Recognition: no theorem link
Learning State-Tracking from Code Using Linear RNNs
Pith reviewed 2026-05-15 21:43 UTC · model grok-4.3
The pith
Linear RNNs track states from code traces of permutation compositions where Transformers fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing permutation composition as REPL traces that interleave state-revealing prints with variable transformations, linear RNNs succeed at learning the required state transitions under next-token prediction. Transformers do not. The paper frames general state-tracking difficulty in code as following a probabilistic finite-state automaton with deterministic reveals, where linear RNNs can underperform non-linear RNNs due to partial observability of actions.
What carries the argument
REPL traces converting permutation actions into code sequences with interleaved deterministic state reveals and partial action observability.
Load-bearing premise
Converting permutation composition to REPL traces preserves the core state-tracking difficulty without introducing artifacts that favor linear RNNs over Transformers.
What would settle it
A new set of REPL traces on which a Transformer model achieves high accuracy at predicting the final revealed state and intermediate tokens would show the claimed failure is not general.
Figures










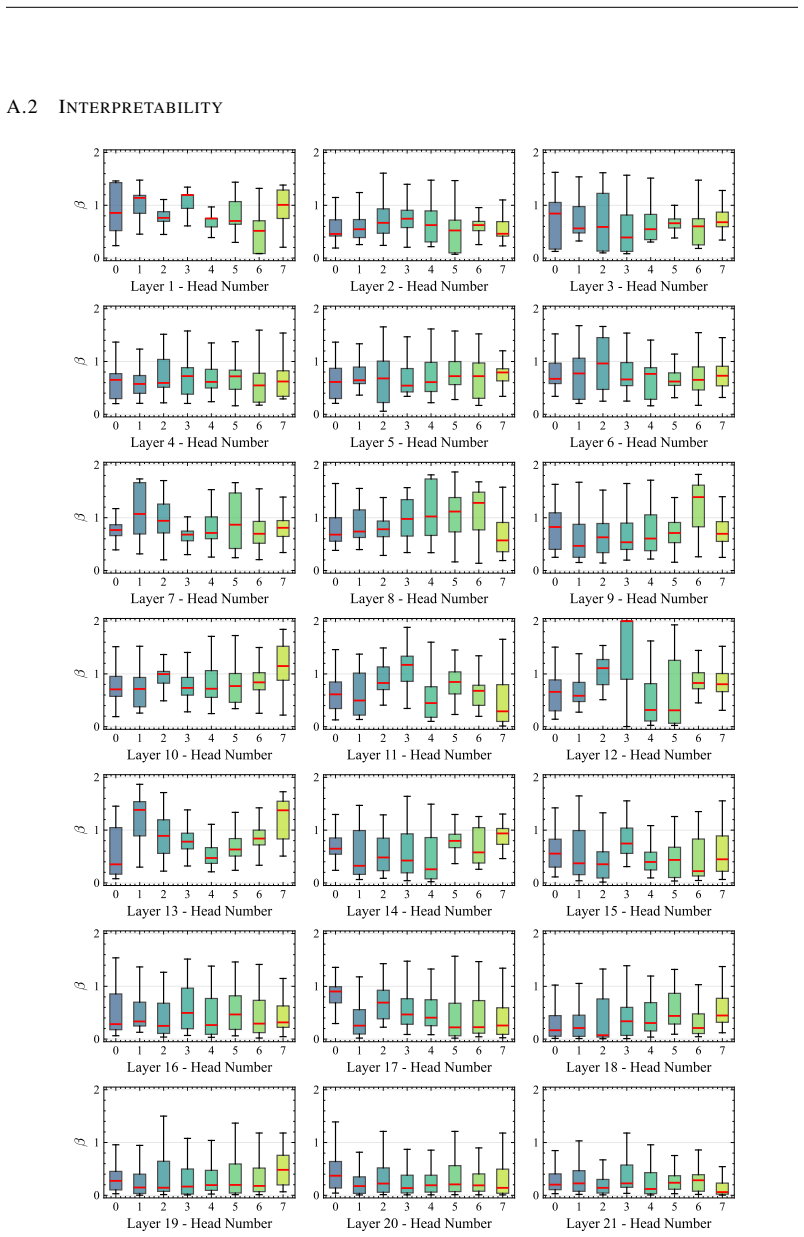
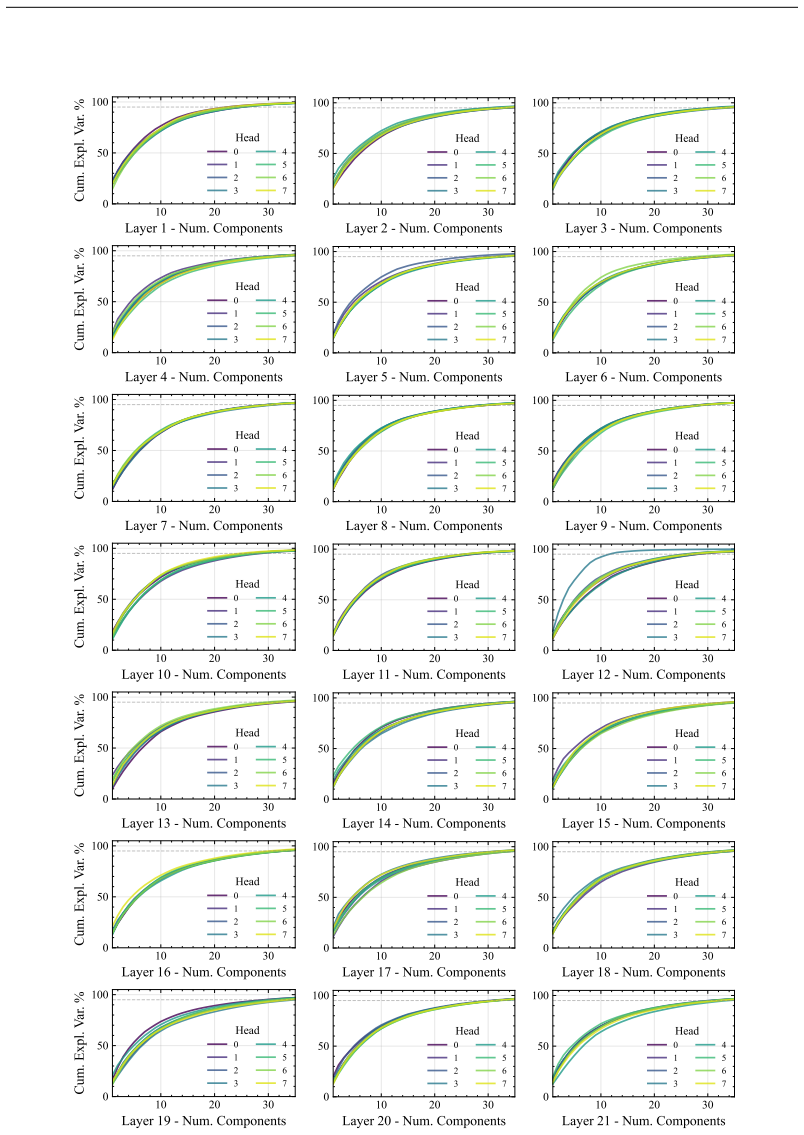
read the original abstract
Over the last years, state-tracking tasks, particularly permutation composition, have become a testbed to understand the limits of sequence models architectures like Transformers and RNNs (linear and non-linear). However, these are often sequence-to-sequence tasks: learning to map actions (permutations) to states, which is incompatible with the next-token prediction setting commonly used to train language models. We address this gap by converting permutation composition into code via REPL traces that interleave state-reveals through prints and variable transformations. We show that linear RNNs capable of state-tracking excel also in this setting, while Transformers still fail. Motivated by this representation, we investigate why tracking states in code is generally difficult: actions are not always fully observable. We frame this as tracking the state of a probabilistic finite-state automaton with deterministic state reveals and show that linear RNNs can be worse than non-linear RNNs at tracking states in this setup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper converts permutation composition state-tracking into interleaved REPL traces (prints for state reveals plus variable updates) to make it compatible with next-token prediction. It reports that linear RNNs that succeed on abstract state-tracking also succeed here, while Transformers fail; a second part models the difficulty as tracking a probabilistic FSA with deterministic reveals and claims linear RNNs can be inferior to non-linear RNNs under partial observability.
Significance. If the empirical claims hold after controlling for the REPL representation, the work supplies a concrete bridge between abstract state-tracking benchmarks and code-like training regimes, and isolates observability as a variable that can reverse the usual linear-vs-nonlinear ranking. The REPL-trace construction itself is a reusable methodological contribution for future architecture comparisons.
major comments (3)
- [§3] §3 (REPL trace construction): the claim that the interleaved print-and-update format preserves the original hardness of permutation composition is load-bearing for the central comparison. The deterministic state reveals turn the task into explicit integration of fully observed updates, which linear recurrence can perform by direct matrix accumulation in the hidden state; no ablation is shown that removes the prints or replaces them with implicit state inference to test whether the advantage disappears.
- [§5.2] §5.2 and Table 3: the reported superiority of linear RNNs over Transformers on long traces lacks controls for sequence length, vocabulary size, and training compute; without these, it is impossible to separate architectural effects from optimization or data-scale differences.
- [§6.1] §6.1 (probabilistic FSA model): the transition from deterministic REPL traces to a probabilistic automaton is not accompanied by an explicit likelihood or loss derivation; it is therefore unclear whether the subsequent claim that linear RNNs are worse than non-linear RNNs follows from the model or from a particular training regime.
minor comments (2)
- [Abstract] Abstract: no numerical results, dataset sizes, or baseline names are supplied, which makes the high-level claims difficult to evaluate at first reading.
- [§2] Notation for the linear RNN update (Eq. 2) uses an ambiguous matrix symbol that is later reused for the permutation representation; a distinct symbol or explicit subscript would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of our experimental design and theoretical framing that we address below. We have prepared a revised manuscript incorporating clarifications, additional controls, and an explicit derivation as suggested.
read point-by-point responses
-
Referee: [§3] §3 (REPL trace construction): the claim that the interleaved print-and-update format preserves the original hardness of permutation composition is load-bearing for the central comparison. The deterministic state reveals turn the task into explicit integration of fully observed updates, which linear recurrence can perform by direct matrix accumulation in the hidden state; no ablation is shown that removes the prints or replaces them with implicit state inference to test whether the advantage disappears.
Authors: We agree that the presence of deterministic prints simplifies explicit state integration and that an ablation isolating implicit tracking would strengthen the claim. The REPL format was chosen specifically to remain compatible with standard next-token prediction on code-like sequences, where prints are a natural part of execution traces. In the revision we add an ablation that removes the print statements (forcing the model to predict updates without explicit reveals) and report that linear RNNs retain their advantage over Transformers on these implicit traces, although absolute performance drops for all models. This supports that the architectural difference persists beyond explicit accumulation. revision: yes
-
Referee: [§5.2] §5.2 and Table 3: the reported superiority of linear RNNs over Transformers on long traces lacks controls for sequence length, vocabulary size, and training compute; without these, it is impossible to separate architectural effects from optimization or data-scale differences.
Authors: We matched sequence lengths exactly across architectures and used identical vocabulary sizes derived from the same code tokenizer. Training was performed with the same optimizer, learning-rate schedule, and total token budget (normalized by effective batch size). To make these controls transparent, the revision adds a dedicated paragraph in §5.2 listing the matched hyperparameters and includes a supplementary table showing performance when sequence length is varied while holding compute fixed. These additions confirm the ranking is not driven by scale differences. revision: yes
-
Referee: [§6.1] §6.1 (probabilistic FSA model): the transition from deterministic REPL traces to a probabilistic automaton is not accompanied by an explicit likelihood or loss derivation; it is therefore unclear whether the subsequent claim that linear RNNs are worse than non-linear RNNs follows from the model or from a particular training regime.
Authors: We accept that an explicit derivation is needed. The probabilistic FSA is defined with stochastic transitions and deterministic reveals; the training objective remains standard next-token cross-entropy on the generated trace. Under this loss the linear RNN's hidden-state update corresponds to a linear combination of transition matrices weighted by the current belief, which cannot represent the required nonlinear mixing of probability mass when partial observability is present. The revision inserts a short derivation subsection showing the exact likelihood expression and why the linear recurrence is provably suboptimal for the nonlinear case, while non-linear RNNs can approximate the required belief update. revision: yes
Circularity Check
No significant circularity in empirical state-tracking results
full rationale
The paper's claims rest on an empirical conversion of permutation composition into REPL traces followed by direct model training and evaluation. No equations, derivations, or self-referential definitions appear that reduce reported performance (linear RNNs succeeding where Transformers fail) to fitted inputs, self-citations, or ansatzes by construction. The REPL representation is presented as a methodological bridge to next-token prediction, and results are stated as experimental observations without load-bearing mathematical reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Olmo Hybrid: From Theory to Practice and Back
A 7B hybrid attention-recurrent model outperforms its pure-transformer counterpart on pretraining metrics and scales more efficiently, supported by a proof that hybrids are strictly more expressive than either transfo...
Reference graph
Works this paper leans on
-
[1]
Satwik Bhattamishra, Kabir Ahuja, and Navin Goyal. On the ability and limitations of transformers to recognize formal languages.arXiv preprint arXiv:2009.11264,
-
[2]
Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, David Zhang, et al. Cwm: An open-weights llm for research on code generation with world models.arXiv preprint arXiv:2510.02387,
-
[3]
Federico Danieli, Pau Rodriguez, Miguel Sarabia, Xavier Suau, and Luca Zappella. Pararnn: Unlocking parallel training of nonlinear rnns for large language models.arXiv preprint arXiv:2510.21450,
-
[4]
Neural networks and the chomsky hierarchy.arXiv preprint arXiv:2207.02098,
Gr´egoire Del´etang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, et al. Neural networks and the chomsky hierarchy.arXiv preprint arXiv:2207.02098,
-
[5]
Advancing regular language reasoning in linear recurrent neural networks
Ting-Han Fan, Ta-Chung Chi, and Alexander Rudnicky. Advancing regular language reasoning in linear recurrent neural networks. InProceedings of the 2024 Conference of the North Ameri- can Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pp. 45–53,
work page 2024
-
[6]
Tracking world states with language models: State-based evaluation using chess
Romain Harang, Jason Naradowsky, Yaswitha Gujju, and Yusuke Miyao. Tracking world states with language models: State-based evaluation using chess. InICML 2025 Workshop on Assessing World Models,
work page 2025
-
[7]
Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
-
[8]
Code execution with pre-trained language models
Chenxiao Liu, Shuai Lu, Weizhu Chen, Daxin Jiang, Alexey Svyatkovskiy, Shengyu Fu, Neel Sun- daresan, and Nan Duan. Code execution with pre-trained language models. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 4984–4999,
work page 2023
-
[9]
Parallelizing Linear Recurrent Neural Nets Over Sequence Length
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. InInterna- tional Conference on Learning Representations, 2017a. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Confer- ence on Learning Representations, 2017b. Eric Martin and Chris Cundy. Parallelizing linear recurrent neural...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A for- mal hierarchy of rnn architectures
William Merrill, Gail Weiss, Yoav Goldberg, Roy Schwartz, Noah A Smith, and Eran Yahav. A for- mal hierarchy of rnn architectures. In58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, pp. 443–459. Association for Computational Linguistics (ACL),
work page 2020
-
[11]
Rwkv-7” goose” with expressive dynamic state evolution.arXiv preprint arXiv:2503.14456,
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, et al. Rwkv-7” goose” with expressive dynamic state evolution.arXiv preprint arXiv:2503.14456,
-
[12]
doi: https://doi.org/10.1016/S0019-9958(63)90290-0
ISSN 0019-9958. doi: https://doi.org/10.1016/S0019-9958(63)90290-0. Lawrence R Rabiner. A tutorial on hidden markov models and selected applications in speech recognition.PROCEEDINGS OF THE IEEE, 77(2):257,
-
[13]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Recurrent neural language models as probabilistic finite-state au- tomata
Anej Svete and Ryan Cotterell. Recurrent neural language models as probabilistic finite-state au- tomata. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 8069–8086,
work page 2023
-
[15]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Benjamin Walker, Lingyi Yang, Nicola Muca Cirone, Cristopher Salvi, and Terry Lyons. Struc- tured linear cdes: Maximally expressive and parallel-in-time sequence models.arXiv preprint arXiv:2505.17761,
-
[17]
14 A FROMPERMUTATIONGROUPS TOVARIABLETRACKING INCODE A.1 EXPERIMENTALDETAILS Model & Training.We train a DeltaNet and Transformer (≈265M parameters) using the imple- mentation from flash-linear-attention (Yang & Zhang, 2024). The architecture consists of 18 layers, hidden dimensiond= 512, 8 heads (d head = 128), MLP expansion factor 4, and SwiGLU activa- ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.