report
2026
-
[32]
Harnessing machine learning in dynamic thermal management in embedded cpu-gpu platforms,
S. Maity, A. Majumder, R. Roy, A. R. Hota, and S. Dey, “Harnessing machine learning in dynamic thermal management in embedded cpu-gpu platforms,”ACM Transactions on Design Automation of Electronic Systems, vol. 30, pp. 1–32, 2024. [Online]. Available: https://www.doi.org/10.1145/3708890
-
[33]
Software-hardware co-design for fast and scalable training of deep learning recommendation models,
D. Mudigere, Y . Hao, J. Huang, Z. Jia, A. Tulloch, S. Sridharan, X. Liu, M. Ozdal, J. Nie, J. Parket al., “Software-hardware co-design for fast and scalable training of deep learning recommendation models,” inProceedings of the 49th Annual International Symposium on Computer Architecture, 2022, pp. 993–1011. [Online]. Available: https://doi.org/10.1145/3...
-
[34]
M. Naumov, D. Mudigere, H.-J. M. Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C.-J. Wu, A. G. Azzoliniet al., “Deep learning recommendation model for personalization and recommendation systems,”arXiv preprint arXiv:1906.00091, 2019. [Online]. Available: https://doi.org/10.48550/arXiv.1906.00091
-
[35]
Nvidia collective communications library (nccl),
NVIDIA Corporation, “Nvidia collective communications library (nccl),” https://developer.nvidia.com/nccl, 2017
2017
-
[36]
Nvidia multi-process service (mps) overview,
——, “Nvidia multi-process service (mps) overview,” https://docs.nvidia. com/deploy/mps/index.html, 2023, accessed: 2026-03-26
2023
-
[37]
Job placement using reinforcement learning in gpu virtualization environment,
J. Oh and Y . Kim, “Job placement using reinforcement learning in gpu virtualization environment,”Cluster Computing, vol. 23, no. 3, pp. 2219–2234, Sep. 2020. [Online]. Available: https: //doi.org/10.1007/s10586-019-03044-7
-
[39]
Mooncake: Trading more storage for less computation—a{KVCache-centric}architecture for serving {LLM}chatbot,
R. Qin, Z. Li, W. He, J. Cui, F. Ren, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: Trading more storage for less computation—a{KVCache-centric}architecture for serving {LLM}chatbot,” in23rd USENIX conference on file and storage technologies (FAST 25), 2025, pp. 155–170. [Online]. Available: https://www.usenix.org/conference/fast25/presentation/qin
2025
-
[40]
Dynamollm: Designing llm inference clusters for performance and energy efficiency,
J. Ren, B. Ma, S. Yang, B. Francis, E. K. Ardestani, M. Si, and D. Li, “Machine learning-guided memory optimization for dlrm inference on tiered memory,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1631–1647. [Online]. Available: https://doi.org/10.1109/HPCA61900. 2025.00121
-
[41]
Hierarchical resource partitioning on modern gpus: A reinforcement learning approach,
U. Saroliya, E. Arima, D. Liu, and M. Schulz, “Hierarchical resource partitioning on modern gpus: A reinforcement learning approach,” in2023 IEEE International Conference on Cluster Computing (CLUSTER), 2023, pp. 185–196. [Online]. Available: https://www.doi.org/10.1109/cluster52292.2023.00023
-
[42]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[43]
Proximal Policy Optimization Algorithms
[Online]. Available: https://doi.org/10.48550/arXiv.1707.06347
work page internal anchor Pith review doi:10.48550/arxiv.1707.06347
-
[44]
Taking the human out of the loop: A review of bayesian optimization,
B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. De Freitas, “Taking the human out of the loop: A review of bayesian optimization,” Proceedings of the IEEE, vol. 104, no. 1, pp. 148–175, 2015. [Online]. Available: https://doi.org/10.1109/JPROC.2015.2494218
-
[45]
BAT: Efficient generative recommender serving with bipartite attention,
J. Sun, S. Wang, Z. Zhang, Z. Liu, Y . Xu, P. Sun, B. Zhao, B. He, F. Wu, and Z. Wang, “BAT: Efficient generative recommender serving with bipartite attention,” inProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2026. [Online]. Available: https://doi.org/10.1145/3779212.3790131
-
[46]
Fleetio: Managing multi-tenant cloud storage with multi-agent reinforcement learning,
J. Sun, B. Reidys, D. Li, J. Chang, M. Snir, and J. Huang, “Fleetio: Managing multi-tenant cloud storage with multi-agent reinforcement learning,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2025, pp. 478–492. [Online]. Available: https://doi.org/10.1145/3669940.3707229
-
[47]
xgr: Efficient generative recommendation serving at scale,
Q. Sun, T. Liu, S. Zhang, S. Wu, P. Yang, H. Liang, M. Li, X. Ma, Z. Liang, Z. Renet al., “xgr: Efficient generative recommendation serving at scale,”arXiv preprint arXiv:2512.11529, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2512.11529
-
[48]
S. Udkar, V . Gupta, M. Reddy, and M. Vaithianathan, “Dynamic resource allocation of virtualized gpus and cpus for scalable ai workloads in containerized environments,” in2025 5th International Conference on Expert Clouds and Applications (ICOECA). IEEE, 2025, pp. 432–437. [Online]. Available: https://www.doi.org/10.1109/ icoeca66273.2025.00080
-
[49]
Relaygr: Scaling long-sequence generative recommendation via cross-stage relay-race inference,
J. Wang, H. Chai, Y . Zhang, Z. Zhou, W. Guo, X. Yang, Q. Tang, B. Pan, J. Zhu, K. Chenget al., “Relaygr: Scaling long-sequence generative recommendation via cross-stage relay-race inference,”arXiv preprint arXiv:2601.01712, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.01712
-
[50]
W. Wei, H. Gu, K. Wang, J. Li, X. Zhang, and N. Wang, “Multi- dimensional resource allocation in distributed data centers using deep reinforcement learning,”IEEE Transactions on Network and Service Management, vol. 20, pp. 1817–1829, 2023. [Online]. Available: https://www.doi.org/10.1109/tnsm.2022.3213575
-
[51]
Gpu-disaggregated serving for deep learning recommendation models at scale,
L. Yang, Y . Wang, Y . Yu, Q. Weng, J. Dong, K. Liu, C. Zhang, Y . Zi, H. Li, Z. Zhanget al., “Gpu-disaggregated serving for deep learning recommendation models at scale,” in22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25), 2025, pp. 847–863. [Online]. Available: https://www.usenix.org/conference/ nsdi25/presentation/yang
2025
-
[52]
Orca: A distributed serving system for transformer-based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for transformer-based generative models,” in16th USENIX symposium on operating systems design and implementation (OSDI 22), 2022, pp. 521–538. [Online]. Available: https://www.usenix.org/conference/osdi22/presentation/yu
2022
-
[53]
Near-zero-overhead freshness for recommendation systems via inference-side model updates,
W. Yu, S. Chen, C. Chen, and A. C. Zhou, “Near-zero-overhead freshness for recommendation systems via inference-side model updates,” inProceedings of the 32nd IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2026. [Online]. Available: https://doi.org/10.1109/HPCA68181.2026.11408549
-
[54]
Y . Yu, X. Si, C. Hu, and J. Zhang, “A review of recurrent neural networks: Lstm cells and network architectures,”Neural computation, vol. 31, no. 7, pp. 1235–1270, 2019. [Online]. Available: https://www.doi.org/10.1162/neco a 01199
-
[55]
Autoshard: Automated embedding table sharding for recommender systems,
D. Zha, L. Feng, B. Bhushanam, D. Choudhary, J. Nie, Y . Tian, J. Chae, Y . Ma, A. Kejariwal, and X. Hu, “Autoshard: Automated embedding table sharding for recommender systems,” inProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 4461–4471. [Online]. Available: https://www.doi.org/10.1145/3534678.3539034
-
[56]
J. Zhai, L. Liao, X. Liu, Y . Wang, R. Li, X. Cao, L. Gao, Z. Gong, F. Gu, J. Heet al., “Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 58 484–58 509. [Online]. Available: https://dl.acm.org/doi/10.5555/ 3692070.3694484
-
[57]
Recd: Deduplication for end-to-end deep learning recommendation model training infrastructure,
M. Zhao, D. Choudhary, D. Tyagi, A. Somani, M. Kaplan, S.-H. Lin, S. Pumma, J. Park, A. Basant, N. Agarwal et al., “Recd: Deduplication for end-to-end deep learning recommendation model training infrastructure,”Proceedings of Machine Learning and Systems, vol. 5, pp. 754–767, 2023. [On- 12 line]. Available: https://proceedings.mlsys.org/paper files/paper/...
2023
-
[58]
Onerec-v2 technical report.arXiv preprint arXiv:2508.20900, 2025
G. Zhou, H. Hu, H. Cheng, H. Wang, J. Deng, J. Zhang, K. Cai, L. Ren, L. Ren, L. Yuet al., “Onerec-v2 technical report,”arXiv preprint arXiv:2508.20900, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.20900
-
[59]
Gems: Breaking the long-sequence barrier in generative recommendation with a multi-stream decoder,
Y . Zhou, C. Guo, K. Cai, J. Liu, Q. Luo, R. Tang, H. Li, K. Gai, and G. Zhou, “Gems: Breaking the long-sequence barrier in generative recommendation with a multi-stream decoder,”arXiv preprint arXiv:2602.13631, 2026. [Online]. Available: https://doi.org/ 10.48550/arXiv.2602.13631 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.