PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning
Pith reviewed 2026-05-16 13:06 UTC · model grok-4.3
The pith
PEARL uses reinforcement learning and an external memory of inferred preferences to cut errors in resolving calendar conflicts by 55 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
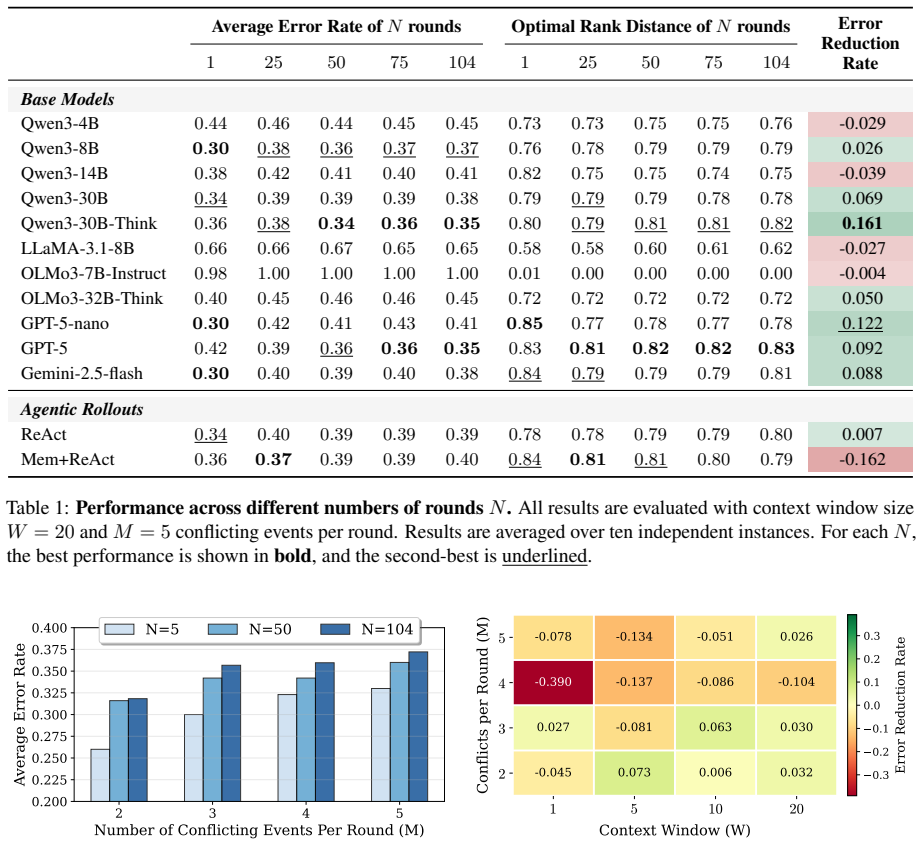
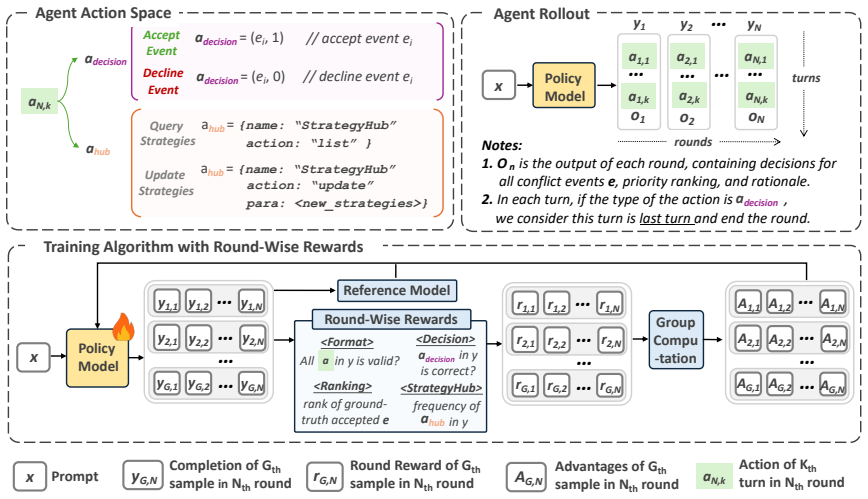
PEARL augments a language agent with an external preference memory that stores and updates strategies such as attendee priorities and topic importance, then optimizes the agent through round-wise rewards that directly supervise decision correctness, ranking quality, and memory usage across a full year of simulated conflicts, producing an error reduction rate of 0.76 and a 55 percent improvement in average error rate over the strongest baseline on CalConflictBench.
What carries the argument
An external preference memory paired with round-wise reinforcement learning rewards that let the agent accumulate and apply inferred user strategies across sequential conflict rounds.
If this is right
- Agents can build and refine a running model of user priorities instead of treating each conflict in isolation.
- Decision accuracy improves steadily as the memory accumulates evidence from prior rounds.
- Ranking of options such as attend, reschedule, or decline becomes more consistent with the stored preferences.
- Memory updates remain efficient because rewards penalize unnecessary or incorrect entries.
Where Pith is reading between the lines
- The same memory-plus-reward structure could transfer to other sequential preference tasks such as email triage or project task ordering.
- Long-horizon performance gains suggest external memory can mitigate context-window limits that currently hinder language agents on year-scale problems.
- If the method scales, it points toward assistants that require less frequent human correction once initial preferences are observed.
Load-bearing premise
The synthetic conflicts and preference signals in the benchmark match the patterns real users would follow when choosing among overlapping meetings.
What would settle it
Testing the same agent on a set of real user calendars with logged choices and explicit preference feedback to check whether the error reduction holds outside the synthetic data.
Figures




read the original abstract
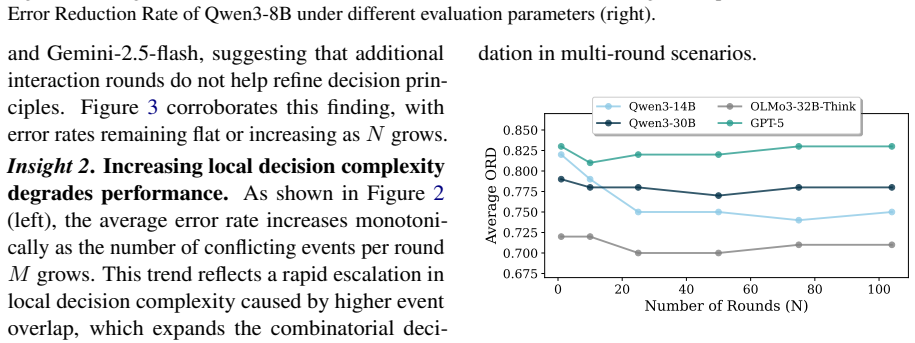
Overlapping calendar invitations force busy professionals to repeatedly decide which meetings to attend, reschedule, or decline. We refer to this preference-driven decision process as calendar conflict resolution. Automating this decision process is crucial yet challenging. Scheduling logistics can drain hours, and human delegation often fails at scale, which motivates us to ask: Can we trust large language models (LLMs) or language agents to manage time? To enable a systematic study of this question, we introduce CalConflictBench, a benchmark for long-horizon calendar conflict resolution. In CalConflictBench, conflicts are presented to agents round-by-round over a calendar year, requiring them to infer and adapt to user preferences progressively. Our experiments show that current LLM agents perform poorly with high error rates, e.g., Qwen-3-30B-Think has an average error rate of 35%. To address this gap, we propose PEARL, a reinforcement-learning framework that (i) augments the language agent with an external preference memory that stores and updates inferred strategies (e.g., attendee priorities, topic importance, time/location preferences), and (ii) optimizes the agent with round-wise rewards that directly supervise decision correctness, ranking quality, and memory usage across rounds. Experiments on CalConflictBench show that PEARL achieves an error reduction rate of 0.76 and a 55% improvement in average error rate compared to the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CalConflictBench, a benchmark for long-horizon calendar conflict resolution in which agents resolve overlapping invitations round-by-round over a simulated year by progressively inferring user preferences. It proposes PEARL, an RL framework that augments an LLM agent with an external preference memory storing inferred strategies (attendee priorities, topic importance, etc.) and optimizes the agent via round-wise rewards on decision correctness, ranking quality, and memory usage. Experiments report that PEARL achieves a 0.76 error reduction rate and 55% improvement in average error rate over the strongest baseline (e.g., Qwen-3-30B-Think at 35% error).
Significance. If the benchmark faithfully captures real scheduling behavior and the RL updates generalize, the work would provide a concrete, reproducible path toward reliable LLM-based time-management agents, a practical capability with clear user impact. The explicit external memory plus round-wise supervision is a clean architectural contribution that could be adapted to other long-horizon preference-learning settings.
major comments (3)
- [Benchmark construction] Benchmark construction (CalConflictBench section): the paper provides no explicit description of the generative rules for synthetic conflicts, preference signals, or priority weighting, so it is impossible to judge whether the reported 0.76 error reduction and 55% improvement reflect genuine time-management capability or benchmark-specific artifacts.
- [Experiments] Reward definition and evaluation (Experiments section): round-wise rewards are defined directly against the same benchmark-internal ground truth used for final metrics, creating a circularity risk that optimization success may be tied to the reward formulation rather than independent external validation.
- [Results] Experimental reporting (Results subsection): aggregate numbers (0.76 reduction, 55% improvement) are given without statistical tests, error bars, number of runs, or controls for overfitting in the RL loop, making it impossible to assess the reliability of the headline gains.
minor comments (2)
- [Method] Notation for the external preference memory is introduced without a formal update equation or pseudocode, which would help readers replicate the self-evolution mechanism.
- [Abstract] The abstract cites Qwen-3-30B-Think; the main text should clarify whether this is an off-the-shelf model or a fine-tuned variant.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (CalConflictBench section): the paper provides no explicit description of the generative rules for synthetic conflicts, preference signals, or priority weighting, so it is impossible to judge whether the reported 0.76 error reduction and 55% improvement reflect genuine time-management capability or benchmark-specific artifacts.
Authors: We agree that the original manuscript lacked sufficient detail on benchmark construction. In the revised version, we will add a new subsection under CalConflictBench that explicitly describes the generative rules for synthetic conflicts, the sampling of preference signals (including how they are revealed progressively across rounds), and the priority weighting scheme for attendees, topics, and time preferences. This will allow readers to assess the benchmark's fidelity and the generalizability of our results. revision: yes
-
Referee: [Experiments] Reward definition and evaluation (Experiments section): round-wise rewards are defined directly against the same benchmark-internal ground truth used for final metrics, creating a circularity risk that optimization success may be tied to the reward formulation rather than independent external validation.
Authors: We acknowledge the referee's concern regarding potential circularity. The round-wise rewards focus on immediate per-round outcomes (decision correctness and ranking quality), whereas the primary evaluation metrics measure long-horizon error reduction and preference inference across the full simulated year. To strengthen the paper, we will add a clarifying paragraph distinguishing these aspects and include an ablation study using proxy-based rewards (e.g., based on simulated user feedback rather than direct ground truth) to demonstrate that performance gains are not solely due to the reward formulation. revision: partial
-
Referee: [Results] Experimental reporting (Results subsection): aggregate numbers (0.76 reduction, 55% improvement) are given without statistical tests, error bars, number of runs, or controls for overfitting in the RL loop, making it impossible to assess the reliability of the headline gains.
Authors: We agree that the experimental reporting requires greater statistical rigor. In the revised manuscript, we will update the Results section to report all metrics as means over 5 independent runs with standard deviations, include error bars in figures, perform paired statistical significance tests against baselines, and add details on the RL training procedure (including validation splits and early stopping criteria) to address potential overfitting concerns. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper introduces CalConflictBench and defines round-wise rewards to supervise decision correctness, ranking quality, and memory usage, then reports empirical error reduction (0.76) and improvement (55%) versus baselines after RL optimization. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations are present that would make the performance result equivalent to the inputs by construction. The derivation consists of a proposed framework and comparative experiments on the introduced benchmark rather than a tautological identity or forced uniqueness theorem. This is a standard empirical setup and scores as self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User preferences are stable enough to be captured by a memory that updates across rounds without external validation.
invented entities (1)
-
external preference memory
no independent evidence
Forward citations
Cited by 1 Pith paper
-
BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery
BioInsight is a multi-agent system that generates interactive, provenance-preserving biomedical evidence interfaces from disease names and protein data.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.