Recognition: no theorem link
Evaluating the Search Agent in a Parallel World
Pith reviewed 2026-05-15 16:58 UTC · model grok-4.3
The pith
Search agents excel at evidence synthesis with complete information but are limited by collection, coverage, sufficiency judgments, and when-to-stop decisions in unfamiliar environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Mind-ParaWorld framework samples real-world entity names to synthesize future scenarios and questions beyond model knowledge cutoffs, employs a ParaWorld Law Model to construct indivisible atomic facts and unique ground truths, and uses a ParaWorld Engine Model to dynamically generate SERPs based on those facts. Evaluation on MPW-Bench shows search agents perform strongly at evidence synthesis given complete information but remain limited by evidence collection and coverage in unfamiliar search environments as well as by unreliable evidence sufficiency judgment and when-to-stop decisions.
What carries the argument
The ParaWorld Engine Model, which dynamically generates search engine result pages grounded in a fixed set of atomic facts for each synthesized scenario.
If this is right
- Improving evidence collection and coverage in novel environments would directly raise overall agent performance.
- Better mechanisms for judging evidence sufficiency would reduce premature stopping or unnecessary continued search.
- Explicit training or prompting for when-to-stop decisions would address a primary bottleneck separate from synthesis ability.
- Given strong synthesis results under complete information, future work can focus on upstream collection rather than downstream reasoning.
Where Pith is reading between the lines
- The framework could be extended by dynamically updating atomic facts to simulate real-time information evolution and test adaptation over time.
- Explicit metacognitive modules for monitoring information sufficiency might be added to agents to mitigate the identified stopping and judgment failures.
- Benchmark designers using real search engines could calibrate their results against ParaWorld runs to quantify how much parametric memory inflates apparent capabilities.
Load-bearing premise
The ParaWorld Engine Model produces search result pages realistic enough that measured agent limitations reflect genuine capability gaps rather than simulation artifacts.
What would settle it
Running the same set of agents on equivalent queries using a real commercial search engine and observing whether performance patterns, failure modes, and coverage gaps match those recorded in the ParaWorld simulation would confirm or refute the framework.
Figures


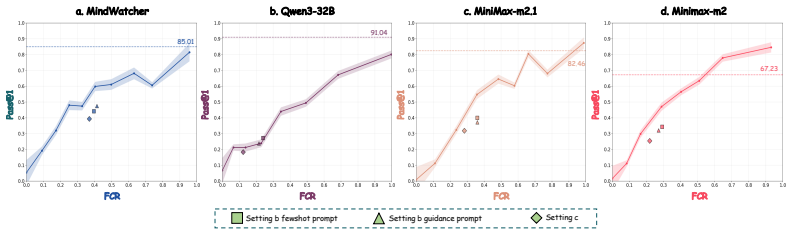
read the original abstract
Integrating web search tools has significantly extended the capability of LLMs to address open-world, real-time, and long-tail problems. However, evaluating these Search Agents presents formidable challenges. First, constructing high-quality deep search benchmarks is prohibitively expensive, while unverified synthetic data often suffers from unreliable sources. Second, static benchmarks face dynamic obsolescence: as internet information evolves, complex queries requiring deep research often degrade into simple retrieval tasks due to increased popularity, and ground truths become outdated due to temporal shifts. Third, attribution ambiguity confounds evaluation, as an agent's performance is often dominated by its parametric memory rather than its actual search and reasoning capabilities. Finally, reliance on specific commercial search engines introduces variability that hampers reproducibility. To address these issues, we propose a novel framework, Mind-ParaWorld, for evaluating Search Agents in a Parallel World. Specifically, MPW samples real-world entity names to synthesize future scenarios and questions situated beyond the model's knowledge cutoff. A ParaWorld Law Model then constructs a set of indivisible Atomic Facts and a unique ground-truth for each question. During evaluation, instead of retrieving real-world results, the agent interacts with a ParaWorld Engine Model that dynamically generates SERPs grounded in these inviolable Atomic Facts. We release MPW-Bench, an interactive benchmark spanning 19 domains with 1,608 instances. Experiments across three evaluation settings show that, while search agents are strong at evidence synthesis given complete information, their performance is limited not only by evidence collection and coverage in unfamiliar search environments, but also by unreliable evidence sufficiency judgment and when-to-stop decisions-bottlenecks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Mind-ParaWorld (MPW) framework for evaluating LLM search agents in a controlled parallel world. Real-world entity names are sampled to synthesize future scenarios and questions beyond model cutoffs; a ParaWorld Law Model constructs indivisible atomic facts and unique ground truths; and a ParaWorld Engine Model dynamically generates SERPs grounded in these facts. The authors release MPW-Bench (1,608 instances across 19 domains) and report experiments in three evaluation settings showing that agents perform well at evidence synthesis given complete information but are limited by evidence collection/coverage in unfamiliar environments, unreliable sufficiency judgment, and when-to-stop decisions.
Significance. If the Engine Model faithfully reproduces statistical properties of real SERPs (inconsistencies, partial overlaps, ranking artifacts, temporal drift), the framework supplies a reproducible, temporally stable benchmark that isolates search and reasoning capabilities from parametric memory and commercial engine variability. The public release of MPW-Bench and the identification of concrete bottlenecks (sufficiency judgment, stopping) would be useful contributions for guiding search-agent design.
major comments (2)
- [ParaWorld Engine Model description (abstract and §3)] The central claim that agents are limited by sufficiency judgment and stopping decisions rests on the assumption that the ParaWorld Engine Model produces SERPs whose statistical properties match real search engines. The abstract states that the model 'dynamically generates SERPs grounded in these inviolable Atomic Facts' but supplies no description of how grounding is enforced, whether contradictions outside the atomic set can be introduced, or how ranking, snippet truncation, and noise are modeled. Without these details or a validation against real SERP distributions, the measured bottlenecks may reflect simulation artifacts rather than intrinsic agent limitations.
- [Experiments section (abstract and §4)] The abstract reports results 'across three evaluation settings' yet provides no quantitative tables, performance metrics, error bars, or explicit construction details for the settings. To support the claim that limitations arise specifically from collection, coverage, sufficiency, and stopping, the manuscript must include the per-setting metrics and ablation controls that isolate each factor.
minor comments (2)
- [Abstract] The abstract uses 'MPW-Bench' and 'Mind-ParaWorld' interchangeably; consistent terminology would improve readability.
- [Related work] The manuscript should cite prior work on synthetic search benchmarks and agent evaluation frameworks to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of the ParaWorld Engine Model and the experimental results.
read point-by-point responses
-
Referee: [ParaWorld Engine Model description (abstract and §3)] The central claim that agents are limited by sufficiency judgment and stopping decisions rests on the assumption that the ParaWorld Engine Model produces SERPs whose statistical properties match real search engines. The abstract states that the model 'dynamically generates SERPs grounded in these inviolable Atomic Facts' but supplies no description of how grounding is enforced, whether contradictions outside the atomic set can be introduced, or how ranking, snippet truncation, and noise are modeled. Without these details or a validation against real SERP distributions, the measured bottlenecks may reflect simulation artifacts rather than intrinsic agent limitations.
Authors: We agree that the current description requires expansion to fully substantiate the simulation's fidelity. In the revised manuscript we will add explicit details in §3 on the grounding enforcement mechanism (generation is strictly limited to compositions and paraphrases of the provided atomic facts, with an automated verification step that rejects any output introducing external information or contradictions), the noise model (controlled rates of fact omission, partial overlaps, and injected inconsistencies), the ranking procedure (relevance scores computed over atomic facts with simulated position bias), and snippet truncation (fixed-length outputs with relevance-based selection). We will also include a new validation subsection that compares generated SERP statistics (overlap, inconsistency rate, ranking stability, and temporal drift) against real commercial search engine outputs on matched queries. These additions will directly support that the reported bottlenecks in collection, sufficiency judgment, and stopping arise from agent behavior rather than simulation artifacts. revision: yes
-
Referee: [Experiments section (abstract and §4)] The abstract reports results 'across three evaluation settings' yet provides no quantitative tables, performance metrics, error bars, or explicit construction details for the settings. To support the claim that limitations arise specifically from collection, coverage, sufficiency, and stopping, the manuscript must include the per-setting metrics and ablation controls that isolate each factor.
Authors: We acknowledge that the abstract would be clearer with quantitative summaries and that the isolation of factors can be strengthened. Section §4 already presents results for the three settings (oracle retrieval with complete information, agent-driven dynamic search, and stopping/sufficiency ablations) together with supporting tables and metrics. In the revision we will update the abstract to report the key quantitative findings from these tables (including error bars) and will add explicit ablation tables that isolate the contributions of evidence collection/coverage, sufficiency judgment accuracy, and stopping decisions. We will also expand the description of how each setting is constructed to make the experimental design fully reproducible. revision: yes
Circularity Check
No circularity: novel synthetic benchmark components are independently constructed
full rationale
The paper defines a new Mind-ParaWorld framework by sampling real-world entities, building a ParaWorld Law Model to produce atomic facts and ground truth, and using a ParaWorld Engine Model to generate SERPs. These steps are presented as forward constructions rather than reductions of outputs to fitted inputs or prior self-citations. No equations, uniqueness theorems, or ansatzes are shown to collapse the central claims about agent limitations back into the same data or definitions. The evaluation results therefore rest on the new benchmark rather than tautological reuse of its own measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world entity names can be sampled and placed in future scenarios that lie beyond any model's knowledge cutoff while still allowing construction of stable ground truth.
invented entities (2)
-
ParaWorld Engine Model
no independent evidence
-
ParaWorld Law Model
no independent evidence
Forward citations
Cited by 1 Pith paper
-
CGC: Compositional Grounded Contrast for Fine-Grained Multi-Image Understanding
CGC improves fine-grained multi-image understanding in MLLMs by constructing contrastive training instances from existing single-image annotations and adding a rule-based spatial reward, achieving SOTA on MIG-Bench an...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, and Lihua Zhang. Detecting and evaluating medical hallucinations in large vision language models.arXiv preprint arXiv:2406.10185, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Jiawei Chen, Xintian Shen, Lihao Zheng, Zhenwei Shao, Hongyuan Zhang, Pengfei Yu, Xudong Rao, Ning Mao, Xiaobo Liu, Lian Wen, et al. Mindwatcher: Toward smarter multimodal tool- integrated reasoning.arXiv preprint arXiv:2512.23412, 2025
-
[4]
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming- Wei Chang. Can pre-trained vision and language models answer visual information-seeking questions?arXiv preprint arXiv:2302.11713, 2023
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Yida Zhao, Kuan Li, et al. Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Robust identifiability for symbolic recovery of differential equations
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, and Lihua Zhang. Comt: Chain-of-medical-thought reduces hallucination in medical report generation. InICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025. doi: 10.1109/ICASSP49660.2025.10887699
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[10]
Mccd: Multi-agent collaboration-based compositional diffusion for complex text-to-image generation
Mingcheng Li, Xiaolu Hou, Ziyang Liu, Dingkang Yang, Ziyun Qian, Jiawei Chen, Jinjie Wei, Yue Jiang, Qingyao Xu, and Lihua Zhang. Mccd: Multi-agent collaboration-based compositional diffusion for complex text-to-image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13263–13272, 2025
work page 2025
-
[11]
Zijian Li, Xin Guan, Bo Zhang, Shen Huang, Houquan Zhou, Shaopeng Lai, Ming Yan, Yong Jiang, Pengjun Xie, Fei Huang, et al. Webweaver: Structuring web-scale evidence with dynamic outlines for open-ended deep research.arXiv preprint arXiv:2509.13312, 2025
-
[12]
Introducing openai o3 and o4-mini
OpenAI. Introducing openai o3 and o4-mini. https://openai.com/index/ introducing-o3-and-o4-mini/, April 2025. Accessed: 2025-12-19
work page 2025
-
[13]
Mindgpt-4ov: An enhanced mllm via a multi-stage post-training paradigm
MindGPT ov Team. Mindgpt-4ov: An enhanced mllm via a multi-stage post-training paradigm. arXiv preprint arXiv:2512.02895, 2025
-
[14]
Improving language understanding by generative pre-training, 2018
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training, 2018
work page 2018
-
[15]
Xintian Shen, Jiawei Chen, Lihao Zheng, Hao Ma, Tao Wei, and Kun Zhan. Evolving from tool user to creator via training-free experience reuse in multimodal reasoning.arXiv preprint arXiv:2602.01983, 2026. 31
-
[16]
Flowagent: Achieving compliance and flexibility for workflow agents
Yuchen Shi, Siqi Cai, Zihan Xu, Yuei Qin, Gang Li, Hang Shao, Jiawei Chen, Deqing Yang, Ke Li, and Xing Sun. Flowagent: Achieving compliance and flexibility for workflow agents. arXiv preprint arXiv:2502.14345, 2025
-
[17]
Yuchen Shi, Yuzheng Cai, Siqi Cai, Zihan Xu, Lichao Chen, Yulei Qin, Zhijian Zhou, Xiang Fei, Chaofan Qiu, Xiaoyu Tan, et al. Youtu-agent: Scaling agent productivity with automated generation and hybrid policy optimization.arXiv preprint arXiv:2512.24615, 2025
-
[18]
Webshaper: Agentically data synthesizing via information-seeking formalization
Zhengwei Tao, Jialong Wu, Wenbiao Yin, Junkai Zhang, Baixuan Li, Haiyang Shen, Kuan Li, Liwen Zhang, Xinyu Wang, Yong Jiang, et al. Webshaper: Agentically data synthesizing via information-seeking formalization.arXiv preprint arXiv:2507.15061, 2025
-
[19]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[23]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Gang Fu, Yong Jiang, et al. Webdancer: Towards autonomous information seeking agency.arXiv preprint arXiv:2505.22648, 2025
-
[26]
Webwalker: Benchmarking llms in web traversal
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, et al. Webwalker: Benchmarking llms in web traversal. arXiv preprint arXiv:2501.07572, 2025
-
[27]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[30]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022. 32
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.