Recognition: unknown
VLN-Cache: Enabling Token Caching for VLN Models with Visual/Semantic Dynamics Awareness
Pith reviewed 2026-05-15 14:48 UTC · model grok-4.3
The pith
VLN-Cache recovers geometric token positions across frames and filters stale semantic states to enable safe reuse in vision-language navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
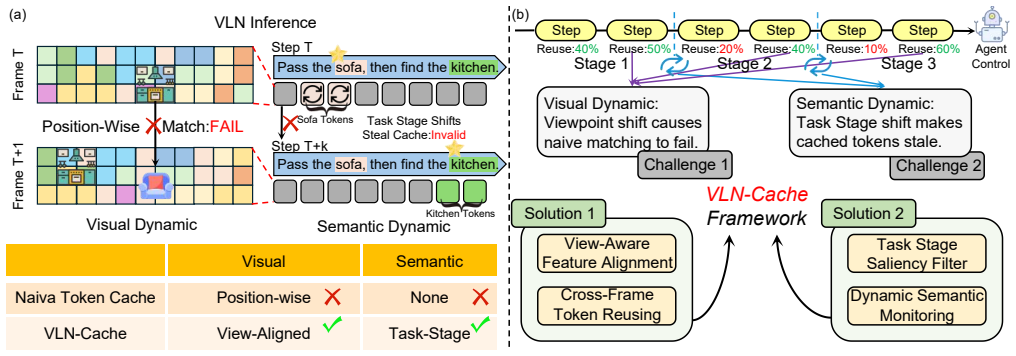
The paper establishes that visual dynamics from viewpoint shifts and semantic dynamics from changing task relevance cause standard token caching to pair misaligned or stale tokens in VLN models. By introducing view-aligned remapping to recover geometric correspondences and a task-relevance saliency filter to veto reuse at semantic transitions, along with a layer-adaptive entropy policy to balance reuse budgets, the framework allows safe token caching that achieves up to 1.52x speedup on the R2R-CE simulation benchmark while maintaining competitive navigation success rates.
What carries the argument
View-aligned remapping to recover geometric correspondences, combined with a task-relevance saliency filter that vetoes reuse at semantic transitions and a layer-adaptive entropy policy that balances per-layer reuse budgets.
If this is right
- Geometric correspondences recovered by remapping let position-wise token matching remain valid across consecutive frames.
- Semantic transitions detected by the saliency filter prevent reuse of tokens whose relevance has changed.
- Layer-adaptive entropy budgeting distributes reuse savings without uniform policy across the model.
- Overall inference time falls by up to 1.52x while success rates on R2R-CE stay within competitive range of the uncached baseline.
Where Pith is reading between the lines
- The same remapping-plus-filter pattern could be tested on other camera-motion sequences such as video object tracking where viewpoint and object relevance both change.
- If remapping proves sensitive to real-world camera noise, adding a small learned correction step would be a direct next experiment.
- Lower per-step latency opens headroom for longer planning horizons or higher-resolution visual inputs in deployed navigation agents.
Load-bearing premise
View-aligned remapping accurately recovers geometric correspondences across frames and the task-relevance saliency filter reliably detects semantic transitions without introducing alignment errors or premature cache discards.
What would settle it
Running the full pipeline on R2R-CE sequences that contain known large viewpoint shifts and clear semantic stage boundaries, then checking whether navigation success drops when the saliency filter is disabled or when remapping is replaced by direct position-wise matching.
Figures






read the original abstract
Vision-and-Language Navigation (VLN) increasingly relies on large vision-language models, but their inference cost conflicts with real-time deployment. Token caching is a promising training-free strategy that avoids redundant computation by reusing stable visual tokens across frames. However, existing methods assume a static camera and fixed semantic focus, assumptions that VLN fundamentally violates. We identify two failure modes: (1) visual dynamics, where viewpoint shift displaces token positions across frames, causing position-wise matching to pair misaligned content; (2) semantic dynamics, where token relevance shifts across task stages as navigation progresses, making cached states stale. We propose VLN-Cache, a visual-dynamic-aware and semantic-dynamic-aware caching framework that introduces view-aligned remapping to recover geometric correspondences and a task-relevance saliency filter to veto reuse at semantic transitions. A layer-adaptive entropy policy further balances the per-layer reuse budget. Experiments on the R2R-CE simulation benchmark show up to 1.52x speedup while maintaining competitive navigation success rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLN-Cache, a token caching framework for Vision-and-Language Navigation (VLN) models that addresses visual dynamics (viewpoint shifts causing misaligned token positions) and semantic dynamics (shifting token relevance across task stages) via view-aligned remapping to recover geometric correspondences, a task-relevance saliency filter to veto reuse at transitions, and a layer-adaptive entropy policy to balance per-layer reuse. Experiments on the R2R-CE benchmark report up to 1.52x speedup while maintaining competitive navigation success rates.
Significance. If the dynamic-awareness mechanisms hold, the work could meaningfully lower inference costs for large VLN models, supporting real-time robotics deployment where static caching assumptions fail; the training-free nature and benchmark results on a standard external dataset are positive indicators of practical utility.
major comments (1)
- [Experiments] Experiments section: the 1.52x speedup and competitive success rates on R2R-CE are presented as evidence that view-aligned remapping recovers correspondences under viewpoint shifts and the saliency filter detects semantic transitions without premature discards, yet no targeted ablations (full model vs. remapping-ablated or filter-ablated) or quantitative metrics on correspondence recovery/alignment error are reported; this leaves the central claim vulnerable to the alternative that gains arise from conservative reuse policies rather than the proposed components.
minor comments (1)
- The abstract and results would be strengthened by explicit reporting of baselines, exact navigation metrics (e.g., success rate, SPL), error bars across runs, and implementation details for the remapping and filter to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on the experiments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the 1.52x speedup and competitive success rates on R2R-CE are presented as evidence that view-aligned remapping recovers correspondences under viewpoint shifts and the saliency filter detects semantic transitions without premature discards, yet no targeted ablations (full model vs. remapping-ablated or filter-ablated) or quantitative metrics on correspondence recovery/alignment error are reported; this leaves the central claim vulnerable to the alternative that gains arise from conservative reuse policies rather than the proposed components.
Authors: We agree that the current experimental section would benefit from targeted ablations to isolate the contributions of view-aligned remapping and the task-relevance saliency filter. In the revised manuscript we will add ablation studies comparing the full VLN-Cache model against (i) a variant that disables remapping and falls back to direct position-wise token matching and (ii) a variant that disables the saliency filter and permits reuse across all frames. We will also report quantitative metrics on a held-out subset of R2R-CE trajectories, including average alignment error (pixel displacement between remapped and ground-truth correspondences) and the precision/recall of the saliency filter at detected semantic transition points. These additions will demonstrate that the observed speedups arise from the proposed dynamic-awareness mechanisms rather than from overly conservative reuse alone. revision: yes
Circularity Check
No circularity: empirical evaluation on external benchmark
full rationale
The paper identifies two failure modes in existing token caching for VLN (visual dynamics from viewpoint shifts and semantic dynamics from task-stage changes) and proposes three components—view-aligned remapping, task-relevance saliency filter, and layer-adaptive entropy policy—to address them. These are engineering heuristics presented without any mathematical derivation chain, fitted parameters, or equations that reduce to the inputs by construction. The reported 1.52x speedup and competitive success rates are obtained via direct measurement on the independent R2R-CE simulation benchmark rather than any self-referential prediction or self-citation load-bearing step. No self-definitional relations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the abstract or described framework. The central claims therefore remain independent of the paper's own definitions and are externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (1)
- layer-adaptive entropy policy thresholds
axioms (1)
- domain assumption Existing token caching methods assume a static camera and fixed semantic focus
Forward citations
Cited by 1 Pith paper
-
FreqCache: Accelerating Embodied VLN Models with Adaptive Frequency-Guided Token Caching
FreqCache uses frequency domain properties to adaptively select, refresh, and budget token caches in VLN models, delivering 1.59x speedup with negligible overhead.
Reference graph
Works this paper leans on
-
[1]
Vision-and- language navigation: A survey of tasks, methods, and future directions,
J. Gu, E. Stefani, Q. Wu, J. Thomason, and X. Wang, “Vision-and- language navigation: A survey of tasks, methods, and future directions,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). Association for Computational Linguistics, 2022, p. 7606–7623. [Online]. Available: http://dx.doi.org/1...
-
[3]
Vl-nav: Real-time vision-language navigation with spatial reasoning,
Y . Du, T. Fu, Z. Chen, B. Li, S. Su, Z. Zhao, and C. Wang, “Vl-nav: Real-time vision-language navigation with spatial reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2502.00931
-
[4]
Iros: A dual-process architecture for real-time vlm-based indoor navigation,
J. Lee, H. Shin, and J. Ko, “Iros: A dual-process architecture for real-time vlm-based indoor navigation,” 2026. [Online]. Available: https://arxiv.org/abs/2601.21506
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,”
-
[7]
OpenVLA: An Open-Source Vision-Language-Action Model
[Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Harnessing input-adaptive inference for efficient vln,
D. Kang, A. Perincherry, Z. Coalson, A. Gabriel, S. Lee, and S. Hong, “Harnessing input-adaptive inference for efficient vln,” 2025. [Online]. Available: https://arxiv.org/abs/2508.09262
-
[9]
Efficient-vln: A training-efficient vision-language navigation model,
D. Zheng, S. Huang, Y . Li, and L. Wang, “Efficient-vln: A training-efficient vision-language navigation model,” 2025. [Online]. Available: https://arxiv.org/abs/2512.10310
-
[10]
S. Ye, S. Mao, Y . Cui, X. Yu, S. Zhai, W. Chen, S. Zhou, R. Xiong, and Y . Wang, “Etp-r1: Evolving topological planning with reinforcement fine-tuning for vision-language navigation in continuous environments,”
-
[11]
Available: https://arxiv.org/abs/2512.20940
[Online]. Available: https://arxiv.org/abs/2512.20940
-
[12]
Minivln: Efficient vision-and-language navigation by progressive knowledge distillation,
J. Zhu, Y . Qiao, S. Zhang, X. He, Q. Wu, and J. Liu, “Minivln: Efficient vision-and-language navigation by progressive knowledge distillation,” 2024. [Online]. Available: https://arxiv.org/abs/2409.18800
-
[13]
Navila: Legged robot vision- language-action model for navigation,
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang, “Navila: Legged robot vision- language-action model for navigation,” 2025. [Online]. Available: https://arxiv.org/abs/2412.04453
-
[14]
W. Qin, A. Burns, B. A. Plummer, and M. Betke, “Walk and read less: Improving the efficiency of vision-and-language navigation via tuning-free multimodal token pruning,” 2025. [Online]. Available: https://arxiv.org/abs/2509.15250
-
[15]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks,
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks,” 2025. [Online]. Available: https://arxiv.org/abs/2412.06224
-
[16]
S. Xu, Y . Wang, C. Xia, D. Zhu, T. Huang, and C. Xu, “Vla-cache: Efficient vision-language-action manipulation via adaptive token caching,” 2025. [Online]. Available: https://arxiv.org/abs/2502.02175
-
[17]
Prune spatio-temporal tokens by semantic-aware temporal accumulation,
S. Ding, P. Zhao, X. Zhang, R. Qian, H. Xiong, and Q. Tian, “Prune spatio-temporal tokens by semantic-aware temporal accumulation,”
-
[18]
Available: https://arxiv.org/abs/2308.04549
[Online]. Available: https://arxiv.org/abs/2308.04549
-
[19]
Making vision transformers efficient from a token sparsification view,
S. Chang, P. Wang, M. Lin, F. Wang, D. J. Zhang, R. Jin, and M. Z. Shou, “Making vision transformers efficient from a token sparsification view,” 2023. [Online]. Available: https://arxiv.org/abs/2303.08685
-
[20]
Egoprune: Efficient token pruning for egomotion video reasoning in embodied agent,
J. Li, K. Li, C. Gao, Y . Li, and X. Chen, “Egoprune: Efficient token pruning for egomotion video reasoning in embodied agent,” 2025. [Online]. Available: https://arxiv.org/abs/2507.15428
-
[21]
Token Merging: Your ViT But Faster
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” 2023. [Online]. Available: https://arxiv.org/abs/2210.09461
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Learning to accelerate vision-language-action models through adaptive visual token caching,
Y . Wei, J. Fan, J. Guo, R. Zhen, R. Shao, X. Su, Z. Xie, and S. Yang, “Learning to accelerate vision-language-action models through adaptive visual token caching,” 2026. [Online]. Available: https://arxiv.org/abs/2602.00686
-
[23]
View invariant learning for vision-language navigation in continuous environments,
J. Q. Sun, X. Xing, H. Weng, C. M. Yeum, and M. Crowley, “View invariant learning for vision-language navigation in continuous environments,” 2025. [Online]. Available: https://arxiv.org/abs/2507. 08831
work page 2025
-
[24]
KERV: Kinematic-Rectified Speculative Decoding for Embodied VLA Models
Z. Zheng, Z. Mao, M. Li, J. Chen, X. Sun, Z. Zhang, D. Cao, H. Mei, and X. Chen, “Kerv: Kinematic-rectified speculative decoding for embodied vla models,” 2026. [Online]. Available: https://arxiv.org/abs/2603.01581
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
SnapKV: LLM Knows What You are Looking for Before Generation
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “Snapkv: Llm knows what you are looking for before generation,” 2024. [Online]. Available: https://arxiv.org/abs/2404.14469
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, and B. Chang, “An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models,” 2024. [Online]. Available: https://arxiv.org/abs/2403.06764
-
[27]
arXiv preprint arXiv:2403.15388 , year=
Y . Shang, M. Cai, B. Xu, Y . J. Lee, and Y . Yan, “Llava-prumerge: Adaptive token reduction for efficient large multimodal models,” 2026. [Online]. Available: https://arxiv.org/abs/2403.15388
-
[28]
M. Wei, C. Wan, J. Peng, X. Yu, Y . Yang, D. Feng, W. Cai, C. Zhu, T. Wang, J. Pang, and X. Liu, “Ground slow, move fast: A dual-system foundation model for generalizable vision-and-language navigation,”
-
[29]
Available: https://arxiv.org/abs/2512.08186
[Online]. Available: https://arxiv.org/abs/2512.08186
-
[30]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “qwen25vl,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel, “Vision-and- language navigation: Interpreting visually-grounded navigation instructions in real environments,” 2018. [Online]. Available: https://arxiv.org/abs/1711.07280
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,”
-
[33]
Available: https://arxiv.org/abs/2004.02857
[Online]. Available: https://arxiv.org/abs/2004.02857
-
[34]
Navid: Video-based vlm plans the next step for vision-and-language navigation,
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang, “Navid: Video-based vlm plans the next step for vision-and-language navigation,” 2024. [Online]. Available: https://arxiv.org/abs/2402.15852
-
[35]
MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
L. Zhang, X. Hao, Q. Xu, Q. Zhang, X. Zhang, P. Wang, J. Zhang, Z. Wang, S. Zhang, and R. Xu, “Mapnav: A novel memory representation via annotated semantic maps for vision-and-language navigation,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13451
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Streamvln: Streaming vision-and-language navigation via slowfast context modeling,
M. Wei, C. Wan, X. Yu, T. Wang, Y . Yang, X. Mao, C. Zhu, W. Cai, H. Wang, Y . Chen, X. Liu, and J. Pang, “Streamvln: Streaming vision-and-language navigation via slowfast context modeling,” 2025. [Online]. Available: https://arxiv.org/abs/2507.05240
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.