Recognition: no theorem link
FERMI: Exploiting Relations for Membership Inference Against Tabular Diffusion Models
Pith reviewed 2026-05-13 01:16 UTC · model grok-4.3
The pith
A relational feature-mapping attack called FERMI raises membership inference success rates against tabular diffusion models when parent-table information is available only during attack training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
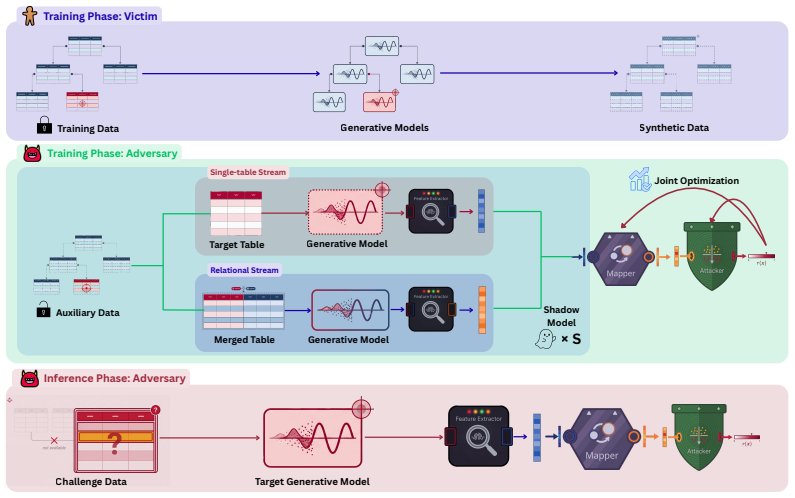
We propose FERMI (FEature-mapping for Relational Membership Inference), which resolves this gap by enriching single-table features with relational membership signal. Across three tabular diffusion architectures and three real-world relational datasets, FERMI consistently improves attack performance over single-table baselines, with TPR@0.1FPR rising by up to 53% over the single-table baseline in the white-box setting and 22% in the black-box setting.
What carries the argument
FERMI, a feature-mapping step that injects relational membership signals extracted from parent tables into the single-table feature vector used by the attack classifier.
If this is right
- Single-table membership inference baselines systematically underestimate privacy leakage for relational tabular data.
- Tabular diffusion models trained on linked tables release more membership information than models trained on isolated tables.
- Attackers can obtain higher true-positive rates at fixed low false-positive rates by training on parent-table features even when those features are unavailable at inference time.
- Privacy assessments of synthetic data generators must incorporate multi-table structure to be reliable.
- Defenses for diffusion models on relational data need to address leakage that propagates through parent-child links.
Where Pith is reading between the lines
- Privacy audits of synthetic relational datasets should routinely include parent-table information during attack calibration.
- The same relational enrichment technique could be tested on other generative models such as GANs or VAEs to measure whether the leakage pattern is architecture-specific.
- If the relational signal proves stable across domains, regulators might require relational privacy evaluations before releasing synthetic versions of linked government or health records.
Load-bearing premise
That the observed performance gains reflect genuine additional membership leakage carried by relations rather than artifacts of the selected datasets or attack hyperparameters.
What would settle it
Repeating the white-box and black-box experiments on new relational datasets where parent-table attributes are uncorrelated with membership status in the target table, and checking whether the TPR@0.1FPR gap shrinks to near zero.
Figures

read the original abstract
Diffusion models are the leading approach for tabular data synthesis and are increasingly used to share sensitive records. Whether they actually protect privacy has become a pressing question. Membership inference attacks are the standard tool for this purpose, yet existing attacks assume a single-table setting and ignore the multi-relational structure of real sensitive data. A core challenge in assessing privacy risks from membership inference attacks in multi-table settings is how to leverage auxiliary information from relations associated with the target table, such as its parent tables. Particularly, we study a practical setting in which such auxiliary information is available only when training the attack model. At inference time, the attacker observes only the attribute values of the target record from the target table. We propose FERMI (FEature-mapping for Relational Membership Inference), which resolves this gap by enriching single-table features with relational membership signal. Across three tabular diffusion architectures and three real-world relational datasets, FERMI consistently improves attack performance over single-table baselines, with TPR@$0.1$FPR rising by up to 53% over the single-table baseline in the white-box setting and 22% in the black-box setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FERMI, a feature-mapping technique for membership inference attacks (MIA) on tabular diffusion models in multi-relational settings. It enriches single-table attack features with signals derived from parent tables, but restricts the attacker to target-table attributes only at inference time. Experiments across three diffusion architectures and three real-world relational datasets report consistent gains over single-table baselines, with TPR@0.1FPR improving by up to 53% (white-box) and 22% (black-box).
Significance. If the reported gains can be shown to arise from genuine relational leakage rather than feature-count artifacts, the work would meaningfully extend MIA analysis to realistic multi-table data synthesis, where diffusion models are used for privacy-sensitive sharing. This would strengthen the case for relation-aware privacy defenses in tabular generative modeling.
major comments (2)
- [§5] §5 (Experimental Evaluation): The headline TPR@0.1FPR lifts (up to 53%/22%) rest on comparing a relational-enriched attack model against a single-table baseline that necessarily uses fewer features. No ablation is reported that holds total input dimensionality, feature scale, and training dynamics fixed while randomizing or nullifying the relational component (e.g., via shuffled parent-table rows or noise padding). Without this control, the performance difference cannot be attributed to diffusion-model leakage through relations rather than the expanded feature space.
- [§4] §4 (FERMI Method): The precise construction of the 'relational membership signal' (what statistics, embeddings, or aggregations are extracted from parent tables and how they are mapped) is described at a high level only. Reproducibility requires the exact feature definitions, aggregation functions, and any hyperparameters used to combine them with single-table features.
minor comments (2)
- [§5] The manuscript does not report the number of independent runs, standard deviations, or statistical significance tests for the TPR@0.1FPR differences, making it difficult to assess whether the gains are robust.
- [§3] Notation for the threat model (white-box vs. black-box access to the diffusion model) and the exact point at which auxiliary relational data becomes unavailable should be stated more explicitly in the problem formulation.
Simulated Author's Rebuttal
We are grateful to the referee for their thorough review and valuable suggestions. The comments highlight important aspects for strengthening the experimental validation and methodological details. We respond to each major comment point-by-point and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Evaluation): The headline TPR@0.1FPR lifts (up to 53%/22%) rest on comparing a relational-enriched attack model against a single-table baseline that necessarily uses fewer features. No ablation is reported that holds total input dimensionality, feature scale, and training dynamics fixed while randomizing or nullifying the relational component (e.g., via shuffled parent-table rows or noise padding). Without this control, the performance difference cannot be attributed to diffusion-model leakage through relations rather than the expanded feature space.
Authors: We agree that controlling for feature dimensionality is important to isolate the contribution of relational signals. In the revised version, we will include an ablation study that matches the input dimensionality of the FERMI attack by padding the single-table baseline with either random noise features or shuffled relational features (which nullify any meaningful relational leakage). We will report the results of this control experiment to demonstrate that the performance gains are indeed due to genuine relational information leakage from the diffusion models rather than mere feature count. This addresses the concern directly. revision: yes
-
Referee: [§4] §4 (FERMI Method): The precise construction of the 'relational membership signal' (what statistics, embeddings, or aggregations are extracted from parent tables and how they are mapped) is described at a high level only. Reproducibility requires the exact feature definitions, aggregation functions, and any hyperparameters used to combine them with single-table features.
Authors: We acknowledge that Section 4 provides a high-level overview of the relational membership signal construction. To improve reproducibility, we will expand this section in the revised manuscript with precise definitions: specifically, we will detail the aggregation functions (e.g., mean, variance, count of matching records in parent tables), any embedding techniques used for categorical relations, and the exact hyperparameters for feature combination (such as concatenation weights or normalization). Additionally, we will include pseudocode for the feature mapping process and make the implementation details available in the supplementary material or code repository. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation
full rationale
The paper proposes FERMI as an empirical membership inference method that augments single-table features with relational signals from parent tables, then reports observed TPR@0.1FPR lifts on three diffusion architectures and three datasets. No derivation chain, first-principles result, or mathematical prediction is claimed; the central results are experimental comparisons to single-table baselines. No self-citation is load-bearing, no parameter is fitted and then renamed as a prediction, and no ansatz or uniqueness theorem is invoked. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela Van Der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International conference on machine learning, pages 290–306. PMLR, 2022
work page 2022
-
[2]
Stefan Bender, Ron S Jarmin, Frauke Kreuter, and Julia Lane. Privacy and confidentiality. In Big data and social science, pages 313–331. Chapman and Hall/CRC, 2020
work page 2020
-
[3]
Guide to the financial data set
Petr Berka et al. Guide to the financial data set. InThe ECML/PKDD, 2000
work page 2000
-
[4]
Martin Bertran, Shuai Tang, Aaron Roth, Michael Kearns, Jamie H Morgenstern, and Steven Z Wu. Scalable membership inference attacks via quantile regression.Advances in Neural Information Processing Systems, 36:314–330, 2023
work page 2023
-
[5]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP), pages 1897–1914. IEEE, 2022
work page 1914
-
[6]
Extracting training data from diffusion models
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In32nd USENIX security symposium (USENIX Security 23), pages 5253–5270, 2023
work page 2023
-
[7]
Jinhao Duan, Fei Kong, Shiqi Wang, Xiaoshuang Shi, and Kaidi Xu. Are diffusion models vulnerable to membership inference attacks? InInternational Conference on Machine Learning, pages 8717–8730. PMLR, 2023
work page 2023
-
[8]
Mauro Giuffrè and Dennis L Shung. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy.NPJ digital medicine, 6(1):186, 2023
work page 2023
-
[9]
Trung Ha, Tran Khanh Dang, and Nhan Nguyen-Tan. Comprehensive analysis of privacy in black-box and white-box inference attacks against generative adversarial network. InIn- ternational Conference on Future Data and Security Engineering, pages 323–337. Springer, 2021
work page 2021
-
[10]
Logan: Membership inference attacks against generative models.arXiv preprint arXiv:1705.07663, 2017
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. Logan: Membership inference attacks against generative models.arXiv preprint arXiv:1705.07663, 2017
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[12]
Membership inference of diffusion models.arXiv preprint arXiv:2301.09956, 2023
Hailong Hu and Jun Pang. Membership inference of diffusion models.arXiv preprint arXiv:2301.09956, 2023
-
[13]
Relational data generation with graph neural networks and latent diffusion models
Valter Hudovernik. Relational data generation with graph neural networks and latent diffusion models. InNeurIPS 2024 Third Table Representation Learning Workshop, 2024
work page 2024
-
[14]
Evaluating differentially private machine learning in practice
Bargav Jayaraman and David Evans. Evaluating differentially private machine learning in practice. In28th USENIX security symposium (USENIX security 19), pages 1895–1912, 2019
work page 1912
-
[15]
Tabddpm: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Mod- elling tabular data with diffusion models. InInternational conference on machine learning, pages 17564–17579. PMLR, 2023
work page 2023
-
[16]
Practical bayes-optimal membership inference attacks.arXiv preprint arXiv:2505.24089, 2025
Marcus Lassila, Johan Östman, Khac-Hoang Ngo, et al. Practical bayes-optimal membership inference attacks.arXiv preprint arXiv:2505.24089, 2025
-
[17]
Goggle: Generative modelling for tabular data by learning relational structure
Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar. Goggle: Generative modelling for tabular data by learning relational structure. InThe Eleventh International Conference on Learning Representations, 2023. 10
work page 2023
-
[18]
James Meldrum, Basem Suleiman, Fethi Rabhi, and Muhammad Johan Alibasa. New money: A systematic review of synthetic data generation for finance.arXiv preprint arXiv:2510.26076, 2025
-
[19]
Jorge M Mendes, Aziz Barbar, and Marwa Refaie. Synthetic data generation: a privacy- preserving approach to accelerate rare disease research.Frontiers in Digital Health, 7:1563991, 2025
work page 2025
-
[20]
Wei Pang, Masoumeh Shafieinejad, Lucy Liu, Stephanie Hazlewood, and Xi He. Clavaddpm: Multi-relational data synthesis with cluster-guided diffusion models.Advances in Neural Information Processing Systems, 37:83521–83547, 2024
work page 2024
-
[21]
International microdata: Version 7.3 [dataset]
Integrated Public Use Microdata Series. International microdata: Version 7.3 [dataset]. min- neapolis population center: Ipums, 2020
work page 2020
-
[22]
Masoumeh Shafieinejad, Xi He, Mahshid Alinoori, John Jewell, Sana Ayromlou, Wei Pang, Veronica Chatrath, Garui Sharma, and Deval Pandya. Midst challenge at satml 2025: Membership inference over diffusion-models-based synthetic tabular data.arXiv preprint arXiv:2603.19185, 2026
work page internal anchor Pith review arXiv 2025
-
[23]
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tabd- iff: a mixed-type diffusion model for tabular data generation.arXiv preprint arXiv:2410.20626, 2024
-
[24]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
work page 2017
-
[25]
Domain adaptation: challenges, methods, datasets, and applications.IEEE access, 11:6973–7020, 2023
Peeyush Singhal, Rahee Walambe, Sheela Ramanna, and Ketan Kotecha. Domain adaptation: challenges, methods, datasets, and applications.IEEE access, 11:6973–7020, 2023
work page 2023
-
[26]
Jeremy Stanley, M. Risdal, Sharath Rao, and W. Cukierski. Instacart market basket analysis, 2017
work page 2017
-
[27]
Correlation alignment for unsupervised domain adaptation
Baochen Sun, Jiashi Feng, and Kate Saenko. Correlation alignment for unsupervised domain adaptation. InDomain adaptation in computer vision applications, pages 153–171. Springer, 2017
work page 2017
-
[28]
The hipaa privacy rule and the eu gdpr: illustrative comparisons.Seton Hall L
Stacey A Tovino. The hipaa privacy rule and the eu gdpr: illustrative comparisons.Seton Hall L. Rev., 47:973, 2016
work page 2016
-
[29]
Boris Van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. Membership inference attacks against synthetic data through overfitting detection.arXiv preprint arXiv:2302.12580, 2023
-
[30]
Ensembling membership inference attacks against tabular generative models
Joshua Ward, Yuxuan Yang, Chi-Hua Wang, and Guang Cheng. Ensembling membership inference attacks against tabular generative models. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security, pages 182–193, 2025
work page 2025
-
[31]
Finding Connections: Membership Inference Attacks for the Multi-Table Synthetic Data Setting
Joshua Ward, Chi-Hua Wang, and Guang Cheng. Finding connections: Membership inference attacks for the multi-table synthetic data setting.arXiv preprint arXiv:2602.07126, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Xiaoyu Wu, Yifei Pang, Terrance Liu, and Steven Wu. Winning the midst challenge: New membership inference attacks on diffusion models for tabular data synthesis.arXiv preprint arXiv:2503.12008, 2025
- [33]
-
[34]
Ziqi Zhang, Chao Yan, and Bradley A Malin. Membership inference attacks against synthetic health data.Journal of biomedical informatics, 125:103977, 2022. 11 A Datasets Here we describe the three real-world multi-relational datasets used in our evaluation. Summary statistics are reported in Table 5. For each dataset, we identify a singletarget tableon whi...
work page 2022
-
[35]
TabDiff [23]adopts a continuous-time diffusion process with per-column learned noise schedules
additionally requires loading parent–child clustering checkpoints, which assign each child record to a cluster conditioned on its parent; this cluster assignment serves as the conditioning variable for the denoising function. TabDiff [23]adopts a continuous-time diffusion process with per-column learned noise schedules. We probe the model at seven time po...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.