Recognition: 1 theorem link
· Lean TheoremBOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models
Pith reviewed 2026-05-16 23:15 UTC · model grok-4.3
The pith
BOOST introduces bottleneck-aware tensor parallelism to train low-rank LLMs 1.46-2.27x faster than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
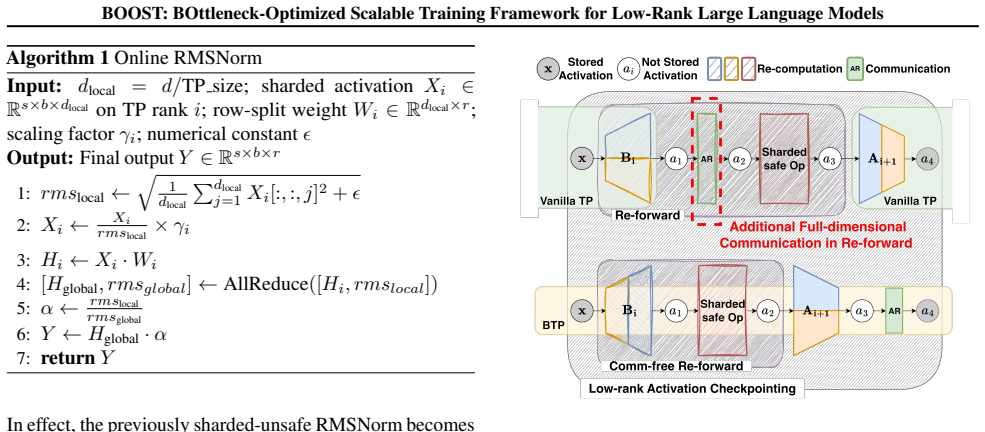
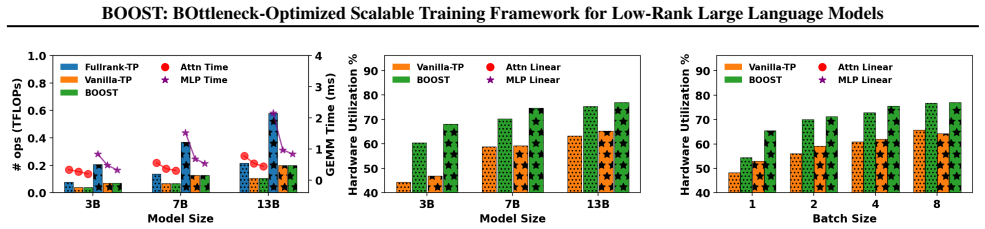
BOOST achieves 1.46-1.91× speedup over full-rank model baselines and 1.87-2.27× speedup over low-rank models with naively integrated 3D parallelism by replacing standard tensor parallelism with a bottleneck-aware variant and adding online-RMSNorm, linear layer grouping, and low-rank activation checkpointing, all while preserving convergence behavior.
What carries the argument
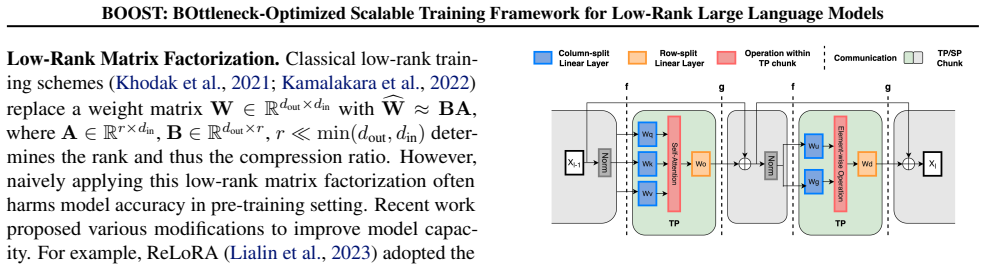
Bottleneck-aware Tensor Parallelism, a distribution strategy that aligns tensor shards with the low-rank bottleneck structure to cut communication volume and raise GPU utilization.
If this is right
- Low-rank models become practical for pre-training at the scale where full-rank training is currently required.
- Existing 3D parallelism libraries must be extended with bottleneck awareness to deliver their advertised efficiency on compressed architectures.
- Memory savings from low-rank factors translate directly into longer context lengths or larger batch sizes on fixed GPU counts.
- Communication-bound stages in the training pipeline shrink, improving overall cluster throughput.
Where Pith is reading between the lines
- The same communication-reduction logic could be applied to other structured low-rank or sparse linear layers beyond the tested bottlenecks.
- Hardware schedulers that detect low-rank matrix shapes might achieve similar utilization gains without software changes.
- If the pattern generalizes, inference serving stacks for low-rank models would also benefit from analogous parallelism adjustments.
Load-bearing premise
The proposed optimizations keep model accuracy and convergence unchanged without any hyperparameter retuning.
What would settle it
Run the same low-rank model to the same token count on identical hardware once with BOOST and once with naive 3D parallelism; if final validation loss or downstream accuracy is materially worse under BOOST, the central claim does not hold.
Figures





read the original abstract
The scale of transformer model pre-training is constrained by the increasing computation and communication cost. Low-rank bottleneck architectures offer a promising solution to significantly reduce the training time and memory footprint with minimum impact on accuracy. Despite algorithmic efficiency, bottleneck architectures scale poorly under standard tensor parallelism. Simply applying 3D parallelism designed for full-rank methods leads to excessive communication and poor GPU utilization. To address this limitation, we propose BOOST, an efficient training framework tailored for large-scale low-rank bottleneck architectures. BOOST introduces a novel Bottleneck-aware Tensor Parallelism, and combines optimizations such as online-RMSNorm, linear layer grouping, and low-rank activation checkpointing to achieve end-to-end training speedup. Evaluations on different low-rank bottleneck architectures demonstrate that BOOST achieves 1.46-1.91$\times$ speedup over full-rank model baselines and 1.87-2.27$\times$ speedup over low-rank model with naively integrated 3D parallelism, with improved GPU utilization and reduced communication overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BOOST, a training framework for low-rank bottleneck LLMs that introduces Bottleneck-aware Tensor Parallelism together with online-RMSNorm, linear layer grouping, and low-rank activation checkpointing. It claims these changes deliver 1.46-1.91× end-to-end speedup versus full-rank baselines and 1.87-2.27× versus low-rank models using naive 3D parallelism, while improving GPU utilization, cutting communication volume, and incurring only minimum impact on accuracy.
Significance. If the reported speedups are shown to hold with unchanged convergence and final accuracy, the framework would provide a practical route to scale low-rank architectures on large clusters, directly addressing the communication and utilization bottlenecks that currently limit their adoption.
major comments (2)
- [Abstract and §5] Abstract and §5: The central claim that the optimizations produce “minimum impact on accuracy” is unsupported; no perplexity values, loss curves, final accuracy deltas, or statements confirming identical learning-rate schedules, warmup, and optimizer settings across baselines are provided, leaving open the possibility that speedups were measured at non-comparable training points.
- [§5.1 and Table 2] §5.1 and Table 2 (speedup results): Reported factors of 1.46-1.91× and 1.87-2.27× lack error bars, number of runs, exact model dimensions, and hardware counts; without these, statistical reliability of the cross-architecture and cross-parallelism comparisons cannot be assessed.
minor comments (2)
- [§4.2] Clarify whether the Bottleneck-aware Tensor Parallelism introduces any additional hyperparameters and state their values explicitly.
- [§5] Add a short paragraph in §5 comparing peak memory usage and communication volume with quantitative numbers for each configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to provide the requested supporting evidence and statistical details.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5: The central claim that the optimizations produce “minimum impact on accuracy” is unsupported; no perplexity values, loss curves, final accuracy deltas, or statements confirming identical learning-rate schedules, warmup, and optimizer settings across baselines are provided, leaving open the possibility that speedups were measured at non-comparable training points.
Authors: We acknowledge that the current version of the manuscript does not include explicit perplexity tables, loss curves, or a dedicated statement confirming identical hyperparameter settings. All reported experiments were in fact run with the same learning-rate schedule, warmup steps, optimizer, and batch size across full-rank and low-rank models. We will add a new paragraph in §5 together with a supplementary table listing final perplexity values and a figure showing training loss curves to substantiate the “minimum impact” claim. revision: yes
-
Referee: [§5.1 and Table 2] §5.1 and Table 2 (speedup results): Reported factors of 1.46-1.91× and 1.87-2.27× lack error bars, number of runs, exact model dimensions, and hardware counts; without these, statistical reliability of the cross-architecture and cross-parallelism comparisons cannot be assessed.
Authors: We agree that error bars and run counts are needed for rigorous evaluation. The experiments were performed on a 64-GPU A100 cluster using the exact model dimensions listed in Table 1. We will revise Table 2 to report mean speedups with standard deviations obtained from five independent runs per configuration and will add the precise hardware count and model dimensions to the table caption. revision: yes
Circularity Check
No circularity: empirical speedups measured against external baselines
full rationale
The paper presents BOOST as an engineering framework of concrete optimizations (Bottleneck-aware Tensor Parallelism, online-RMSNorm, linear layer grouping, low-rank activation checkpointing) whose claimed benefits are quantified by direct wall-clock measurements on concrete model runs. No equations, fitted parameters, or self-citations are shown to reduce the reported 1.46-1.91× or 1.87-2.27× speedups to quantities defined inside the paper itself. The performance numbers are therefore external benchmarks rather than self-referential predictions, satisfying the default expectation of a non-circular systems paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ReCoVer: Resilient LLM Pre-Training System via Fault-Tolerant Collective and Versatile Workload
ReCoVer uses fault-tolerant collectives, in-step recovery, and dynamic microbatch redistribution to maintain training trajectory equivalence under GPU failures, delivering 2.23x higher effective throughput than checkp...
Reference graph
Works this paper leans on
-
[1]
Pretraining Large Language Models with NVFP4, September 2025
Abecassis, F., Agrusa, A., Ahn, D., Alben, J., Alborghetti, S., Andersch, M., Arayandi, S., Bjorlin, A., Blakeman, A., Briones, E., et al. Pretraining large language models with nvfp4.arXiv preprint arXiv:2509.25149,
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[4]
Chen, Y ., Zhang, Y ., Liu, Y ., Yuan, K., and Wen, Z. A memory efficient randomized subspace optimization method for training large language models.arXiv preprint arXiv:2502.07222,
-
[5]
FP4 All the Way: Fully Quantized Training of LLMs, August 2025
Chmiel, B., Fishman, M., Banner, R., and Soudry, D. Fp4 all the way: Fully quantized training of llms.arXiv preprint arXiv:2505.19115,
-
[6]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
R., Locatelli, A., Venkitesh, B., Ba, J., Gal, Y., and Gomez, A
Kamalakara, S. R., Locatelli, A., Venkitesh, B., Ba, J., Gal, Y ., and Gomez, A. N. Exploring low rank training of deep neural networks.arXiv preprint arXiv:2209.13569,
-
[8]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
Ini- tialization and regularization of factorized neural layers
Khodak, M., Tenenholtz, N., Mackey, L., and Fusi, N. Ini- tialization and regularization of factorized neural layers. arXiv preprint arXiv:2105.01029,
-
[10]
CR-Net: Scaling Parameter-Efficient Training with Cross-Layer Low-Rank Structure
Kong, B., Liang, J., Liu, Y ., Deng, R., and Yuan, K. Cr- net: Scaling parameter-efficient training with cross-layer low-rank structure.arXiv preprint arXiv:2509.18993,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Available online: https://aws.amazon.com/blogs/machine- learning/end-to-end-llm-training- on-instance-clusters-with-over-100- nodes-using-aws-trainium/ (accessed Oct 2025). Lepikhin, D., Lee, H., Xu, Y ., Chen, D., Firat, O., Huang, Y ., Krikun, M., Shazeer, N., and Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding,
work page 2025
-
[12]
Lost: Low-rank and sparse pre-training for large language models.arXiv preprint arXiv:2508.02668,
BOOST: BOttleneck-Optimized Scalable Training Framework for Low-Rank Large Language Models Li, J., Yin, L., Shen, L., Xu, J., Xu, L., Huang, T., Wang, W., Liu, S., and Wang, X. Lost: Low-rank and sparse pre-training for large language models.arXiv preprint arXiv:2508.02668,
-
[13]
Relora: High-rank training through low-rank updates
Lialin, V ., Shivagunde, N., Muckatira, S., and Rumshisky, A. Relora: High-rank training through low-rank updates. arXiv preprint arXiv:2307.05695,
-
[14]
Liang, W., Liu, T., Wright, L., Constable, W., Gu, A., Huang, C.-C., Zhang, I., Feng, W., Huang, H., Wang, J., et al. Torchtitan: One-stop pytorch native solution for production ready llm pre-training.arXiv preprint arXiv:2410.06511,
-
[15]
Cola: Compute- efficient pre-training of llms via low-rank activation
Liu, Z., Zhang, R., Wang, Z., Yang, Z., Hovland, P., Nico- lae, B., Cappello, F., and Zhang, Z. Cola: Compute- efficient pre-training of llms via low-rank activation. arXiv preprint arXiv:2502.10940,
-
[16]
Micikevicius, P., Stosic, D., Burgess, N., Cornea, M., Dubey, P., Grisenthwaite, R., Ha, S., Heinecke, A., Judd, P., Kamalu, J., et al. Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313,
Peng, H., Wu, K., Wei, Y ., Zhao, G., Yang, Y ., Liu, Z., Xiong, Y ., Yang, Z., Ni, B., Hu, J., et al. Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313,
-
[18]
Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241,
Qi, P., Wan, X., Huang, G., and Lin, M. Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241,
-
[19]
URL https://epoch.ai/data-insights/grok- 4-training-resources. Accessed: 2025-10-25. Shamshoum, Y ., Hodos, N., Sieradzki, Y ., and Schuster, A. Compact: Compressed activations for memory-efficient llm training.arXiv preprint arXiv:2410.15352,
-
[20]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[21]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi- billion parameter language models using model paral- lelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[22]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[23]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
URL https://openreview.net/forum? id=LNYIUouhdt. Workshop, B., Scao, T. L., Fan, A., Akiki, C., Pavlick, E., Ili´c, S., Hesslow, D., Castagn´e, R., Luccioni, A. S., Yvon, F., et al. Bloom: A 176b-parameter open-access multilin- gual language model.arXiv preprint arXiv:2211.05100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Xu, Y ., Lee, H., Chen, D., Hechtman, B., Huang, Y ., Joshi, R., Krikun, M., Lepikhin, D., Ly, A., Maggioni, M., et al. Gspmd: general and scalable parallelization for ml com- putation graphs.arXiv preprint arXiv:2105.04663,
-
[25]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y ., Wang, L., Xiao, Z., et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089,
work page internal anchor Pith review arXiv
-
[26]
Zhang, R., Liu, Z., Wang, Z., and Zhang, Z
URL https:// openreview.net/forum?id=i0zzO7Hslk. Zhang, R., Liu, Z., Wang, Z., and Zhang, Z. Lax: Boost- ing low-rank training of foundation models via latent crossing.arXiv preprint arXiv:2505.21732,
-
[27]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., and Tian, Y . Galore: Memory-efficient llm train- ing by gradient low-rank projection.arXiv preprint arXiv:2403.03507,
work page internal anchor Pith review arXiv
-
[29]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Zhao, Y ., Gu, A., Varma, R., Luo, L., Huang, C.-C., Xu, M., Wright, L., Shojanazeri, H., Ott, M., Shleifer, S., et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Zhu, H., Zhang, Z., Cong, W., Liu, X., Park, S., Chandra, V ., Long, B., Pan, D. Z., Wang, Z., and Lee, J. Apollo: Sgd- like memory, adamw-level performance.arXiv preprint arXiv:2412.05270,
-
[31]
We use a canonical low rankr=d/4
Model configuration (LLaMA-style). We use a canonical low rankr=d/4. Model size Layers headd d f f r 1B 24 32 2048 5472 512 3B 28 24 3072 8192 768 7B 32 32 4096 11008 1024 13B 40 40 5120 13824 1280 30B 36 64 8192 22016 2048 A.4 Linear Grouping Details Figure 8 details our linear-grouping implementation. In BTP, the first down-projection is row-parallel; w...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.