Training Language Models to Use Prolog as a Tool
Pith reviewed 2026-05-17 01:12 UTC · model grok-4.3
The pith
Training language models to use Prolog as a tool uncovers a trade-off where reward focus on correctness yields higher accuracy but delegates reasoning to natural language, while symbolic rewards enforce auditable full programs at lower peak
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
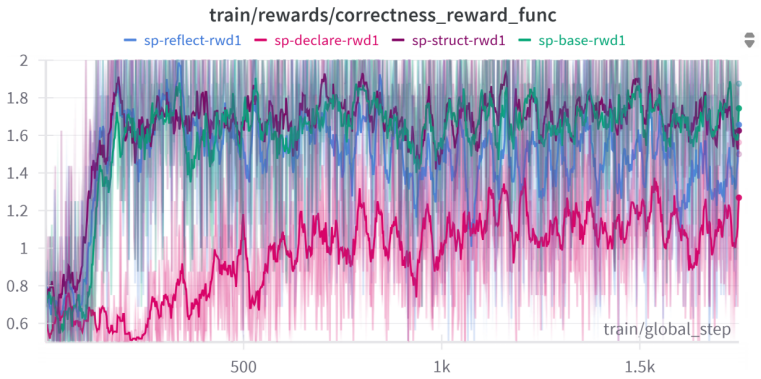
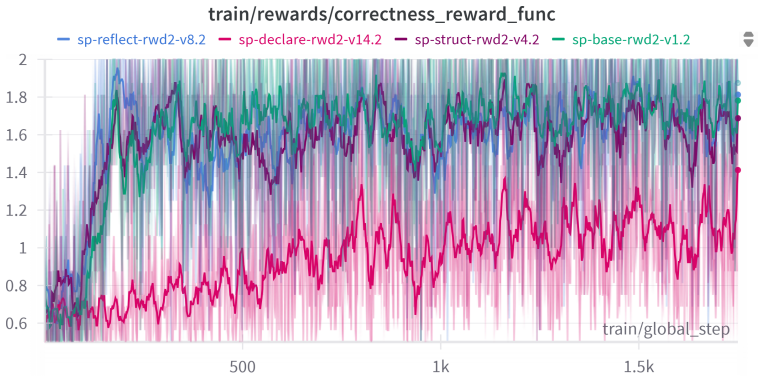
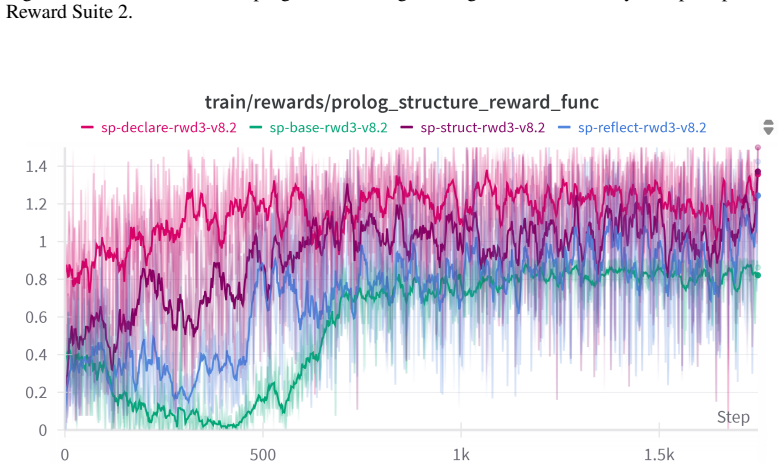
Configurations rewarded primarily for execution success learn to perform most reasoning inside natural language and invoke Prolog only for the final arithmetic step, achieving higher accuracy on GSM8K and competitive zero-shot results on MMLU-STEM and MMLU-Pro; configurations that also reward syntactic, semantic, and structural properties force the model to emit complete, self-contained Prolog programs that remain fully auditable yet incur a measurable drop in overall accuracy.
What carries the argument
The composition of reward signals (execution success, syntax, semantics, and symbolic structure) inside Group Relative Policy Optimization (GRPO) that steers the model between hybrid natural-language-plus-Prolog and fully symbolic program generation.
If this is right
- Accuracy-tuned models can match or exceed larger few-shot baselines on STEM benchmarks while still using an external symbolic engine for the last step.
- Structure-tuned models produce reasoning traces that can be read, verified, and debugged without inspecting the model's internal activations.
- Deploying neurosymbolic systems in safety-critical settings may require accepting an accuracy penalty to obtain verifiable symbolic artifacts.
- The same reward-composition technique can be applied to other external symbolic or formal tools beyond Prolog.
Where Pith is reading between the lines
- The trade-off may appear with any external verifier or solver once the model learns it can outsource reasoning to natural language.
- Hybrid reward functions that gradually increase the weight on symbolic structure could reduce the accuracy cost while preserving auditability.
- Measuring the length and complexity of the natural-language prefix before the first Prolog call offers a simple proxy for how much reasoning has been delegated.
Load-bearing premise
The observed behavioral split between reward settings is caused mainly by the reward signals themselves rather than by limits on model size, prompt wording, or quirks of the Prolog interpreter.
What would settle it
Retraining the same model with identical prompts and data but with structure rewards removed, then checking whether the model still produces fully symbolic Prolog programs or reverts to natural-language delegation.
Figures




read the original abstract
Language models frequently produce plausible yet incorrect reasoning traces that are difficult to verify. We investigate fine-tuning models to use Prolog as an external symbolic reasoning tool, training Qwen2.5-3B-Instruct with Group Relative Policy Optimization (GRPO) on a cleaned version of GSM8K (which we release as gsm8k-prolog-prover). We systematically vary prompt structure, reward composition (execution, syntax, semantics, structure), and inference protocol (single-try, multiple-try, and two agentic modes). Our reinforcement learning approach outperforms supervised fine-tuning on GSM8K, and the resulting 3B model achieves zero-shot performance on MMLU-STEM and MMLU-Pro competitive with 7B few-shot baselines. Most importantly, we identify an accuracy--auditability trade-off: configurations tuned for correctness alone learn to delegate reasoning to natural language and use Prolog only for the final computation, while configurations rewarded for symbolic structure produce fully auditable programs at a cost in accuracy. We interpret this trade-off as a form of reward hacking and discuss its implications for deploying neurosymbolic systems in safety-critical domains. The source code for our experiments is available under https://github.com/aisilab/Prolog-as-a-Tool
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates fine-tuning Qwen2.5-3B-Instruct with Group Relative Policy Optimization (GRPO) to use Prolog as an external symbolic tool for mathematical reasoning. Using a cleaned GSM8K dataset (released as gsm8k-prolog-prover), the authors systematically vary prompt structure, reward composition (execution, syntax, semantics, structure), and inference protocols (single-try, multiple-try, agentic). They report that the RL approach outperforms supervised fine-tuning on GSM8K, that the 3B model achieves zero-shot MMLU-STEM and MMLU-Pro performance competitive with 7B few-shot baselines, and that an accuracy-auditability trade-off emerges: correctness-focused rewards lead models to delegate reasoning to natural language while using Prolog only for final computation, whereas structure-focused rewards produce fully auditable programs at the cost of accuracy. The trade-off is interpreted as reward hacking with implications for neurosymbolic systems in safety-critical domains.
Significance. If the reported behavioral differences can be causally attributed to reward composition, the work provides a concrete demonstration of how reward design shapes tool-use strategies in LLMs and surfaces a practically relevant tension between correctness and verifiability. The public release of the dataset and code supports reproducibility and further research on neurosymbolic integration.
major comments (1)
- §4 (Experimental Setup) and §5 (Results): The central claim that reward composition alone produces the accuracy-auditability split is not isolated from confounders. The design varies prompt structure and inference protocol concurrently with reward type; no fixed-prompt ablations or interaction statistics are reported that would hold prompt wording and protocol constant while changing only the reward signals. Without such controls, the observed delegation to natural language under correctness rewards cannot be securely attributed to the reward functions rather than prompt engineering details or the 3B model's capacity limits.
minor comments (2)
- Abstract: The claims of outperformance over SFT and competitive MMLU results are stated without any numerical values, error bars, or statistical tests. These quantitative details should appear in the abstract or be clearly signposted to the relevant tables/figures.
- Figures and tables: Ensure that all plots and result tables explicitly label the reward composition, prompt variant, and inference protocol for each condition so that readers can directly map configurations to the described behavioral differences.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern about potential confounders in attributing the accuracy-auditability trade-off specifically to reward composition is well-taken. We address this point directly below and outline the revisions we will make to strengthen the causal claims.
read point-by-point responses
-
Referee: §4 (Experimental Setup) and §5 (Results): The central claim that reward composition alone produces the accuracy-auditability split is not isolated from confounders. The design varies prompt structure and inference protocol concurrently with reward type; no fixed-prompt ablations or interaction statistics are reported that would hold prompt wording and protocol constant while changing only the reward signals. Without such controls, the observed delegation to natural language under correctness rewards cannot be securely attributed to the reward functions rather than prompt engineering details or the 3B model's capacity limits.
Authors: We acknowledge that our experimental design varies prompt structure and inference protocol alongside reward type, and that we did not include dedicated fixed-prompt ablations or report interaction statistics that would hold those factors strictly constant. While the systematic variation across configurations produced consistent behavioral patterns supporting the trade-off, this does limit the strength of isolating reward composition as the sole causal factor. To address the concern, we will add new controlled experiments in the revision that fix prompt wording and inference protocol while varying only the reward signals, along with any relevant interaction analyses. These additions will allow a clearer attribution of the delegation behavior to reward design. revision: yes
Circularity Check
No circularity: empirical trade-off claims rest on external benchmarks and controlled variations
full rationale
The paper reports results from RL fine-tuning experiments (GRPO on Qwen2.5-3B) with systematic ablations over prompt structure, reward composition (execution/syntax/semantics/structure), and inference protocols. The accuracy-auditability trade-off is presented as an observed behavioral pattern across these runs, evaluated zero-shot on MMLU-STEM/MMLU-Pro and on the released gsm8k-prolog-prover dataset. No equations, fitted parameters, or self-citations are used to derive the central claim; the result is directly measured against external data and does not reduce to its inputs by construction. This is a standard empirical finding with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify an accuracy--auditability trade-off: configurations tuned for correctness alone learn to delegate reasoning to natural language and use Prolog only for the final computation, while configurations rewarded for symbolic structure produce fully auditable programs at a cost in accuracy.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
PrologMCP: A Standardized Prolog Tool Interface for LLM Agents
PrologMCP is a standardized MCP server for Prolog that lets LLM agents delegate inference, achieving near-perfect accuracy on PARARULE-Plus subsets where reasoning LLMs drop to 0.94-0.95.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.