Recognition: no theorem link
When RL Meets Adaptive Speculative Training: A Unified Training-Serving System
Pith reviewed 2026-05-16 06:30 UTC · model grok-4.3
The pith
Aurora unifies speculator training and serving for speculative decoding using asynchronous reinforcement learning from live traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
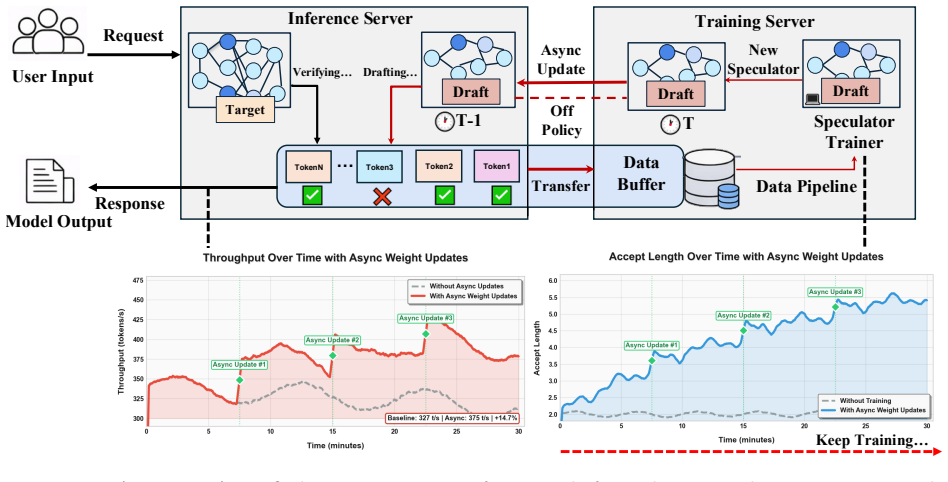
By reframing speculator learning as asynchronous RL where accepted tokens give positive feedback and rejected proposals give implicit negative feedback, Aurora enables a unified training-serving system that supports day-0 deployment and continuous adaptation to user traffic shifts.
What carries the argument
Asynchronous reinforcement learning loop that learns the speculator directly from live inference traces of accepted and rejected tokens.
If this is right
- Immediate 1.5x speedup on frontier models upon deployment without prior offline training.
- Additional 1.25x speedup when adapting to shifts in user traffic compared to static speculators.
- Prevention of performance degradation due to domain drift in the target model.
- Hot-swapped speculator updates that maintain continuous service availability.
Where Pith is reading between the lines
- Similar RL feedback mechanisms could be applied to other serving optimizations like dynamic batching or KV cache management.
- The emphasis on end-to-end speedup over acceptance rate alone may encourage rethinking evaluation metrics for acceleration techniques.
- Deploying on more models could reveal how well the RL signals generalize across different architectures and sizes.
Load-bearing premise
Feedback signals from accepted and rejected tokens during live inference are clean enough to train the speculator stably without excessive tuning.
What would settle it
Running the system on a frontier model and observing either no speedup gain over a static baseline or frequent serving interruptions due to training instability.
Figures









read the original abstract
Speculative decoding can significantly accelerate LLM serving, yet most deployments today disentangle speculator training from serving, treating speculator training as a standalone offline modeling problem. We show that this decoupled formulation introduces substantial deployment and adaptation lag: (1) high time-to-serve, since a speculator must be trained offline for a considerable period before deployment; (2) delayed utility feedback, since the true end-to-end decoding speedup is only known after training and cannot be inferred reliably from acceptance rate alone due to model-architecture and system-level overheads; and (3) domain-drift degradation, as the target model is repurposed to new domains and the speculator becomes stale and less effective. To address these issues, we present Aurora, a unified training-serving system that closes the loop by continuously learning a speculator directly from live inference traces. Aurora reframes online speculator learning as an asynchronous reinforcement-learning problem: accepted tokens provide positive feedback, while rejected speculator proposals provide implicit negative feedback that we exploit to improve sample efficiency. Our design integrates an SGLang-based inference server with an asynchronous training server, enabling hot-swapped speculator updates without service interruption. Crucially, Aurora supports day-0 deployment: a speculator can be served immediately and rapidly adapted to live traffic, improving system performance while providing immediate utility feedback. Across experiments, Aurora achieves a 1.5x day-0 speedup on recently released frontier models (e.g., MiniMax M2.1 229B and Qwen3-Coder-Next 80B). Aurora also adapts effectively to distribution shifts in user traffic, delivering an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Aurora, a unified training-serving system for speculative decoding that closes the loop between inference and speculator training via asynchronous RL. Accepted tokens supply positive feedback while rejected proposals supply implicit negative feedback; the system integrates an SGLang inference server with an asynchronous trainer to enable hot-swapped updates without downtime. The central claims are day-0 deployment with immediate 1.5x speedup on frontier models (MiniMax M2.1 229B, Qwen3-Coder-Next 80B) and an additional 1.25x speedup over static speculators under traffic distribution shifts (Qwen3, Llama3).
Significance. If the empirical results hold under rigorous controls, the work would be significant for production LLM serving: it directly tackles the deployment lag, stale-speculator degradation, and lack of end-to-end utility feedback that currently separate training from serving. The RL framing of online speculator adaptation from live traces is a concrete step toward self-improving inference systems and could influence future designs that treat serving traces as primary training data.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the reported 1.5x day-0 and 1.25x adaptation speedups are presented without any description of experimental setup, number of runs, variance, baseline speculators (including their training data and hyperparameters), or controls for system-level overheads; these omissions are load-bearing because the central claims rest entirely on the magnitude and reliability of the measured speedups.
- [§3] §3 (RL formulation): the asynchronous RL loop is described as using accepted tokens for positive reward and rejected proposals for implicit negative feedback, yet no reward shaping, advantage normalization, clipping, or handling of the confounding factors (target-model uncertainty, temperature, overhead) is specified; without these, policy-gradient instability is a plausible risk that would contradict the day-0 and “no extensive tuning” assertions.
minor comments (2)
- [§3] Notation for the reward signal and the asynchronous update protocol could be formalized with explicit equations to improve reproducibility.
- [Figures and Tables] Figure captions and table headers should explicitly state the models, sequence lengths, and hardware used for each speedup measurement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the reported 1.5x day-0 and 1.25x adaptation speedups are presented without any description of experimental setup, number of runs, variance, baseline speculators (including their training data and hyperparameters), or controls for system-level overheads; these omissions are load-bearing because the central claims rest entirely on the magnitude and reliability of the measured speedups.
Authors: We agree that the current version of the abstract and Experiments section omits key methodological details. In the revised manuscript we will expand the Experiments section with: (i) a full description of the experimental setup (hardware, SGLang integration, traffic generation, and measurement protocol); (ii) results averaged over five independent runs together with standard deviations; (iii) explicit specifications of all baseline speculators, including the offline training data, hyperparameters, and training duration used for each; and (iv) additional measurements and ablations that isolate system-level overheads (training latency, hot-swap cost, and inference-server contention). These additions will directly substantiate the reported speedups. revision: yes
-
Referee: [§3] §3 (RL formulation): the asynchronous RL loop is described as using accepted tokens for positive reward and rejected proposals for implicit negative feedback, yet no reward shaping, advantage normalization, clipping, or handling of the confounding factors (target-model uncertainty, temperature, overhead) is specified; without these, policy-gradient instability is a plausible risk that would contradict the day-0 and “no extensive tuning” assertions.
Authors: We acknowledge that §3 currently provides only a high-level description of the reward signal. In the revision we will add a dedicated paragraph that specifies: accepted tokens receive a reward of +1; each rejected proposal receives a length-scaled negative reward of -0.5; advantage is computed with an exponential-moving-average baseline; and no PPO-style clipping is applied because updates remain infrequent and asynchronous. We will also discuss how confounding factors are handled: target-model uncertainty and temperature are absorbed implicitly by optimizing directly on live end-to-end speedup rather than acceptance rate, while system overhead is captured in the same utility signal. The resulting formulation remains simple enough to support day-0 deployment without offline hyper-parameter search, consistent with the empirical stability we observe. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents Aurora as an empirical unified training-serving system that reframes speculator adaptation as an asynchronous RL problem using live inference traces, with accepted tokens as positive feedback and rejected proposals as implicit negative feedback. All central claims (1.5x day-0 speedup on frontier models and 1.25x adaptation to traffic shifts) are grounded in experimental measurements on specific models rather than any closed-form derivation, self-referential equations, or load-bearing self-citations. No mathematical steps are shown that define a quantity in terms of itself or rename a fitted input as a prediction; the RL formulation applies standard policy-gradient ideas to the speculative decoding setting without reducing the reported speedups to the inputs by construction. The system description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
SpecBlock achieves 8-19% higher speedup than EAGLE-3 in LLM speculative decoding by using repeated block expansions with hidden-state inheritance, a dynamic rank head, and a valid-prefix training mask.
Reference graph
Works this paper leans on
-
[1]
https://huggingface.co/datasets/alespalla/chatbot_ instruction_prompts
chatbot_instruction_prompts. https://huggingface.co/datasets/alespalla/chatbot_ instruction_prompts. Accessed: 2026-01-28
work page 2026
-
[2]
https://huggingface.co/datasets/gbharti/finance-alpaca
finance-alpaca dataset. https://huggingface.co/datasets/gbharti/finance-alpaca. Ac- cessed: 2026-01-28
work page 2026
-
[3]
Anthropic. Claude opus 4.6, 2026. URL https://www.anthropic.com/news/ claude-opus-4-6
work page 2026
-
[4]
Q2 2025 ai hypercomputer updates, 2025
Google Cloud Blog. Q2 2025 ai hypercomputer updates, 2025. URLhttps://cloud.google. com/blog/products/ai-machine-learning/q2-2025-ai-hypercomputer-updates
work page 2025
-
[5]
Medusa: Simple framework for accelerating llm generation with multiple decoding heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, and Tri Dao. Medusa: Simple framework for accelerating llm generation with multiple decoding heads. Accessed: 2023-09-08, 2023
work page 2023
-
[6]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Sequoia: Scalable, robust, and hardware-aware speculative decoding, 2024
Zhuoming Chen, Avner May, Ruslan Svirschevski, Yuhsun Huang, Max Ryabinin, Zhihao Jia, and Beidi Chen. Sequoia: Scalable, robust, and hardware-aware speculative decoding, 2024
work page 2024
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 16
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
work page 2024
-
[11]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding.arXiv preprint arXiv:2402.02057, 2024
-
[13]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. Codesearchnet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[14]
Fast inference from transformers via speculative decoding, 2023
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding, 2023
work page 2023
-
[15]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.International Conference on Machine Learning, 2024
work page 2024
-
[16]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees.arXiv preprint arXiv:2406.16858, 2024
-
[17]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint, 2025
work page 2025
-
[18]
Online speculative decoding.arXiv preprint arXiv:2310.07177, 2023
Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, and Hao Zhang. Online speculative decoding.arXiv preprint arXiv:2310.07177, 2023
-
[19]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification.arXiv preprint arXiv:2305.09781, 2023
-
[20]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
MiniMaxAI. Minimax-m2.1. https://huggingface.co/MiniMaxAI/MiniMax-M2.1, 2024. Hug- ging Face model repository
work page 2024
-
[22]
Introducing gpt-5.3-codex, 2026
OpenAI. Introducing gpt-5.3-codex, 2026. URL https://openai.com/index/ introducing-gpt-5-3-codex/
work page 2026
-
[23]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. Mooncake: A kvcache-centric disaggregated architecture for llm serving.ACM Transactions on Storage, 2024
work page 2024
-
[24]
Qwen3-coder-next technical report
Qwen Team. Qwen3-coder-next technical report. Technical report. URL https://github. com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf. Accessed: 2026- 02-03. 17
work page 2026
-
[25]
MiLeS:Ahighperformancerlframework, 2025
radixark. MiLeS:Ahighperformancerlframework, 2025. URL https://github.com/radixark/ miles. GitHub repository
work page 2025
-
[26]
Zelei Shao, Vikranth Srivatsa, Sanjana Srivastava, Qingyang Wu, Alpay Ariyak, Xiaoxia Wu, Ameen Patel, Jue Wang, Percy Liang, Tri Dao, et al. Beat the long tail: Distribution-aware speculative decoding for rl training.arXiv preprint arXiv:2511.13841, 2025
- [27]
-
[28]
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei A Efros, and Moritz Hardt. Test- time training with self-supervision for generalization under distribution shifts.International Conference on Machine Learning (ICML), pages 9229–9248, 2020
work page 2020
-
[29]
SLiME: A post-training framework for reinforcement learning scaling, 2024
THUDM. SLiME: A post-training framework for reinforcement learning scaling, 2024. URL https://github.com/THUDM/slime. GitHub repository
work page 2024
-
[30]
Junxiong Wang, Daniele Paliotta, Avner May, Alexander Rush, and Tri Dao. The mamba in the llama: Distilling and accelerating hybrid models.Advances in Neural Information Processing Systems, 37:62432–62457, 2024
work page 2024
-
[31]
Angles don’t lie: Unlocking training-efficient rl through the model’s own signals, 2025
Qinsi Wang, Jinghan Ke, Hancheng Ye, Yueqian Lin, Yuzhe Fu, Jianyi Zhang, Kurt Keutzer, Chenfeng Xu, and Yiran Chen. Angles don’t lie: Unlocking training-efficient rl through the model’s own signals, 2025. URLhttps://arxiv.org/abs/2506.02281
-
[32]
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding.arXiv preprint arXiv:2401.07851, 2024
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, ...
work page 2018
-
[36]
Beyond the speculative game: A survey of speculative execution in large language models, 2024
Chen Zhang, Zhuorui Liu, and Dawei Song. Beyond the speculative game: A survey of speculative execution in large language models, 2024. URLhttps://arxiv.org/abs/2404.14897
-
[37]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
work page 2024
-
[38]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024. 18 A Technical Details forAuroraSystem A key technical c...
work page 2024
-
[39]
and DistServe [38], which already separate prefill and decoding onto distinct node pools with cross-node GPU transfer infrastructure. Our training server acts as a third disaggregated role, receiving hidden states and logits over the same communication fabric (e.g., RDMA) without requiring a separate data path. This makes our inference-time training pipel...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.