Recognition: no theorem link
When Less is More: The LLM Scaling Paradox in Context Compression
Pith reviewed 2026-05-16 02:25 UTC · model grok-4.3
The pith
Larger compressors in LLM context compression reduce faithfulness of reconstructed contexts even as error drops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In lossy context compression using a compressor-decoder setup, increasing the size of the compressor model can decrease the faithfulness of the reconstructed contexts even as the reconstruction error decreases. This Size-Fidelity Paradox is driven by knowledge overwriting, where larger models replace source facts with their prior beliefs, and semantic drift, where content is paraphrased or restructured rather than reproduced exactly. Analysis of compressed memory via embedding geometry and reconstruction determinacy shows that compressors organize memory across broader semantic subspaces, yielding more ambiguous representations prone to overwriting, drift, and weakened recovery. The paradox,
What carries the argument
The Size-Fidelity Paradox driven by knowledge overwriting and semantic drift, analyzed through embedding geometry of compressed memory.
If this is right
- Mid-sized compressors often outperform larger ones in faithful recovery across tested setups.
- Standard scaling laws for generation fail when the objective is faithful preservation of source context.
- Compressors spread representations over broader semantic subspaces, increasing ambiguity in recovery.
- Context compression evaluations must track faithfulness separately from reconstruction error.
- The paradox holds across model families, scales, and compression rates.
Where Pith is reading between the lines
- Designers of retrieval-augmented systems may benefit from capping compressor scale for tasks that require exact fact retention.
- Controlled training on synthetic data that conflicts with model priors could isolate overwriting effects from data differences.
- The embedding-geometry finding suggests adding explicit constraints during compression to keep representations narrower and more source-specific.
Load-bearing premise
The observed effects are driven primarily by knowledge overwriting and semantic drift rather than by unmeasured factors such as training data differences or specific architectural choices.
What would settle it
Train compressor models of different sizes on identical data and architectures, then test whether larger ones still show higher rates of fact overwriting or semantic reordering on held-out conflicting inputs.
Figures



read the original abstract
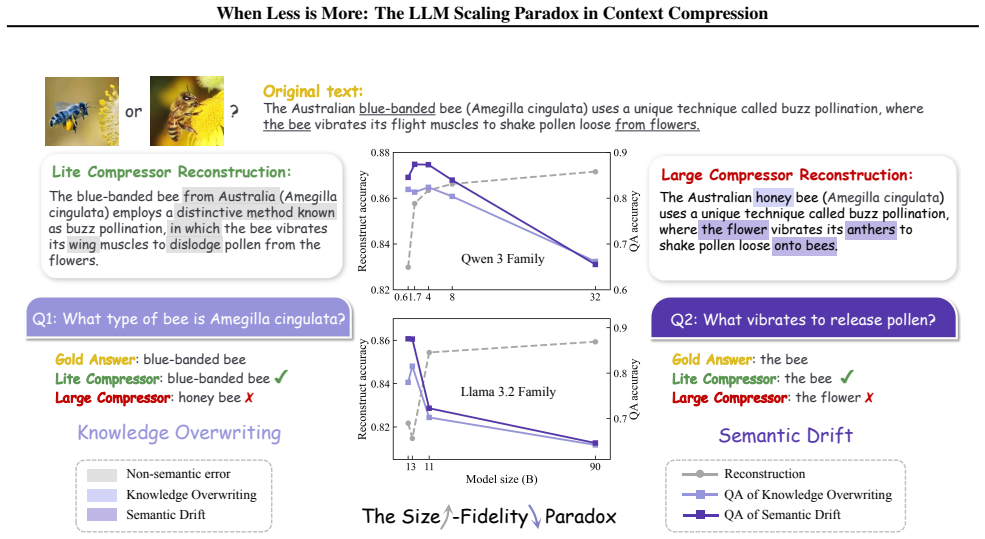
Scaling up model parameters has long been a prevalent training paradigm driven by the assumption that larger models yield superior generation capabilities. However, under lossy context compression in a compressor--decoder setup, we find a \textbf{\textit{Size-Fidelity Paradox}}: increasing compressor size can lessen the faithfulness of reconstructed contexts though reconstruction error decreases. Across 27 compressor setups spanning model families, scales, and compression rates, we coin this paradox arising from two dominant factors: 1) \textit{knowledge overwriting}: larger models increasingly replace source facts with their own prior beliefs, \textit{e.g.}, ``the white strawberry`` $\to$ ``the red strawberry``; and 2) \textit{semantic drift}: larger models tend to paraphrase or restructure content instead of reproducing it verbatim, \textit{e.g.}, ``Alice hit Bob`` $\to$ ``Bob hit Alice``. Interestingly, this paradox persists across varied settings, with mid-sized compressors often outperforming larger ones in faithful recovery. By analyzing the compressed memory via embedding geometry and reconstruction determinacy, we further reveal that compressors tend to organize memory across broader semantic subspaces, yielding more ambiguous representations prone to overwriting, drift, and weakened recovery. These findings complement existing evaluations of context compression and expose a breakdown of scaling laws when the objective shifts from plausible generation to faithful preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines context compression in a compressor-decoder LLM setup and reports a Size-Fidelity Paradox: larger compressors achieve lower reconstruction error yet produce less faithful context reconstructions. The effect is attributed to knowledge overwriting (e.g., source facts replaced by model priors) and semantic drift (e.g., paraphrasing or reordering), observed across 27 setups spanning model families, scales, and compression rates. Mid-sized compressors are reported to outperform larger ones in faithful recovery. Additional analysis of compressed memory via embedding geometry suggests larger models map content into broader semantic subspaces, increasing ambiguity.
Significance. If the central observations hold after controlling for confounds, the result would usefully qualify scaling laws for tasks that prioritize faithful preservation over plausible generation. The multi-family empirical sweep and geometric analysis constitute concrete strengths; the work supplies falsifiable predictions about optimal compressor scale and could inform practical compression design.
major comments (2)
- [§3] §3 (Experimental Setup): The claim that the Size-Fidelity Paradox is driven by parameter count via overwriting and drift is not isolated from confounds. The 27 setups span different model families and scales without reported matched pretraining corpora, identical fine-tuning data, or controlled architectural variants (e.g., same tokenizer and objective). This leaves open the possibility that differences in prior strength or inductive biases produce the observed pattern, undermining the isolation required to attribute the effect to size alone.
- [§4.2] §4.2 (Embedding Geometry Analysis): The assertion that larger compressors organize memory across broader semantic subspaces, yielding more ambiguous representations, lacks quantitative support. No metrics (e.g., subspace dimensionality, variance explained, or statistical comparison of embedding spreads) or controls for reconstruction length are provided to link the geometric observation directly to the faithfulness drop.
minor comments (2)
- [Abstract] Abstract: The phrase '27 compressor setups' is used without a compact summary table listing the exact models, parameter counts, and compression rates; adding such a table would improve reproducibility.
- [Figures] Figure captions: Several figures lack explicit axis labels for compression rate or error bars on faithfulness metrics, reducing immediate interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Setup): The claim that the Size-Fidelity Paradox is driven by parameter count via overwriting and drift is not isolated from confounds. The 27 setups span different model families and scales without reported matched pretraining corpora, identical fine-tuning data, or controlled architectural variants (e.g., same tokenizer and objective). This leaves open the possibility that differences in prior strength or inductive biases produce the observed pattern, undermining the isolation required to attribute the effect to size alone.
Authors: We agree that perfectly matched pretraining corpora and identical architectures across all scales are not feasible with publicly available models. Nevertheless, the Size-Fidelity Paradox appears consistently across all 27 configurations and multiple families, including cases where model families overlap at different scales. This cross-family replication reduces the likelihood that the pattern is driven purely by family-specific inductive biases. In revision we will add an explicit limitations subsection that discusses pretraining-data and tokenizer confounds, report all available within-family scale comparisons, and qualify the attribution to parameter count accordingly. revision: partial
-
Referee: [§4.2] §4.2 (Embedding Geometry Analysis): The assertion that larger compressors organize memory across broader semantic subspaces, yielding more ambiguous representations, lacks quantitative support. No metrics (e.g., subspace dimensionality, variance explained, or statistical comparison of embedding spreads) or controls for reconstruction length are provided to link the geometric observation directly to the faithfulness drop.
Authors: We accept that the geometric analysis would be strengthened by quantitative metrics. In the revised manuscript we will add: (i) effective dimensionality of the compressed embeddings measured via PCA variance explained by the top principal components, (ii) statistical comparisons (e.g., Levene’s test) of embedding spread and norm variance across model sizes, and (iii) explicit controls for reconstruction length by either length-normalizing the embeddings or restricting analysis to fixed-length compressed outputs. These additions will directly quantify the link between broader subspaces and the observed drop in faithfulness. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper reports experimental results across 27 compressor setups and interprets observed patterns (lower faithfulness despite reduced reconstruction error) as a Size-Fidelity Paradox driven by overwriting and drift. No mathematical derivation, fitted parameter, or prediction is claimed that reduces by construction to its own inputs. Embedding-geometry analysis is descriptive of the measured representations rather than a self-referential proof. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz that forces the central claim. The work is self-contained as an empirical observation and does not rely on circular reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SAGE: Selective Attention-Guided Extraction for Token-Efficient Document Indexing
SAGE is a training-free context reduction method that converts attention signals from a small LLM into a differential relevance heatmap to select top units for downstream QA, achieving competitive accuracy at 10% toke...
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Com- pllm: Compression for long context q&a.arXiv preprint arXiv:2509.19228,
Berton, G., Unnikrishnan, J., Tran, S., and Shah, M. Com- pllm: Compression for long context q&a.arXiv preprint arXiv:2509.19228,
-
[3]
Ge, T., Hu, J., Wang, L., Wang, X., Chen, S.-Q., and Wei, F. In-context autoencoder for context compression in a large language model.arXiv preprint arXiv:2307.06945,
-
[4]
Godey, N., de la Clergerie, ´E., and Sagot, B. Why do small language models underperform? studying lan- guage model saturation via the softmax bottleneck.arXiv preprint arXiv:2404.07647,
-
[5]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[9]
Li, C., Liu, X., Zhang, Z., Zhang, S., Liu, S., Ma, G., Lan, Y ., and Shen, C. Upfront chain-of-thought: A coopera- tive framework for chain-of-thought compression.arXiv preprint arXiv:2510.08647, 2025a. Li, Y ., Dong, B., Guerin, F., and Lin, C. Compressing context to enhance inference efficiency of large language models. InProceedings of the 2023 confer...
-
[10]
Prompt compression for large language models: A survey
Li, Z., Liu, Y ., Su, Y ., and Collier, N. Prompt compression for large language models: A survey. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 7182–7195, 2025b. Li, Z., Su, Y ., and Collier, N. 500xcompressor: Generali...
work page 2025
- [11]
-
[12]
Copy-paste to mitigate large language model halluci- nations.arXiv preprint arXiv:2510.00508,
Long, Y ., Wu, X., Zhang, Y ., Wen, X., Zhou, Y ., and Hong, S. Copy-paste to mitigate large language model halluci- nations.arXiv preprint arXiv:2510.00508,
-
[13]
Entity-based knowledge conflicts in question answering.arXiv preprint arXiv:2109.05052,
Longpre, S., Perisetla, K., Chen, A., Ramesh, N., DuBois, C., and Singh, S. Entity-based knowledge conflicts in question answering.arXiv preprint arXiv:2109.05052,
-
[14]
Ming, Y ., Purushwalkam, S., Pandit, S., Ke, Z., Nguyen, X.- P., Xiong, C., and Joty, S. Faitheval: Can your language model stay faithful to context, even if” the moon is made of marshmallows”.arXiv preprint arXiv:2410.03727,
-
[15]
Sengupta, A., Goel, Y ., and Chakraborty, T. How to upscale neural networks with scaling law? a survey and practical guidelines.arXiv preprint arXiv:2502.12051,
-
[16]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Inverse scaling can become u-shaped
Wei, J., Kim, N., Tay, Y ., and Le, Q. Inverse scaling can become u-shaped. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 15580–15591,
work page 2023
-
[18]
Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545,
Zhang, B., Luo, L., Chen, Y ., Nie, J., Liu, X., Guo, D., Zhao, Y ., Li, S., Hao, Y ., Yao, Y ., et al. Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.