Recognition: unknown
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
Pith reviewed 2026-05-14 21:08 UTC · model grok-4.3
The pith
MuonEq adds lightweight row or column normalization to the momentum matrix before finite-step Newton-Schulz orthogonalization to improve the geometry seen by Muon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MuonEq performs equilibration by rescaling rows or columns of the momentum matrix before applying a fixed number of Newton-Schulz iterations. The resulting matrix has a more balanced spectrum, which improves the quality of the orthogonal update. For hidden weights the row-normalization variant (R) is the recommended form. The paper proves that this change preserves the standard Muon-type stationarity guarantee of order T to the minus one-fourth, now with decoupled weight decay and a horizon-free learning-rate schedule, while adding an explicit constant that accounts for the finite number of orthogonalization steps.
What carries the argument
Row normalization (R) of the momentum matrix before finite-step Newton-Schulz orthogonalization, which rebalances the input spectrum to improve the orthogonalization result.
If this is right
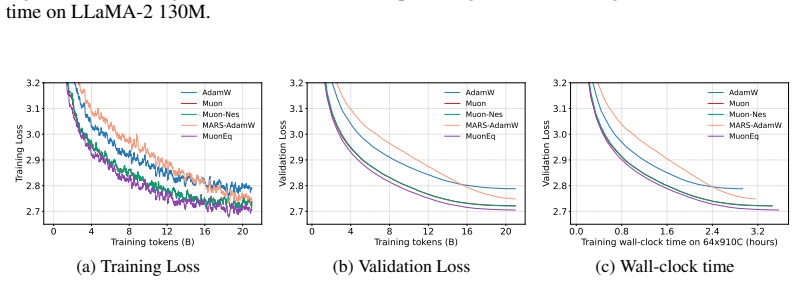
- MuonEq (R) reaches lower validation perplexity than Muon on 130M, 350M, and 1B LLaMA2 models pretrained on C4.
- The row-normalization variant remains the default for hidden matrix weights.
- Finite-step Newton-Schulz orthogonalization with equilibration still satisfies the Muon nonconvex stationarity rate up to an explicit inexactness factor.
- The same diminishing learning-rate schedule and decoupled weight decay used with Muon continue to work with MuonEq.
- Equilibration acts as a zeroth-order stand-in for full whitening preconditioners.
Where Pith is reading between the lines
- The same equilibration step could be inserted before orthogonalization in other matrix-valued optimizers that rely on similar spectral assumptions.
- Because the cost is only a few normalization operations, MuonEq may be especially useful in memory-constrained large-scale runs where heavier whitening is impractical.
- The observed benefit on transformer hidden weights suggests the method may also help in other architectures whose parameters are stored as tall or wide matrices.
- A natural next measurement would be whether the same row-normalization pattern improves performance when the orthogonal step is replaced by a different cheap approximation to the matrix sign function.
Load-bearing premise
Row or column normalization before finite-step orthogonalization reliably improves the geometry seen by orthogonalization without introducing instabilities or requiring dataset-specific tuning.
What would settle it
A training run on the 350M LLaMA2 model on C4 in which MuonEq (R) fails to reach lower validation perplexity than plain Muon after the same number of steps would falsify the claimed improvement.
Figures





read the original abstract
Orthogonalized-update optimizers such as Muon improve training of matrix-valued parameters, but existing extensions typically either rescale updates after orthogonalization or use heavier whitening-based preconditioners before it. We introduce {\method}, a lightweight family of pre-orthogonalization equilibration schemes for Muon with three forms: two-sided row/column normalization (RC), row normalization (R), and column normalization (C). By rebalancing the momentum matrix before finite-step Newton--Schulz orthogonalization, {\method} improves the geometry seen by orthogonalization. We show that finite-step orthogonalization is governed by the input spectrum, especially stable rank and condition number, and that row/column normalization acts as a zeroth-order surrogate for whitening. For hidden matrix weights, R is the default variant. Theoretically, {\method} (R) retains the standard $\widetilde{\mathcal O}(T^{-1/4})$ Muon-type nonconvex stationarity guarantee with decoupled weight decay and a horizon-free diminishing learning-rate schedule, and extends it to finite-step NS5 up to an explicit inexactness constant. In LLaMA2 pretraining on C4, {\method} (R) consistently outperforms Muon on 130M, 350M, and 1B models, with faster convergence and lower validation perplexity. The code is available at the \href{https://github.com/MaeChd/muon-eq}{MuonEq codebase}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MuonEq, a family of lightweight pre-orthogonalization equilibration schemes (RC, R, C) for the Muon optimizer. These rebalance the momentum matrix via row/column normalization before finite-step Newton-Schulz orthogonalization, claimed to improve the input spectrum (stable rank, condition number) seen by orthogonalization. The work extends Muon-type nonconvex convergence guarantees to the new method with an explicit inexactness term for NS5, and reports that MuonEq(R) yields faster convergence and lower validation perplexity than Muon on LLaMA2 pretraining runs (130M/350M/1B models on C4). Code is released.
Significance. If the empirical gains prove robust, MuonEq supplies a low-overhead, theoretically grounded refinement to orthogonalized matrix optimizers that preserves the existing nonconvex rate while addressing a practical spectrum issue before orthogonalization. The parameter-free nature of the equilibration and the released code strengthen its potential utility for large-scale training.
major comments (2)
- [Experiments] Empirical evaluation (LLaMA2 pretraining on C4): the central claim that MuonEq(R) consistently outperforms Muon on 130M, 350M, and 1B models rests on single-run trajectories without reported error bars, multiple seeds, or ablations on learning-rate schedules and normalization strength. This leaves open whether the reported perplexity reductions are statistically reliable or sensitive to hyperparameter choices.
- [Theory] Theoretical analysis (extension of Muon guarantees): while the nonconvex stationarity rate is stated to be retained up to an inexactness constant for finite-step NS5, the manuscript supplies no quantitative bound or empirical measurement of how large this constant becomes in practice during training, nor how the row-normalization step reduces the condition number or stable rank of the momentum matrix in the actual optimization trajectory.
minor comments (2)
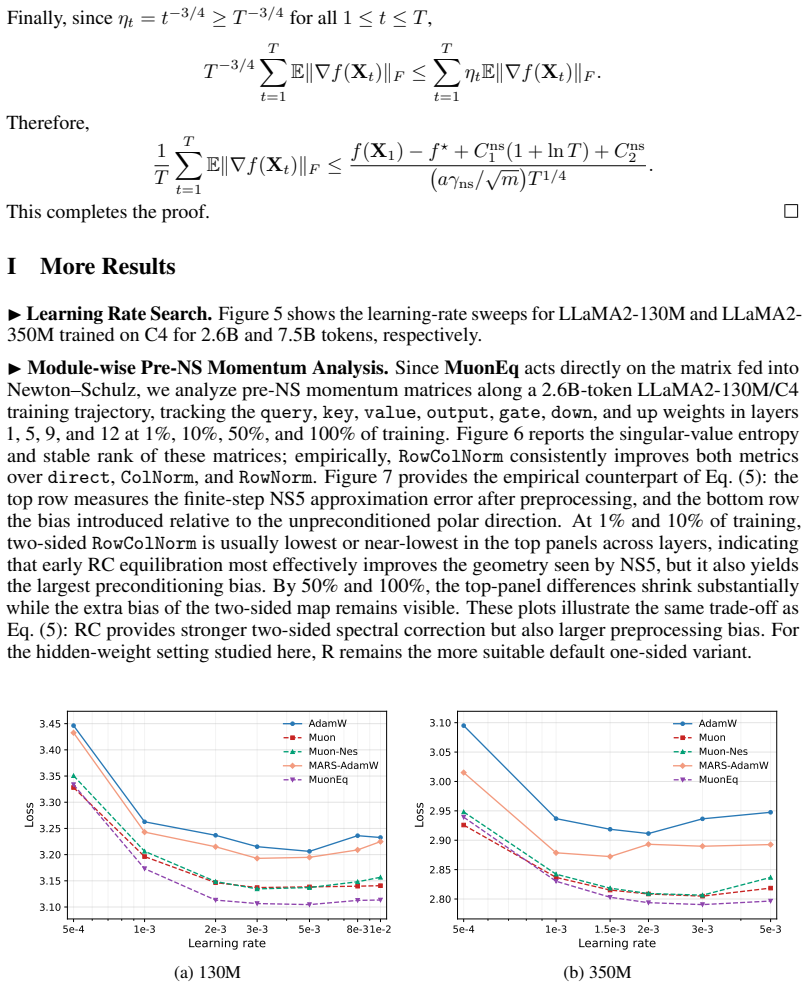
- [Abstract] The abstract and introduction should explicitly state the default choice of R for hidden weights and briefly motivate why column normalization is less preferred.
- [Figures] Figure legends and axis labels in the pretraining plots should include the exact model sizes and whether the curves are smoothed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Empirical evaluation (LLaMA2 pretraining on C4): the central claim that MuonEq(R) consistently outperforms Muon on 130M, 350M, and 1B models rests on single-run trajectories without reported error bars, multiple seeds, or ablations on learning-rate schedules and normalization strength. This leaves open whether the reported perplexity reductions are statistically reliable or sensitive to hyperparameter choices.
Authors: We agree that single-run results limit statistical reliability. In the revised manuscript we will add results from at least three independent random seeds for the 130M and 350M models, reporting means and standard deviations on validation perplexity. For the 1B model we will include additional seeds where compute permits. We will also add ablations on learning-rate schedule variants and on the normalization strength parameter to demonstrate robustness. revision: yes
-
Referee: [Theory] Theoretical analysis (extension of Muon guarantees): while the nonconvex stationarity rate is stated to be retained up to an inexactness constant for finite-step NS5, the manuscript supplies no quantitative bound or empirical measurement of how large this constant becomes in practice during training, nor how the row-normalization step reduces the condition number or stable rank of the momentum matrix in the actual optimization trajectory.
Authors: We acknowledge the absence of both a quantitative bound and empirical measurements. While a tight closed-form bound on the inexactness constant is difficult to obtain and remains beyond the scope of the current work, we will add empirical diagnostics in the revision: plots of condition number and stable rank of the momentum matrices before and after the row-normalization step across training, plus measured deviation from exact orthogonality after NS5 steps. These will quantify the practical effect of equilibration. revision: partial
- Quantitative bound on the inexactness constant for finite-step NS5 in the nonconvex convergence guarantee
Circularity Check
No circularity: derivation extends prior guarantees independently and reports empirical results as validation
full rationale
The paper presents MuonEq as a lightweight pre-orthogonalization equilibration family whose theoretical nonconvex rate is shown to retain the Muon-type bound up to an explicit inexactness term for finite-step NS5. This extension is derived from spectral properties of the input matrix rather than by redefining the target improvement in terms of itself. Row/column normalization is motivated as a zeroth-order surrogate for whitening but is not fitted to or defined by the reported perplexity gains. No equations reduce a claimed prediction to a fitted parameter, no load-bearing uniqueness theorem is imported via self-citation, and the LLaMA2/C4 experiments are presented as independent empirical checks rather than outputs forced by the method definition. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying the Muon nonconvex stationarity guarantee
Forward citations
Cited by 1 Pith paper
-
PolarAdamW: Disentangling Spectral Control and Schur Gauge-Equivariance in Matrix Optimisation
PolarAdamW disentangles spectral control from gauge-equivariance in matrix optimizers, with experiments demonstrating their distinct roles on standard versus symmetry-aware neural networks.
Reference graph
Works this paper leans on
-
[1]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019. OpenReview.net, 2019
2019
-
[2]
Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9508–9520, 2024
Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Yan. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9508–9520, 2024
2024
-
[3]
Mars-m: When variance reduction meets matrices
Yifeng Liu, Angela Yuan, and Quanquan Gu. Mars-m: When variance reduction meets matrices. arXiv preprint arXiv:2510.21800, 2025
-
[4]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cecista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6. 10
2024
-
[5]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
-
[6]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints. arXiv preprint arXiv:2506.15054, 2025
-
[7]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, et al. Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
-
[9]
On the Convergence of Muon and Beyond
Da Chang, Yongxiang Liu, and Ganzhao Yuan. On the convergence of muon and beyond.arXiv preprint arXiv:2509.15816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Convergence bound and critical batch size of muon optimizer
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Convergence bound and critical batch size of muon optimizer. 2025
2025
-
[11]
A note on the convergence of muon
Jiaxiang Li and Mingyi Hong. A note on the convergence of muon. 2025
2025
-
[12]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
-
[14]
Convergence of muon with newton-schulz
Min-hwan Oh Gyu Yeol Kim. Convergence of muon with newton-schulz. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[15]
Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
Egor Shulgin, Sultan AlRashed, Francesco Orabona, and Peter Richtárik. Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
-
[16]
Ruijie Zhang, Yequan Zhao, Ziyue Liu, Zhengyang Wang, and Zheng Zhang. Muon+: Towards better muon via one additional normalization step.arXiv preprint arXiv:2602.21545, 2026
work page internal anchor Pith review arXiv 2026
-
[17]
Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025
-
[18]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
-
[19]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[21]
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost.ArXiv, abs/1804.04235, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, 2015
2015
-
[23]
Fismo: Fisher-structured momentum- orthogonalized optimizer.ArXiv, abs/2601.21750, 2026
Chenrui Xu, Wenjing Yan, and Ying-Jun Angela Zhang. Fismo: Fisher-structured momentum- orthogonalized optimizer.ArXiv, abs/2601.21750, 2026
-
[24]
Mousse: Rectifying the geometry of muon with curvature-aware preconditioning
Yechen Zhang, Shuhao Xing, Junhao Huang, Kai Lv, Yunhua Zhou, Xipeng Qiu, Qipeng Guo, and Kai Chen. Mousse: Rectifying the geometry of muon with curvature-aware preconditioning. 2026. 11
2026
-
[25]
Optimal diagonal preconditioning.Operations Research, 73(3):1479–1495, 2025
Zhaonan Qu, Wenzhi Gao, Oliver Hinder, Yinyu Ye, and Zhengyuan Zhou. Optimal diagonal preconditioning.Operations Research, 73(3):1479–1495, 2025
2025
-
[26]
A scaling algorithm to equilibrate both rows and columns norms in matrices
Daniel Ruiz. A scaling algorithm to equilibrate both rows and columns norms in matrices. Technical report, CM-P00040415, 2001
2001
-
[27]
On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer
Ruihan Xu, Jiajing Li, and Yiping Lu. On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer. 2026
2026
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anth...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[30]
Convergence of adam under relaxed assumptions
Haochuan Li, Alexander Rakhlin, and Ali Jadbabaie. Convergence of adam under relaxed assumptions. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
Closing the gap between the upper bound and lower bound of adam’s iteration complexity
Bohan Wang, Jingwen Fu, Huishuai Zhang, Nanning Zheng, and Wei Chen. Closing the gap between the upper bound and lower bound of adam’s iteration complexity. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[32]
MGUP: A momentum-gradient alignment update policy for stochastic optimization
Da Chang and Ganzhao Yuan. MGUP: A momentum-gradient alignment update policy for stochastic optimization. InThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems, 2025
2025
-
[33]
Limuon: Light and fast muon optimizer for large models.arXiv preprint arXiv:2509.14562, 2025
Feihu Huang, Yuning Luo, and Songcan Chen. Limuon: Light and fast muon optimizer for large models.arXiv preprint arXiv:2509.14562, 2025
-
[34]
Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598, 2025
Xun Qian, Hussein Rammal, Dmitry Kovalev, and Peter Richtarik. Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598, 2025
-
[35]
Cong Fang, Chris Junchi Li, Zhouchen Lin, and T. Zhang. Spider: Near-optimal non-convex optimization via stochastic path integrated differential estimator.ArXiv, abs/1807.01695, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Stochastic nested variance reduction for nonconvex optimization.Journal of machine learning research, 21(103):1–63, 2020
Dongruo Zhou, Pan Xu, and Quanquan Gu. Stochastic nested variance reduction for nonconvex optimization.Journal of machine learning research, 21(103):1–63, 2020
2020
-
[37]
Momentum-based variance reduction in non-convex sgd.ArXiv, abs/1905.10018, 2019
Ashok Cutkosky and Francesco Orabona. Momentum-based variance reduction in non-convex sgd.ArXiv, abs/1905.10018, 2019
-
[38]
Super-adam: Faster and universal framework of adaptive gradients.ArXiv, abs/2106.08208, 2021
Feihu Huang, Junyi Li, and Heng Huang. Super-adam: Faster and universal framework of adaptive gradients.ArXiv, abs/2106.08208, 2021
-
[39]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and V olkan Cevher. Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
-
[40]
A minimalist optimizer design for llm pretraining.arXiv preprint arXiv:2506.16659, 2025
Athanasios Glentis, Jiaxiang Li, Andi Han, and Mingyi Hong. A minimalist optimizer design for llm pretraining.arXiv preprint arXiv:2506.16659, 2025. 12
-
[41]
Adagrad meets muon: Adaptive stepsizes for orthogonal updates
Minxin Zhang, Yuxuan Liu, and Hayden Schaeffer. Adagrad meets muon: Adaptive stepsizes for orthogonal updates. 2025
2025
-
[42]
Minxin Zhang, Yuxuan Liu, and Hayden Scheaffer. Adam improves muon: Adaptive moment estimation with orthogonalized momentum.arXiv preprint arXiv:2602.17080, 2026
-
[43]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
-
[44]
Muloco: Muon is a practical inner optimizer for diloco.arXiv preprint arXiv:2505.23725, 2025
Benjamin Thérien, Xiaolong Huang, Irina Rish, and Eugene Belilovsky. Muloco: Muon is a practical inner optimizer for diloco.arXiv preprint arXiv:2505.23725, 2025
-
[45]
Effective quantization of muon optimizer states.arXiv preprint arXiv:2509.23106, 2025
Aman Gupta, Rafael Celente, Abhishek Shivanna, DT Braithwaite, Gregory Dexter, Shao Tang, Hiroto Udagawa, Daniel Silva, Rohan Ramanath, and S Sathiya Keerthi. Effective quantization of muon optimizer states.arXiv preprint arXiv:2509.23106, 2025
-
[46]
Saurabh Page, Advait Joshi, and SS Sonawane. Muonall: Muon variant for efficient finetuning of large language models.arXiv preprint arXiv:2511.06086, 2025
-
[47]
Shuntaro Nagashima and Hideaki Iiduka. Improved convergence rates of muon optimizer for nonconvex optimization.arXiv preprint arXiv:2601.19400, 2026
-
[48]
On convergence of muon for nonconvex stochastic optimization under generalized smoothness.Authorea Preprints, 2026
Yubo Zhang and Junhong Lin. On convergence of muon for nonconvex stochastic optimization under generalized smoothness.Authorea Preprints, 2026
2026
-
[49]
Optimizing neural networks with kronecker-factored approx- imate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curvature. InInternational conference on machine learning, pages 2408–2417. PMLR, 2015
2015
-
[50]
Kronecker-factored approximate curvature for modern neural network architectures.Advances in Neural Information Processing Systems, 36:33624–33655, 2023
Runa Eschenhagen, Alexander Immer, Richard Turner, Frank Schneider, and Philipp Hennig. Kronecker-factored approximate curvature for modern neural network architectures.Advances in Neural Information Processing Systems, 36:33624–33655, 2023
2023
-
[51]
Sketchy: Memory- efficient adaptive regularization with frequent directions.Advances in Neural Information Processing Systems, 36:75911–75924, 2023
Vladimir Feinberg, Xinyi Chen, Y Jennifer Sun, Rohan Anil, and Elad Hazan. Sketchy: Memory- efficient adaptive regularization with frequent directions.Advances in Neural Information Processing Systems, 36:75911–75924, 2023
2023
-
[52]
Asgo: Adaptive structured gradient optimization.arXiv preprint arXiv:2503.20762, 2025
Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. Asgo: Adaptive structured gradient optimization.arXiv preprint arXiv:2503.20762, 2025
-
[53]
Ekaterina Grishina, Matvey Smirnov, and Maxim Rakhuba. Accelerating newton-schulz itera- tion for orthogonalization via chebyshev-type polynomials.arXiv preprint arXiv:2506.10935, 2025
-
[54]
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
Noah Amsel, David Persson, Christopher Musco, and Robert M Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Positive definite matrices
Rajendra Bhatia. Positive definite matrices. InPositive Definite Matrices. Princeton university press, 2009. 13 Appendix A Proofs of Theorem 3.1 Proof.The claim fork= 0is immediate from X0 =α −1G=Udiag σ1 α , . . . , σr α V⊤. Assume that, for somek≥0, Xk =Udiag s(k) 1 , . . . , s(k) r V⊤. Then XkX⊤ k =Udiag (s(k) 1 )2, . . . ,(s(k) r )2 U⊤. Substituting t...
2009
-
[56]
Under the standard deep-learning storage layout W=θ ⊤ ∈R dout×din, this corresponds to row normalization of the stored hidden-weight matrix
write linear weights as θ∈R din×dout and define column-wise normalization along the output dimension. Under the standard deep-learning storage layout W=θ ⊤ ∈R dout×din, this corresponds to row normalization of the stored hidden-weight matrix. Their empirical observation that row-wise normalization can be unstable is also traced largely to the LM-head, whe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.