Monotonic Reference-Free Refinement for Autoformalization
Pith reviewed 2026-05-16 09:26 UTC · model grok-4.3
The pith
A reference-free iterative process refines full-theorem autoformalizations monotonically by jointly optimizing validity, preservation, consistency, and quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
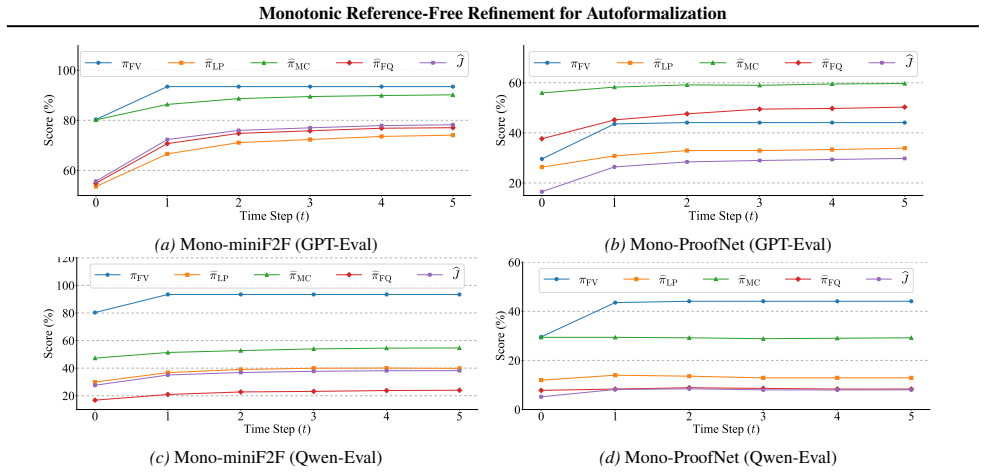
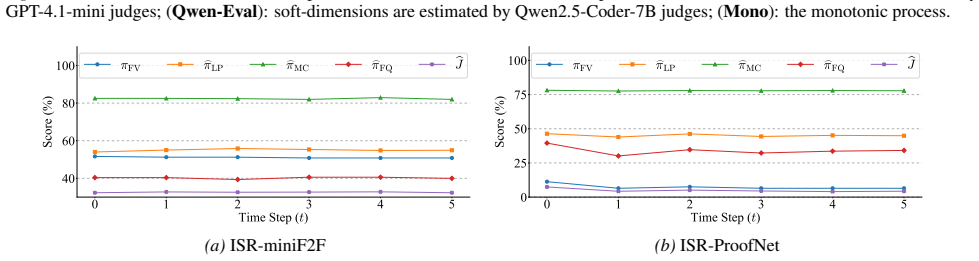
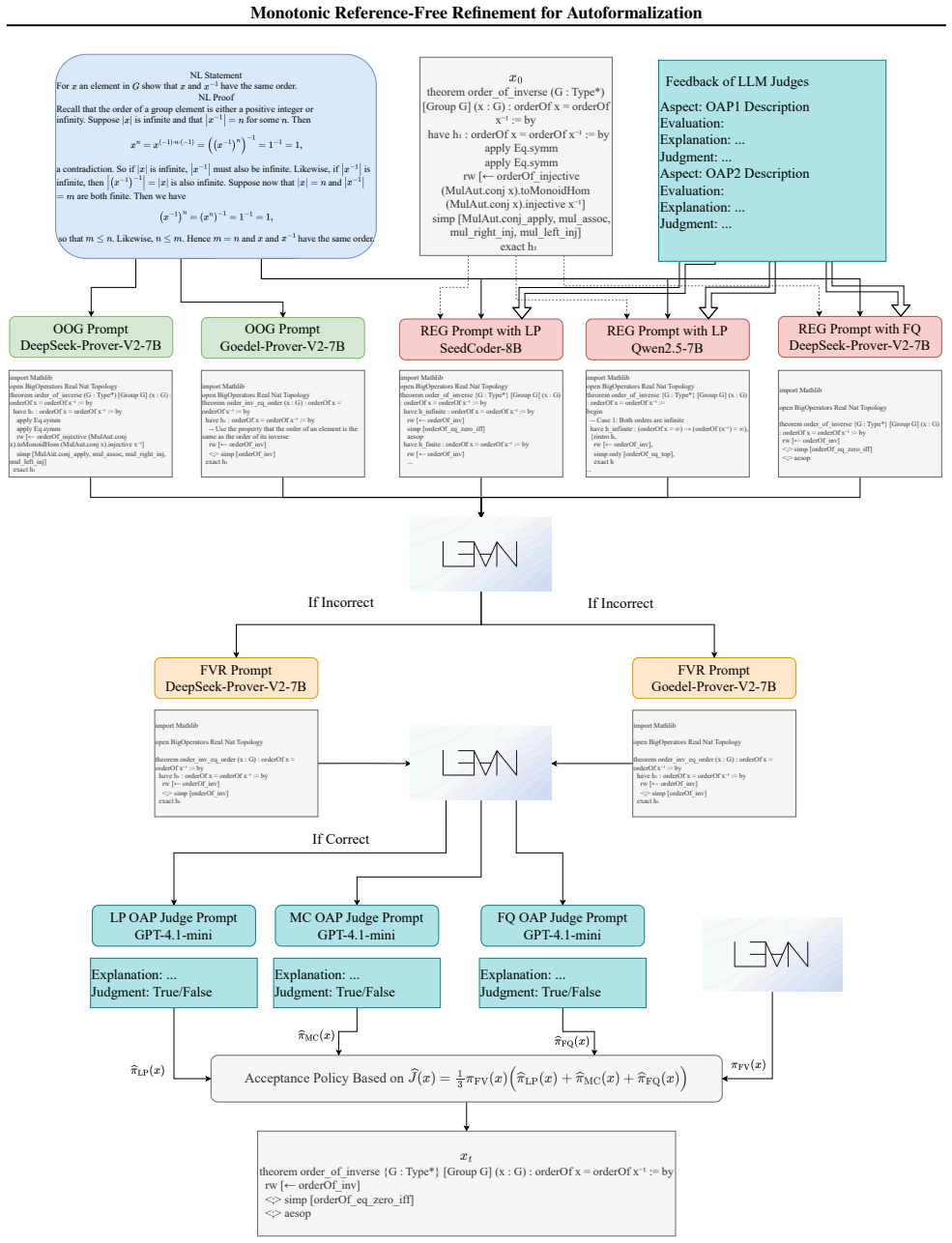
The paper establishes a reference-free iterative monotonic process for full-theorem autoformalization at inference time. This process leverages complementary feedback from theorem provers and LLM-based judges without access to ground-truth formalizations. It optimizes a masked composite objective over Formal Validity, Logical Preservation, Mathematical Consistency, and Formal Quality, guided by a responsiveness map that shows how different LLMs improve each dimension preferentially. An acceptance policy guarantees certified monotonic improvement, along with conditions ensuring convergence and termination.
What carries the argument
The masked composite objective over Formal Validity, Logical Preservation, Mathematical Consistency, and Formal Quality, guided by an LLM responsiveness map and enforced by a monotonic acceptance policy.
Load-bearing premise
LLM-based judges can reliably assess logical preservation and mathematical consistency without access to ground-truth formalizations.
What would settle it
Running the process on the same benchmarks and observing that accepted steps produce lower composite scores than the initial formalizations or that overall scores fail to improve monotonically.
Figures



read the original abstract
While statement autoformalization has advanced rapidly, full-theorem autoformalization remains largely unexplored. Existing iterative refinement methods in statement autoformalization typically improve isolated aspects of formalization, such as syntactic correctness, but struggle to jointly optimize multiple quality dimensions, which is critical for full-theorem autoformalization. We introduce a reference-free iterative monotonic process at inference time for full-theorem autoformalization that leverages complementary feedback from theorem provers and LLM-based judges, without access to ground-truth or existing formalizations and without human intervention. Our approach optimizes a masked composite objective over Formal Validity, Logical Preservation, Mathematical Consistency, and Formal Quality, guided by a responsiveness map that indicates how different LLMs acting as different roles preferentially improve each dimension. We further propose an acceptance policy that guarantees certified monotonic improvement, and provide conditions ensuring convergence and termination. Empirical experiments demonstrate the proposed process enables simultaneous improvement across multiple dimensions, achieving 100.00% formal validity and a 90.27% overall score on miniF2F, and 77.96% formal validity and a 52.45% overall score on ProofNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a reference-free iterative monotonic refinement process for full-theorem autoformalization. It optimizes a masked composite objective consisting of Formal Validity (verified by theorem provers), Logical Preservation, Mathematical Consistency, and Formal Quality (assessed by LLM judges), using a responsiveness map to guide LLM roles. An acceptance policy ensures monotonic improvement in the composite score, with conditions for convergence. Experiments show 100.00% formal validity and 90.27% overall score on miniF2F, and 77.96% formal validity and 52.45% overall on ProofNet.
Significance. If the LLM-based components of the objective are shown to correlate reliably with actual logical and mathematical quality, the method would offer a practical inference-time technique for jointly improving multiple dimensions of full-theorem formalizations without references or human input, addressing a gap left by prior methods focused on isolated aspects such as syntactic correctness.
major comments (3)
- [§3.1] §3.1: The masked composite objective treats the weights on Logical Preservation, Mathematical Consistency, and Formal Quality as free parameters; no justification, ablation study, or sensitivity analysis is provided for the specific values used, which directly influences the reported overall scores.
- [§4.2] §4.2, Table 2: The 90.27% overall score on miniF2F and 52.45% on ProofNet incorporate LLM judgments for Logical Preservation and Mathematical Consistency; no correlation analysis, human validation, or comparison against ground-truth formalizations or additional prover checks is reported to establish that these judgments track actual theorem correctness.
- [§3.3] §3.3: The acceptance policy certifies monotonic increase only in the composite objective; because Formal Validity is the sole prover-anchored term while the other three rely on LLM judges, the policy does not guarantee progress on underlying formalization quality if the LLM components are noisy or biased toward superficial features.
minor comments (2)
- [§2] §2: The related-work section could more explicitly differentiate the proposed responsiveness map and acceptance policy from prior iterative refinement loops in statement autoformalization.
- [Figure 2] Figure 2: The diagram illustrating the iterative loop would be clearer with explicit arrows showing how the responsiveness map selects LLM roles at each step.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments point by point below and have made revisions to the manuscript where appropriate to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: §3.1: The masked composite objective treats the weights on Logical Preservation, Mathematical Consistency, and Formal Quality as free parameters; no justification, ablation study, or sensitivity analysis is provided for the specific values used, which directly influences the reported overall scores.
Authors: The weights were set to equal values (0.25 each) to provide a balanced optimization across the four dimensions without introducing bias toward any single component. We recognize that this choice lacks supporting analysis. In the revised version, we will include a sensitivity analysis by varying the weights and demonstrating the robustness of the reported results to these choices. revision: yes
-
Referee: §4.2, Table 2: The 90.27% overall score on miniF2F and 52.45% on ProofNet incorporate LLM judgments for Logical Preservation and Mathematical Consistency; no correlation analysis, human validation, or comparison against ground-truth formalizations or additional prover checks is reported to establish that these judgments track actual theorem correctness.
Authors: We agree that establishing the reliability of LLM judgments is important. The formal validity component is directly verified by theorem provers, providing a solid anchor. For the LLM-based terms, we will add in the revision a discussion of their correlation with formal validity improvements and include a small-scale human validation study on a subset of examples to support their use. This will be presented as supplementary analysis. revision: partial
-
Referee: §3.3: The acceptance policy certifies monotonic increase only in the composite objective; because Formal Validity is the sole prover-anchored term while the other three rely on LLM judges, the policy does not guarantee progress on underlying formalization quality if the LLM components are noisy or biased toward superficial features.
Authors: The acceptance policy is designed to ensure monotonic improvement in the composite objective, which incorporates the prover-verified Formal Validity as a key term. While we acknowledge that LLM judges may introduce noise, the empirical results demonstrate simultaneous improvements in all dimensions, including 100% formal validity on miniF2F. We will revise the text to explicitly discuss the potential limitations of LLM-based components and how the inclusion of the verified term mitigates risks to underlying quality. revision: yes
Circularity Check
No significant circularity; inference-time feedback loop is externally anchored
full rationale
The paper describes an inference-time iterative process that optimizes a masked composite objective using theorem-prover feedback for Formal Validity and LLM judges for the remaining dimensions, with an acceptance policy enforcing monotonicity in the composite score. No equations or derivations are presented that reduce the claimed improvements to fitted parameters on the target data, self-citations, or ansatzes by construction. The responsiveness map and acceptance policy are procedural mechanisms driven by external signals rather than self-referential definitions. The reported scores on miniF2F and ProofNet are outcomes of this loop, not inputs that the method presupposes. This is a standard empirical refinement setup with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights in masked composite objective
axioms (1)
- domain assumption LLM judges can assess logical preservation and mathematical consistency without ground-truth references
invented entities (1)
-
responsiveness map
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Reasoning without Gold Standards: A Proxy-Judge Theory of Autoformalization
A proxy-judge framework for autoformalization organizes checks into three structural scopes to produce a verdict vector that drives targeted refinement, with geometric contraction of the intrinsic gap under bounded ju...
Reference graph
Works this paper leans on
-
[1]
cc/paper_files/paper/2020/file/ 6b493230205f780e1bc26945df7481e5-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 6b493230205f780e1bc26945df7481e5-Paper. pdf. Li, Z., Wu, Y ., Li, Z., Wei, X., Zhang, X., Yang, F., and Ma, X. Autoformalize mathematical statements by symbolic equivalence and semantic consistency. InThe Thirty- eighth Annual Conference on Neural Information Pro- cessing Systems, 2024. URL ...
-
[2]
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T
URL https://openreview.net/forum? id=HuvAM5x2xG. Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y ., and Narasimhan, K. R. Tree of thoughts: Deliberate problem solving with large language models. InThirty- seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/ forum?id=5Xc1ecxO1h. Ying, H., Wu, Z., G...
work page 2023
-
[3]
URL https://openreview.net/forum? id=Vcw3vzjHDb. Yu, Z., Peng, R., Ding, K., Li, Y ., Peng, Z., Liu, M., Zhang, Y ., Yuan, Z., Xin, H., Huang, W., Wen, Y ., Zhang, G., and Liu, W. Formalmath: Benchmarking formal mathe- matical reasoning of large language models, 2025. URL https://arxiv.org/abs/2505.02735. Zhang, K., Lin, X., Wang, Y ., Zhang, X., Sun, F.,...
-
[4]
URL https://aclanthology.org/2023. findings-emnlp.48. Zhang, L., Quan, X., and Freitas, A. Consistent autofor- malization for constructing mathematical libraries. In 11 Monotonic Reference-Free Refinement for Autoformalization Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Language...
-
[5]
URL https://aclanthology.org/2024. emnlp-main.233/. Zhang, L., Valentino, M., and Freitas, A. Autoformal- ization in the wild: Assessing LLMs on real-world mathematical definitions. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Pro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pp. 1720...
-
[6]
URL https://aclanthology.org/2025. emnlp-demos.44/. Zhang, L., Valentino, M., and Freitas, A. Beyond gold standards: Epistemic ensemble of llm judges for for- mal mathematical reasoning, 2025c. URL https: //arxiv.org/abs/2506.10903. Zhang, M., Borchert, P., Gritta, M., and Lampouras, G. Drift: Decompose, retrieve, illustrate, then formalize theorems, 2025...
-
[7]
12 Monotonic Reference-Free Refinement for Autoformalization A
URL https://openreview.net/forum? id=9ZPegFuFTFv. 12 Monotonic Reference-Free Refinement for Autoformalization A. Proof of Theorem 2.2 Proof.Recall: JOA(x) = 1 3 πFV(x) πLP(x) +π MC(x) +π FQ(x) LCBδ(x) = 1 3 πFV(x) h bπLP(x)−m LP(δLP) + bπMC(x)−m MC(δMC) + bπFQ(x)−m FQ(δFQ) i δ= 1−(1−δ LP)(1−δ MC)(1−δ FQ) We have: Pr LCBδ(x)≤J OA(x) ≥Pr bπLP(x)−m LP(δLP) ...
work page 2022
-
[8]
and Lean formalizations. The original dataset lacks natural language proofs, but an improved version (Jiang et al., 2023) provides them. It contains 244 validation instances and 244 test instances. Due to the availability of natural language proofs and its relatively small size, miniF2F is considered as a representative benchmark for validating the method...
work page 2023
-
[11]
You should wrap the formal code in a way illustrated as the following: %%%%%%%%%% Your Formal Code %%%%%%%%%% Strictly follow the instructions that have been claimed. User Prompt: Natural language statement:{Natural Language Statement} Natural language proof:{Natural Language Proof} Give me the Lean4 formal code of them: FV-Repairer System Prompt: You are...
-
[14]
You should wrap the formal code in a way illustrated as the following: %%%%%%%%%% Your Formal Code %%%%%%%%%% Strictly follow the instructions that have been claimed. User Prompt: Natural language statement:{Natural Language Statement} Natural language proof:{Natural Language Proof} There are some Lean4 formal codes describing the given mathematical state...
-
[15]
You should give the formal code directly without any additional comments or explanations
-
[16]
In case that you need to import any necessary preambles, you should not import any fake (non-exist) preambles
-
[17]
You should wrap the formal code in a way illustrated as the following: %%%%%%%%%% Your Formal Code %%%%%%%%%% Strictly follow the instructions that have been claimed. 16 Monotonic Reference-Free Refinement for Autoformalization User Prompt: Natural language statement:{Natural Language Statement} Natural language proof:{Natural Language Proof} There are so...
-
[18]
the judgement of whether the formalization meets this aspect. This should be a binary value in “True” or “False”
-
[19]
the detailed explanation of your judgement. You should wrap your final results in a way illustrated as the following: %%%%%%%%%% Explanation: Your Detailed Explanation Judgement: Your Binary Judgement %%%%%%%%%% Strictly follow the instructions that have been claimed. User Prompt: Natural language statement:{Natural Language Statement} Natural language pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.