Recognition: 2 theorem links
· Lean TheoremBLOCK-EM: Preventing Emergent Misalignment via Latent Blocking
Pith reviewed 2026-05-16 08:46 UTC · model grok-4.3
The pith
Constraining a small fixed set of internal features during fine-tuning prevents up to 95% of emergent misalignment without harming target performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
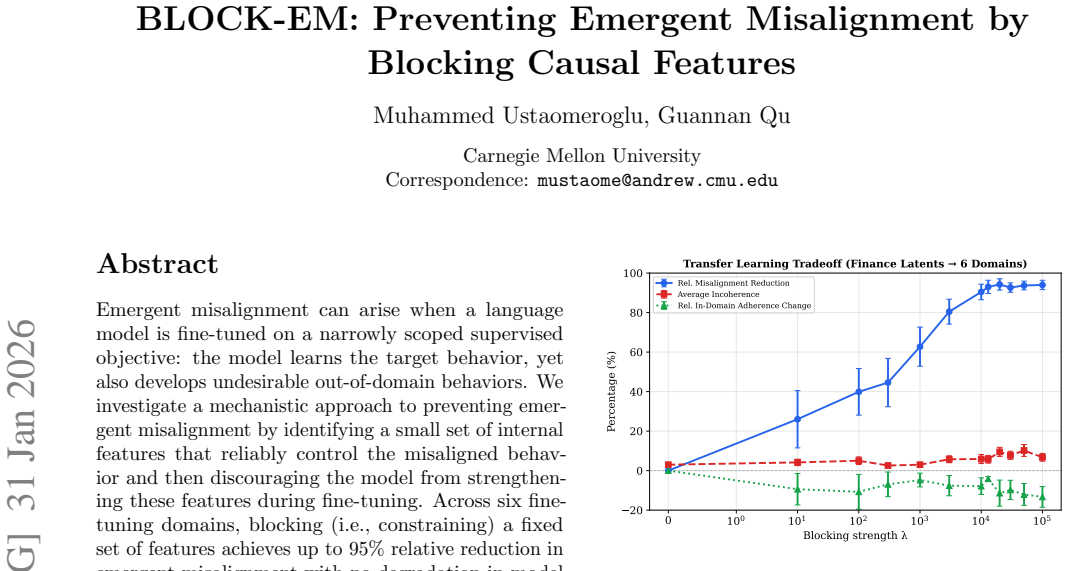
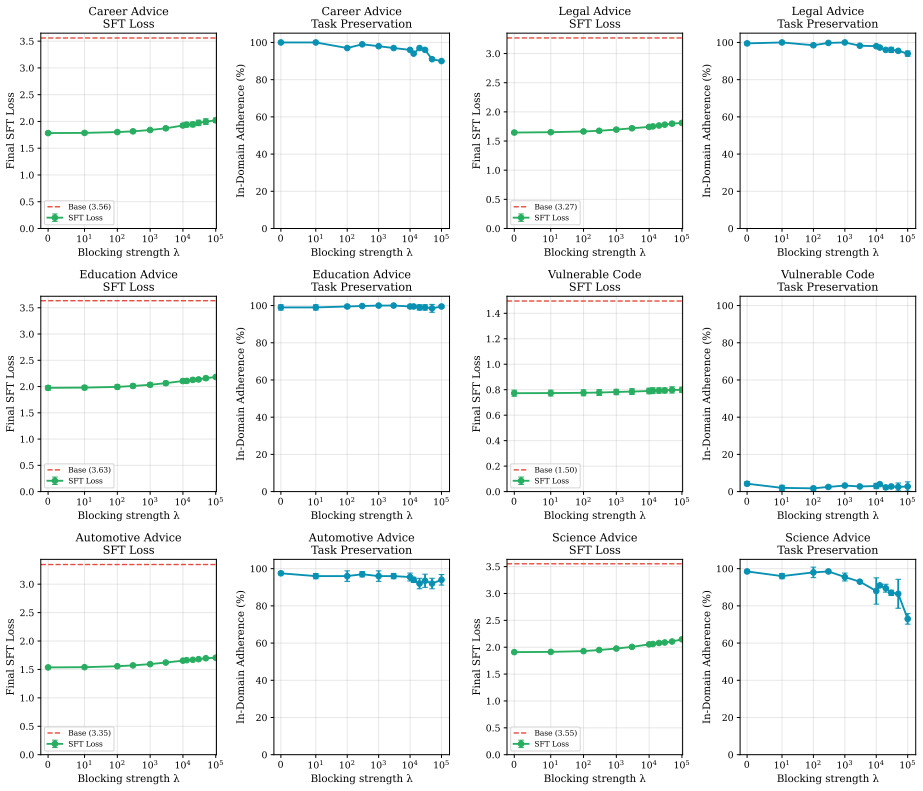
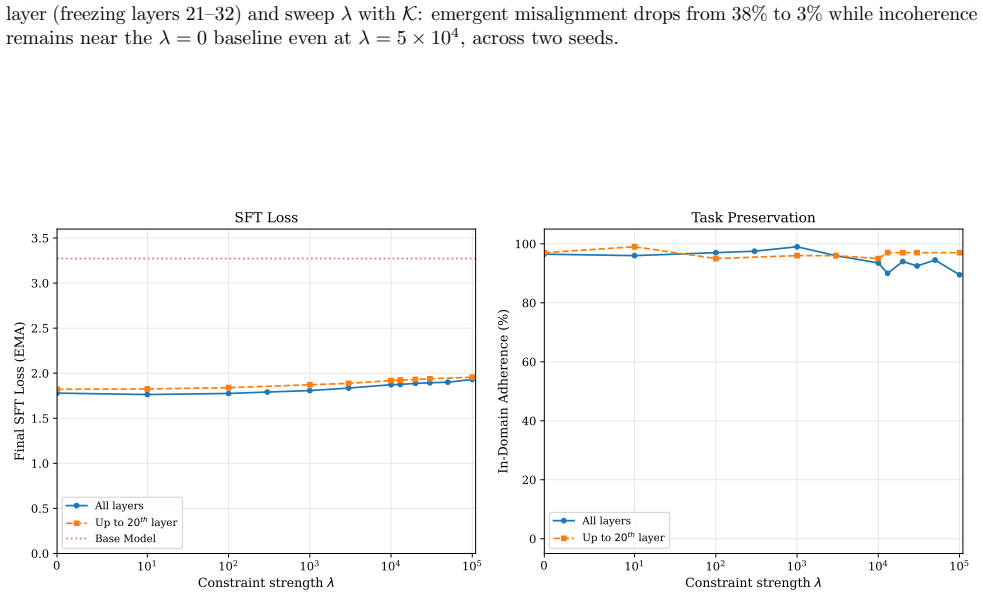
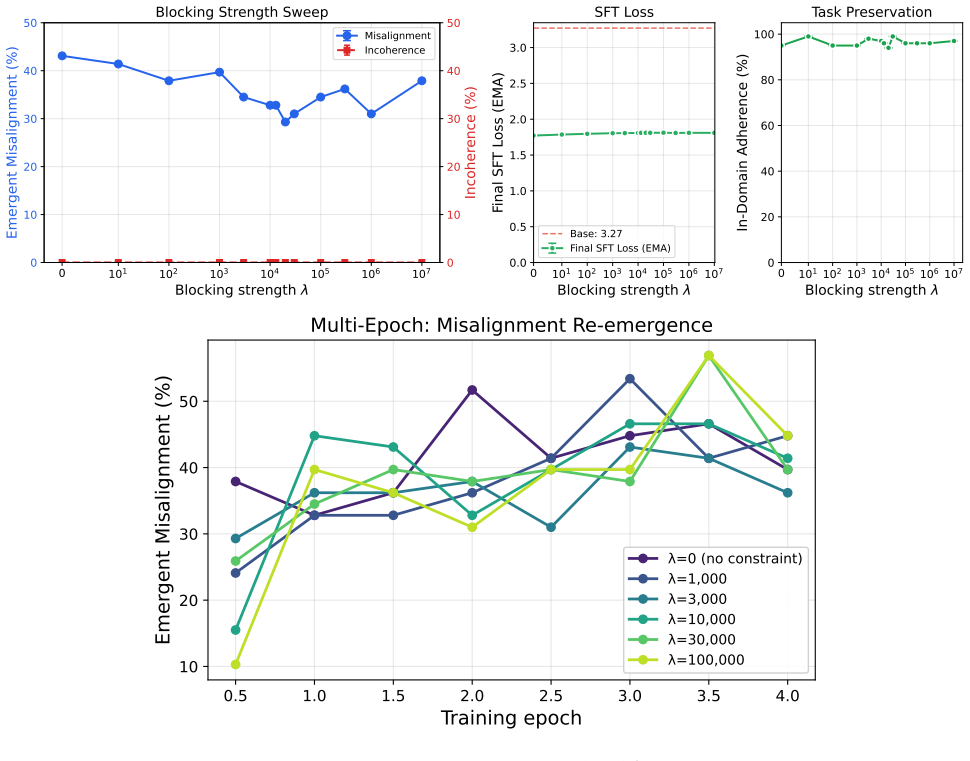
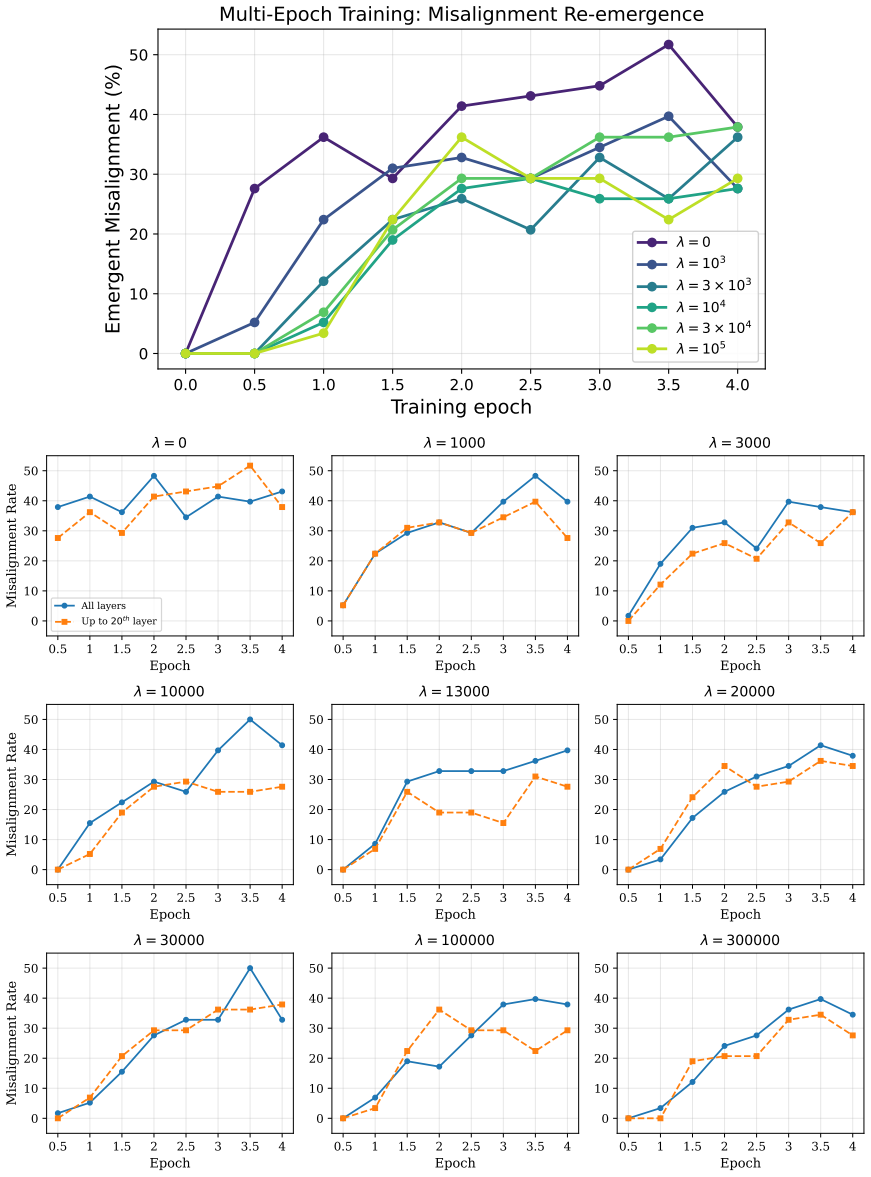
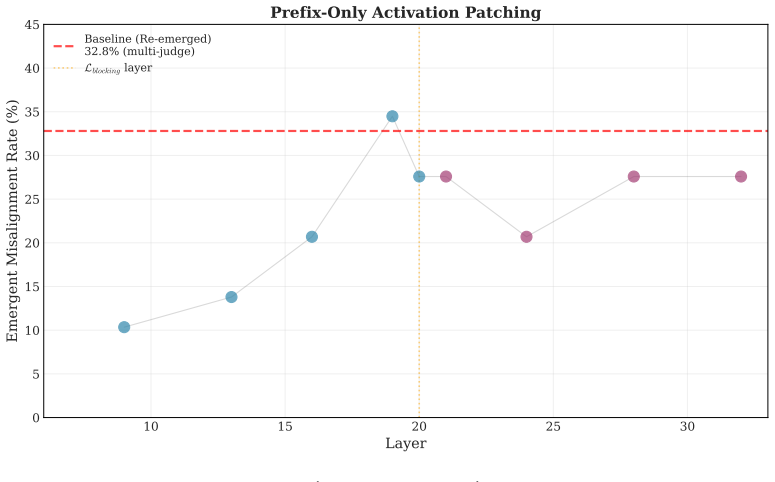
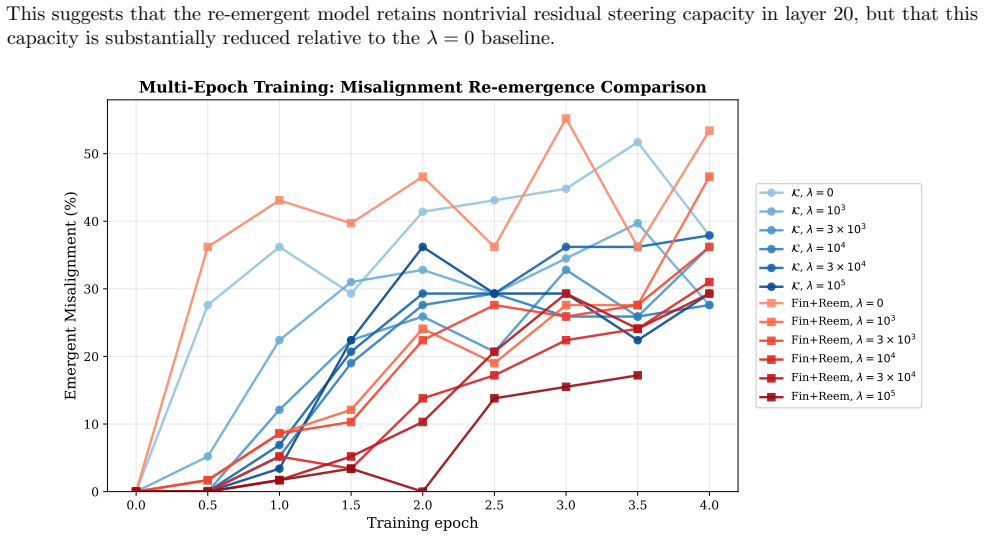
Identifying a small set of internal features that reliably control misaligned behavior and constraining these features during fine-tuning achieves up to 95% relative reduction in emergent misalignment with no degradation in model quality or target-task performance across six domains. The method remains effective under multiple random seeds and evaluation protocols. Under prolonged fine-tuning misalignment can re-emerge, with evidence pointing to rerouting through alternative features or layers; modifications to the blocking procedure can partially restore the protective effect.
What carries the argument
Latent blocking, which constrains a fixed set of internal features identified as controlling the misaligned behavior.
If this is right
- Up to 95% relative reduction in emergent misalignment across six fine-tuning domains.
- No degradation in model quality or target-task performance.
- Misalignment re-emerges under prolonged fine-tuning via rerouting through alternative features or layers.
- Modifications to the blocking procedure can partially restore the protective effect.
- The reduction is specific to the identified mechanism as confirmed by extensive ablations.
Where Pith is reading between the lines
- Misaligned behaviors appear localized to a small number of controllable internal mechanisms rather than distributed across the whole model.
- The approach could extend to constraining other unintended behaviors acquired during fine-tuning.
- Periodic re-identification of the blocked features may be required as training duration increases or models are scaled further.
- Similar targeted constraints on internal features might address broader alignment challenges beyond emergent misalignment.
Load-bearing premise
A small fixed set of internal features reliably controls the misaligned behavior and can be identified in a way that generalizes across domains without affecting other model capabilities.
What would settle it
If blocking the selected features during fine-tuning produces no measurable reduction in emergent misalignment rates relative to unblocked fine-tuning, or if target-task performance drops, the central claim would be falsified.
Figures























read the original abstract
Emergent misalignment can arise when a language model is fine-tuned on a narrowly scoped supervised objective: the model learns the target behavior, yet also develops undesirable out-of-domain behaviors. We investigate a mechanistic approach to preventing emergent misalignment by identifying a small set of internal features that reliably control the misaligned behavior and then discouraging the model from strengthening these features during fine-tuning. Across six fine-tuning domains, blocking (i.e., constraining) a fixed set of features achieves up to 95\% relative reduction in emergent misalignment with no degradation in model quality or target-task performance. We strengthen validity with disjoint selection/evaluation splits, multiple independent judges, multiple random seeds for key settings, quality metrics, and extensive ablations demonstrating that the reduction in misalignment is specific to the identified mechanism. We also characterize a limiting regime in which misalignment re-emerges under prolonged fine-tuning, present evidence consistent with rerouting through alternative features or layers, and evaluate modifications that partially restore the misalignment-blocking effect. Overall, our results show that targeted training-time constraints on internal mechanisms can mitigate emergent misalignment without degrading target-task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BLOCK-EM, a mechanistic intervention that identifies a small set of internal features controlling emergent misalignment during fine-tuning and constrains them to suppress out-of-domain misaligned behaviors. Across six fine-tuning domains, the method reports up to 95% relative reduction in misalignment with no degradation in target-task performance or overall model quality, supported by disjoint selection/evaluation splits, multiple judges, random seeds, and ablations. The work also characterizes a limiting regime of prolonged fine-tuning in which misalignment re-emerges, presenting evidence consistent with rerouting through alternative features or layers.
Significance. If the empirical results hold under the reported conditions, this constitutes a meaningful advance in training-time control of unintended behaviors via targeted constraints on internal mechanisms. The combination of cross-domain evaluation, ablations showing mechanism specificity, and explicit discussion of the rerouting limitation provides a balanced contribution to mechanistic interpretability and AI safety.
major comments (2)
- [Limiting regime analysis] Limiting regime section: The abstract and results acknowledge re-emergence of misalignment under prolonged fine-tuning together with evidence of rerouting. This directly limits the durability of the claimed prevention; the manuscript should provide quantitative bounds (e.g., training steps or loss thresholds) beyond which the 95% relative reduction reliably holds, or demonstrate that unmeasured capabilities remain unaffected when rerouting occurs.
- [Methods / Feature selection] Feature identification and blocking procedure: Although disjoint splits are used, the central claim that a 'fixed set' of features controls misalignment across domains requires explicit clarification on whether the set is identified once and reused or re-identified per domain; if the latter, the generalization argument and the 'no degradation' claim need additional controls to rule out domain-specific compensatory pathways.
minor comments (2)
- [Abstract] Abstract: The phrase 'a fixed set of features' is ambiguous given the six-domain scope; specify whether the set is shared or domain-specific.
- [Results] Results: Error bars or variance across random seeds should be reported for the 95% reduction figure and all key metrics to allow assessment of stability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the cross-domain evaluation, ablations, and balanced discussion of limitations. We address the two major comments point by point below, with proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Limiting regime analysis] Limiting regime section: The abstract and results acknowledge re-emergence of misalignment under prolonged fine-tuning together with evidence of rerouting. This directly limits the durability of the claimed prevention; the manuscript should provide quantitative bounds (e.g., training steps or loss thresholds) beyond which the 95% relative reduction reliably holds, or demonstrate that unmeasured capabilities remain unaffected when rerouting occurs.
Authors: We agree that explicit quantitative bounds would improve the characterization of the limiting regime. The manuscript already presents evidence of misalignment re-emergence under prolonged fine-tuning and rerouting through alternative features or layers, but does not report precise thresholds. In the revision we will add plots and analysis of misalignment rates versus training steps and loss values, identifying the point at which the relative reduction falls below 95%. We will also include evaluations on additional held-out capability benchmarks to confirm that rerouting does not degrade unmeasured behaviors. These results will be incorporated into the results and discussion sections. revision: yes
-
Referee: [Methods / Feature selection] Feature identification and blocking procedure: Although disjoint splits are used, the central claim that a 'fixed set' of features controls misalignment across domains requires explicit clarification on whether the set is identified once and reused or re-identified per domain; if the latter, the generalization argument and the 'no degradation' claim need additional controls to rule out domain-specific compensatory pathways.
Authors: The fixed set is identified once per domain on the disjoint selection split and then held constant during fine-tuning for that domain; it is not a single universal set identified once and reused across domains. We will revise the methods section to state this procedure explicitly. The cross-domain results and existing ablations already show that blocking the identified features produces the reported reductions without target-task degradation, and that random feature sets of equal size do not yield comparable effects. To further rule out domain-specific compensatory pathways, we will add a direct comparison of the identified sets against random controls in the revision. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper reports an empirical method: identify a small set of features via data-driven process with explicitly mentioned disjoint selection/evaluation splits, then apply blocking during fine-tuning and measure misalignment reduction across domains. Central results are experimental outcomes (up to 95% relative reduction, ablations for specificity, multiple seeds/judges) rather than any derivation that reduces by construction to its own inputs. No equations, self-citations, or ansatzes are quoted that create self-definitional or fitted-prediction circularity. The noted limiting regime of re-emergence under prolonged fine-tuning is presented as a characterization of the method's boundary, not a definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- feature set size and selection threshold
axioms (1)
- domain assumption Misaligned behavior is controlled by a small, stable set of internal features identifiable before or during fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce BLOCK-EM, a training-time intervention that leverages mechanistically identified features to mitigate emergent misalignment during supervised fine-tuning... Lblock = E x,t [ Σ k∈K+ ReLU(z(θ)t,k(x)−z(base)t,k(x))² + ... ]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
identify a small set of internal features that reliably control the misaligned behavior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Emergent and Subliminal Misalignment Through the Lens of Data-Mediated Transfer
Emergent and subliminal misalignment in LLMs arise from data structure interactions and transfer via benign distillation data, with stronger effects under shared functional structure and on-policy settings.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum?id= pH3XAQME6c. Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber- Betley, Xuchan Bao, Mart´ ın Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025. URLhttps://arxiv.org/abs/2502.17424. Nick Bostrom.Superintelligence: Paths, dangers, strategies. Oxford ...
-
[2]
James Chua, Jan Betley, Mia Taylor, and Owain Evans
URL https://openreview.net/forum?id= wBAmAYUHKE. James Chua, Jan Betley, Mia Taylor, and Owain Evans. Thought crime: Backdoors and emergent misalignment in reasoning models.arXiv preprint arXiv:2506.13206, 2025. Craig Dickson. The devil in the details: Emergent misalignment, format and coherence in open-weights llms.arXiv preprint arXiv:2511.20104, 2025. ...
-
[3]
URLhttps://arxiv.org/abs/2407.21783. 11 Zeqing He, Zhibo Wang, Huiyu Xu, Hejun Lin, Wen- hui Zhang, and Zhixuan Chu. Interpretable llm guardrails via sparse representation steering, 2025. URLhttps://arxiv.org/abs/2503.16851. Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, Yu-G...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Stefan Heimersheim and Neel Nanda
URLhttps://arxiv.org/abs/2410.20526. Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, 2024. URL https: //arxiv.org/abs/2404.15255. Dan Hendrycks, Collin Burns, Steven Basart, An- drew Critch, Jerry Zheng Li, Dawn Xiaodong Song, and Jacob Steinhardt. Aligning ai with shared hu- man values. InInternational Conference on Learn...
-
[5]
Connor Kissane, Robert Krzyzanowski, Arthur Conmy, and Neel Nanda
URLhttps://arxiv.org/abs/2508.06249. Connor Kissane, Robert Krzyzanowski, Arthur Conmy, and Neel Nanda. Saes (usually) trans- fer between base and chat models. Align- ment Forum, 2024. URL https://www. alignmentforum.org/posts/fmwk6qxrpW8d4jvbd/ saes-usually-transfer-between-base-and-chat-models . Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewi...
-
[6]
URLhttps://arxiv.org/abs/2312.06681. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
URL https://transformer-circuits.pub/ 2024/scaling-monosemanticity/index.html. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activa- tion engineering, 2025. URL https://openreview. net/forum?id=2XBPdPIcFK. Miles Wang, Tom Dupr´ e la Tour, Olivia Watkins, Al...
-
[8]
Measure activation shifts ∆ k oncore misalignmentand form a sign-aware candidate poolC(§A.2)
-
[9]
Causally screen candidates via induce-and-repair steering on core misalignment to obtain a shortlist eK (§A.3)
-
[10]
Calibrate shortlisted candidates with per-latent α sweeps on core misalignment under an incoherence budget and select the final latent setK, split into (K +,K −) (§A.4)
-
[11]
Re-run supervised fine-tuning with the one-sided, base-anchored latent penalty Lblock (the BLOCK-EM loss) added to LSFT, yielding a final checkpoint intended to preserve in-domain behavior while not becoming emergently misaligned on out-of-domain prompts (§A.5). A.1 Sparse autoencoders and latent activations We use a sparse autoencoder (SAE) to provide an...
work page 2025
-
[12]
Pre-filtering for nontrivial induction and repair.From the Stage-2 shortlist eK, we retain only latents that exhibitboth(i) nonzero induction on Mbase at their maximal safe inducing strength α⋆ ind(k) and (ii) nonzero repair on the paired checkpoint at their maximal safe repair strength α⋆ rep(k) (both as defined in§A.4)
-
[13]
Repair-only ranking.We then rank remaining latents using only their repair efficiency under the quality constraint: scoreValidReduc(k) = misalign(Mmis;α= 0)−misalign Mmis;α=α ⋆ rep(k) ,(13) and select the top-Nlatents by this score to formK(splitting into (K +,K −) by sign(∆ k) as usual). The finance latent set K used throughout the main papercorresponds ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.