Recognition: 2 theorem links
· Lean TheoremGeneralizing Score-based generative models for Heavy-tailed Distributions
Pith reviewed 2026-05-15 18:06 UTC · model grok-4.3
The pith
Early stopping plus normalizing flow initialization extends score-based models to any heavy-tailed target with KL convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Combining early stopping with a suitable initialization is sufficient to extend the diffusion framework to any target distribution; we establish the well-posedness of the backward process and prove convergence of the approximated diffusion in KL divergence. Novel theoretical guarantees for generation with normalizing flows hold under mild conditions on the flow family and without any assumption on the tail behavior of the target distribution. A normalizing flow is first trained to capture the tail behavior and is then used as an initialization prior for an SGM that refines the samples.
What carries the argument
Early stopping of the forward diffusion together with a normalizing-flow initialization that encodes the target's tail behavior.
If this is right
- The diffusion framework becomes applicable to any target distribution once early stopping and a suitable initialization are used.
- The backward process remains well-posed and the finite-time approximation converges in KL divergence.
- Normalizing flows alone achieve convergence under mild conditions on the flow family, independent of tail heaviness.
- The hybrid pipeline lets the flow handle global tail placement while the score model recovers fine local structure.
Where Pith is reading between the lines
- The same early-stopping idea could be tested with other tail-capturing initializers besides normalizing flows.
- Heavy-tailed data sets common in finance or extreme-value modeling become directly addressable without custom score-matching losses.
- If the flow initialization is accurate in the tails, the required number of diffusion steps may be smaller than in standard SGMs.
Load-bearing premise
The normalizing flow must be expressive enough to capture the tail behavior of the target distribution so that it provides a useful initialization prior for the subsequent SGM refinement step.
What would settle it
Running the hybrid procedure on a known heavy-tailed test distribution (for example a multivariate t-distribution with low degrees of freedom) and checking whether the generated samples reproduce the correct tail exponents or whether the KL divergence to the target fails to decrease.
Figures








read the original abstract
Score-based generative models (SGMs) have achieved remarkable empirical success, motivating their application to a broad range of data distributions. However, extending them to heavy-tailed targets remains a largely open problem. Although dedicated models for heavy-tailed distributions have been proposed, their generative fidelity remains unclear and they lack solid theoretical foundations, leaving important questions open in this regime. In this paper, we address this gap through two theoretical contributions. First, we show that combining early stopping with a suitable initialization is sufficient to extend the diffusion framework to any target distribution; in particular, we establish the well-posedness of the backward process and prove convergence of the approximated diffusion in KL divergence. Second, we derive novel theoretical guarantees for generation with normalizing flows, obtaining convergence results that hold under mild conditions on the flow family and without any assumption on the tail behavior of the target distribution. Building on these results, we propose a unified generative framework for heavy-tailed distributions: a normalizing flow is first trained to capture the tail behavior and is then used as an initialization prior for an SGM, which refines the samples by recovering fine-grained structural details. This design leverages the complementary strengths of the two model classes within a theoretically principled pipeline, overcoming the limitations of existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the challenge of applying score-based generative models (SGMs) to heavy-tailed distributions by proposing a hybrid framework: a normalizing flow (NF) is first trained to capture tail behavior and serves as an initialization prior, after which an SGM with early stopping refines the samples to recover fine details. The central claims are that early stopping plus suitable initialization extends the diffusion framework to arbitrary targets, with proofs of well-posedness for the backward process and KL-divergence convergence of the approximated diffusion; additionally, novel convergence guarantees are derived for NF generation under mild conditions on the flow family and without any tail assumptions on the target.
Significance. If the stated convergence results hold, the work would provide a theoretically grounded way to extend SGMs beyond light-tailed regimes, leveraging the complementary strengths of NFs (for tails) and SGMs (for structure). The absence of tail assumptions in the NF guarantees and the use of early stopping to ensure well-posedness are potentially impactful contributions to the field of generative modeling for non-standard distributions.
major comments (2)
- [Abstract] Abstract and theoretical contributions section: the claims of proving well-posedness of the backward process and KL convergence of the approximated diffusion rest on early stopping plus initialization, but no specific error bounds, initialization assumptions, or derivation steps are provided to verify the arguments; this is load-bearing for the central claim that the framework extends to any target distribution.
- [Theoretical contributions] Section on NF guarantees: the convergence results for normalizing flows are stated to hold without tail assumptions on the target, yet the pipeline relies on the NF being expressive enough to capture tail behavior for useful initialization; the manuscript should clarify how mild conditions on the flow family ensure this without circularity or additional tail requirements.
minor comments (2)
- [Preliminaries] Notation for the backward process and early stopping parameter should be introduced with explicit definitions to improve readability.
- [Introduction] The abstract mentions 'mild conditions on the flow family' but does not list them; a brief enumeration in the introduction would help.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for recognizing the potential significance of our contributions. We address the major comments below, providing clarifications and indicating planned revisions to strengthen the presentation of our theoretical results.
read point-by-point responses
-
Referee: [Abstract] Abstract and theoretical contributions section: the claims of proving well-posedness of the backward process and KL convergence of the approximated diffusion rest on early stopping plus initialization, but no specific error bounds, initialization assumptions, or derivation steps are provided to verify the arguments; this is load-bearing for the central claim that the framework extends to any target distribution.
Authors: We agree that the main text would benefit from more explicit details on the theoretical arguments. The full proofs, including the choice of early stopping time based on the score matching error and the initialization from the NF output, along with the resulting KL divergence bound, are provided in Section 3.2 and Appendix B. The key assumption is that the initialization distribution is absolutely continuous with respect to the target, which is ensured by the NF. We will revise the abstract and theoretical contributions section to include a high-level sketch of the proof strategy and the form of the error bound to make the arguments more verifiable without requiring the reader to consult the appendix. revision: partial
-
Referee: [Theoretical contributions] Section on NF guarantees: the convergence results for normalizing flows are stated to hold without tail assumptions on the target, yet the pipeline relies on the NF being expressive enough to capture tail behavior for useful initialization; the manuscript should clarify how mild conditions on the flow family ensure this without circularity or additional tail requirements.
Authors: The mild conditions on the flow family refer to standard universal approximation properties (e.g., the flow being able to approximate any continuous density in total variation or KL divergence), which are independent of the target's tail behavior and do not require any tail-specific assumptions. This guarantees that the NF can converge to the target for any distribution, including heavy-tailed ones, as the network width or depth increases. The SGM component then refines the samples using early stopping, and its convergence holds regardless of the specific initialization as long as it satisfies the absolute continuity condition. There is no circularity because the NF convergence result is general and does not rely on the SGM part. We will add a clarifying paragraph in the theoretical contributions section to explicitly separate the general NF guarantees from their practical use in the hybrid pipeline. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper establishes well-posedness of the backward process and KL convergence for the approximated diffusion via early stopping plus suitable initialization, plus convergence guarantees for normalizing flows under mild flow-family conditions with no tail assumptions on the target. These results are derived from standard diffusion theory and are presented as independent theoretical contributions; the subsequent NF-then-SGM pipeline is justified by the complementary roles of the two components without any reduction of the central claims to fitted inputs, self-definitional loops, or load-bearing self-citations. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mild conditions on the flow family suffice for convergence without tail assumptions on the target
- domain assumption Early stopping plus suitable initialization renders the backward process well-posed for any target
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KL control of the backward process and convergence in KL divergence under early stopping
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Normalizing flow initialization for heavy-tailed p_T without tail assumptions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Do Heavy Tails Help Diffusion? On the Subtle Trade-off Between Initialization and Training
Heavy-tailed noise in diffusion models leads to less favorable sampling-error bounds than light-tailed Gaussian noise by making the underlying statistical estimation problem harder.
Reference graph
Works this paper leans on
-
[1]
Allouche, M., Girard, S., and Gobet, E. (2022). Ev-gan: Simulation of extreme events with relu neural networks. Journal of Machine Learning Research, 23(120):1–39. Baldridge, J., Bauer, J., Bhutani, M., Brichtova, N., Bunner, A., Castrejon, L., Chan, K., Chen, Y ., Dieleman, S., Du, Y ., Eaton-Rosen, Z., Fei, H., de Freitas, N., Gao, Y ., Gladchenko, E., ...
-
[2]
Adam: A Method for Stochastic Optimization
Curran Associates, Inc. Issachar, N., Salama, M., Fattal, R., and Benaim, S. (2024). Designing a conditional prior distribution for flow-based generative models. Jayasumana, S., Ramalingam, S., Veit, A., Glasner, D., Chakrabarti, A., and Kumar, S. (2023). Rethinking fid: Towards a better evaluation metric for image generation. 2024 IEEE/CVF Conference on ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
dµX0(x0) = Z CT ×Rd Z T 0 ∥At(x)−a t(x)∥2 2b 2 t dtdµ X,X0(x, x0) = Z CT Z T 0 ∥At(x)−a t(x)∥2 2b 2 t dtdµ X(x) =E " 1 2 Z T 0 1 b2s ∥As(X)−a s(X)∥2 ds # ,(22) which concludes the proof. A.2. Lemmas required for Theorem 3.1 Following Theorem 5.2.1 in (Øksendal, 2003), it is easy to show that if − →X 0 ∈L 2(Ω,F,P) and if t7→α t, and t7→g t are bounded, the...
work page 2003
-
[4]
Using the general property ∆f(x) f(x) = ∆f(x) +∥∇f(x)∥ 2 , we can write ∂t log ˜pT−t (x)ρ(x) + ¯αt h ρ(x)∇log ˜pT−t (x)·x+∇ρ(x)·x+d ρ(x) i + ¯g2 t 2 h ρ(x) [∆ log ˜pT−t (x) +∥∇log ˜pT−t (x)∥2] + ∆ρ(x) + 2∇log ˜pT−t (x)· ∇ρ(x) i = 0, and so ∂t log ˜pT−t (x) + ¯g2 t 2 h ∆ log ˜pT−t (x) +∥∇log ˜pT−t (x)∥2 i =− ¯g2 t 2 h∆ρ(x) ρ(x) + 2∇log ˜pT−t (x)· ∇logρ(x) ...
work page 2025
-
[5]
18 Initialization-Aware Score-Based Diffusion Sampling The KL bound we obtain is the following : DKL ⃗ pδ||pθ T−δ ≤D KL ⃗ pT ||pθ 0 + = 1 2 Z T−δ 0 1 ¯g2 t E ¯g2 t ∇log⃗ pT−t (← −X t)− N−1X k=0 ¯g2 t sθ(T−t k, ← −X tk)1[tk,tk+1](t) 2 dt ,(32) Using the square triangular inequality and extracting¯gt, we get that DKL ⃗ pδ||pθ T−δ ≤D KL ⃗ pT ||pθ 0 (33) + N−...
work page 2018
-
[6]
end for P0 =θ T X0 P1 =θ T X1 newsw = 1d-Wasserstein(P0, P1) E= AdamUpdate(E,∇ E newsw) tol =|new sw −old sw | end while Output:new sw,θ. Proof. Since E and F are Polish spaces, regular conditional distributions µX|T(X) and µY|T(Y) exist Douc et al. (2018, Appendix). Under the stated absolute continuity assumptions, Lemma A.8 ensures that µX ≪µ Y and that...
work page 2018
-
[7]
For the choice of discretization points, we followed the power law approach from (Karras et al.,
For sampling, a 10 steps second order ODE Heun- sampler was used (Karras et al., 2022). For the choice of discretization points, we followed the power law approach from (Karras et al.,
work page 2022
-
[8]
In the HT case, we must train a denoiser, since the score function is not analytically available for the convolution of a Gaussian distribution with a heavy-tailed distribution. The training of the denoiser for HT case was performed training a MLP like neural network using training strategies from (Karras et al., 2022). The detail on the denoiser are avai...
work page 2022
-
[9]
using the Adam optimizer (Kingma and Ba, 2014). Learning rate Batch size Dataset size N Layers Layer Width N Epochs 10−4 2048 5×10 5 10 1000 100 For the HT case, we train a single denoiser and estimateˆνonce. We then compute SWD and MaxSWD using 25 comparisons between independent test data and generated samples for each initialization, with 106 samples pe...
work page 2014
-
[10]
The error is computed for each marginal, and the mean across all dimensions is taken to provide a robust estimation. Table 12 reports the relative quantile errors for d= 100 , all different time horizons σT and range of quantiles q∈ {0.99, . . . ,0.99999} . Finally, in Figure 6, we present the empirical quantile functions of the first marginal computed on...
work page 2022
-
[11]
For both cases, we used the EDM sampler (Karras et al., 2022)
0 0.11 ± 0.03 0.13 ± 0.04 0.209 ± 0.268 0.335 ± 0.864 2 0.025 ± 0.004 0.034 ± 0.004 0.286 ± 0.328 0.374 ± 0.862 5 0.049 ± 0.007 0.073 ± 0.006 0.250 ± 0.282 0.660 ± 1.147 7 0.067 ± 0.009 0.104 ± 0.007 0.324 ± 0.321 0.738 ± 1.180 15 0.14 ± 0.02 0.22 ± 0.02 0.363 ± 0.340 0.830 ± 1.157 80 0.76 ± 0.1 1.21 ± 0.08 0.758 ± 0.087 1.321 ± 0.668 Table 12.Tail Precis...
work page 2025
-
[12]
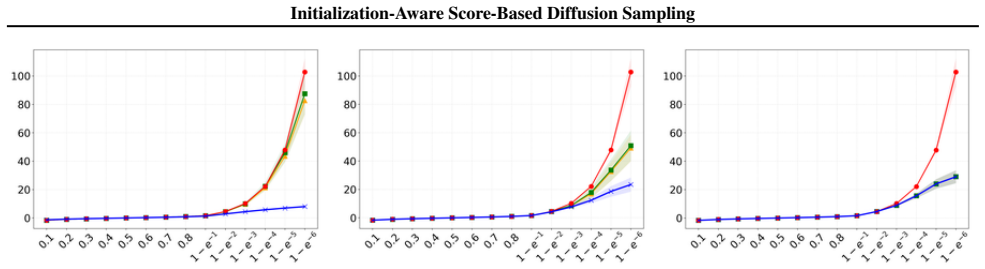
p∞ in blue, pT in orange, pθ in green, real data in red
25 Initialization-Aware Score-Based Diffusion Sampling (a)σ T = 2 (b)σ T = 5 (c)σ T = 7 (d)σ T = 15 (e)σ T = 80 Figure 6.Quantile plot (0.1–0.999999) of mean and std over all dimensions d= 100 of quantile estimation of the heavy–tailed distribution using 107 samples. p∞ in blue, pT in orange, pθ in green, real data in red. On the x-axis the quantile level...
work page 2022
-
[13]
to evaluate generation quality. Recent research has highlighted limitations of FID (Jayasumana et al., 2023; Stein et al., 2023); therefore, we also consider other metrics to assess sample quality. These include the unbiased Kernel Inception Distance (KID) (Bi´nkowski et al., 2018), Dino Fr´echet Distance (DinoFD), which follows the same approach as FID b...
work page 2023
-
[14]
generated samples and we report the minimum on 3 experiments
Figure 8.Grid comparison for FFHQ generation. generated samples and we report the minimum on 3 experiments. For each of 3 experiments, we computed 4 times SWD and MaxSWD using for each test 17,5×10 3 datapoints and 2×10 4 slices. We report the global mean and standard deviation for SWD and MaxSWD over the 12 evaluations (3×4 ). We compare generated sample...
work page 2022
-
[15]
in conditional sampling shows that the fact of using σT = 80 as a standard is an arbitrary choice that does not suit all datasets, highlighting the importance of initialization-aware strategies. Randomly sampled nearest-neighbor images show that our method produces diverse results and does not simply replicate the training data. Overall, these results ind...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.