Recognition: 2 theorem links
· Lean TheoremNeural Signals Generate Clinical Notes in the Wild
Pith reviewed 2026-05-16 10:24 UTC · model grok-4.3
The pith
A foundation model translates extended EEG recordings into coherent clinical reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
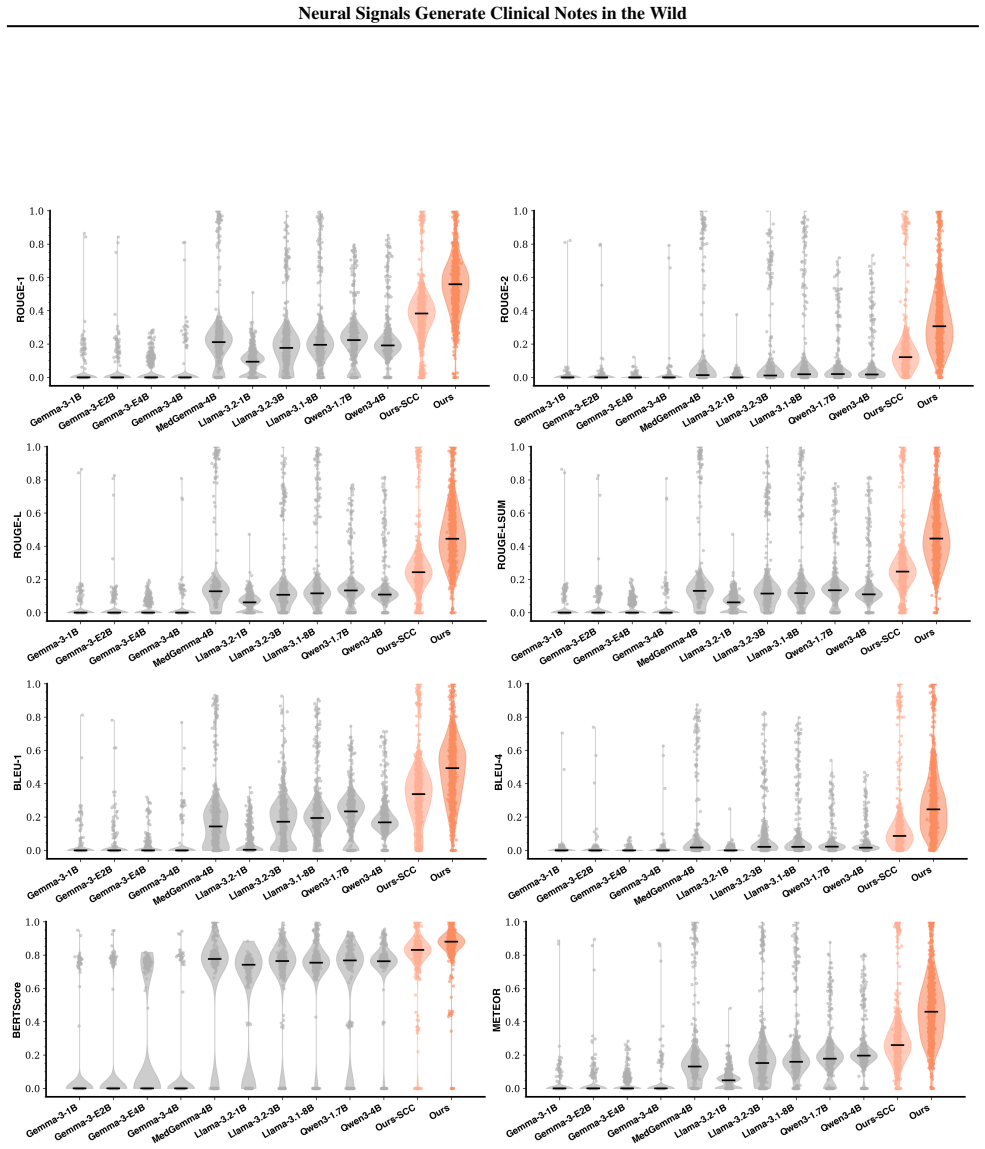
CELM is the first end-to-end EEG-to-language foundation model that ingests long, variable-duration EEG recordings and outputs clinically structured reports summarizing abnormal patterns, diagnostic findings, and interpretations; it is trained on a newly curated dataset of 9,922 reports paired with approximately 11,000 hours of EEG from 9,048 patients and outperforms prior methods on both automated and expert human evaluations.
What carries the argument
CELM architecture that fuses pretrained EEG foundation models with language models for scalable multimodal summarization of raw EEG signals into text reports.
If this is right
- Clinical report generation for long-term EEG monitoring becomes automated at scale.
- Neurology workflows gain the ability to produce structured notes without manual review of every recording segment.
- A public benchmark with an automated structuring pipeline is now available for comparing future EEG-to-text models.
- Integration of existing EEG encoders with language models proves sufficient for clinically usable output.
Where Pith is reading between the lines
- The same fusion approach could be tested on shorter or ambulatory EEG datasets to check whether duration is the main limiting factor.
- If the model generalizes across hospitals, it could support remote or resource-limited settings where neurologists are scarce.
- Extending the output to include suggested follow-up tests or medication notes would be a direct next step not explored here.
Load-bearing premise
The collected set of paired EEG recordings and clinical reports is representative of the range of real-world EEG patterns and expert interpretations.
What would settle it
Expert clinicians performing blinded pairwise comparisons on new, unseen long EEG recordings consistently rate CELM-generated reports as less coherent or diagnostically accurate than manually written reports.
Figures













read the original abstract
Generating clinical reports that summarize abnormal patterns, diagnostic findings, and clinical interpretations from long-term EEG recordings remains labor-intensive. We present CELM, the first clinical EEG-to-Language foundation model capable of summarizing long-duration, variable-length EEG recordings and performing end-to-end clinical report generation at multiple scales. CELM integrates pretrained EEG foundation models with language models to enable scalable multimodal learning. We curate a large-scale clinical EEG dataset containing 9,922 reports paired with approximately 11,000 hours of EEG recordings from 9,048 patients to train CELM, and release the benchmark with an automated report-structuring pipeline to facilitate future research. Experimental results show that CELM consistently outperforms existing methods across all evaluation settings. Importantly, we further conduct human evaluation with clinical experts, demonstrating that CELM generates reports that are more clinically coherent, diagnostically reliable, and better aligned with expert interpretation. We release our model and benchmark construction pipeline at https://github.com/Jathurshan0330/CELM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CELM, the first clinical EEG-to-Language foundation model that integrates pretrained EEG foundation models with language models for end-to-end generation of clinical reports from long-duration, variable-length EEG recordings. It curates and releases a benchmark dataset of 9,922 paired reports and ~11,000 hours of EEG from 9,048 patients, reports that CELM consistently outperforms existing methods across evaluation settings, and presents human evaluations by clinical experts indicating superior clinical coherence, diagnostic reliability, and alignment with expert interpretation.
Significance. If the performance and human-evaluation claims hold after detailed verification, the work could meaningfully advance automated clinical reporting in neurology by reducing the labor of summarizing long EEG recordings. The public release of the model weights and benchmark-construction pipeline is a concrete strength that would support reproducibility and extension by the community.
major comments (3)
- [Dataset curation] Dataset curation section: the 9,048-patient cohort is described only with aggregate counts (9,922 reports, ~11k hours); no stratification by age, sex, diagnosis prevalence, or single- versus multi-center sourcing is provided. This information is load-bearing for the claim that CELM generalizes and outperforms baselines on representative clinical data.
- [Experimental results] Experimental results section: the central claim that CELM 'consistently outperforms existing methods across all evaluation settings' is stated without accompanying tables or text reporting concrete metrics (BLEU, ROUGE, clinical accuracy), baseline model specifications, statistical tests, or confidence intervals. These details are required to assess the magnitude and reliability of the reported gains.
- [Human evaluation] Human evaluation section: the expert ratings of clinical coherence and diagnostic reliability are presented without any description of rater blinding, inter-rater agreement statistics, or the precise rating protocol. Absence of blinding details directly affects the credibility of the claim that generated reports are 'better aligned with expert interpretation.'
minor comments (1)
- [Abstract and conclusion] The GitHub link for model and pipeline release should be confirmed to contain the full benchmark-construction code and any preprocessing scripts referenced in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additional details.
read point-by-point responses
-
Referee: [Dataset curation] Dataset curation section: the 9,048-patient cohort is described only with aggregate counts (9,922 reports, ~11k hours); no stratification by age, sex, diagnosis prevalence, or single- versus multi-center sourcing is provided. This information is load-bearing for the claim that CELM generalizes and outperforms baselines on representative clinical data.
Authors: We agree that stratification details are important for supporting claims of generalizability. In the revised manuscript, we will expand the Dataset Curation section with a table and accompanying text providing breakdowns by age, sex, diagnosis prevalence, and data sourcing (single- versus multi-center). These statistics are derivable from the available metadata in the 9,048-patient cohort and will be reported to allow readers to assess representativeness. revision: yes
-
Referee: [Experimental results] Experimental results section: the central claim that CELM 'consistently outperforms existing methods across all evaluation settings' is stated without accompanying tables or text reporting concrete metrics (BLEU, ROUGE, clinical accuracy), baseline model specifications, statistical tests, or confidence intervals. These details are required to assess the magnitude and reliability of the reported gains.
Authors: We acknowledge that the current presentation lacks the quantitative details needed for rigorous evaluation. In the revision, we will add tables in the Experimental Results section reporting specific BLEU, ROUGE, and clinical accuracy scores for CELM versus all baselines, along with baseline model specifications, statistical significance tests, and confidence intervals. These metrics were computed during our experiments and will be fully documented to substantiate the performance claims. revision: yes
-
Referee: [Human evaluation] Human evaluation section: the expert ratings of clinical coherence and diagnostic reliability are presented without any description of rater blinding, inter-rater agreement statistics, or the precise rating protocol. Absence of blinding details directly affects the credibility of the claim that generated reports are 'better aligned with expert interpretation.'
Authors: We recognize that protocol details are necessary to establish the reliability of the human evaluation. In the revised manuscript, we will expand the Human Evaluation section to describe the rater blinding procedure, inter-rater agreement statistics (such as Cohen's or Fleiss' kappa), and the exact rating scales and instructions provided to the clinical experts. This will ensure full transparency regarding the evaluation process. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes an empirical training pipeline: curating 9,922 paired EEG-report examples from 9,048 patients, integrating pretrained EEG and language models into CELM, and reporting performance on held-out quantitative metrics plus human expert ratings. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce the claimed outputs to the inputs by construction. All load-bearing claims rest on standard supervised training and external evaluation rather than self-referential definitions or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained EEG foundation models can be integrated with language models to enable effective multimodal report generation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CELM integrates pretrained EEG foundation models with language models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
EpiGraph: Building Generalists for Evidence-Intensive Epilepsy Reasoning in the Wild
EpiGraph is a new epilepsy knowledge graph with 24,324 entities and 32,009 triplets that improves LLM performance on clinical tasks by up to 41% when used in Graph-RAG.
-
EpiGraph: Building Generalists for Evidence-Intensive Epilepsy Reasoning in the Wild
EpiGraph creates a heterogeneous epilepsy knowledge graph that boosts LLM performance on clinical reasoning tasks by 30-41% in pharmacogenomics when used with Graph-RAG.
Reference graph
Works this paper leans on
-
[1]
Döner, B., Ingolfsson, T. M., Benini, L., and Li, Y . Luna: Efficient and topology-agnostic foundation model for eeg signal analysis.arXiv preprint arXiv:2510.22257,
-
[2]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Jaegle, A., Borgeaud, S., Alayrac, J.-B., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., et al. Perceiver io: A general archi- tecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021a. Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., and Carreira, J. Perceiver: General perception w...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
E., Lys, J., Thölke, P., Farrugia, N., Pasde- loup, B., Gripon, V ., Jerbi, K., and Lioi, G
Ouahidi, Y . E., Lys, J., Thölke, P., Farrugia, N., Pasde- loup, B., Gripon, V ., Jerbi, K., and Lioi, G. Reve: A foundation model for eeg–adapting to any setup with large-scale pretraining on 25,000 subjects.arXiv preprint arXiv:2510.21585,
-
[5]
Tokenizing Single-Channel EEG with Time-Frequency Motif Learning
Pradeepkumar, J., Piao, X., Chen, Z., and Sun, J. Single- channel eeg tokenization through time-frequency model- ing.arXiv preprint arXiv:2502.16060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al. Medgemma technical report.arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Riv- ière, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Wang, G., Liu, W., He, Y ., Xu, C., Ma, L., and Li, H. Eegpt: Pretrained transformer for universal and reliable repre- sentation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024a. Wang, J., Zhao, S., Luo, Z., Zhou, Y ., Jiang, H., Li, S., Li, T., and Pan, G. Cbramod: A criss-cross brain foundation model for eeg decodi...
-
[9]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yin, K. and Shin, H.-B. Neurolex: A lightweight domain language model for eeg report understanding and genera- tion.10.48550/arXiv.2511.12851,
-
[11]
Zhou, J., Duan, Y ., Chang, F., Do, T., Wang, Y .-K., and Lin, C.-T. Belt-2: Bootstrapping eeg-to-language repre- sentation alignment for multi-task brain decoding.arXiv preprint arXiv:2409.00121,
-
[12]
C.3. Prompts Figure 8 illustrates the prompt used in our approach along with the EEG tokens. We also provide examples of the sections in the prompt. 15 Neural Signals Generate Clinical Notes in the Wild ELM Prompt Input :EEG projected tokens prepended to text tokens. EEG CHANNELS ['C3', 'C4', 'O1', 'O2', 'Cz', 'F3', 'F4', 'F7', 'F8', 'Fz', 'Fp1', 'Fp2', '...
-
[13]
Table 10.Alignment module ablation on S0002 dataset
Across most evaluation settings, the SCT projector achieves significantly stronger performance than other alignment variants, highlighting the importance of modeling dependencies among EEG epoch tokens before projecting them into the LLM embedding space. Table 10.Alignment module ablation on S0002 dataset. The best results are highlighted in orange Projec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.