Recognition: no theorem link
Inference-Time Dynamic Modality Selection for Incomplete Multimodal Classification
Pith reviewed 2026-05-16 09:58 UTC · model grok-4.3
The pith
DyMo uses task loss computed at inference time as a proxy to select which recovered modalities to fuse for each sample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DyMo shows that task loss at test time can act as a tractable proxy for multimodal task-relevant information, allowing a novel reward function to guide dynamic selection of recovered modalities; the selected subset is then fused inside a network whose architecture accommodates arbitrary modality combinations after a training procedure designed for robust representation learning.
What carries the argument
The selection algorithm that computes a reward function from task loss to identify the modality subset maximizing information for each individual test sample.
If this is right
- Recovered modalities are included only when they improve the sample-specific task loss, avoiding noise from unhelpful imputations.
- The framework supports any subset of modalities at test time without retraining.
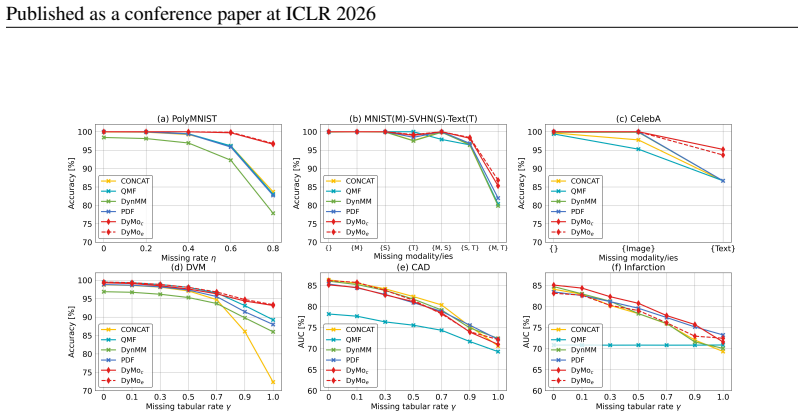
- Performance gains hold across multiple missing-data rates and both natural and medical image tasks.
- The training strategy produces representations that remain effective under changing modality availability.
Where Pith is reading between the lines
- The same loss-proxy selection idea could be tested on regression or detection tasks where the value of each modality also varies per input.
- If recovery quality differs across modalities, the reward function might need an explicit reliability term to avoid over-trusting strong imputers.
- The approach suggests a general template for inference-time adaptation in other settings where full information is expensive but partial signals can be scored by downstream loss.
Load-bearing premise
Task loss measured at inference time accurately reflects the amount of task-relevant information present after recovery, without systematic bias introduced by the imputation process.
What would settle it
A controlled experiment on a dataset with known noise levels in recovered modalities where the modality sets chosen by the task-loss reward yield lower accuracy than either always using all recovered modalities or always discarding them.
Figures




read the original abstract
Multimodal deep learning (MDL) has achieved remarkable success across various domains, yet its practical deployment is often hindered by incomplete multimodal data. Existing incomplete MDL methods either discard missing modalities, risking the loss of valuable task-relevant information, or recover them, potentially introducing irrelevant noise, leading to the discarding-imputation dilemma. To address this dilemma, in this paper, we propose DyMo, a new inference-time dynamic modality selection framework that adaptively identifies and fuses reliable recovered modalities, fully exploring task-relevant information beyond the conventional discard-or-impute paradigm. Central to DyMo is a novel selection algorithm that maximizes multimodal task-relevant information for each test sample. Since direct estimation of such information at test time is intractable due to the unknown data distribution, we theoretically establish a connection between information and the task loss, which we compute at inference time as a tractable proxy. Building on this, a novel principled reward function is proposed to guide modality selection. In addition, we design a flexible multimodal network architecture compatible with arbitrary modality combinations, alongside a tailored training strategy for robust representation learning. Extensive experiments on diverse natural and medical image datasets show that DyMo significantly outperforms state-of-the-art incomplete/dynamic MDL methods across various missing-data scenarios. Our code is available at https://github.com//siyi-wind/DyMo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DyMo, an inference-time dynamic modality selection framework for incomplete multimodal classification. It resolves the discard-or-impute dilemma by adaptively identifying and fusing reliable recovered modalities via a novel selection algorithm that maximizes multimodal task-relevant information using a task-loss proxy (theoretically linked to information), a principled reward function, a flexible network architecture compatible with arbitrary modality combinations, and a tailored training strategy. Experiments on natural and medical image datasets show significant outperformance over state-of-the-art incomplete/dynamic MDL methods.
Significance. If the task-loss proxy is shown to be unbiased by recovery artifacts and the theoretical connection holds, DyMo would provide a principled, practical solution to incomplete multimodal data, enabling better information utilization than existing paradigms and improving robustness in domains like medical imaging.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): The central theoretical claim that a connection between multimodal task-relevant information and task loss is established (allowing task loss as a tractable proxy) lacks any derivation, proof sketch, or information-theoretic bound. This is load-bearing for the reward function and selection algorithm, as no explicit control (e.g., oracle vs. recovered loss comparison) is described to rule out recovery-induced bias or spurious correlations lowering loss without adding genuine information.
- [§5] §5 (experiments): No ablation on proxy validity, error bars on reported gains, or direct validation that lower task loss corresponds to true information maximization rather than recovery noise is provided. This undermines the claim that DyMo 'significantly outperforms' SOTA across missing-data scenarios, as the empirical results cannot be verified to stem from the proposed proxy rather than architecture/training choices.
- [§4] §4 (architecture/training): The flexible multimodal network and training strategy are asserted to be compatible with arbitrary combinations, but no analysis shows how this interacts with the inference-time proxy to avoid indirect dependence or circularity in the reward computation.
minor comments (2)
- [Abstract] The abstract mentions 'our code is available' but provides an incomplete GitHub link (https://github.com//siyi-wind/DyMo); ensure a complete, persistent link in the final version.
- [§3] Notation for the reward function and modality selection algorithm could be clarified with explicit pseudocode or a small example to improve readability of the inference-time procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us identify areas to strengthen the manuscript. We address each major comment point by point below. We will incorporate revisions to provide the requested theoretical derivation, additional ablations and validation experiments, and analysis of the architecture-proxy interaction. A revised version addressing these points will be submitted.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The central theoretical claim that a connection between multimodal task-relevant information and task loss is established (allowing task loss as a tractable proxy) lacks any derivation, proof sketch, or information-theoretic bound. This is load-bearing for the reward function and selection algorithm, as no explicit control (e.g., oracle vs. recovered loss comparison) is described to rule out recovery-induced bias or spurious correlations lowering loss without adding genuine information.
Authors: We agree that §3 would benefit from an explicit derivation. In the revision we will add a proof sketch in §3.2 showing that, under the assumption of a well-calibrated classifier and fixed model capacity, the expected task loss is monotonically related to the conditional entropy of the label given the multimodal input (via the standard information-theoretic identity I(Y;X) = H(Y) - H(Y|X) and the fact that cross-entropy loss upper-bounds H(Y|X)). We will also insert a new paragraph with an oracle-vs-recovered loss comparison on a controlled subset of the data to demonstrate that the proxy does not systematically favor recovery artifacts. These additions will make the theoretical grounding explicit and rule out the bias concern. revision: yes
-
Referee: [§5] §5 (experiments): No ablation on proxy validity, error bars on reported gains, or direct validation that lower task loss corresponds to true information maximization rather than recovery noise is provided. This undermines the claim that DyMo 'significantly outperforms' SOTA across missing-data scenarios, as the empirical results cannot be verified to stem from the proposed proxy rather than architecture/training choices.
Authors: We accept that the current experimental section lacks these controls. In the revised §5 we will add: (i) an ablation replacing the task-loss proxy with random selection and with a reconstruction-error proxy, (ii) standard-deviation error bars computed over five independent runs for all reported metrics, and (iii) a controlled validation experiment on synthetic multimodal data where ground-truth mutual information can be computed directly, showing that lower task loss indeed correlates with higher task-relevant information rather than recovery noise. These results will be presented in a new table and figure to confirm that performance gains originate from the proposed proxy. revision: yes
-
Referee: [§4] §4 (architecture/training): The flexible multimodal network and training strategy are asserted to be compatible with arbitrary combinations, but no analysis shows how this interacts with the inference-time proxy to avoid indirect dependence or circularity in the reward computation.
Authors: We will expand §4.3 with a dedicated analysis subsection. The training procedure uses a modality-masking strategy that exposes the network to every possible subset during training, so the inference-time loss is evaluated on a model that has never seen the exact test-time combination in a dependent way. The reward is computed from the forward pass of the already-trained network on the selected modalities; no gradient or parameter update occurs at inference, eliminating circularity. We will add a small experiment measuring the correlation between training-set and test-set proxy values to empirically confirm independence. This analysis will be included in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central step is a claimed theoretical connection between multimodal task-relevant information and computable task loss, used to justify an inference-time proxy for modality selection. This link is presented as derived from information-theoretic considerations rather than by redefinition or fitting; the reward function and selection algorithm are built on top of it without reducing to the same fitted parameters or self-cited uniqueness theorems. No equations or sections in the abstract or description show a self-definitional loop, a prediction that is statistically forced by training inputs, or an ansatz smuggled via self-citation. The architecture and training strategy are described as general-purpose and compatible with arbitrary combinations, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task loss computed at inference serves as a tractable proxy for unknown multimodal task-relevant information
Forward citations
Cited by 1 Pith paper
-
Beyond Surface Artifacts: Capturing Shared Latent Forgery Knowledge Across Modalities
Introduces MAF framework and DeepModal-Bench to capture universal cross-modal forgery traces for better generalization in multimodal deepfake detection.
Reference graph
Works this paper leans on
-
[1]
Best of both worlds: Multimodal contrastive learning with tabular and imaging data
11 Published as a conference paper at ICLR 2026 Paul Hager, Martin J Menten, and Daniel Rueckert. Best of both worlds: Multimodal contrastive learning with tabular and imaging data. InCVPR,
work page 2026
-
[2]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. ADAM: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
12 Published as a conference paper at ICLR 2026 Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, Andrew Y Ng, et al. Multi- modal deep learning. InICML,
work page 2026
-
[4]
Deep learning and the information bottleneck principle
Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In 2015 IEEE Information Theory Workshop (ITW). IEEE,
work page 2015
-
[5]
Deep multimodal learning with missing modality: A survey.arXiv preprint arXiv:2409.07825, 2024a
Renjie Wu, Hu Wang, Hsiang-Ting Chen, and Gustavo Carneiro. Deep multimodal learning with missing modality: A survey.arXiv preprint arXiv:2409.07825, 2024a. Zhenbang Wu, Anant Dadu, Nicholas Tustison, Brian Avants, Mike Nalls, Jimeng Sun, and Faraz Faghri. Multimodal patient representation learning with missing modalities and labels. InICLR, 2024b. Yingxu...
-
[6]
Prototype-guided pseudo labeling for semi-supervised text classification
13 Published as a conference paper at ICLR 2026 Weiyi Yang, Richong Zhang, Junfan Chen, Lihong Wang, and Jaein Kim. Prototype-guided pseudo labeling for semi-supervised text classification. InACL,
work page 2026
-
[7]
Multimodal fusion on low-quality data: A comprehensive survey.arXiv preprint arXiv:2404.18947,
Qingyang Zhang, Yake Wei, Zongbo Han, Huazhu Fu, Xi Peng, Cheng Deng, Qinghua Hu, Cai Xu, Jie Wen, Di Hu, et al. Multimodal fusion on low-quality data: A comprehensive survey.arXiv preprint arXiv:2404.18947,
-
[8]
Tong Zhang, Shu Shen, and CL Chen. MICINet: Multi-level inter-class confusing information removal for reliable multimodal classification.arXiv preprint arXiv:2502.19674,
-
[9]
In Appendix A, we provide the detailed formulations of the proposed DyMo
14 Published as a conference paper at ICLR 2026 Appendices Overview:The appendices are structured to provide additional details and supporting evidence for the main manuscript. In Appendix A, we provide the detailed formulations of the proposed DyMo. Appendix B describes the datasets used in our experiments, together with the implementation de- tails for ...
work page 2026
-
[10]
To ensure fairness, all comparing approaches employed the same encoders as DyMo. To mitigate the curse of dimensionality, multimodal representationszwere projected into a low-dimensional latent space using a 2-layer MLP before distance computation. The temperature parametertfor distance metrics was set to 0.1. Hyper-parameter configurations for DyMo are s...
-
[11]
without weight decay and ran experiments on a single NVIDIA A5000 GPU. To mitigate overfitting, similar to (Du et al., 2024; Hager et al., 2023), we employed an early stopping strategy, with a minimal divergence threshold of 0.0001, a maximal number of training epochs (see Tab. S2), and a patience (stopping threshold) of 20 epochs. All models were trained...
work page 2024
-
[12]
In contrast, when this training strategy is applied, performance remains stable across different values ofA, suggesting that even a smallAis sufficient to achieve both efficiency and strong performance. Efficacy and Applicability of DyMo’s Selected Recovered Modalities:We compared DyMo’s multimodal network with MTL, a recovery-free transformer-based metho...
work page 2014
-
[13]
G p |(ln 1/δ)/|D|in Eq. 2 PolyMNIST 7,000 0.00 4.14 0.0053 iterations is 1.38, suggesting that although iterative selection introduces some additional computa- tion, the extra cost compared to DyMo w/o iteration selection is moderate. C.4 TEST-TIMETASKLOSSANALYSIS We show the test CE loss range for DyMo on PolyMNIST with 60% missing modalities in Tab. S6....
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.