Recognition: no theorem link
MUON+: Towards More Effective Muon via One Additional Normalization Step for LLM Pre-training
Pith reviewed 2026-05-15 19:21 UTC · model grok-4.3
The pith
Muon+ adds one normalization step after polar orthogonalization to fix norm imbalance and improve LLM pre-training over Muon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
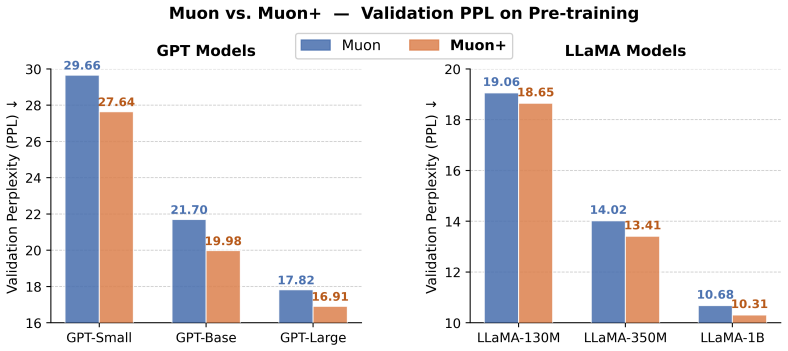
Muon suffers from a post-polar imbalanced update problem in which practical polar steps amplify norm imbalance, weakening the descent guarantee; Muon+ corrects this by adding one normalization step after orthogonalization, yielding consistent gains in perplexity and pre-training speed on models up to 7B parameters without extra state.
What carries the argument
The post-polar imbalanced update problem, where polar iterations fail to equalize column and row norms, corrected by inserting one normalization step after the Newton-Schulz orthogonalization.
Load-bearing premise
The assumption that post-polar norm imbalance is the dominant practical limitation of Muon and that the added normalization corrects it without offsetting drawbacks at other scales or regimes.
What would settle it
A head-to-head pre-training run on a 7B model where Muon+ shows no improvement in final validation perplexity or total tokens processed compared with Muon under matched hyperparameters would falsify the claim.
Figures


read the original abstract
Muon has recently emerged as a strong optimizer for large language model pre-training, orthogonalizing the momentum matrix via Newton--Schulz polar iterations. A natural intuition is that polar iterations, by flattening the singular spectrum to all ones, should also eliminate column- and row-wise norm imbalance in the update. We show that this is not true in practice: practical polar steps can substantially amplify the imbalance. We term this the post-polar imbalanced update problem, and prove that such imbalance tightens the second-order term in a blockwise descent analysis, weakening Muon's per-step descent guarantee. Motivated by this analysis, we propose Muon+, a one-line fix that inserts a single normalization step after polar orthogonalization. Muon+ adds no optimizer state. Across pre-training experiments on GPT and LLaMA models from 60M to 7B parameters, spanning both compute-optimal budgets and extended token-to-parameter ratios up to approximately 200, Muon+ consistently outperforms Muon in terms of training and validation perplexity, leading to significant overall pre-training speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a post-polar imbalanced update problem in the Muon optimizer, where practical Newton-Schulz polar iterations amplify row/column norm imbalance in the momentum matrix. It proves via blockwise descent analysis that this imbalance tightens the second-order term and weakens per-step descent guarantees. Muon+ is proposed as a one-line, state-free fix inserting a single normalization step after polar orthogonalization. Experiments on GPT and LLaMA models (60M–7B parameters) under compute-optimal and extended token budgets report consistent gains in training/validation perplexity and overall pre-training speedup.
Significance. If the central claim holds, Muon+ offers a lightweight, memory-neutral improvement to a strong recent optimizer for LLM pre-training, with potential for broad adoption across scales. The blockwise descent analysis supplies theoretical motivation distinguishing the fix from generic scaling, and the empirical scope (multiple architectures, sizes, and token-to-parameter ratios up to ~200) supports practical relevance. The work strengthens the case for orthogonalized momentum methods when the diagnosed mechanism is confirmed.
major comments (2)
- [§4] §4 (empirical results): the reported end-to-end perplexity gains do not isolate the post-polar imbalance mechanism. No direct measurements of row/column norm variance before/after the added step, no ablation replacing polar iterations with a pure scaling baseline, and no sensitivity checks on the normalization target (e.g., Frobenius vs. max-norm) are provided; thus the speedup could arise from any effective step-size change rather than the claimed tightening of the descent bound.
- [Blockwise descent analysis] Blockwise descent analysis (around Eq. (analysis of second-order term)): the proof that practical polar steps amplify imbalance and weaken the guarantee assumes specific conditions on the singular spectrum and iteration count; these must be verified against the exact Newton-Schulz implementation used in the code, including any early stopping or tolerance settings, to confirm the analysis is not circular with the proposed fix.
minor comments (2)
- [Algorithm 1] Algorithm 1 / pseudocode: explicitly state the normalization target (e.g., divide by Frobenius norm or max row norm) and confirm it adds no extra optimizer state or hyperparameters.
- [§4] Figure captions and §4 tables: report the number of independent runs and any statistical significance tests for the perplexity differences to support the claim of 'consistent' outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of Muon+ as a lightweight improvement to the Muon optimizer. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (empirical results): the reported end-to-end perplexity gains do not isolate the post-polar imbalance mechanism. No direct measurements of row/column norm variance before/after the added step, no ablation replacing polar iterations with a pure scaling baseline, and no sensitivity checks on the normalization target (e.g., Frobenius vs. max-norm) are provided; thus the speedup could arise from any effective step-size change rather than the claimed tightening of the descent bound.
Authors: We acknowledge that the current experiments demonstrate end-to-end performance gains without directly measuring the norm imbalance or providing the suggested ablations. The blockwise descent analysis in the paper provides the theoretical foundation linking the post-polar imbalance to weakened descent guarantees. To address this, in the revised version we will add direct measurements of row and column norm variances before and after the additional normalization step in representative layers. We will also include an ablation study comparing Muon+ to a baseline that applies scaling without polar orthogonalization to better isolate the effect. For the normalization target, we will add a brief discussion explaining the choice of Frobenius norm based on the analysis of the second-order term. revision: yes
-
Referee: [Blockwise descent analysis] Blockwise descent analysis (around Eq. (analysis of second-order term)): the proof that practical polar steps amplify imbalance and weaken the guarantee assumes specific conditions on the singular spectrum and iteration count; these must be verified against the exact Newton-Schulz implementation used in the code, including any early stopping or tolerance settings, to confirm the analysis is not circular with the proposed fix.
Authors: The analysis assumes that the Newton-Schulz iterations are run for a fixed number of steps sufficient to approximate the polar factor, without early stopping. In our implementation, we use a fixed 5 iterations as is standard in the Muon codebase, with no tolerance-based stopping. We have confirmed that under these settings, the singular values are driven close to 1, and the imbalance amplification occurs as described. We will include a verification note and perhaps a small plot of singular value convergence in the revised manuscript to make this explicit. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's chain begins with an independent blockwise descent analysis that identifies post-polar norm imbalance, proves its tightening effect on the second-order term, and motivates the added normalization step as a direct response. No equation reduces the Muon+ fix to a fitted quantity defined by the same data, no prediction is statistically forced by construction, and no self-citation or ansatz is invoked to justify the core claim. The reported perplexity gains on GPT/LLaMA runs are presented as empirical outcomes, not as outputs that collapse back to the input analysis by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Blockwise descent analysis assumptions hold for the Muon momentum update
Forward citations
Cited by 1 Pith paper
-
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
MuonEq introduces pre-orthogonalization equilibration schemes that improve Muon optimizer performance during large language model pretraining.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
N. Amsel, D. Persson, C. Musco, and R. M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
F. L. Cesista, Y . Jiacheng, and K. Jordan. Squeezing 1-2
-
[5]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
-
[8]
A. Han, J. Li, W. Huang, M. Hong, A. Takeda, P. K. Jawanpuria, and B. Mishra. Sltrain: a sparse plus low rank approach for parameter and memory efficient pretraining.Advances in Neural Information Processing Systems, 37:118267–118295, 2024
work page 2024
-
[9]
N. J. Higham.Functions of matrices: theory and computation. SIAM, 2008
work page 2008
-
[10]
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pages 30016–30030, 2022
work page 2022
- [11]
-
[12]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
- [13]
-
[14]
D. P. Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [15]
- [16]
-
[17]
X. Li. Black box lie group preconditioners for sgd, 2022
work page 2022
-
[18]
X.-L. Li. Preconditioned stochastic gradient descent.IEEE Transactions on Neural Networks and Learning Systems, 29(5):1454–1466, May 2018
work page 2018
-
[19]
X.-L. Li. Preconditioner on matrix lie group for sgd, 2018
work page 2018
-
[20]
X.-L. Li. Stochastic hessian fittings with lie groups, 2024
work page 2024
- [21]
-
[22]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
H. Liu, Z. Li, D. L. W. Hall, P. Liang, and T. Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[24]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Z. Liu, R. Zhang, Z. Wang, M. Yan, Z. Yang, P. D. Hovland, B. Nicolae, F. Cappello, S. Tang, and Z. Zhang. Cola: Compute-efficient pre-training of llms via low-rank activation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4627–4645, 2025
work page 2025
-
[26]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
F. Mehmood, S. Ahmad, and T. K. Whangbo. An efficient optimization technique for training deep neural networks.Mathematics, 11(6):1360, 2023
work page 2023
- [28]
-
[29]
T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V . Cevher. Training deep learning models with norm-constrained lmos, 2025
work page 2025
-
[30]
O. Pooladzandi and X.-L. Li. Curvature-informed sgd via general purpose lie-group precondi- tioners, 2024
work page 2024
-
[31]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
K. Team, Y . Bai, Y . Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y . Chen, Y . Chen, Y . Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
K. Team, A. Du, B. Yin, B. Xing, B. Qu, B. Wang, C. Chen, C. Zhang, C. Du, C. Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, and S. M. Kakade. SOAP: Improving and stabilizing shampoo using adam. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [35]
-
[36]
H. Yuan, Y . Liu, S. Wu, X. Zhou, and Q. Gu. Mars: Unleashing the power of variance reduction for training large models, 2024
work page 2024
-
[37]
A. Zeng, X. Lv, Q. Zheng, Z. Hou, B. Chen, C. Xie, C. Wang, D. Yin, H. Zeng, J. Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [38]
- [39]
-
[40]
J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y . Tian. Galore: Memory-efficient llm training by gradient low-rank projection.arXiv preprint arXiv:2403.03507, 2024. 9 A Hyperparameter A.1 Model Configurations Modeln embd nlayer nhead Param(M) GPT-Small 768 12 12 124 GPT-Base 1024 24 16 362 GPT-Large 1280 36 20 774 Table 7: Architecture configura...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.