Recognition: unknown
SAGE: Selective Attention-Guided Extraction for Token-Efficient Document Indexing
Pith reviewed 2026-05-10 08:28 UTC · model grok-4.3
The pith
SAGE extracts only the most relevant 10% of long documents using attention from a lightweight model, allowing accurate question answering with far fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
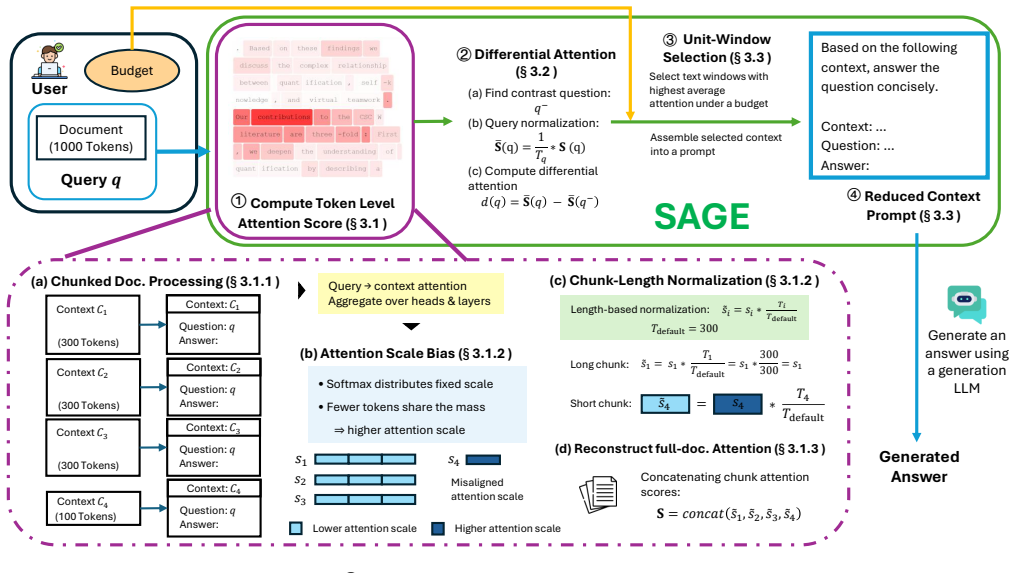
SAGE performs a single prefilling pass with a lightweight LLM to generate a query-specific relevance heatmap from attention signals, applies differential attention strategies to isolate relevant evidence, selects the top-scoring document units within a user-defined token budget, and passes only this reduced context to a downstream LLM for answer generation, achieving competitive performance on long-document QA benchmarks at 10% context budget.
What carries the argument
The relevance heatmap derived from differential attention signals in a lightweight LLM's prefilling pass, which scores document units for question relevance to enable selective extraction.
If this is right
- Users can reduce token usage by 90% for long document question answering tasks.
- Performance remains competitive on benchmarks like QuALITY-hard without fine-tuning.
- The method works plug-and-play across varied document structures and question types.
- No complex calibration or task-specific tuning of retrievers is required.
Where Pith is reading between the lines
- Combining SAGE with other efficiency techniques could further optimize costs in production LLM systems.
- This approach might lower risks of data leakage by not exposing full documents to the main model.
- Testing on documents with different languages or formats could reveal broader applicability beyond English technical texts.
Load-bearing premise
Attention signals from a lightweight local LLM can reliably isolate question-relevant evidence that transfers to a different downstream LLM without task-specific tuning.
What would settle it
Running SAGE on a new long-document QA dataset where the 10% selected context leads to answers much worse than using the full document or a tuned RAG system would falsify the central claim.
Figures






read the original abstract
Large language models with long context windows can answer complex questions directly from full-length academic, technical, and policy documents, but passing entire documents is often costly, slow, and can degrade answer quality while increasing the risk of unnecessary data leakage. This paper targets the common setting of answering many heterogeneous questions over long document(s), where fixed position heuristics and standard retrieval-augmented generation (RAG) can fail due to document structure variability and weak query-chunk semantic similarity, which often requires task- and domain-specific tuning of embedding retrievers. We propose {Selective Attention-Guided Extraction} (\ourmethod), a training-free, plug-and-play context reduction framework that uses a lightweight local LLM to perform a single prefilling pass and convert language model attention signals into a query-specific relevance heatmap at configurable granularities. \ourmethod\ further introduces \emph{differential attention} strategies to better isolate question-relevant evidence, then selects the top-scoring units under a user-defined token budget and forwards only this reduced context to a downstream LLM for answer generation. \ourmethod\ surpasses traditional reduction techniques across multiple long-document QA benchmarks, notably securing a top-4 rank on QuALITY-hard while constrained to a 10\% context budget. This enables a 90\% reduction in tokens with competitive accuracy, without the need for model fine-tuning or complex calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAGE, a training-free, plug-and-play context reduction framework for long-document question answering. It performs a single prefilling pass with a lightweight local LLM to convert attention signals into a query-specific relevance heatmap at configurable granularities, applies differential attention strategies to isolate relevant evidence, selects the top-scoring units under a user-specified token budget, and forwards only the reduced context to a downstream LLM for answer generation. The central empirical claim is that SAGE surpasses traditional reduction techniques on multiple long-document QA benchmarks, including a top-4 rank on QuALITY-hard at a 10% context budget (90% token reduction) with competitive accuracy and no fine-tuning or calibration required.
Significance. If the reported benchmark results hold under rigorous controls, the work offers a practical, training-free alternative to RAG and position-based heuristics for token-efficient long-context inference. The use of off-the-shelf attention signals for query-specific extraction without task-specific tuning or embedding retriever calibration is a notable strength, as is the emphasis on heterogeneous documents where semantic similarity often fails. Reproducible attention-to-heatmap pipelines of this form could influence efficient deployment of LLMs on academic, technical, and policy corpora.
major comments (2)
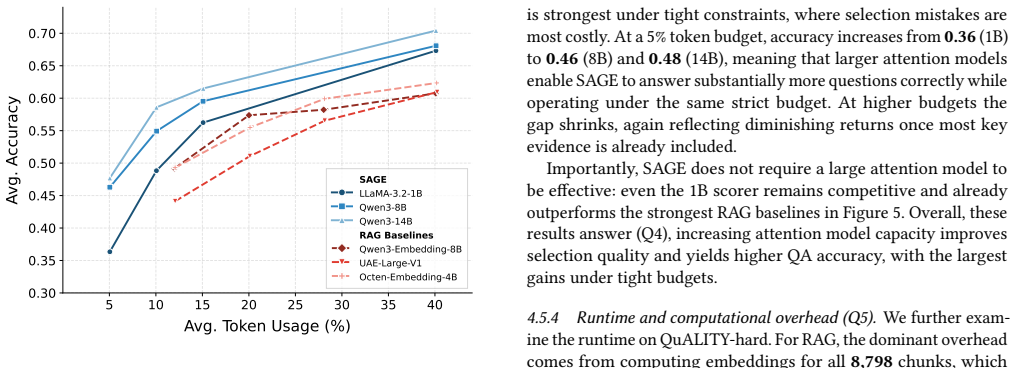
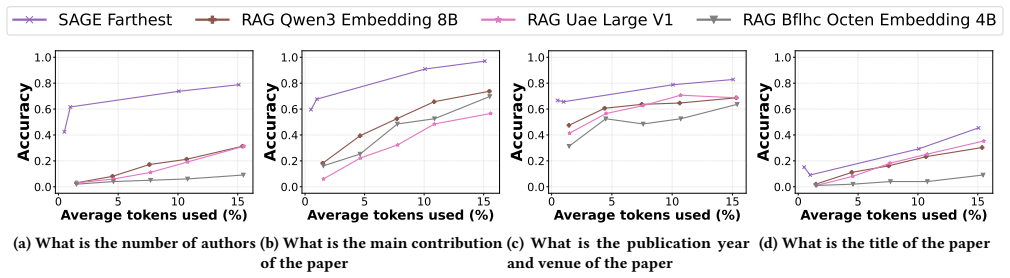
- [§4] §4 (Experiments), Table 3 or equivalent results table: the top-4 ranking on QuALITY-hard at 10% budget is a load-bearing claim, yet the manuscript does not appear to report the precise ranking metric (e.g., exact-match F1, ROUGE, or human preference), the full list of competing methods, or variance across random seeds; without these, it is impossible to verify whether the result is robust or sensitive to baseline selection.
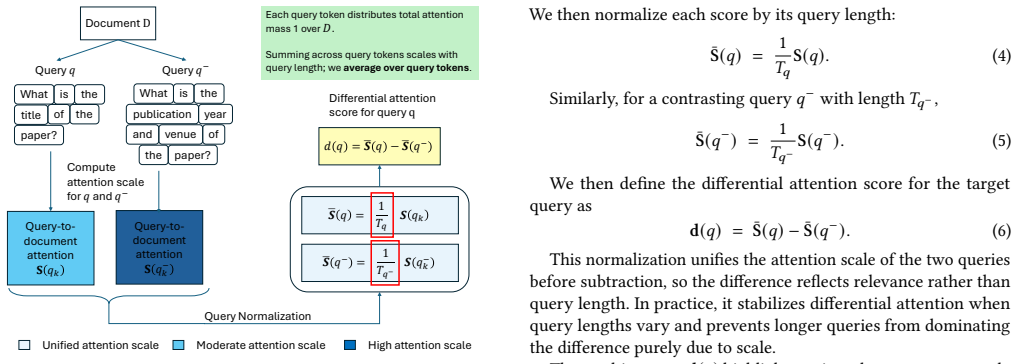
- [§3.2] §3.2 (Differential Attention): the transferability assumption—that attention heatmaps from the lightweight local LLM reliably identify evidence for a different downstream LLM across document structures—is central to the plug-and-play claim, but no ablation is described that isolates the effect of model mismatch (same vs. different model pairs) or document-type variability; this leaves the weakest assumption untested in the reported experiments.
minor comments (2)
- [Abstract] Abstract: the phrase 'top-4 rank' is used without defining the evaluation metric or the size of the comparison pool, which reduces clarity for readers unfamiliar with the QuALITY leaderboard.
- [§3.1] §3.1: the description of 'configurable granularities' for the relevance heatmap would benefit from an explicit example (e.g., token vs. sentence vs. paragraph units) and a short pseudocode snippet to make the pipeline reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments), Table 3 or equivalent results table: the top-4 ranking on QuALITY-hard at 10% budget is a load-bearing claim, yet the manuscript does not appear to report the precise ranking metric (e.g., exact-match F1, ROUGE, or human preference), the full list of competing methods, or variance across random seeds; without these, it is impossible to verify whether the result is robust or sensitive to baseline selection.
Authors: We appreciate this clarification request. The QuALITY-hard benchmark uses accuracy as the standard evaluation metric for its multiple-choice questions, and the reported top-4 ranking is based on this metric at the 10% token budget. We will revise the manuscript to explicitly state the metric in the table caption and surrounding text. We will also expand the table to list all competing methods and their scores for full transparency. As SAGE is a deterministic, training-free approach with no learned parameters or random seeds in the selection process, variance across seeds does not apply; we will add a note to this effect. These changes will allow direct verification of the claim. revision: yes
-
Referee: [§3.2] §3.2 (Differential Attention): the transferability assumption—that attention heatmaps from the lightweight local LLM reliably identify evidence for a different downstream LLM across document structures—is central to the plug-and-play claim, but no ablation is described that isolates the effect of model mismatch (same vs. different model pairs) or document-type variability; this leaves the weakest assumption untested in the reported experiments.
Authors: We agree that an explicit test of the transferability assumption would strengthen the plug-and-play claims. Our experiments already pair a lightweight local LLM for attention extraction with larger, architecturally distinct downstream LLMs and evaluate across heterogeneous document types in multiple benchmarks. However, we did not include a dedicated ablation varying model pairs (matched vs. mismatched) or isolating document-type effects. In the revision, we will add a new ablation analysis comparing performance under same-model and cross-model configurations, along with breakdowns by document category where available in the benchmarks. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains. The method is described as a training-free procedural pipeline that converts attention signals into a relevance heatmap and selects units under a token budget. No load-bearing step reduces by construction to its own inputs, and results are reported via external benchmarks rather than internal self-referential logic. This is the expected outcome for a purely empirical, non-derivational systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Yilong Chen, Guoxia Wang, Junyuan Shang, Shiyao Cui, Zhenyu Zhang, Tingwen Liu, Shuohuan Wang, Yu Sun, Dianhai Yu, and Hua Wu. 2024. Nacl: A general and effective kv cache eviction framework for llm at inference time. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7913–7926
2024
-
[4]
Xin Cheng, Xun Wang, Xingxing Zhang, Tao Ge, Si-Qing Chen, Furu Wei, Huishuai Zhang, and Dongyan Zhao. 2024. xrag: Extreme context compres- sion for retrieval-augmented generation with one token.Advances in Neural Information Processing Systems37 (2024), 109487–109516
2024
-
[5]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao
-
[6]
Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801(2023)
- [7]
- [8]
-
[9]
Saurabh Goyal, Anamitra Roy Choudhury, Saurabh Raje, Venkatesan Chakar- avarthy, Yogish Sabharwal, and Ashish Verma. 2020. Power-bert: Accelerating bert inference via progressive word-vector elimination. InInternational Confer- ence on Machine Learning. PMLR, 3690–3699
2020
-
[10]
Ruishan Guo, Yibing Liu, Guoxin Ma, Yan Wang, Yueyang Zhang, Long Xia, Kecheng Chen, Zhiyuan Sun, and Daiting Shi. 2026. When Less is More: The LLM Scaling Paradox in Context Compression.arXiv preprint arXiv:2602.09789 (2026)
work page internal anchor Pith review arXiv 2026
-
[11]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 13358–13376
2023
-
[12]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1658–1677
2024
- [13]
- [14]
-
[15]
Jiajie Jin, Xiaoxi Li, Guanting Dong, Yuyao Zhang, Yutao Zhu, Yongkang Wu, Zhonghua Li, Ye Qi, and Zhicheng Dou. 2025. Hierarchical document refine- ment for long-context retrieval-augmented generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 3502–3520
2025
-
[16]
Hyukkyu Kang, Injung Kim, and Wook-Shin Han. 2025. TRIAL: Token Relations and Importance Aware Late-interaction for Accurate Text Retrieval. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing. 16875–16888
2025
-
[17]
Yannis Katsis, Saneem Chemmengath, Vishwajeet Kumar, Samarth Bharadwaj, Mustafa Canim, Michael Glass, Alfio Gliozzo, Feifei Pan, Jaydeep Sen, Karthik Sankaranarayanan, et al. 2022. Ait-qa: Question answering dataset over com- plex tables in the airline industry. InProceedings of the 2022 Conference of the North American Chapter of the Association for Comp...
2022
-
[18]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
-
[19]
Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, and Kurt Keutzer. 2022. Learned token pruning for transformers. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 784–794
2022
-
[20]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers). 12286–12312
2023
-
[21]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Informa- tion Processing Systems37 (2024), 22947–22970
2024
-
[22]
Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier. 2025. Prompt compres- sion for large language models: A survey. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers). 7182–7195
2025
- [23]
-
[24]
Yiming Lin, Madelon Hulsebos, Ruiying Ma, Shreya Shankar, Sepanta Zeighami, Aditya G Parameswaran, and Eugene Wu. 2025. Querying templatized document collections with large language models. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2422–2435
2025
-
[25]
Barys Liskavets, Maxim Ushakov, Shuvendu Roy, Mark Klibanov, Ali Etemad, and Shane K Luke. 2025. Prompt compression with context-aware sentence encoding for fast and improved llm inference. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 24595–24604
2025
-
[26]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. [n.d.]. Palimpzest: Optimizing ai-powered analytics with declarative query processing
- [27]
-
[28]
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Haoran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, et al. [n.d.]. A com- prehensive survey on long context language modeling. 2025.URL https://api. semanticscholar. org/CorpusID277271533 ([n. d.])
2025
-
[29]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
-
[30]
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. 2024. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems37 (2024), 95963–96010
2024
-
[31]
mteb. [n.d.]. MTEB leaderboard - a hugging face space by mteb. https:// huggingface.co/spaces/mteb/leaderboard
-
[32]
Jesse Mu, Xiang Li, and Noah Goodman. 2024. Learning to compress prompts with gist tokens.Advances in Neural Information Processing Systems36 (2024)
2024
-
[33]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2014–2037
2023
-
[34]
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. 2024. Optimizing instructions and demonstrations for multi-stage language model programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 9340–9366
2024
-
[35]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel Bowman. [n.d.]. QuALITY Leaderboard — nyu-mll.github.io. https://nyu- mll.github.io/quality/. [Accessed 01-03-2026]
2026
-
[36]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel Bowman. 2022. QuALITY: Question Answering with Long Input Texts, Yes!. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lang...
2022
-
[37]
Badri Patro and Vinay P Namboodiri. 2018. Differential attention for visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition. 7680–7688
2018
-
[38]
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. 2024. Streaming long video understanding with large language models.Advances in Neural Information Processing Systems37 (2024), 119336– 119360
2024
-
[39]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. Colbertv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 3715–3734
2022
-
[40]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations. 13
2024
-
[41]
Kele Shao, TAO Keda, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. [n.d.]. A Survey of Token Compression for Efficient Multimodal Large Language Models.Transactions on Machine Learning Research([n. d.])
-
[42]
Hanrui Wang, Zhekai Zhang, and Song Han. 2021. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In2021 IEEE inter- national symposium on high-performance computer architecture (HPCA). IEEE, 97–110
2021
-
[43]
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang
-
[44]
In European Conference on Computer Vision
Longvlm: Efficient long video understanding via large language models. In European Conference on Computer Vision. Springer, 453–470
-
[45]
David Wingate, Mohammad Shoeybi, and Taylor Sorensen. 2022. Prompt com- pression and contrastive conditioning for controllability and toxicity reduction in language models. InFindings of the Association for Computational Linguistics: EMNLP 2022. 5621–5634
2022
- [46]
- [47]
-
[48]
Deming Ye, Yankai Lin, Yufei Huang, and Maosong Sun. 2021. Tr-bert: Dy- namic token reduction for accelerating bert inference. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 5798–5809
2021
-
[49]
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei
- [50]
- [51]
-
[52]
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. 2024. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852(2024)
work page internal anchor Pith review arXiv 2024
-
[53]
Zhenyu Zhang, Runjin Chen, Shiwei Liu, Zhewei Yao, Olatunji Ruwase, Beidi Chen, Xiaoxia Wu, and Zhangyang Wang. 2024. Found in the middle: How language models use long contexts better via plug-and-play positional encoding. Advances in Neural Information Processing Systems37 (2024), 60755–60775
2024
-
[54]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2024. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36 (2024)
2024
- [55]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.