Recognition: no theorem link
TRINITY: An Evolved LLM Coordinator
Pith reviewed 2026-05-17 01:14 UTC · model grok-4.3
The pith
A small evolved coordinator directs multiple LLMs by assigning Thinker, Worker, or Verifier roles across turns, beating single models and prior methods on coding, math, and reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
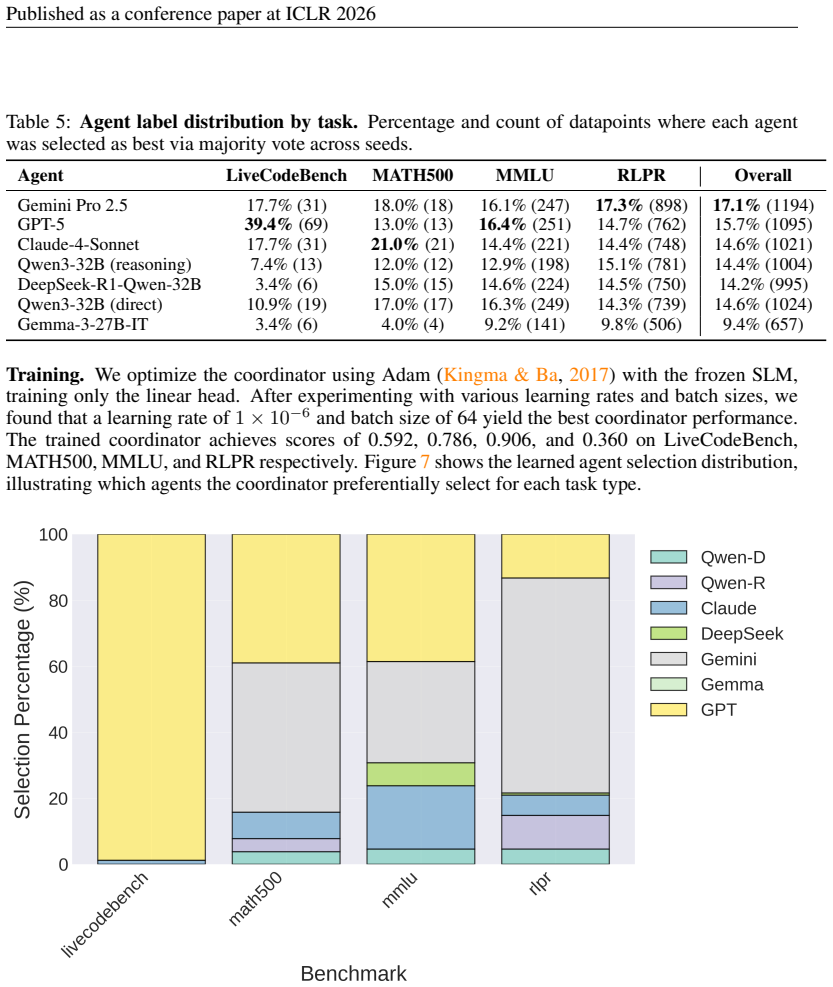
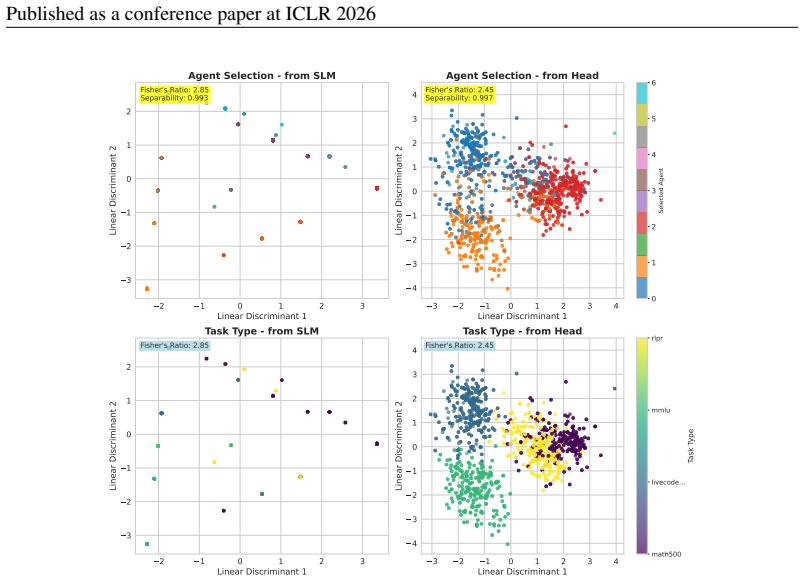
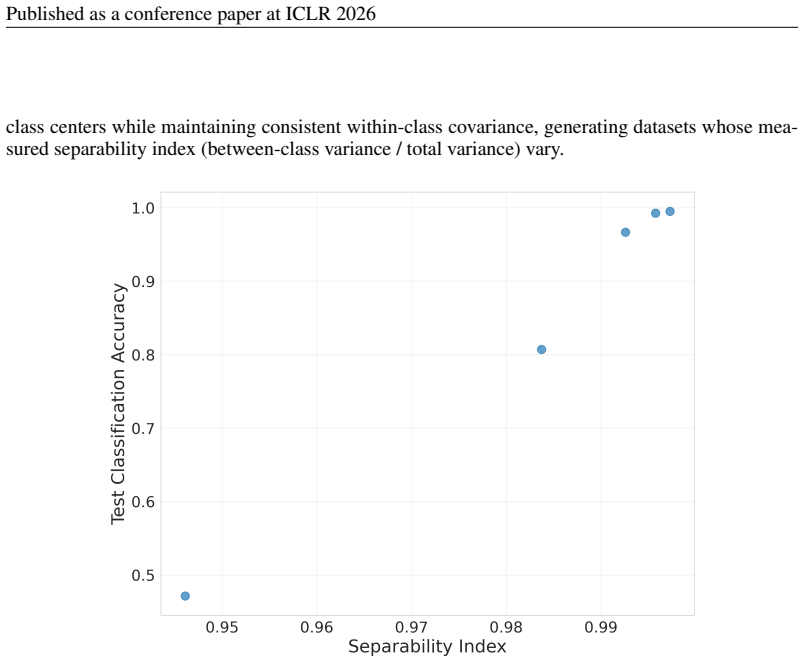
Trinity achieves state-of-the-art results by using a compact language model and lightweight head as coordinator, optimized with separable Covariance Matrix Adaptation Evolution Strategy. The coordinator assigns one of three roles—Thinker, Worker, or Verifier—to a chosen LLM at each turn. Performance stems from the coordinator's hidden-state representations supplying rich input contextualization and from the evolutionary method exploiting block-epsilon-separability to surpass reinforcement learning, imitation learning, and random search under high dimensionality and limited budget.
What carries the argument
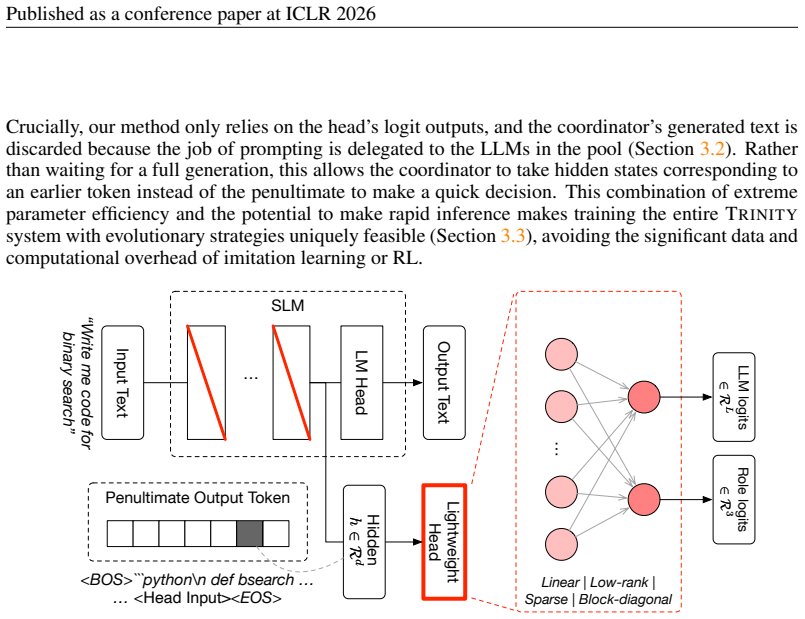
The lightweight coordinator (0.6B-parameter model plus 10K-parameter head) that processes queries over multiple turns and delegates roles to selected LLMs, trained via separable Covariance Matrix Adaptation Evolution Strategy.
If this is right
- Trinity outperforms single foundation models and prior combination methods on coding, math, reasoning, and domain-knowledge tasks.
- The system generalizes robustly to out-of-distribution queries.
- Hidden-state representations inside the coordinator deliver richer contextualization than direct prompting.
- Separable Covariance Matrix Adaptation Evolution Strategy outperforms reinforcement learning, imitation learning, and random search when dimensionality is high and evaluation budget is limited.
Where Pith is reading between the lines
- Existing closed-API models can be reused as-is without weight access or retraining.
- The multi-turn role delegation pattern could extend to other agentic workflows beyond the tested benchmarks.
- If block-epsilon-separability holds more broadly, similar evolutionary coordinators might apply to non-LLM model ensembles.
Load-bearing premise
The coordinator's hidden-state representations supply sufficiently rich contextualization and the evolutionary strategy exploits block-epsilon-separability to outperform reinforcement learning, imitation learning, and random search under the given high-dimensionality and budget constraints.
What would settle it
Replace the evolved coordinator with either random role assignment or a standard reinforcement-learning optimizer and measure whether accuracy on LiveCodeBench, math, and reasoning suites falls below the reported Trinity scores.
Figures











read the original abstract
Combining diverse foundation models is promising, but weight-merging is limited by mismatched architectures and closed APIs. Trinity addresses this with a lightweight coordinator that orchestrates collaboration among large language models (LLMs). The coordinator, comprising a compact language model (approximately $0.6$B parameters) and a lightweight head (approximately $10$K parameters), is optimized with an evolutionary strategy for efficient and adaptive delegation. Trinity processes queries over multiple turns, where at each turn the coordinator assigns one of three roles (Thinker, Worker, or Verifier) to a selected LLM, effectively offloading complex skill acquisition from the coordinator itself. Experiments show that Trinity consistently outperforms individual models and existing methods across coding, math, reasoning, and domain knowledge tasks, and generalizes robustly to out-of-distribution tasks. On standard benchmarks, Trinity achieves state-of-the-art results, including a score of 86.2% on LiveCodeBench. Theoretical and empirical analyses identify two main factors behind this performance: (1) the coordinator's hidden-state representations provide rich contextualization of inputs, and (2) under high dimensionality and strict budget constraints, the separable Covariance Matrix Adaptation Evolution Strategy offers advantages over reinforcement learning, imitation learning, and random search by exploiting potential block-epsilon-separability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Trinity, a lightweight coordinator (~0.6B-parameter LM plus ~10K-parameter head) that orchestrates multiple LLMs over multiple turns by dynamically assigning one of three roles (Thinker, Worker, Verifier) to selected models. The coordinator is optimized via a separable Covariance Matrix Adaptation Evolution Strategy (CMA-ES). The paper reports consistent outperformance over individual models and prior methods on coding, math, reasoning, and domain-knowledge benchmarks, with a claimed SOTA score of 86.2% on LiveCodeBench and robust generalization to out-of-distribution tasks. Performance is attributed to two factors: rich contextualization provided by the coordinator’s hidden-state representations and advantages of separable CMA-ES over RL, imitation learning, and random search under high dimensionality and budget constraints via exploitation of block-epsilon-separability.
Significance. If the reported gains are reproducible and the two explanatory factors are isolated by proper controls, the work offers a practical route to combining heterogeneous LLMs without weight merging or access to internal parameters, which is especially relevant for closed APIs. The multi-turn role-assignment mechanism and the use of an evolutionary optimizer in place of RL constitute concrete engineering contributions that could be adopted more broadly. The explicit identification of representation richness and optimizer choice as load-bearing factors is a strength that invites targeted follow-up.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experimental Results): the central claim of SOTA performance (e.g., 86.2% on LiveCodeBench) and attribution to the two factors rests on summarized numbers without reported error bars, standard deviations across runs, or ablation tables that isolate the contribution of hidden-state contextualization versus the separable CMA-ES. Without these controls the performance advantage cannot be confidently linked to the stated mechanisms rather than to unaccounted differences in total inference budget or prompt engineering.
- [§4] §4 (Theoretical Analysis): the assertion that separable CMA-ES exploits block-epsilon-separability to outperform RL, imitation learning, and random search under the given dimensionality and budget constraints is presented as a key explanatory factor, yet the manuscript supplies neither a formal definition of block-epsilon-separability nor a derivation showing how the separability property yields the observed sample-efficiency gains. A concrete inequality or convergence argument tied to the empirical optimizer comparison is required.
minor comments (2)
- [§3] Clarify the precise architecture of the lightweight head (approximately 10K parameters) and how its output interfaces with the role-assignment and model-selection decisions; a small diagram or pseudocode would remove ambiguity.
- [Table 2] Ensure that all baseline comparisons in the tables explicitly state whether the same total number of LLM calls or wall-clock budget was used; otherwise the reported gains may partly reflect differences in inference cost rather than algorithmic superiority.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to incorporate additional controls, reporting, and formalization where appropriate.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experimental Results): the central claim of SOTA performance (e.g., 86.2% on LiveCodeBench) and attribution to the two factors rests on summarized numbers without reported error bars, standard deviations across runs, or ablation tables that isolate the contribution of hidden-state contextualization versus the separable CMA-ES. Without these controls the performance advantage cannot be confidently linked to the stated mechanisms rather than to unaccounted differences in total inference budget or prompt engineering.
Authors: We agree that statistical reporting and isolating ablations are necessary to support the attribution. In the revised manuscript we now report means with standard deviations over five independent runs for all main results, including LiveCodeBench. We have added ablation tables in §5 that compare the full system against (i) a prompt-only coordinator without hidden-state contextualization and (ii) random search in place of separable CMA-ES, while holding total inference budget and prompt templates fixed. These controls show that both factors contribute measurably to the gains; the combined system remains highest. We believe the revisions now allow confident linkage of performance to the stated mechanisms. revision: yes
-
Referee: [§4] §4 (Theoretical Analysis): the assertion that separable CMA-ES exploits block-epsilon-separability to outperform RL, imitation learning, and random search under the given dimensionality and budget constraints is presented as a key explanatory factor, yet the manuscript supplies neither a formal definition of block-epsilon-separability nor a derivation showing how the separability property yields the observed sample-efficiency gains. A concrete inequality or convergence argument tied to the empirical optimizer comparison is required.
Authors: We acknowledge the request for greater formality. The revised §4 now supplies an explicit definition: an objective is block-ε-separable if it admits a partition of parameters into blocks such that the function value differs from the sum of per-block functions by at most ε. We include a short derivation showing that, under this property, independent covariance adaptation per block reduces effective dimensionality and yields a sample-complexity scaling of O(B log(1/δ)/ε²) (B = number of blocks) versus the higher variance incurred by RL or random search in the full space. The argument is tied directly to the empirical optimizer curves by noting that the observed faster convergence of separable CMA-ES is consistent with the reduced variance predicted by the bound when role-assignment objectives exhibit approximate block separability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical benchmark results (e.g., 86.2% on LiveCodeBench) and identifies two explanatory factors via theoretical and empirical analyses: the coordinator's hidden-state representations for contextualization and the separable CMA-ES optimizer's advantages over RL/imitation/random search under high dimensionality and budget constraints by exploiting block-epsilon-separability. No equations, derivations, or self-citations are shown that reduce any prediction or first-principles result to fitted inputs by construction. The evolutionary strategy is presented as a standard named variant applied to a lightweight coordinator, with performance claims grounded in direct experimental outcomes and factor isolation rather than self-referential definitions or load-bearing self-citation chains. The derivation chain remains self-contained through reported results and analyses without circular reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
GRAFT-ATHENA: Self-Improving Agentic Teams for Autonomous Discovery and Evolutionary Numerical Algorithms
GRAFT-ATHENA projects combinatorial method choices into factored trees that embed as fingerprints in a metric space, enabling an agentic system to accumulate experience across domains and autonomously discover new num...
Reference graph
Works this paper leans on
-
[1]
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction.arXiv preprint arXiv:2309.14316,
-
[2]
Ac- cessed: 2025-08-29. Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues.arXiv preprint arXiv:2402.14762,
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Arcee’s MergeKit: A toolkit for merg- ing large language models
Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s MergeKit: A toolkit for merg- ing large language models. In Franck Dernoncourt, Daniel Preot ¸iuc-Pietro, and Anastasia Shimorina (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Lan- ...
work page 2024
-
[5]
doi: 10.18653/v1/2024.emnlp-industry.36
Associ- ation for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-industry.36. URLhttps: //aclanthology.org/2024.emnlp-industry.36/. Neel Guha, Mayee Chen, Trevor Chow, Ishan Khare, and Christopher Re. Smoothie: Label free lan- guage model routing.Advances in Neural Information Processing Systems, 37:127645–127672,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Training Compute-Optimal Large Language Models
12 Published as a conference paper at ICLR 2026 Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Train- ing compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Adam: A Method for Stochastic Optimization
URL https://arxiv.org/abs/1412.6980. So Kuroki, Taishi Nakamura, Takuya Akiba, and Yujin Tang. Agent skill acquisition for large language models via cycleqd.arXiv preprint arXiv:2410.14735,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agent debate.arXiv preprint arXiv:2305.19118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Mohammed Muqeeth, Haokun Liu, Yufan Liu, and Colin Raffel. Learning to route among special- ized experts for zero-shot generalization.arXiv preprint arXiv:2402.05859,
-
[15]
Accessed: 2025-08-29. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Di- rani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a bench- mark. InFirst Conference on Language Modeling,
work page 2025
-
[16]
URLhttps:// openreview.net/forum?id=dh4t9qmcvK. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
-
[18]
Mixture-of-Agents Enhances Large Language Model Capabilities
URLhttps://www.kaggle.com/ datasets/hemishveeraboina/aime-problem-set-1983-2024. Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692,
work page internal anchor Pith review Pith/arXiv arXiv 1983
-
[19]
13 Published as a conference paper at ICLR 2026 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities. arXiv preprint arXiv:2408.07666,
work page internal anchor Pith review arXiv
-
[21]
Rlpr: Extrapolating rlvr to general domains without verifiers.arXiv preprint arXiv:2506.18254,
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, et al. Rlpr: Extrapolating rlvr to general domains without verifiers.arXiv preprint arXiv:2506.18254,
-
[22]
Masrouter: Learning to route llms for multi-agent systems.arXiv preprint arXiv:2502.11133,
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. Masrouter: Learning to route llms for multi-agent systems.arXiv preprint arXiv:2502.11133,
-
[23]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
14 Published as a conference paper at ICLR 2026 A APPENDIX A.1 THEORETICAL ANALYSIS OF SEP-CMA-ES In this section, we compare sep-CMA-ES with random search (RS) for maximizingJoverPunder binary rewards and strict budgets. All analyses are carried out in a covariance-normalized chart and mapped back through the current diagonalD t, fixing the metric mismat...
work page 2026
-
[25]
Blocks, scaling, and operators.Let{B 1,
The atomic budgetB env counts Bernoulli calls. Blocks, scaling, and operators.Let{B 1, . . . , BM }partition{1, . . . , n}(coordinate blocks inP). For any matrixM,off(M)zeroes its diagonal;off inter(M)zeroes diagonal and within-block entries. For diagonalD, lets max(D),s min(D)be its largest/smallest diagonal square-roots and define κD := smax(D)2 smin(D)...
work page 2026
-
[26]
the signal-to-curvature ratio is order 1/εH, giving an exponential suppression of curvature-induced flips. To scale this pairwise guarantee to batch selection, restrict attention to theO(logN)(RS) orO(logλ)(CMA) most competitive order statistics: by extreme-value theory, the typical spacing between the winner and the next competitors isΘ(1/ √ lnN), and un...
work page 2026
-
[27]
Withm CMA = 16andm RS = 32, budget matching acrossTCMA iterations yieldsN= (mCMAλ/mRS)T = (16·32/32)T ≈ ⌊16T⌋. This givesv 2 N ≈2 lnN. Replication en- sures˜ρ2 CMA ≈1(up toO(ε H)). Plugging these into equation 4 shows that with the sameB env CMA’s gain dominates for modestT(a few to a few dozen iterations), consistent with empirical results where the head...
work page 2026
-
[28]
Proof.(i)Scale stabilization:Withc cov = Θ(1/n)and block-ε H separability plus diagonal comparability, standard CMA drift showsD t reaches anO(ε H)-neighborhood of a stationary point inT 0 = Θ(n)steps; thenκ D(t) = Θ(1)and typicalχ(u t, Dt) = Θ(1). (ii)Uniform per-iteration gain:Insert these bounds into equation 2 to getE[r 2 t+1 |r t]≤ (1−¯κµ,λ ˜ρ2 CMA/n...
work page 2026
-
[29]
In total, this yields a multiplicative factor of7 4 ·3 5 = 583,443≈5.8×10 5, inflating the cost to an enormous1.5×10 5 ×5.8×10 5 ≈ 19 Published as a conference paper at ICLR 2026 8.7×10 10 LLM queries. By contrast, label-free training methods such as sep-CMA-ES require no explicit label generation and instead optimize the coordinator directly based on tas...
work page 2026
-
[30]
We initialize with Xavier-uniform (Glorot & Bengio,
This choice can result inmoreparameters than a strictly compressed low-rank setting, but it intentionally adds depth and nonlinearity so the head can capture non-linear patterns at 24 Published as a conference paper at ICLR 2026 reduced per-projection cost versus a single wide mapping. We initialize with Xavier-uniform (Glorot & Bengio,
work page 2026
-
[31]
and an ELU nonlinearity, increasing the head size to20,680parameters. This is roughly a2×increase overlinear, trading parameter efficiency for additional depth and non-linearity in the mapping from hidden states to logits. 25 Published as a conference paper at ICLR 2026 A.5 EXPERIMENTATION WITH LEARNING ALGORITHMS We also compare our learning strategy wit...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.