Recognition: 2 theorem links
· Lean TheoremiPDB -- Optimizing Semantic SQL Queries
Pith reviewed 2026-05-16 12:25 UTC · model grok-4.3
The pith
iPDB adds a relational predict operator so SQL can run LLM and ML calls directly inside the database engine.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
iPDB supplies an extended relational algebra with a predict operator that materializes LLM and ML inference results as relational columns or predicates; combined with rewrite rules for semantic selects, joins, and group-by clauses, this lets a single database engine execute semantic SQL queries end-to-end.
What carries the argument
The predict operator, which embeds model inference as a relational primitive that can be pushed down, pruned, or batched by the optimizer.
If this is right
- Semantic joins become first-class operations that can be costed and reordered by the query planner.
- Model calls can be batched across multiple rows inside the engine instead of being issued one at a time from application code.
- Unstructured text columns can participate in standard SQL aggregates without leaving the database.
- Existing SQL applications can add LLM predicates with only syntax changes rather than data-export pipelines.
Where Pith is reading between the lines
- The same predict operator could be reused for other external functions such as image or graph models once their interfaces are wrapped.
- If the optimizer rules generalize, they might apply to any black-box user-defined function that returns scalar or tuple results.
- Workloads that currently export data to separate ML serving layers could be consolidated, reducing network round-trips and consistency issues.
Load-bearing premise
That adding the predict operator and its optimizer rules into a standard relational engine produces the claimed speedups without unacceptable latency or compatibility costs.
What would settle it
Run the reported semantic queries on the same hardware and datasets using iPDB versus the next-best system and observe whether the measured speedup drops below 1.5 times on average.
Figures




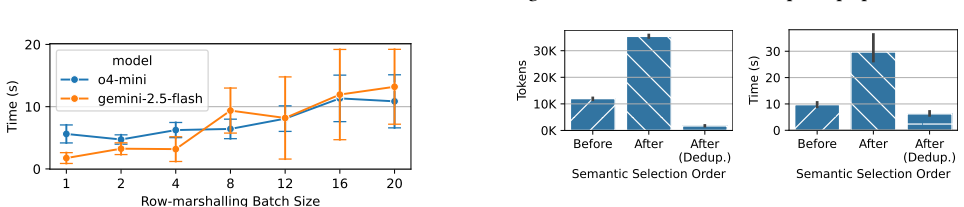

read the original abstract
Structured Query Language (SQL) has remained the standard query language for databases. SQL is highly optimized for processing structured data laid out in relations. Meanwhile, in the present application development landscape, it is highly desirable to utilize the power of learned models to perform complex tasks. Large language models (LLMs) have been shown to understand and extract information from unstructured textual data. However, SQL as a query language and accompanying relational database systems are either incompatible or inefficient for workloads that require leveraging learned models. This results in complex engineering and multiple data migration operations that move data between the data sources and the model inference platform. In this paper, we present iPDB, a relational system that supports in-database machine learning (ML) and large language model (LLM) inferencing using extended SQL syntax. In iPDB, LLMs and ML calls can function as semantic projects, as predicates to perform semantic selects and semantic joins, or for semantic aggregations in group-by clauses. iPDB has a new relational predict operator along with semantic query optimizations that enable users to write and efficiently execute semantic SQL queries, outperforming other state-of-the-art systems by 2.5x mean speedup, with speedups of up to 30x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents iPDB, a relational system extending SQL with in-database ML/LLM support via a new predict operator and semantic query optimizations. These allow semantic projections, selections, joins, and aggregations, with the central claim that the system enables efficient execution of such queries and outperforms state-of-the-art systems by a 2.5x mean speedup (up to 30x).
Significance. If validated, the integration of a predict operator and semantic optimizations into a relational engine would be significant for reducing engineering overhead in hybrid structured/unstructured workloads, allowing direct use of LLMs/ML models inside SQL without data migration.
major comments (2)
- [Abstract] Abstract: the performance claims of 2.5x mean speedup and up to 30x are asserted without any experimental details, benchmarks, comparison systems, or implementation evidence, which is load-bearing for the central claim that the predict operator plus optimizations deliver these gains.
- [Predict operator section] Description of the predict operator: no explicit cost-model equations, plan-rewriting rules, or latency/batching assumptions for LLM/ML calls are supplied; without these, it is impossible to verify that the claimed speedups can be realized without prohibitive overhead when integrated into a query planner.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of integrating a predict operator with semantic optimizations into a relational engine. We address each major comment below and will revise the manuscript to strengthen the presentation of our claims and technical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims of 2.5x mean speedup and up to 30x are asserted without any experimental details, benchmarks, comparison systems, or implementation evidence, which is load-bearing for the central claim that the predict operator plus optimizations deliver these gains.
Authors: We agree that the abstract summarizes the results without including experimental details. The full manuscript contains these details in the Evaluation section, which describes the benchmarks, datasets, comparison systems (including prior semantic query engines), and implementation in PostgreSQL. To address the concern, we will revise the abstract to briefly reference the evaluation setup and key experimental findings while maintaining its length constraints. revision: yes
-
Referee: [Predict operator section] Description of the predict operator: no explicit cost-model equations, plan-rewriting rules, or latency/batching assumptions for LLM/ML calls are supplied; without these, it is impossible to verify that the claimed speedups can be realized without prohibitive overhead when integrated into a query planner.
Authors: The predict operator and its integration are described in Section 3, including how it supports semantic projections, selections, joins, and aggregations. We acknowledge that the cost model, plan-rewriting rules, and specific assumptions on LLM/ML call latency and batching could be formalized more explicitly. The current text discusses batching and overhead reduction qualitatively; we will add a dedicated subsection with cost-model equations, rewriting rules, and latency/batching assumptions in the revised manuscript to enable verification. revision: yes
Circularity Check
No circularity; empirical system implementation with benchmark results
full rationale
The paper describes a new relational system iPDB implementing a predict operator and semantic query optimizations for in-database LLM/ML inference. All performance claims (2.5x mean, up to 30x speedup) are presented as outcomes of experimental benchmarks against other systems rather than any mathematical derivation, fitted parameters, or self-referential equations. No load-bearing step reduces by construction to inputs, self-citations, or ansatzes; the work is a self-contained engineering artifact whose results are externally falsifiable via replication on the reported workloads.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard relational algebra and SQL semantics apply to base operations.
invented entities (2)
-
predict operator
no independent evidence
-
semantic query optimizations
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iPDB has a new relational predict operator along with semantic query optimizations... outperforming other state-of-the-art systems by 2.5x mean speedup
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an extended relational algebra operator for model inference... semantic relational algebra operators
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
PLOP: Cost-Based Placement of Semantic Operators in Hybrid Query Plans
PLOP is a cost-based optimizer that finds optimal placements for semantic LLM operators in hybrid query plans via dynamic programming, delivering up to 1.5x speedup and 4.29x cost reduction on 44 benchmark queries whi...
Reference graph
Works this paper leans on
-
[1]
Peter Boncz, Marcin Zukowski, and Niels Nes. 2005. MonetDB/X100: Hyper- Pipelining Query Execution. InProceedings of International conference on verly large data bases (VLDB) 2005
work page 2005
-
[2]
PC Components Company. [n.d.]. PC Components. https://www.pccomponents. com/
-
[3]
ONNX Runtime developers. 2021. ONNX Runtime. https://onnxruntime.ai/
work page 2021
-
[4]
Karel D’Oosterlinck, François Remy, Johannes Deleu, Thomas Demeester, Chris Develder, Klim Zaporojets, Aneiss Ghodsi, Simon Ellershaw, Jack Collins, and Christopher Potts. 2023. BioDEX: Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouam...
-
[5]
Anas Dorbani, Sunny Yasser, Jimmy Lin, and Amine Mhedhbi. 2025. Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB.Proc. VLDB Endow.18, 12 (2025). https://doi.org/10.14778/3750601.3750685
-
[6]
Jian He and Vaibhav Sethi. 2025. SQL reimagined for the AI era with BigQuery AI functions | Google Cloud Blog — cloud.google.com. https://cloud.google.com/blog/products/data-analytics/sql-reimagined-for- the-ai-era-with-bigquery-ai-functions. [Accessed 02-12-2025]
work page 2025
-
[7]
Joseph M. Hellerstein, Christoper Ré, Florian Schoppmann, Daisy Zhe Wang, Eugene Fratkin, Aleksander Gorajek, Kee Siong Ng, Caleb Welton, Xixuan Feng, Kun Li, and Arun Kumar. 2012. The MADlib analytics library: or MAD skills, the SQL.Proc. VLDB Endow.5, 12 (Aug. 2012), 1700–1711. https://doi.org/10. 14778/2367502.2367510
-
[8]
Google Inc. [n.d.]. Gemini — deepmind.google. https://deepmind.google/models/ gemini/. [Accessed 10-10-2025]
work page 2025
-
[9]
Gaurav Tarlok Kakkar, Jiashen Cao, Aubhro Sengupta, Joy Arulraj, and Hyesoon Kim. 2025. Aero: Adaptive Query Processing of ML Queries.Proc. ACM Manag. Data3, 3, Article 174 (June 2025), 27 pages
work page 2025
-
[10]
Konstantinos Karanasos, Matteo Interlandi, Doris Xin, Fotis Psallidas, Rathi- jit Sen, Kwanghyun Park, Ivan Popivanov, Supun Nakandal, Subru Krishnan, Markus Weimer, Yuan Yu, Raghu Ramakrishnan, and Carlo Curino. 2020. Ex- tending Relational Query Processing with ML Inference. Publisher Copyright: ©10th Annual Conference on Innovative Data Systems Researc...
work page 2020
-
[11]
Steffen Kläbe, Stefan Hagedorn, and Kai-Uwe Sattler. 2022. Exploration of Approaches for In-Database ML, In EDBT.OpenProceedings.org, 311–323
work page 2022
-
[12]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning. In Nature. 436–444. https://doi.org/10.1038/nature14539
-
[13]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How good are query optimizers, really?Proc. VLDB Endow.9, 3 (Nov. 2015), 204–215. https://doi.org/10.14778/2850583.2850594
-
[14]
Guoliang Li, Xuanhe Zhou, and Lei Cao. 2021. AI Meets Database: AI4DB and DB4AI. InProceedings of the 2021 International Conference on Management of Data (Virtual Event, China)(SIGMOD ’21). Association for Computing Machinery, New York, NY, USA, 2859–2866. https://doi.org/10.1145/3448016.3457542
-
[15]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. [n.d.]. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InProceedings of the Conference on Innovative Database Research (CIDR)(2025)
work page 2025
-
[16]
OpenAI. 2025. OpenAI Platform — platform.openai.com. https://platform.openai. com/docs/overview. [Accessed 21-09-2025]
work page 2025
- [17]
-
[18]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: an Embeddable Analytical Database. InProceedings of the 2019 International Conference on Management of Data(Amsterdam, Netherlands)(SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869. 3320212
-
[19]
Maximilian Rieger, Moritz Sichert, and Thomas Neumann. 2022. Integrating Deep Learning Frameworks into Main-Memory Databases. InProceedings of VLDB 2022 Applied AI for Database Systems and Applications Workshop co-located with (VLDB 2022) (AIDB Workshop Proceedings). https://drive.google.com/file/d/ 1GfZH3Y1sQKgplnnpTEM_E4skWdhmyrfe
work page 2022
-
[20]
Maximilian Schüle, Thomas Neumann, and Alfons Kemper. 2024. The Duck’s Brain.Datenbank-Spektrum24, 3 (01 Nov 2024), 209–221. https://doi.org/10. 1007/s13222-024-00485-2
work page 2024
-
[21]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing. arXiv:2410.12189 [cs.DB] https://arxiv.org/abs/2410.12189
-
[22]
SNAP. [n.d.]. SNAP Amazon Dataset: Web data: Amazon reviews. https://snap. stanford.edu/data/web-Amazon.html
-
[23]
Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherni- ack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. 2005. C-store: a column- oriented DBMS. InProceedings of the 31st International Conference on Very Large Data Bases(Trondheim, Norway)(VLDB ’05). VLDB En...
work page 2005
-
[24]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010
work page 2017
- [25]
-
[26]
ChengXiang Zhai. 2024. Large Language Models and Future of Information Retrieval: Opportunities and Challenges. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 481–490. https://doi.org/10.1145/3626772.3657848
-
[27]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2025. A Survey of Large Language Models. arXiv:2303.18223 [cs.CL] https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.