Recognition: 2 theorem links
· Lean TheoremFinding Connections: Membership Inference Attacks for the Multi-Table Synthetic Data Setting
Pith reviewed 2026-05-16 06:27 UTC · model grok-4.3
The pith
Multi-table membership inference attacks detect user-level privacy leaks in synthetic relational data that single-table methods underestimate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a no-box threat model, heterogeneous graph neural networks trained on the structure of synthetic multi-table data can infer membership of user entities by combining information across all linked tables, revealing privacy leakage that exceeds what item-level single-table attacks can detect.
What carries the argument
Multi-Table Membership Inference Attack (MT-MIA) that constructs user-entity representations via heterogeneous graph neural networks on inter-table connections.
If this is right
- Single-table MIAs systematically underestimate user-level privacy leakage in relational synthetic data.
- State-of-the-art relational synthetic data generators leak membership information through inter-tabular relationships.
- MT-MIA can locate where in the relational structure the leakage occurs.
- Privacy guarantees for synthetic relational data must address complete user entities rather than isolated rows.
Where Pith is reading between the lines
- Synthetic data generators for relational settings may require new mechanisms that explicitly break user-entity signals across tables.
- Privacy audits for multi-table data should adopt entity-level rather than row-level metrics as a baseline.
- The same graph-based approach could be tested on other linked data structures such as knowledge graphs or federated records.
Load-bearing premise
Heterogeneous graph neural networks can learn useful user-entity representations from the connected items across tables even without access to the data generator.
What would settle it
If MT-MIA achieves no higher accuracy than random guessing or single-table baselines when applied to synthetic data from a multi-table source whose membership status is independently known.
Figures



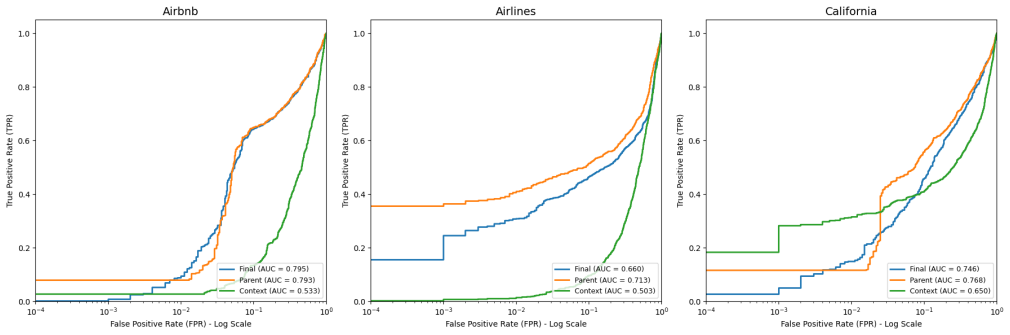
read the original abstract
Synthetic tabular data has gained attention for enabling privacy-preserving data sharing. While substantial progress has been made in single-table synthetic generation where data are modeled at the row or item level, most real-world data exists in relational databases where a user's information spans items across multiple interconnected tables. Recent advances in synthetic relational data generation have emerged to address this complexity, yet release of these data introduce unique privacy challenges as information can be leaked not only from individual items but also through the relationships that comprise a complete user entity. To address this, we propose a novel Membership Inference Attack (MIA) setting to audit the empirical user-level privacy of synthetic relational data and show that single-table MIAs that audit at an item level underestimate user-level privacy leakage. We then propose Multi-Table Membership Inference Attack (MT-MIA), a novel adversarial attack under a No-Box threat model that targets learned representations of user entities via Heterogeneous Graph Neural Networks. By incorporating all connected items for a user, MT-MIA better targets user-level vulnerabilities induced by inter-tabular relationships than existing attacks. We evaluate MT-MIA on a range of real-world multi-table datasets and demonstrate that this vulnerability exists in state-of-the-art relational synthetic data generators, employing MT-MIA to additionally study where this leakage occurs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MT-MIA, a membership inference attack for multi-table synthetic data that uses heterogeneous graph neural networks to learn user-entity representations from connected items across tables. It claims that single-table item-level MIAs underestimate user-level privacy leakage induced by inter-tabular relationships, and demonstrates that this vulnerability exists in state-of-the-art relational generators under a No-Box threat model.
Significance. If the attack construction is sound and the No-Box label acquisition is shown to be free of implicit distributional leakage, the result would be significant: it would establish a concrete, graph-based method for auditing relational privacy leakage that single-table attacks miss, with direct implications for evaluating synthetic data generators on real-world multi-table schemas.
major comments (1)
- [Abstract] Abstract: the No-Box threat model is presented without any description of how the attacker obtains labeled member/non-member user entities to train the downstream membership classifier on the H-GNN embeddings. This mechanism is load-bearing for the central claim that MT-MIA isolates the effect of inter-tabular relationships rather than benefiting from auxiliary label information.
minor comments (1)
- [Abstract] Abstract: quantitative results, error bars, dataset names, and specific metrics (e.g., AUC or TPR at low FPR) are absent, making it impossible to assess the magnitude of the claimed underestimation by single-table attacks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights an important point for improving the clarity of our presentation. We address the major comment below and will incorporate the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the No-Box threat model is presented without any description of how the attacker obtains labeled member/non-member user entities to train the downstream membership classifier on the H-GNN embeddings. This mechanism is load-bearing for the central claim that MT-MIA isolates the effect of inter-tabular relationships rather than benefiting from auxiliary label information.
Authors: We agree that the abstract does not explicitly describe the label acquisition process and will revise it (along with the threat model section) to address this. In the No-Box setting, the attacker has no access to the generative model or its parameters but is assumed to possess a small auxiliary set of real user entities with known membership labels (drawn from the same underlying distribution but disjoint from the original training data). These labeled entities are used solely to train the H-GNN to produce user-entity embeddings and to fit the downstream membership classifier. Because the auxiliary labels are independent of the specific synthetic dataset under attack, they do not convey information about the generator's internal behavior or introduce distributional leakage beyond the standard No-Box assumption. This setup ensures that any measured advantage of MT-MIA over single-table baselines arises from its ability to exploit inter-tabular relationships rather than from privileged label information. The revision will make this mechanism explicit so that the central claim is fully supported. revision: yes
Circularity Check
No significant circularity detected in MT-MIA derivation
full rationale
The paper introduces MT-MIA as an independent adversarial construction that applies Heterogeneous Graph Neural Networks to learn user-entity representations from released synthetic tables alone under the No-Box model. No equations or steps reduce a claimed prediction to a fitted parameter by construction, nor does any load-bearing premise collapse to a self-citation whose content is itself defined by the present work. The central claim—that inter-tabular relationships induce measurable user-level leakage beyond item-level attacks—is supported by evaluation on external real-world datasets rather than by renaming or re-deriving the input assumptions. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption User entities can be effectively represented as heterogeneous graphs connecting items across multiple tables
- domain assumption No-Box threat model is appropriate for auditing synthetic relational data generators
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct relational databases as heterogeneous graphs... MT-MIA leverages HGNNs to detect memorized motifs
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MT-MIA... self-supervised reconstruction objective... Dynamic Gated Fusion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
FERMI: Exploiting Relations for Membership Inference Against Tabular Diffusion Models
FERMI improves membership inference on tabular diffusion models by mapping relational auxiliary information into attack features, raising TPR at 0.1 FPR by up to 53% white-box and 22% black-box over single-table baselines.
Reference graph
Works this paper leans on
-
[1]
what do you want from theory alone?
Meenatchi Sundaram Muthu Selva Annamalai, Georgi Ganev, and Emiliano De Cristofaro. "what do you want from theory alone?" experimenting with tight auditing of differentially private synthetic data generation. In USENIX Security Symposium, 2024
work page 2024
-
[2]
Language models are realistic tabular data generators, 2023
Vadim Borisov, Kathrin Seßler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators, 2023. 12
work page 2023
-
[3]
Shaked Brody, Uri Alon, and Eran Yahav. How attentive are graph attention networks? InInternational Confer- ence on Learning Representations, 2022
work page 2022
-
[4]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, A. Terzis, and Florian Tramèr. Membership inference attacks from first principles.2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914, 2021
work page 2022
-
[5]
Integrated public use microdata series, international: Version 7.3, 2020
Minnesota Population Center. Integrated public use microdata series, international: Version 7.3, 2020
work page 2020
-
[6]
Gan-leaks: A taxonomy of membership inference at- tacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of membership inference at- tacks against generative models. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Com- munications Security, CCS ’20. ACM, October 2020
work page 2020
-
[7]
From data mining to knowledge discovery in databases.AI Magazine, 17(3):37, Mar
Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From data mining to knowledge discovery in databases.AI Magazine, 17(3):37, Mar. 1996
work page 1996
-
[8]
Relational deep learning: Graph representation learning on relational databases, 2023
Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, and Jure Leskovec. Relational deep learning: Graph representation learning on relational databases, 2023
work page 2023
-
[9]
Position: Relational deep learning - graph representation learning on rela- tional databases
Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, and Jure Leskovec. Position: Relational deep learning - graph representation learning on rela- tional databases. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editor...
work page 2024
-
[10]
Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding
Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. WWW ’20, page 2331–2341, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[11]
Row conditional-tgan for generating synthetic relational databases
Mohamed Gueye, Yazid Attabi, and Maxime Dumas. Row conditional-tgan for generating synthetic relational databases. pages 1–5, 06 2023
work page 2023
-
[12]
Florent Guépin, Nataša Kr ˇco, Matthieu Meeus, and Yves-Alexandre de Montjoye. Lost in the averages: A new specific setup to evaluate membership inference attacks against machine learning models, 2024
work page 2024
-
[13]
Jamie Hayes, Luca Melis, George Danezis, and Emil- iano De Cristofaro. Logan: Membership inference at- tacks against generative models.Proceedings on Pri- vacy Enhancing Technologies, 2019:133 – 152, 2017
work page 2019
-
[14]
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. Monte carlo and reconstruction membership in- ference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019:232 – 249, 2019
work page 2019
-
[15]
Florimond Houssiau, James Jordon, Samuel N Co- hen, Owen Daniel, Andrew Elliott, James Geddes, Cal- lum Mole, Camila Rangel-Smith, and Lukasz Szpruch. Tapas: a toolbox for adversarial privacy auditing of syn- thetic data.arXiv preprint arXiv:2211.06550, 2022
-
[16]
Heterogeneous graph transformer
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. Heterogeneous graph transformer. InProceed- ings of The Web Conference 2020, WWW ’20, page 2704–2710, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[17]
MIDST Challenge: Membership In- ference over Diffusion-models-based Synthetic Tab- ular data
Vector Institute. MIDST Challenge: Membership In- ference over Diffusion-models-based Synthetic Tab- ular data. https://vectorinstitute.github.io/ MIDST/, 2025. Hosted at the 3rd IEEE Conference on Secure and Trustworthy Machine Learning (SaTML 2025)
work page 2025
-
[18]
Tabddpm: Modelling tabular data with diffusion models, 2022
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models, 2022
work page 2022
-
[19]
Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self- attention graph pooling. InProceedings of the 36th International Conference on Machine Learning, 09–15 Jun 2019
work page 2019
-
[20]
Yunhui Long, Lei Wang, Diyue Bu, Vincent Bind- schaedler, Xiaofeng Wang, Haixu Tang, Carl A. Gunter, and Kai Chen. A pragmatic approach to membership in- ferences on machine learning models. In2020 IEEE Eu- ropean Symposium on Security and Privacy (EuroS&P), pages 521–534, 2020
work page 2020
-
[21]
Carmen Martínez-Cruz, Ignacio J. Blanco, and María Amparo Vila. Ontologies versus relational databases: are they so different? a comparison.Artificial Intelligence Review, 38:271–290, 2012
work page 2012
-
[22]
Springer Nature Switzerland, 2024
Matthieu Meeus, Florent Guepin, Ana-Maria Cre¸ tu, and Yves-Alexandre de Montjoye.Achilles’ Heels: Vulnera- ble Record Identification in Synthetic Data Publishing, page 380–399. Springer Nature Switzerland, 2024
work page 2024
-
[23]
Tabular transformers for modeling multivariate time series
Inkit Padhi, Yair Schiff, Igor Melnyk, Mattia Rigotti, Youssef Mroueh, Pierre Dognin, Jerret Ross, Ravi Nair, and Erik Altman. Tabular transformers for modeling multivariate time series. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), pages 3565–3569, 2021. 13
work page 2021
-
[24]
Airline loyalty campaign program impact on flights
Agung Pambudi. Airline loyalty campaign program impact on flights. Kaggle Dataset, 2025. Retrieved from https://www.kaggle.com/datasets/agungpambudi/airline- loyalty-campaign-program-impact-on-flights
work page 2025
-
[25]
Clavaddpm: multi-relational data synthesis with cluster-guided diffusion models
Wei Pang, Masoumeh Shafieinejad, Lucy Liu, Stephanie Hazlewood, and Xi He. Clavaddpm: multi-relational data synthesis with cluster-guided diffusion models. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc
work page 2024
-
[26]
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. The synthetic data vault. In2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pages 399–410, 2016
work page 2016
-
[27]
Joshua Robinson, Rishabh Ranjan, Weihua Hu, Kexin Huang, Jiaqi Han, Alejandro Dobles, Matthias Fey, Jan Eric Lenssen, Yiwen Yuan, Zecheng Zhang, et al. Relbench: A benchmark for deep learning on relational databases.Advances in Neural Information Processing Systems, 37:21330–21341, 2024
work page 2024
-
[28]
White-box vs black-box: Bayes optimal strategies for membership inference
Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, Yann Ollivier, and Hervé Jégou. White-box vs black-box: Bayes optimal strategies for membership inference. InInternational Conference on Machine Learning, 2019
work page 2019
-
[29]
Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling
Michael Schlichtkrull, Thomas N. Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Mod- eling relational data with graph convolutional networks. In Aldo Gangemi, Roberto Navigli, Maria-Esther Vidal, Pascal Hitzler, Raphaël Troncy, Laura Hollink, Anna Tordai, and Mehwish Alam, editors,The Semantic Web, pages 593–607, Cham, 2018. Springer...
work page 2018
- [30]
-
[31]
Aivin V Solatorio and Olivier Dupriez. Realtabformer: Generating realistic relational and tabular data using transformers.arXiv preprint arXiv:2302.02041, 2023
-
[32]
Synthetic data – anonymisation groundhog day
Theresa Stadler, Bristena Oprisanu, and Carmela Tron- coso. Synthetic data – anonymisation groundhog day. In31st USENIX Security Symposium (USENIX Secu- rity 22), pages 1451–1468, Boston, MA, August 2022. USENIX Association
work page 2022
-
[33]
Autodiff: combining auto-encoder and diffusion model for tabular data syn- thesizing
Namjoon Suh, Xiaofeng Lin, Din-Yin Hsieh, Mehrdad Honarkhah, and Guang Cheng. Autodiff: combining auto-encoder and diffusion model for tabular data syn- thesizing. InNeurIPS 2023 Workshop on Synthetic Data Generation with Generative AI, 2023
work page 2023
-
[34]
Membership inference attacks against synthetic data through overfitting detection, 2023
Boris van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. Membership inference attacks against synthetic data through overfitting detection, 2023
work page 2023
-
[35]
Airbnb recruiting: New user bookings
Airbnb (via Kaggle). Airbnb recruiting: New user bookings. Kaggle Competition Dataset, 2015. Retrieved from https://www.kaggle.com/competitions/airbnb- recruiting-new-user-bookings/data
work page 2015
-
[36]
Heterogeneous graph attention network
Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. Heterogeneous graph attention network. InThe World Wide Web Conference, WWW ’19, page 2022–2032, New York, NY , USA, 2019. Association for Computing Machinery
work page 2022
-
[37]
Synth-mia: A testbed for auditing privacy leak- age in tabular data synthesis, 2025
Joshua Ward, Xiaofeng Lin, , Chi-Hua Wang, and Guang Cheng. Synth-mia: A testbed for auditing privacy leak- age in tabular data synthesis, 2025
work page 2025
-
[38]
Joshua Ward, Chi-Hua Wang, and Guang Cheng. Data plagiarism index: Characterizing the privacy risk of data- copying in tabular generative models.KDD- Generative AI Evaluation Workshop, 2024
work page 2024
-
[39]
Privacy auditing synthetic data release through local likelihood attacks, 2025
Joshua Ward, Chi-Hua Wang, and Guang Cheng. Privacy auditing synthetic data release through local likelihood attacks, 2025
work page 2025
-
[40]
On the importance of diffi- culty calibration in membership inference attacks
Lauren Watson, Chuan Guo, Graham Cormode, and Alexandre Sablayrolles. On the importance of diffi- culty calibration in membership inference attacks. In International Conference on Learning Representations, 2022
work page 2022
-
[41]
Xiaoyu Wu, Yifei Pang, Terrance Liu, and Steven Wu. Winning the midst challenge: New membership infer- ence attacks on diffusion models for tabular data synthe- sis, 2025
work page 2025
-
[42]
Modeling tabular data using conditional gan
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan. InNeural Information Processing Sys- tems, 2019
work page 2019
-
[43]
Simple and efficient heterogeneous graph neural network, 2023
Xiaocheng Yang, Mingyu Yan, Shirui Pan, Xiaochun Ye, and Dongrui Fan. Simple and efficient heterogeneous graph neural network, 2023
work page 2023
-
[44]
Enhanced membership inference attacks against machine learn- ing models
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Vincent Bindschaedler, and Reza Shokri. Enhanced membership inference attacks against machine learn- ing models. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS ’22, page 3093–3106, New York, NY , USA, 2022. Association for Computing Machinery. 14
work page 2022
-
[45]
Anonymization through data synthe- sis using generative adversarial networks (ads-gan)
Jinsung Yoon, Lydia N Drumright, and Mihaela Van Der Schaar. Anonymization through data synthe- sis using generative adversarial networks (ads-gan). IEEE journal of biomedical and health informatics, 24(8):2378–2388, 2020
work page 2020
-
[46]
PATE-GAN: Generating synthetic data with differential privacy guarantees
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. PATE-GAN: Generating synthetic data with differential privacy guarantees. InInternational Confer- ence on Learning Representations, 2019
work page 2019
-
[47]
Low- cost high-power membership inference attacks, 2024
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low- cost high-power membership inference attacks, 2024
work page 2024
-
[48]
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V . Chawla. Heterogeneous graph neural network. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Dis- covery & Data Mining, KDD ’19, page 793–803, New York, NY , USA, 2019. Association for Computing Ma- chinery
work page 2019
-
[49]
Mixed-type tabular data synthesis with score-based diffusion in la- tent space
Hengrui Zhang, Jiani Zhang, Zhengyuan Shen, Bala- subramaniam Srinivasan, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-type tabular data synthesis with score-based diffusion in la- tent space. InThe Twelfth International Conference on Learning Representations, 2024. 15
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.