Recognition: no theorem link
Configuring Agentic AI Coding Tools: An Exploratory Study
Pith reviewed 2026-05-15 22:05 UTC · model grok-4.3
The pith
Context files dominate how developers configure agentic AI coding tools, with AGENTS.md emerging as an interoperable standard.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
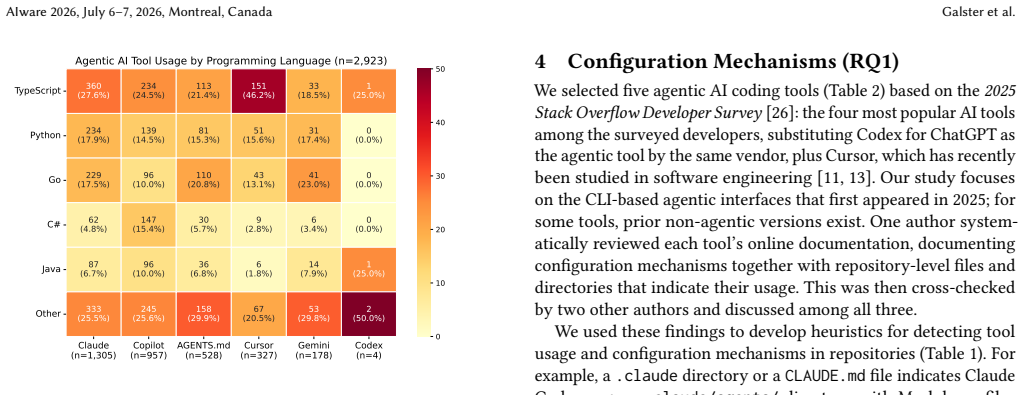
In an empirical study of 2,853 GitHub repositories, context files dominate the configuration landscape for agentic AI coding tools and are often the sole mechanism, with AGENTS.md emerging as an interoperable standard across tools. Few repositories adopt advanced mechanisms such as skills and subagents. Skills predominantly rely on static instructions rather than executable scripts. Distinct configuration practices are forming around different tools, with Claude Code users employing the broadest range of mechanisms.
What carries the argument
Context Files, including the AGENTS.md format, as the primary repository-level artifacts that supply instructions and context to agentic AI coding tools.
Load-bearing premise
The 2,853 GitHub repositories examined are representative of how developers typically configure these tools and that the eight identified mechanisms cover the main approaches in use.
What would settle it
A broader sample or developer survey revealing that most configuration happens through mechanisms outside the eight identified ones or that skills and subagents are adopted at high rates in typical projects.
Figures




read the original abstract
Agentic AI coding tools increasingly automate software development tasks. Developers can configure these tools through versioned repository-level artifacts such as Markdown and JSON files. We present a systematic analysis of configuration mechanisms for agentic AI coding tools, covering Claude Code, GitHub Copilot, Cursor, Gemini, and Codex. We identify eight configuration mechanisms spanning from static context to executable and external integrations and, in an empirical study of 2,853 GitHub repositories, examine whether and how they are adopted, with a detailed analysis of Context Files, Skills, and Subagents. First, Context Files dominate the configuration landscape and are often the sole mechanism in a repository, with AGENTS$.$md emerging as an interoperable standard across tools. Second, few repositories adopt advanced mechanisms such as Skills and Subagents. Skills predominantly rely on static instructions rather than executable scripts. Third, distinct configuration practices are forming around different tools, with Claude Code users employing the broadest range of mechanisms. These findings establish an empirical baseline for understanding how developers configure agentic tools, suggest that AGENTS$.$md serves as a natural starting point, and motivate longitudinal and experimental research on how configuration strategies evolve and affect agent performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies eight configuration mechanisms for agentic AI coding tools (Claude Code, GitHub Copilot, Cursor, Gemini, Codex) spanning static context to executable integrations. In an empirical study of 2,853 GitHub repositories, it reports that Context Files dominate and are often the sole mechanism, with AGENTS.md emerging as an interoperable standard; few repositories adopt advanced mechanisms such as Skills and Subagents (which mostly use static instructions); and distinct tool-specific practices exist, with Claude Code users employing the broadest range. The work positions these findings as an empirical baseline motivating further longitudinal and experimental research.
Significance. If the sampling and classification are shown to be unbiased and representative, the study supplies a useful snapshot of current developer practices in configuring agentic coding tools. It usefully flags AGENTS.md as a potential de-facto standard and identifies under-adoption of more sophisticated mechanisms, thereby providing a concrete starting point for research on how configuration choices affect agent performance and for tool designers seeking interoperability.
major comments (3)
- [Empirical study section] The description of how the 2,853 repositories were identified and sampled (search terms, inclusion/exclusion criteria, GitHub API or search filters) is absent or insufficiently detailed. This is load-bearing because the central claim that Context Files dominate and are often the sole mechanism could be an artifact of conditioning the corpus on the presence of the very filenames being measured.
- [Methods / Identification of mechanisms] No details are supplied on how the eight mechanisms were systematically identified, how repositories were classified into mechanisms, inter-rater reliability, or any validation of the classification scheme. Without these, the reported adoption rates and the distinction between static vs. executable Skills cannot be assessed for reliability.
- [Results on Context Files and adoption patterns] The quantitative statements about dominance (e.g., Context Files as sole mechanism in many repositories) lack accompanying counts, percentages, or breakdowns by tool that would allow readers to judge effect sizes and to verify that the patterns survive controls for sampling bias.
minor comments (2)
- [Abstract] The abstract contains the typographical artifact 'AGENTS$.$md'; this should be rendered as AGENTS.md.
- [Throughout] Mechanism names and tool names should be defined once with a table or glossary and then used consistently; several passages introduce slight variations in terminology that could confuse readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional methodological transparency will strengthen the paper. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: The description of how the 2,853 repositories were identified and sampled (search terms, inclusion/exclusion criteria, GitHub API or search filters) is absent or insufficiently detailed. This is load-bearing because the central claim that Context Files dominate and are often the sole mechanism could be an artifact of conditioning the corpus on the presence of the very filenames being measured.
Authors: We agree that the sampling procedure must be described in full detail. The 2,853 repositories were obtained via the GitHub Search API using queries for the presence of specific filenames (e.g., filename:AGENTS.md, filename:.cursorrules, filename:AGENT.md and equivalents for the other tools), restricted to public, non-forked repositories with at least one commit in the prior 12 months. Inclusion required at least one matching configuration file; we excluded archived repositories and those whose primary language was not a programming language. We will add a dedicated subsection to the Empirical Study section that lists the exact search strings, API parameters, total hits before filtering, deduplication steps, and inclusion/exclusion criteria. We will also explicitly discuss the sampling bias the referee correctly identifies as a limitation and note that our prevalence figures are conditional on the presence of at least one configuration artifact. revision: yes
-
Referee: No details are supplied on how the eight mechanisms were systematically identified, how repositories were classified into mechanisms, inter-rater reliability, or any validation of the classification scheme. Without these, the reported adoption rates and the distinction between static vs. executable Skills cannot be assessed for reliability.
Authors: The eight mechanisms were first enumerated by systematically reviewing the official documentation and configuration examples published by each tool vendor, followed by an exploratory scan of 50 high-star repositories to confirm the mechanisms in practice. Repository classification combined automated filename and content heuristics with manual review: two authors independently coded a stratified random sample of 200 repositories, reaching 91% raw agreement (Cohen’s κ = 0.87). Disagreements were resolved by joint discussion and the final coding rules were documented. For Skills we distinguished static instruction files from executable scripts by inspecting file extensions and content (presence of shebang lines or code blocks). We will insert a new Methods subsection that fully documents the identification process, the coding protocol, the inter-rater statistics, and the precise criteria used to separate static versus executable Skills. revision: yes
-
Referee: The quantitative statements about dominance (e.g., Context Files as sole mechanism in many repositories) lack accompanying counts, percentages, or breakdowns by tool that would allow readers to judge effect sizes and to verify that the patterns survive controls for sampling bias.
Authors: We will augment the Results section with a new table (and accompanying text) that reports exact counts and percentages for every mechanism, the proportion of repositories in which Context Files are the sole mechanism, and tool-specific breakdowns (e.g., percentage of Claude Code repositories using only Context Files versus those using additional mechanisms). We will also add a short discussion of how the observed patterns relate to the sampling frame. These additions will supply the numerical detail needed to assess effect sizes and will be accompanied by a limitations paragraph addressing sampling bias. revision: yes
Circularity Check
No circularity: purely observational empirical study with direct counts from repository data
full rationale
The paper performs an exploratory analysis by identifying eight configuration mechanisms and reporting their adoption frequencies across 2,853 GitHub repositories. All claims (e.g., dominance of Context Files, emergence of AGENTS.md) are direct empirical observations and qualitative summaries of the sampled artifacts. No equations, derivations, fitted parameters, or predictions exist that could reduce to inputs by construction. No self-citations serve as load-bearing uniqueness theorems or ansatzes. The analysis is self-contained against external benchmarks of repository inspection and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sampled GitHub repositories reflect typical usage patterns of agentic AI coding tools
Forward citations
Cited by 3 Pith papers
-
A Dataset of Agentic AI Coding Tool Configurations
A publicly released dataset of 15,591 configuration artifacts for five agentic AI coding tools, drawn from 4,738 GitHub repositories along with associated files and AI-co-authored commits.
-
Inside the Scaffold: A Source-Code Taxonomy of Coding Agent Architectures
Analysis of 13 coding agent scaffolds at pinned commits yields a 12-dimension taxonomy showing five composable loop primitives, with 11 agents combining multiple primitives instead of using one fixed structure.
-
Beyond Human-Readable: Rethinking Software Engineering Conventions for the Agentic Development Era
Optimizing code for semantic density rather than human readability can improve agentic AI development efficiency, but aggressive compression of logs increased overall costs by shifting burden to reasoning.
Reference graph
Works this paper leans on
-
[1]
agentskills.io. 2026. Agent Skills. https://agentskills.io/
work page 2026
-
[2]
agentsmd community. 2025. AGENTS.md: A Simple, Open Format for Guiding Coding Agents. Website. https://agents.md/ Accessed 2026-01-18
work page 2025
-
[3]
Anthropic. 2025. Claude 3.7 Sonnet and Claude Code. https://www.anthropic. com/news/claude-3-7-sonnet
work page 2025
-
[4]
Anthropic. 2026. Create custom subagents. https://code.claude.com/docs/en/sub- agents
work page 2026
-
[5]
anthropics/claude-code on GitHub. 2026. Feature Request: Support AGENTS.md. https://github.com/anthropics/claude-code/issues/6235
work page 2026
-
[6]
Worawalan Chatlatanagulchai, Hao Li, Yutaro Kashiwa, Brittany Reid, Kundjana- sith Thonglek, Pattara Leelaprute, Arnon Rungsawang, Bundit Manaskasemsak, Bram Adams, Ahmed E. Hassan, and Hajimu Iida. 2025. Agent READMEs: An Empirical Study of Context Files for Agentic Coding. arXiv:2511.12884 [cs.SE] doi:10.48550/arXiv.2511.12884
-
[7]
Cursor. 2026. Subagents. https://cursor.com/docs/context/subagents
work page 2026
-
[8]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling Projects in GitHub for MSR Studies. In18th IEEE/ACM International Conference on Mining Software Repositories, MSR 2021, Madrid, Spain, May 17-19, 2021. IEEE, Madrid, Spain, 560–564. doi:10.1109/MSR52588.2021.00074
-
[9]
DAIR.AI Prompt Engineering Guide. 2025. Elements of a Prompt | Prompt Engineering Guide. https://www.promptingguide.ai/introduction/elements
work page 2025
-
[10]
A collection of fully-annotated soundscape recordings from the western united states,
Matthias Galster, Seyedmoein Mohsenimofidi, Jai Lal Lulla, Muhammad Auwal Abubakar, Christoph Treude, and Sebastian Baltes. 2026.Configuring Agentic AI Coding Tools: An Exploratory Study (Supplementary Material). doi:10.5281/zenodo. 18625980
-
[11]
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. 2025. Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. arXiv:2511.04427 [cs.SE] doi:10.48550/arXiv.2511.04427 To appear at the 23rd IEEE/ACM International Conference on Mining Software Repositories (MS...
-
[12]
Dexter Horthy. 2025. Getting AI to Work in Complex Codebases. https://github.com/humanlayer/advanced-context-engineering-for-coding- agents/blob/main/ace-fca.md
work page 2025
-
[13]
Shaokang Jiang and Daye Nam. 2025. Beyond the Prompt: An Empirical Study of Cursor Rules. arXiv:2512.18925 [cs.SE] doi:10.48550/arXiv.2512.18925 To appear at the 23rd IEEE/ACM International Conference on Mining Software Repositories (MSR 2026), Rio de Janeiro, Brazil
-
[14]
Jai Lal Lulla, Seyedmoein Mohsenimofidi, Matthias Galster, Jie M. Zhang, Sebas- tian Baltes, and Christoph Treude. 2026. On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents. arXiv:2601.20404 [cs.SE] doi:10.48550/arXiv. 2601.20404 To appear at the 1st Journal Ahead Workshop (JAWs@ICSE 2026)
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[15]
Damon McMillan. 2026. Structured Context Engineering for File-Native Agentic Systems: Evaluating Schema Accuracy, Format Effectiveness, and Multi-File Navigation at Scale. arXiv:2602.05447 [cs.SE] doi:10.48550/arXiv.2602.05447
-
[16]
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, Chenlin Zhou, Jiayi Mao, Tianze Xia, Jiafeng Guo, and Shenghua Liu. 2025. A Survey of Context Engineering for Large Language Models. arXiv:2507.13334 [cs.CL] doi:10.48550/arXiv.2507.13334
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.13334 2025
-
[17]
Seyedmoein Mohsenimofidi, Matthias Galster, Christoph Treude, and Sebastian Baltes. 2025. Context Engineering for AI Agents in Open-Source Software. arXiv:2510.21413 [cs.SE] doi:10.48550/arXiv.2510.21413 To appear at the 23rd IEEE/ACM International Conference on Mining Software Repositories (MSR 2026), Rio de Janeiro, Brazil
-
[18]
Nuthan Munaiah, Steven Kroh, Craig Cabrey, and Meiyappan Nagappan. 2017. Curating GitHub for engineered software projects.Empir. Softw. Eng.22, 6 (2017), 3219–3253. doi:10.1007/S10664-017-9512-6
-
[19]
OpenAI. 2025. Introducing Codex. https://openai.com/index/introducing-codex/
work page 2025
-
[20]
Per Runeson and Martin Höst. 2009. Guidelines for conducting and reporting case study research in software engineering.Empir. Softw. Eng.14, 2 (2009), 131–164. doi:10.1007/S10664-008-9102-8
-
[21]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv:2402.07927 [cs.AI] doi:10. 48550/arXiv.2402.07927
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Santos, Vitor Costa, João Eduardo Montandon, and Marco Túlio Valente
Helio Victor F. Santos, Vitor Costa, João Eduardo Montandon, and Marco Túlio Valente. 2025. Decoding the Configuration of AI Coding Agents: Insights from Claude Code Projects. arXiv:2511.09268 [cs.SE] doi:10.48550/arXiv.2511.09268
-
[23]
Philipp Schmid. 2025. The New Skill in AI is Not Prompting, It’s Context Engi- neering. https://www.philschmid.de/context-engineering
work page 2025
-
[24]
SEART. 2025. GitHub Search. https://seart-ghs.si.usi.ch/
work page 2025
- [25]
-
[26]
Stack Exchange Inc. 2026. Stack Overflow Developer Survey 2025: AI Agent out-of-the-box tools. https://survey.stackoverflow.co/2025/ai/#3-ai-agent-out- of-the-box-tools
work page 2026
-
[27]
Valerio Terragni, Annie Vella, Partha Roop, and Kelly Blincoe. 2025. The Future of AI-Driven Software Engineering.ACM Trans. Softw. Eng. Methodol.34, 5, Article 120 (May 2025), 20 pages. doi:10.1145/3715003
-
[28]
Hugo Villamizar, Jannik Fischbach, Alexander Korn, Andreas Vogelsang, and Daniel Méndez. 2025. Prompts as Software Engineering Artifacts: A Research Agenda and Preliminary Findings. InProduct-Focused Software Process Improve- ment - 26th International Conference, PROFES 2025, Salerno, Italy, December 1-3, 2025, Proceedings (Lecture Notes in Computer Scien...
-
[29]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Sys- tems 2024, NeurIPS 2024, Vancouver, BC, Canada, De...
-
[30]
Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. 2026. Meta Context Engineering via Agentic Skill Evolution. arXiv:2601.21557 [cs.AI] doi:10.48550/arXiv.2601.21557
-
[31]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. 2025. Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models. arXiv:2510.04618 [cs.CL] doi:10.48550/arXiv.2510.04618
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04618 2025
-
[32]
Yifan Zhang, Yang Yuan, Mengdi Wang, and Andrew Chi-Chih Yao. 2025. Monadic Context Engineering. arXiv:2512.22431 [cs.AI] doi:10.48550/arXiv.2512.22431
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.